Image Processing and Computer Vision Techniques in Jupyter Notebook
发布时间: 2024-09-15 17:50:32 阅读量: 96 订阅数: 44 

Algorithms for Image Processing and Computer Vision, 2nd Edition
# Image Processing and Computer Vision Techniques in Jupyter Notebook
## Chapter 1: Introduction to Jupyter Notebook
### 2.1 What is Jupyter Notebook
Jupyter Notebook is an interactive computing environment that supports code execution, text writing, and image display. Its main features include:
- Supports multiple programming languages, such as Python, R, Julia, etc.;
- Can run in a browser without needing to install additional development environments;
- Allows mixing code and text, making experimentation and result presentation more convenient;
- Supports plugin extensions for easy integration with various tools.
### 2.2 Advantages and Characteristics of Jupyter Notebook
In the field of image processing and computer vision, Jupyter Notebook has many advantages:
- It provides a visual presentation of the image processing process, facilitating debugging and demonstration;
- The interactive notebook makes experimental data visualization more intuitive;
- Code and explanatory text are presented synchronously, making sharing and communication easier;
- Supports data visualization libraries, such as Matplotlib, Seaborn, etc., enriching the presentation forms.
This is an introduction to Jupyter Notebook along with its advantages and characteristics. Next, we will delve into the basics of image processing.
# 2. Basics of Image Processing
#### 2.1 Overview of Image Processing
Image processing refers to the techniques used to manipulate digital images to obtain desired information or improve image quality. Image processing generally includes the following:
- Image enhancement: Improving image quality and visualization through various techniques.
- Image restoration: Restoring images by removing noise or repairing damaged parts.
- Image compression: Reducing the storage space required for images through various encoding algorithms.
- Feature extraction: Extracting key features from images for subsequent image recognition and analysis.
#### 2.2 Introduction to Common Image Processing Libraries
In image processing, commonly used libraries include:
| Library Name | Language | Main Functions |
| ------------ | -------- | -------------- |
| OpenCV | C++/Python | Provides a wide range of image processing and computer vision functionalities |
| Pillow | Python | Supports image opening, manipulation, saving, etc. |
| scikit-image | Python | Offers various image processing algorithms and tools |
Code example: Using OpenCV to read an image and display it
```python
import cv2
import matplotlib.pyplot as plt
# Read the image
image = cv2.imread('image.jpg')
# Convert color space
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Display the image
plt.imshow(image_rgb)
plt.axis('off')
plt.show()
```
mermaid formatted flowchart example:
```mermaid
graph LR
A[Start] --> B(Image Enhancement)
B --> C(Image Restoration)
C --> D(Image Compression)
D --> E(Feature Extraction)
E --> F[End]
```
With the above content, we have a deeper understanding of the basics of image processing. The next section will continue to introduce image reading and display in Jupyter Notebook.
# 3. Image Reading and Display in Jupyter Notebook
## 3.1 Image Reading
In Jupyter Notebook, we can use common image processing libraries to read image files, such as OpenCV and PIL. Here is an example code using OpenCV to read an image:
```python
import cv2
# Read image file
img = cv2.imread('image.jpg')
# Display image size
height, width, channels = img.shape
print('Image size:', height, 'x', width)
# Display a message indicating successful reading
print('Image read successfully!')
```
## 3.2 Image Display
In Jupyter Notebook, we can use the Matplotlib library to display images. Here is an example code using Matplotlib to display an image:
```python
import matplotlib.pyplot as plt
import cv2
# Read image file
img = cv2.imread('image.jpg')
# Convert BGR format image to RGB format
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Display image
plt.imshow(img)
plt.axis('off') # Hide the axes
plt.show()
```
Next, we will use a table to compare the pros and cons of the two methods:
| Method | Pros | Cons |
| ----------------- | ------------------------------- | ----------------------------- |
| OpenCV | Fast image reading | Supports fewer formats |
| Matplotlib | Supports a wide range of formats | Slower than OpenCV |
Below is a Mermaid formatted flowchart showing the process of image reading and display:
```mermaid
graph LR
A[Start] --> B[Read Image File]
B --> C[Display Image Size]
C --> D[Display Successful Reading Message]
D --> E[Convert BGR to RGB Format]
E --> F[Display Image]
F --> G[End]
```
This concludes the specific content of Chapter 3, wh

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Adblock Plus高级应用:如何利用过滤器提升网页加载速度

# 摘要
本文全面介绍了Adblock Plus作为一款流行的广告拦截工具,从其基本功能到高级过滤策略,以及社区支持和未来的发展方向进行了详细探讨。首先,文章概述了Adb
【QCA Wi-Fi源代码优化指南】:性能与稳定性提升的黄金法则

# 摘要
本文对QCA Wi-Fi源代码优化进行了全面的概述,旨在提升Wi-Fi性能和稳定性。通过对QCA Wi-Fi源代码的结构、核心算法和数据结构进行深入分析,明确了性能优化的关键点。文章详细探讨了代码层面的优化策略,包括编码最佳实践、性能瓶颈的分析与优化、以及稳定性改进措施。系统层面
网络数据包解码与分析实操:WinPcap技术实战指南
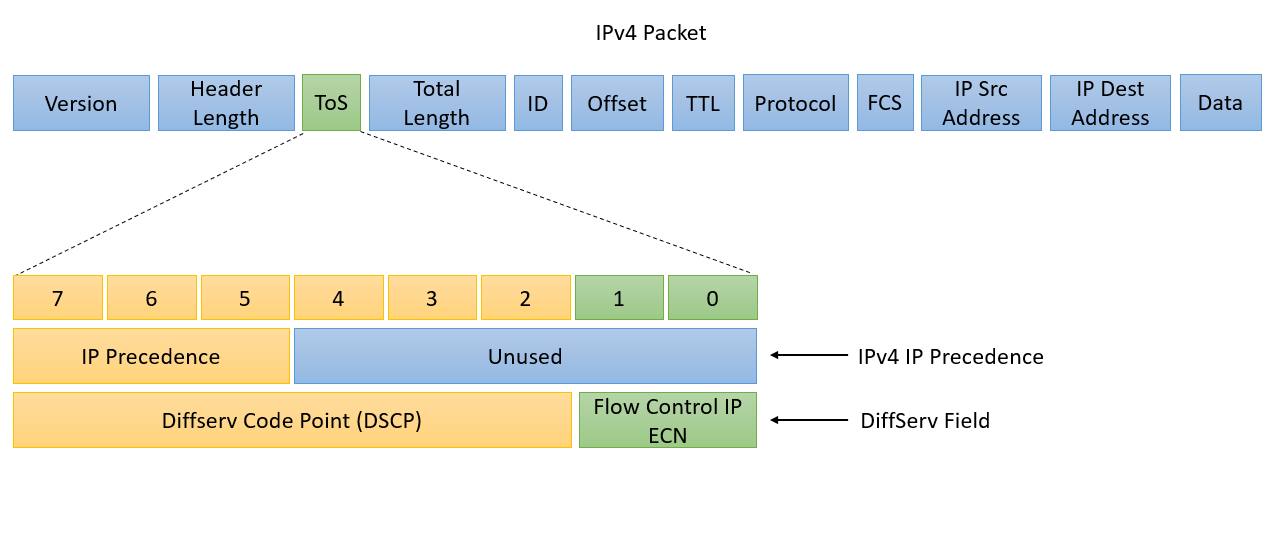
# 摘要
随着网络技术的不断进步,网络数据包的解码与分析成为网络监控、性能优化和安全保障的重要环节。本文从网络数据包解码与分析的基础知识讲起,详细介绍了WinPcap技术的核心组件和开发环境搭建方法,深入解析了数据包的结构和解码技术原理,并通过实际案例展示了数据包解码的实践过程。此外,本文探讨了网络数据分析与处理的多种技术,包括数据包过滤、流量分析,以及在网络安全中的应用,如入侵检测系统和网络
【EMMC5.0全面解析】:深度挖掘技术内幕及高效应用策略

# 摘要
EMMC5.0技术作为嵌入式存储设备的标准化接口,提供了高速、高效的数据传输性能以及高级安全和电源管理功能。本文详细介绍了EMMC5.0的技术基础,包括其物理结构、接口协议、性能特点以及电源管理策略。高级特性如安全机制、高速缓存技术和命令队列技术的分析,以及兼容性和测试方法的探讨,为读者提供了全面的EMMC5.0技术概览。最后,文章探讨了EMMC5.0在嵌入式系统中的应用以及未来的发展趋势和高效应用策略,强调了软硬
【高级故障排除技术】:深入分析DeltaV OPC复杂问题

# 摘要
本文旨在为DeltaV系统的OPC故障排除提供全面的指导和实践技巧。首先概述了故障排除的重要性,随后探讨了理论基础,包括DeltaV系统架构和OPC技术的角色、故障的分类与原因,以及故障诊断和排查的基本流程。在实践技巧章节中,详细讨论了实时数据通信、安全性和认证
手把手教学PN532模块使用:NFC技术入门指南
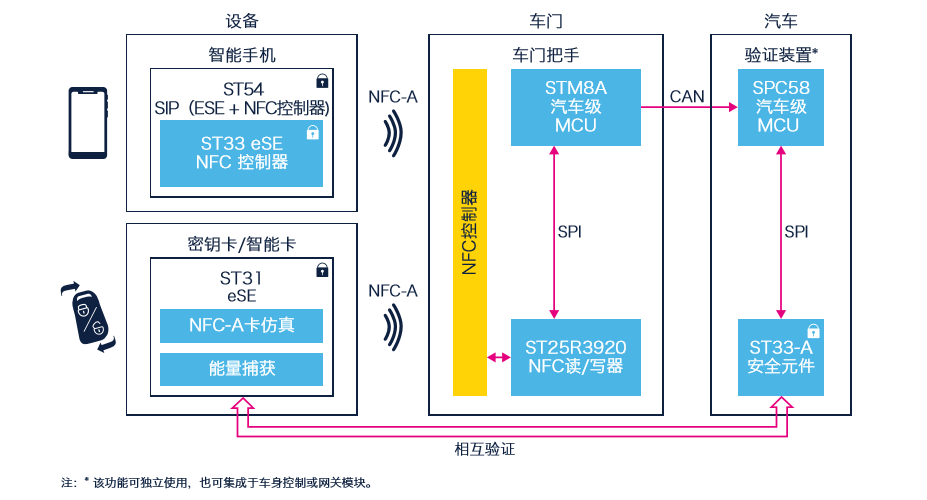
# 摘要
NFC(Near Field Communication,近场通信)技术是一项允许电子设备在短距离内进行无线通信的技术。本文首先介绍了NFC技术的起源、发展、工作原理及应用领域,并阐述了NFC与RFID(Radio-Frequency Identification,无线射频识别)技术的关系。随后,本文重点介绍了PN532模块的硬件特性、配置及读写基础,并探讨了
PNOZ继电器维护与测试:标准流程和最佳实践

# 摘要
PNOZ继电器作为工业控制系统中不可或缺的组件,其可靠性对生产安全至关重要。本文系统介绍了PNOZ继电器的基础知识、维护流程、测试方法和故障处理策略,并提供了特定应用案例分析。同时,针对未来发展趋势,本文探讨了新兴技术在PNOZ继电器中的应用前景,以及行业标准的更新和最佳实践的推广。通过对维护流程和故障处理的深入探讨,本文旨在为工程师提供实用的继电器维护与故障处
【探索JWT扩展属性】:高级JWT用法实战解析

# 摘要
本文旨在介绍JSON Web Token(JWT)的基础知识、结构组成、标准属性及其在业务中的应用。首先,我们概述了JWT的概念及其在身份验证和信息交换中的作用。接着,文章详细解析了JWT的内部结构,包括头部(Header)、载荷(Payload)和签名(Signature),并解释了标准属性如发行者(iss)、主题(sub)、受众(aud
Altium性能优化:编写高性能设计脚本的6大技巧

# 摘要
本文系统地探讨了基于Altium设计脚本的性能优化方法与实践技巧。首先介绍了Altium设计脚本的基础知识和性能优化的重要性,强调了缩短设计周期和提高系统资源利用效率的必要性。随后,详细解析了Altium设计脚本的运行机制及性能分析工具的应用。文章第三章到第四章重点讲述了编写高性能设计脚本的实践技巧,包括代码优化原则、脚
Qt布局管理技巧

# 摘要
本文深入探讨了Qt框架中的布局管理技术,从基础概念到深入应用,再到实践技巧和性能优化,系统地阐述了布局管理器的种类、特点及其适用场景。文章详细介绍了布局嵌套、合并技术,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )