Code Execution Order and Debugging Tips in Jupyter Notebook
发布时间: 2024-09-15 17:35:52 阅读量: 30 订阅数: 44 

check-execution-order
# 1. Understanding Code Execution Order in Jupyter Notebook
1.1 Default Rules for Code Execution Order:
- Jupyter Notebook executes code blocks from top to bottom by default.
- After each code block is executed, the output will be displayed below the code block.
1.2 Manually Adjusting Code Block Execution Order:
- You can manually execute specified code blocks using the "Run" button or shortcuts in the toolbar above.
- Numbered markers (e.g., `In[1]`, `In[2]`, etc.) are used to indicate the order of execution for code blocks.
1.3 Viewing Code Execution Status and Output Results:
- The square brackets `[]` to the left of a code block indicate that it has not been executed yet, `[*]` means it is currently executing, and `[1]` signifies it has been executed.
- If a code block encounters an error during execution, the system will display an error message and the line number where the error occurred.
With these methods, we can clearly understand the execution order and status of code in Jupyter Notebook, making debugging and viewing the results of code execution more convenient.
# 2. Debugging Code in Jupyter Notebook
Debugging is crucial during the development process as it helps us quickly discover and resolve issues within the code. Here are some commonly used techniques for debugging code in Jupyter Notebook:
#### 2.1 Inserting Breakpoints for Debugging
Inserting breakpoints is a common debugging method that allows the program to pause at a specified location, enabling us to inspect the execution process step by step.
- How to insert a breakpoint: Click on the blank space to the left of the code line, a blue circle will appear indicating that a breakpoint has been added.
- Example code:
```python
def calculate_sum(nums):
total = 0
for num in nums:
total += num
return total
nums = [1, 2, 3, 4, 5]
total_sum = calculate_sum(nums)
print(total_sum)
```
#### 2.2 Single-Step Debugging
Single-step debugging allows us to execute the code line by line and view the results of each step, which helps us understand the code execution process more clearly.
- Common operations for single-step debugging: Use the "Step Execution" button in the debugging toolbar to step through the code line by line.
- Example code:
```python
def calculate_sum(nums):
total = 0
for num in nums:
total += num
print(f'Current total: {total}')
return total
nums = [1, 2, 3, 4, 5]
total_sum = calculate_sum(nums)
print(total_sum)
```
#### 2.3 Viewing Variable Values and Status
During debugging, we need to continuously monitor variable values and status to promptly identify issues and make adjustments.
- Viewing variable values: In Jupyter Notebook, you can use the print() function to output the value of variables.
- Example code:
```python
def calculate_sum(nums):
total = 0
for num in nums:
total += num
print(f'Current total: {total}')
return total
nums = [1, 2, 3, 4, 5]
total_sum = calculate_sum(nums)
print(total_sum)
```
#### Debugging Flowchart Example:
```mermaid
graph TB
A(Start) --> B{Condition Check}
B -- Yes --> C[Execute Code Block A]
B -- No --> D[Execute Code Block B]
C --> E{Need Debugging?}
E -- Yes --> F[Insert Breakpoint]
E -- No --> G[Continue Execution]
F --> H{Single-Step Debugging}
H -- Yes --> I[Check Variable Status]
H -- No --> I
I --> G
G --> J(End)
D --> J
```
With the above debugging techniques, we can more efficiently troubleshoot code issues in Jupyter Notebook, improving development efficiency.
# 3. Using Magic Commands in Jupyter Notebook to Enhance Debugging Efficiency
In Jupyter Notebook, magic commands can help us debug and optimize code performance more efficiently. Below are several commonly used magic commands and their usage methods.
#### 3.1 %debug: Enter Debug Mode When an Exception Occurs
The `%debug` magic command can be used to enter debug mode when an exception occurs in the code, allowing us to view the cause of the exception. Here is an example code:
```python
def divide_by_zero():
return 10 / 0
try:
divide_by_zero()
except Exception as e:
%debug
```
In the above code, if the `divide_by_zero()` function throws a division by zero exception, `%debug` will启动 the debugger, allowing us to view the current call stack and variable states.
#### 3.2 %pdb: Automatically Start the Debugger When an Exception Occurs
The `%pdb` magic command can automatically start the debugger when an exception occurs in the code, without needing to manually add a `try...except` block. For example:
```python
%pdb on
def divide_by_zero():
return 10 / 0
divide_by_zero()
```
In this example, when the `divide_by_zero()` function throws a division by zero exception, the debugger will automatically启动 for debugging purposes.
#### 3.3 %timeit: Measure Code Execution Time
The `%timeit` magic command can be used to measure the execution time of a cod

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【EDEM仿真非球形粒子专家】:揭秘提升仿真准确性的核心技术

# 1. EDEM仿真软件概述与非球形粒子的重要性
## 1.1 EDEM仿真软件简介
EDEM是一种用于粒子模拟的仿真工具,能够准确地模拟和分析各种离散元方法(Discrete Element Method, DEM)问题。该软件广泛应用于采矿
雷达数据压缩技术突破:提升效率与存储优化新策略

# 1. 雷达数据压缩技术概述
在现代军事和民用领域,雷达系统产生了大量的数据,这些数据的处理和存储是技术进步的关键。本章旨在对雷达数据压缩技术进行简要
SaTScan软件的扩展应用:与其他统计软件的协同工作揭秘

# 1. SaTScan软件概述
SaTScan是一种用于空间、时间和空间时间数据分析的免费软件,它通过可变动的圆形窗口统计分析方法来识别数据中的异常聚集。本章将简要介绍SaTScan的起源、功能及如何在不同领域中得到应用。SaTScan软件特别适合公共卫生研究、环境监测和流行病学调查等领域,能够帮助研究人员和决策者发现数据中的模式和异常,进行预防和控制策略的制定。
在
SGMII传输层优化:延迟与吞吐量的双重提升技术

# 1. SGMII传输层优化概述
在信息技术不断发展的今天,网络传输的效率直接影响着整个系统的性能。作为以太网物理层的标准之一,SGMII(Serial Gigabit Media Independent Interface)在高性能网络设计中起着至关重要的作用。SGMII传输层优化,就是通过一系列手段来提高数据传输效率,减少延迟,提升吞吐量,从而达到优化整个网络性能的目
Java SPI与依赖注入(DI)整合:技术策略与实践案例
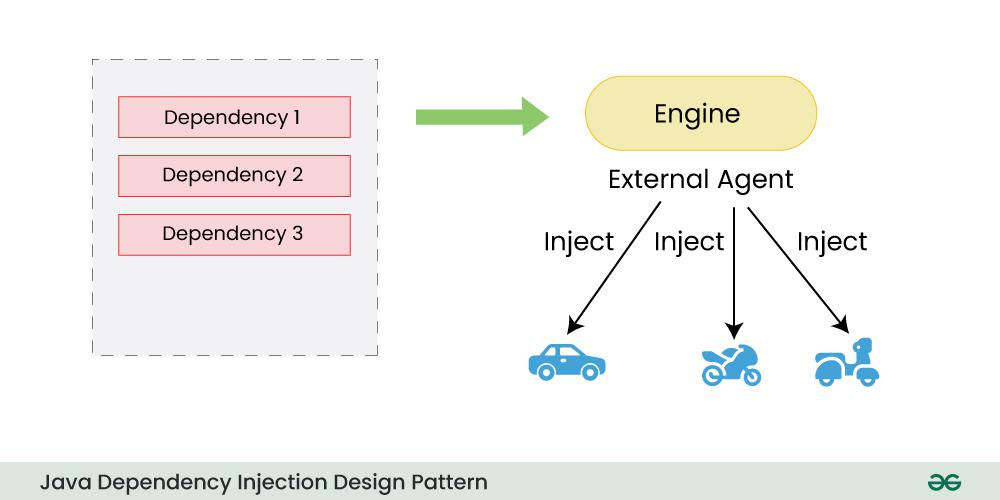
# 1. Java SPI机制概述
## 1.1 SPI的概念与作用
Service Provider Interface(SPI)是Java提供的一套服务发现机制,允许我们在运行时动态地提供和替换服务实现。它主要被用来实现模块之间的解耦,使得系统更加灵活,易于扩展。通过定义一个接口以及一个用于存放具体服务实现类的配置文件,我们可以轻松地在不修改现有代码的情况下,增加或替换底
【矩阵求逆的历史演变】:从高斯到现代算法的发展之旅

# 1. 矩阵求逆概念的起源与基础
## 1.1 起源背景
矩阵求逆是线性代数中的一个重要概念,其起源可以追溯到19世纪初,当时科学家们开始探索线性方程组的解法。早期的数学家如高斯(Carl Friedrich Gauss)通过消元法解决了线性方程组问题,为矩阵求逆奠定了基础。
社交网络分析工具大比拼:Gephi, NodeXL, UCINET优劣全面对比
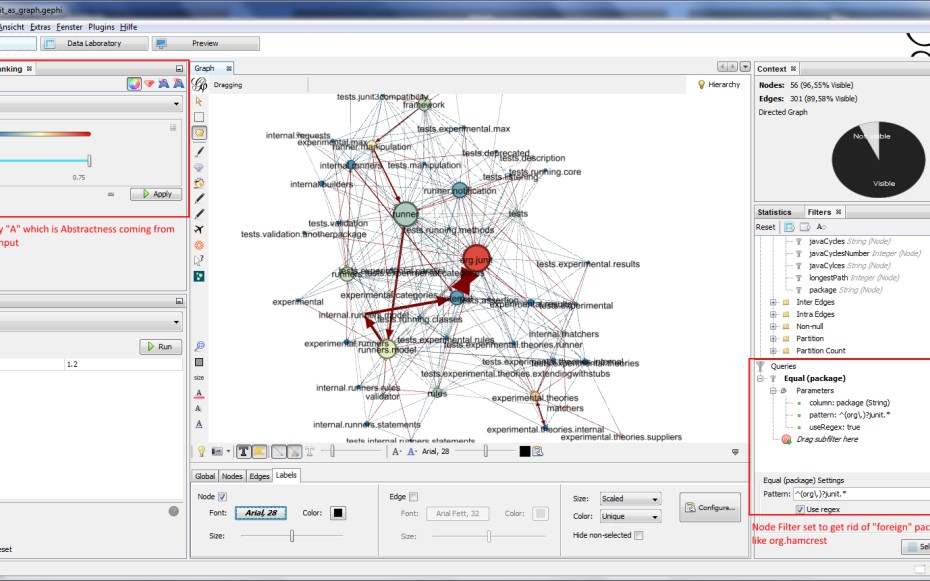
# 1. 社交网络分析概述
社交网络分析是理解和揭示社会结构和信息流的一种强有力的工具,它跨越了人文和社会科学的边界,找到了在计算机科学中的一个牢固立足点。这一分析不仅限于对人际关系的研究,更扩展到信息传播、影响力扩散、群体行为等多个层面。
## 1.1 社交网络分析的定义
社交网络分析(Social Network Analysis,简称SNA)是一种研究社会结构的方法论
原型设计:提升需求沟通效率的有效途径

# 1. 原型设计概述
在现代产品设计领域,原型设计扮演着至关重要的角色。它不仅是连接设计与开发的桥梁,更是一种沟通与验证设计思维的有效工具。随着技术的发展和市场对产品快速迭代的要求不断提高,原型设计已经成为产品生命周期中不可或缺的一环。通过创建原型,设计师能够快速理解用户需求,验证产品概念,及早发现潜在问题,并有效地与项目相关方沟通想法,从而推动产品向前发展。本章将对原型设计的必要性、演变以及其在产品开发过程中的作
Python环境监控高可用构建:可靠性增强的策略

# 1. Python环境监控高可用构建概述
在构建Python环境监控系统时,确保系统的高可用性是至关重要的。监控系统不仅要在系统正常运行时提供实时的性能指标,而且在出现故障或性能瓶颈时,能够迅速响应并采取措施,避免业务中断。高可用监控系统的设计需要综合考虑监控范围、系统架构、工具选型等多个方面,以达到对资源消耗最小化、数据准确性和响应速度最优化的目
【信号异常检测法】:FFT在信号突变识别中的关键作用
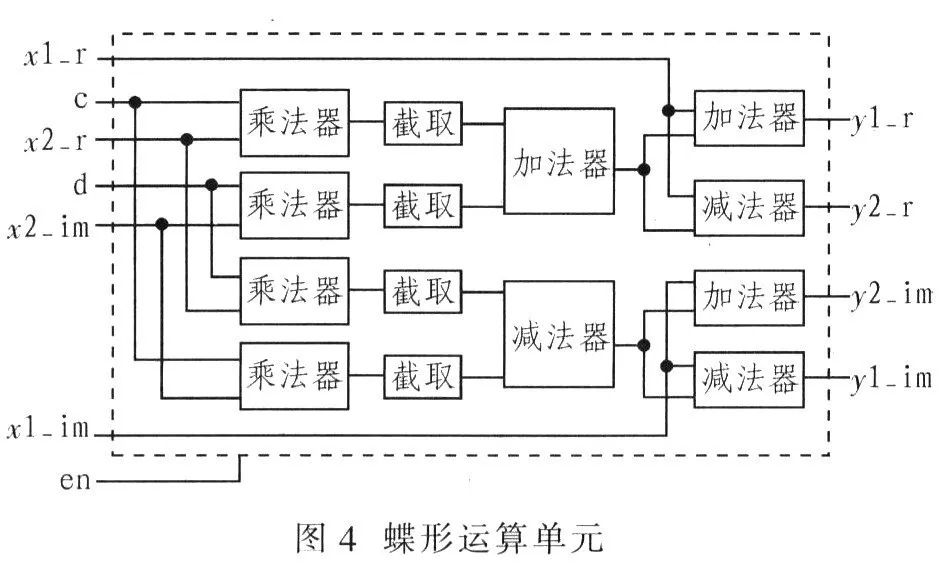
# 1. 信号异常检测法基础
## 1.1 信号异常检测的重要性
在众多的IT和相关领域中,从工业监控到医疗设备,信号异常检测是确保系统安全和可靠运行的关键技术。信号异常检测的目的是及时发现数据中的不规则模式,这些模式可能表明了设备故障、网络攻击或其他需要立即关注的问题。
## 1.2 信号异常检测方法概述
信号异常检测的方法多种多样,包括统计学方法、机器学习方法、以及基于特定信号
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )