Data Processing and Cleaning Tips in Jupyter Notebook
发布时间: 2024-09-15 17:43:53 阅读量: 37 订阅数: 44 
# Chapter 1. Data Import and Overview
Data forms the bedrock of any data analysis endeavor. The first step in data processing is correctly importing and initially observing the data. This chapter will introduce how to perform data import and overview in Jupyter Notebook, including importing datasets, viewing dataset information, data preview, and preliminary observation.
### Importing Datasets
In the data processing journey, we often use the pandas library to handle data. Pandas provides a rich set of data structures and functions, facilitating the import of various formats of data files, such as CSV, Excel, SQL databases, and more. Below is an example code for importing datasets:
```python
import pandas as pd
# Importing a dataset from a CSV file
df = pd.read_csv('data.csv')
# Importing a dataset from an Excel file
df = pd.read_excel('data.xlsx')
# Importing a dataset from an SQL database
import sqlite3
conn = sqlite3.connect('database.db')
df = pd.read_sql_query("SELECT * FROM table", conn)
```
### Viewing Dataset Information
After importing the dataset, we need to view the basic information of the dataset, including data dimensions, column names, data types, missing value situations, etc. The `info()` method can be used to quickly view the information of the dataset:
```python
# ***
***()
```
### Data Preview and Preliminary Observation
In addition to viewing the information of the dataset, we can also use methods like `head()` and `tail()` to preview the first or last few rows of the dataset, allowing for a more intuitive understanding of the data structure:
```python
# Viewing the first few rows of the dataset
df.head()
# Viewing the last few rows of the dataset
df.tail()
```
With these operations, we can have a preliminary understanding of the imported dataset, laying the groundwork for subsequent data cleaning and processing.
# Chapter 2. Data Cleaning and Processing
Data cleaning and processing are crucial in data analysis, as cleaning and processing data makes it more accurate and complete, thereby enhancing the accuracy and credibility of subsequent analysis. This chapter will introduce common data cleaning and processing techniques, including handling missing values, handling duplicate values, data type conversion, and outlier handling.
### Handling Missing ***
***mon methods include removing missing values and filling in missing values.
The table below shows a dataset with missing values, and we will demonstrate how to handle these missing values.
| Name | Age | Gender | Score |
|---------|-----|--------|-------|
| Xiao Ming | 25 | Male | 85 |
| Xiao Hong | 30 | Female | NaN |
| Xiao Hua | NaN | Male | 77 |
| Xiao Li | 28 | Male | 92 |
```python
# Example code for handling missing values
import pandas as pd
data = {'Name': ['Xiao Ming', 'Xiao Hong', 'Xiao Hua', 'Xiao Li'],
'Age': [25, 30, None, 28],
'Gender': ['Male', 'Female', 'Male', 'Male'],
'Score': [85, None, 77, 92]}
df = pd.DataFrame(data)
# Deleting rows with missing values
df.dropna(inplace=True)
```
The processed dataset will delete rows with missing values, retaining complete data.
### ***
***mon methods include deleting duplicate values and keeping unique values.
The following code demonstrates how to handle duplicate values:
```python
# Example code for handling duplicate values
# Assuming df is a dataset with duplicate values
df.drop_duplicates(inplace=True)
```
With the above code, we can delete duplicate values in the dataset, ensuring uniqueness.
The above examples cover handling missing values and duplicate values. We will continue to introduce data type conversion and outlier handling later.
# Chapter 3. Data Filtering and Sorting
In the data processing process, data filtering and sorting are very common operations. We can select an interesting subset of data through filtering, and sorting can arrange data according to specific rules. In this chapter, we will introduce how to perform data filtering and sorting operations.
### Conditional Filtering
In a DataFrame, we often need to filter data rows based on certain conditions. The following example demonstrates how to perform conditional filtering using Pandas:
```python
import pandas as pd
# Creating example data
data = {'A': [1, 2, 3, 4, 5],
'B': ['a', 'b', 'c', 'd', 'e']}
df = pd.DataFrame(data)
# Filtering based on conditions
filtered_df = df[df['A'] > 2]
print(filtered_df)
```
With the above code, we can filter data rows where the value in column 'A' is greater than 2.
### Column Selection and Filtering
In addition to filtering rows, sometimes we need to select and filter columns as well. Pandas provides a simple way to achieve this:
```python
# Selecting specific columns
selected_
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ARM调试接口进化论】:ADIV6.0相比ADIV5在数据类型处理上的重大飞跃

# 摘要
本文全面概述了ARM调试接口的发展和特点,重点介绍了ADIV5调试接口及其对数据类型处理的机制。文中详细分析了ADIV5的数据宽度、对齐问题和复杂数据结构的处理挑战,并探讨了ADIV6.0版本带来的核心升级,包括调试架构的性能提升和对复杂数据类型处理的优
渗透测试新手必读:靶机环境的五大实用技巧

# 摘要
随着网络安全意识的增强,渗透测试成为评估系统安全的关键环节。靶机环境作为渗透测试的基础平台,其搭建和管理对于测试的有效性和安全性至关重要。本文全面概述了渗透测试的基本概念及其对靶机环境的依赖性,深入探讨了靶机环境搭建的理论基础和实践技巧,强调了在选择操作系统、工具、网络配置及维护管理方面的重要性。文章还详细介绍了渗透测试中的攻击模拟、日志分析以及靶机环境的安全加固与风险管理。最后,展
LGO脚本编写:自动化与自定义工作的第一步
# 摘要
本文详细介绍了LGO脚本编写的基础知识和高级应用,探讨了其在自动化任务、数据处理和系统交互中的实战应用。首先概述了LGO脚本的基本元素,包括语法结构、控制流程和函数使用。随后,文章通过实例演练展示了LGO脚本在自动化流程实现、文件数据处理以及环境配置中的具体应用。此外,本文还深入分析了LGO脚本的扩展功能、性能优化以及安全机制,提出了
百万QPS网络架构设计:字节跳动的QUIC案例研究
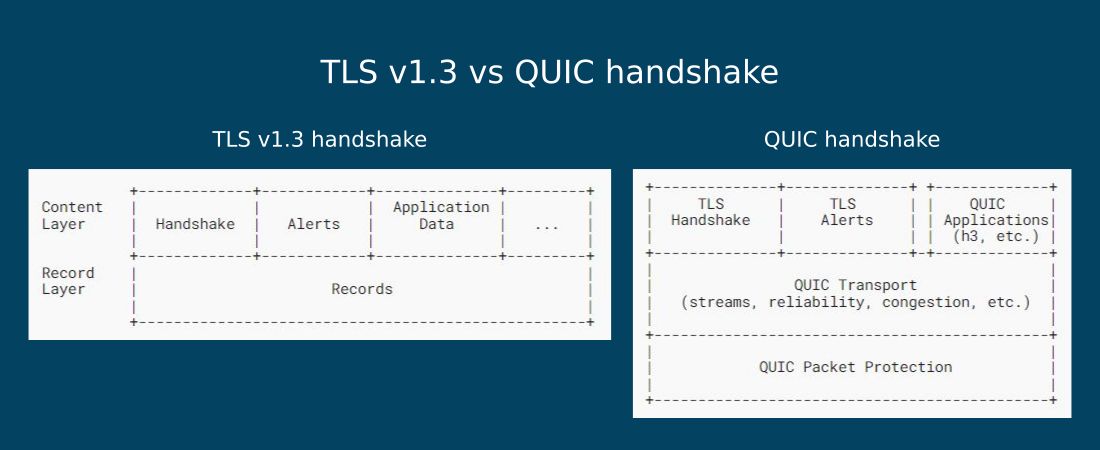
# 摘要
随着网络技术的快速发展,百万QPS(每秒查询数)已成为衡量现代网络架构性能的关键指标之一。本文重点探讨了网络架构设计中面临百万QPS挑战时的策略,并详细分析了QUIC协议作为新兴传输层协议相较于传统TCP/IP的优势,以及字节跳动如何实现并优化QUIC以提升网络性能。通过案例研究,本文展示了QUIC协议在实际应用中的效果,
FPGA与高速串行通信:打造高效稳定的码流接收器(专家级设计教程)

# 摘要
本文全面探讨了基于FPGA的高速串行通信技术,从硬件选择、设计实现到码流接收器的实现与测试部署。文中首先介绍了FPGA与高速串行通信的基础知识,然后详细阐述了FPGA硬件设计的关键步骤,包括芯片选择、硬件配置、高速串行标准选择、内部逻辑设计及其优化。接下来,文章着重讲述了高速串行码流接收器的设计原理、性能评估与优化策略,以及如何在实际应用中进行测试和部署。最后,本文展望了高速串行
Web前端设计师的福音:贝塞尔曲线实现流畅互动的秘密
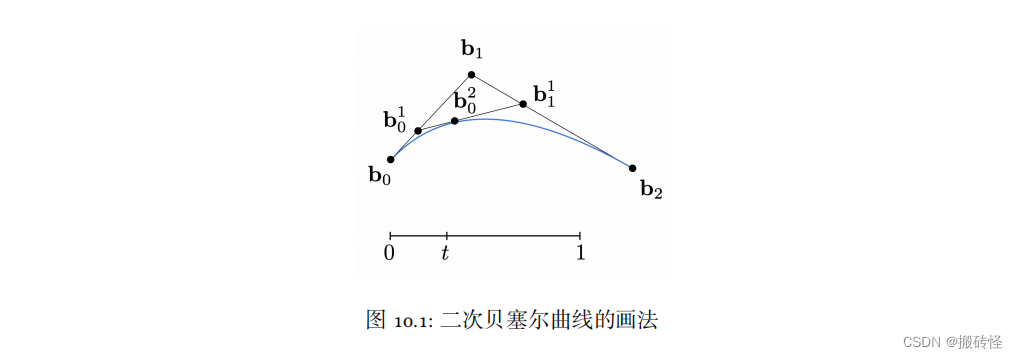
# 摘要
贝塞尔曲线是计算机图形学中用于描述光滑曲线的重要工具,它在Web前端设计中尤为重要,通过CSS和SVG技术实现了丰富的视觉效果和动画。本文首先介绍了贝塞尔曲线的数学基础和不同类型的曲线,然后具体探讨了如何在Web前端应用中使用贝塞尔曲线,包括CSS动画和SVG路径数据的利用。文章接着通过实践案例分析,阐述了贝塞尔曲线在提升用户界面动效平滑性、交互式动画设计等方面的应用。最后,文章聚焦于性能优化
【终端工具对决】:MobaXterm vs. WindTerm vs. xshell深度比较

# 摘要
本文对市面上流行的几种终端工具进行了全面的深度剖析,比较了MobaXterm、WindTerm和Xshell这三款工具的基本功能、高级特性,并进行了性能测试与案例分析。文中概述了各终端工具的界面操作体验、支持的协议与特性,以及各自的高级功能如X服务器支持、插件系统、脚本化能力等。性能测试结果和实际使用案例为用户提供了具体的性能与稳定性数据参考。最后一章从用户界面、功能特性、性能稳定性等维度对
电子建设项目决策系统:预算编制与分析的深度解析

# 摘要
本文对电子建设项目决策系统进行了全面的概述,涵盖了预算编制和分析的核心理论与实践操作,并探讨了系统的优化与发展方向。通过分析预算编制的基础理论、实际项目案例以及预算编制的工具和软件,本文提供了深入的实践指导。同时,本文还对预算分析的重要性、方法、工具和实际案例进行了详细讨论,并探讨了如何将预算分析结果应用于项目优化。最后,本文考察了电子建设项目决策系统当前的优化方法和未来的发展趋势
【CSEc硬件加密模块集成攻略】:在gcc中实现安全与效率
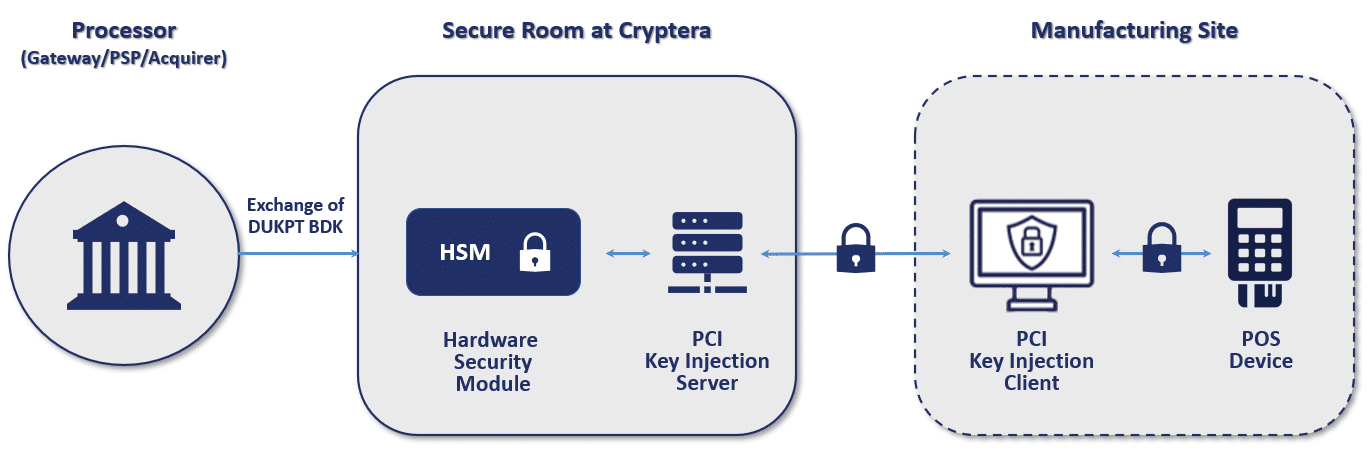
# 摘要
本文详细介绍了CSEc硬件加密模块的基础知识、工作原理、集成实践步骤、性能优化与安全策略以及在不同场景下的应用案例。首先,文章概述了CSEc模块的硬件架构和加密解密机制,并将其与软件加密技术进行了对比分析。随后,详细描述了在gcc环境中如何搭建和配置环境,并集成CSEc模块到项目中。此外,本文还探讨了性能调优和安全性加强措施,包括密钥管理和防御
【确保硬件稳定性与寿命】:硬件可靠性工程的实战技巧

# 摘要
硬件可靠性工程是确保现代电子系统稳定运行的关键学科。本文首先介绍了硬件可靠性工程的基本概念和硬件测试的重要性,探讨了不同类型的硬件测试方法及其理论基础。接着,文章深入分析了硬件故障的根本原因,故障诊断技术,以及预防性维护对延长设备寿命的作用。第四章聚焦于硬件设计的可靠性考虑,HALT与HAS
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )