Introduction to Common Data Science Tools in Jupyter Notebook
发布时间: 2024-09-15 17:46:44 阅读量: 30 订阅数: 36 

Introduction to Data Science in Python Assignment2
# 1. Introduction to Jupyter Notebook
Jupyter Notebook is an open-source interactive computing tool that is widely used for data cleaning and transformation, numerical simulation, statistical modeling, data visualization, and machine learning, among other fields. It supports over 40 programming languages, including Python, R, and Julia. The flexibility of Jupyter Notebook allows data scientists to write, experiment, and present results in one place.
## What is Jupyter Notebook?
Jupyter Notebook is an interactive computing environment based on an open-source web application that allows users to write and run code in a notebook format. Users can write executable code in the notebook, combining rich text, formulas, images, and charts.
## Advantages of Jupyter Notebook
- **Interactive Computing**: Ability to run code in real-time, view results, and quickly iterate for improvements.
- **Documented**: Supports Markdown format, integrating code, text, and charts into a single document.
- **Easy Sharing**: Can be exported to formats such as HTML and PDF for easy sharing with others.
- **Support for Multiple Programming Languages**: In addition to Python, it supports R, Julia, and other mainstream programming languages.
- **Rich Extensions**: Boasts a plethora of plugins and extension libraries to meet various needs.
- **Graphical Interface**: Facilitates visualization of data and results, aiding in data analysis and presentation.
## How to Install Jupyter Notebook
Installing Jupyter Notebook is straightforward and can be done using the pip package manager:
```bash
pip install jupyterlab
```
After installation, start Jupyter Notebook:
```bash
jupyter notebook
```
You can then open the Jupyter Notebook interface in your browser and begin coding and documenting.
# 2. Data Processing Tools
Data processing is a crucial part of data science projects, and common data processing tools in Jupyter Notebook include the Pandas and Numpy libraries. We will now delve into their usage.
#### 2.1 Introduction to Pandas Library
Pandas is a library in Python for data processing and analysis, which provides a data structure known as DataFrame, making data manipulation simpler and more efficient. Here are some of Pandas' commonly used features:
- Data Reading: Can read from various data sources, such as CSV files, SQL databases, Excel files, etc.
- Data Cleaning: Handles missing values, duplicates, outliers, etc., to make data cleaner.
- Data Filtering: Filters data based on conditions to extract the necessary parts.
- Data Aggregation: Performs statistical analysis and aggregates data.
Below is a simple example of Pandas code that reads a CSV file and displays the first few rows:
```python
import pandas as pd
# Reading CSV file
data = pd.read_csv('data.csv')
# Displaying the first five rows of data
print(data.head())
```
#### 2.2 Introduction to Numpy Library
Numpy is a library in Python for scientific computing, primarily used for handling multidimensional arrays and matrix operations. Numpy provides efficient mathematical functions and tools suitable for processing large-scale data. Here are some of Numpy's features:
- Array Operations: Numpy arrays perform fast vectorized operations, enhancing computational efficiency.
- Logical Operations: Capable of logical operations and boolean indexing.
- Mathematical Functions: Provides a wide range of mathematical functions such as sin, cos, exp, etc.
- Linear Algebra Operations: Supports matrix multiplication, inversion, and other linear algebra operations.
Below is a simple example of Numpy code that creates a two-dimensional array and performs matrix multiplication:
```python
import numpy as np
# Creating arrays
arr1 = np.array([[1, 2], [3, 4]])
arr2 = np.array([[2, 0], [1, 3]])
# Matrix multiplication operation
result = np.dot(arr1, arr2)
print(result)
```
#### 2.3 Data Cleaning and Processing Tips
In actual data processing, it is often necessary to clean and process data to ensure data quality. Some commonly used data cleaning and processing tips include:
- Handling Missing Values: Use the `dropna()` or `fillna()` functions in the Pandas library to address missing values.
- Removing Duplicates: Utilize the `drop_duplicates()` function in the Pandas library to eliminate duplicates.
- Dealing with Outliers: Identify and handle outliers using statistical methods or visualization techniques.
- Data Transformation: Perform standardization, normalization, discretization, and other data transformations.
- Feature Engineering: Create new features or combine features to extract more useful information.
By mastering these data processing tools and techniques, data can be processed more efficiently, laying a foundation for subsequent analysis and modeling work.
# 3. Data Visualization Tools
Data visualization plays a vital role in data science projects because intuitive and clear charts help us better understand data, discover trends, and patterns. In Jupyter Notebook, there are many commonly used data visualization tools, including Matplotlib, Seaborn, and Plotly, among others. We will now discuss their characteristics and how to apply these tools for data visualization in projects.
#### 3.1 Introduction to Matplotlib Library
Matplotlib is one of the most widely used plotting libraries in Python. It offers a rich set of plotting features and is capable of creating various types of charts, such as line charts, scatter plots, bar charts, etc. Below are some of the features of Matplotlib:
- Supports multiple chart styles
- Highly flexible with the ability to customize various parts of the chart in detail
- User-friendly with comprehensive documentation and an active community
#### 3.2 Introduction to Seaborn Library
Seaborn is a high-level plotting library built on top of Matplotlib, focusing on statistical visualization. It allows for the creation of beautiful statistical cha

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【实变函数论:大师级解题秘籍】

# 摘要
实变函数论是数学分析的一个重要分支,涉及对实数系函数的深入研究,包括函数的极限、连续性、微分、积分以及更复杂结构的研究。本文概述了实变函数论的基本理论,重点探讨了实变函数的基本概念、度量空间与拓扑空间的性质、以及点集拓扑的基本定理。进一步地,文章深入分析了测度论和积分论的理论框架,讨论了实变函数空间的结构特性,包括L^p空间的性质及其应用。文章还介绍了实变函数论的高级技巧
【Betaflight飞控软件快速入门】:从安装到设置的全攻略

# 摘要
本文对Betaflight飞控软件进行了全面介绍,涵盖了安装、配置、基本功能使用、高级设置和优化以及故障排除与维护的详细步骤和技巧。首先,本文介绍了Betaflight的基本概念及其安装过程,包括获取和安装适合版本的固件,以及如何使用Betaflight Conf
Vue Select选择框高级过滤与动态更新:打造无缝用户体验
# 摘要
本文详细探讨了Vue Select选择框的实现机制与高级功能开发,涵盖了选择框的基础使用、过滤技术、动态更新机制以及与Vue生态系统的集成。通过深入分析过滤逻辑和算法原理、动态更新的理论与实践,以及多选、标签模式的实现,本文为开发者提供了一套完整的Vue Select应用开发指导。文章还讨论了Vue Select在实际应用中的案例,如表单集成、复杂数据处理,并阐述了测试、性能监控和维
揭秘DVE安全机制:中文版数据保护与安全权限配置手册

# 摘要
随着数字化时代的到来,数据价值与安全风险并存,DVE安全机制成为保护数据资产的重要手段。本文首先概述了DVE安全机制的基本原理和数据保护的必要性。其次,深入探讨了数据加密技术及其应用,以
三角矩阵实战案例解析:如何在稀疏矩阵处理中取得优势

# 摘要
稀疏矩阵和三角矩阵是计算机科学与工程领域中处理大规模稀疏数据的重要数据结构。本文首先概述了稀疏矩阵和三角矩阵的基本概念,接着深入探讨了稀疏矩阵的多种存储策略,包括三元组表、十字链表以及压缩存储法,并对各种存储法进行了比较分析。特别强调了三角矩阵在稀疏存储中的优势,讨论了在三角矩阵存储需求简化和存储效率提升上的策略。随后,本文详细介绍了三角矩阵在算法应用中的实践案例,以及在编程实现方
Java中数据结构的应用实例:深度解析与性能优化
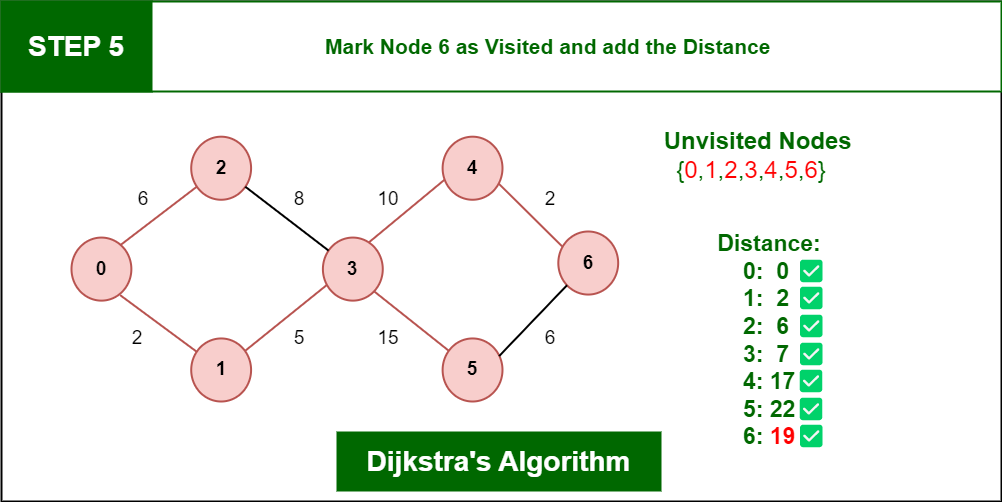
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
【性能提升】:一步到位!施耐德APC GALAXY UPS性能优化技巧

# 摘要
本文旨在深入探讨不间断电源(UPS)系统的性能优化与管理。通过细致分析UPS的基础设置、高级性能调优以及创新的维护技术,强调了在不同应用场景下实现性能优化的重要性。文中不仅提供了具体的设置和监控方法,还涉及了故障排查、性能测试和固件升级等实践案例,以实现对UPS的全面性能优化。此外,文章还探讨了环境因素、先进的维护技术及未来发展趋势,为UPS性能优化提供了全
坐标转换秘籍:从西安80到WGS84的实战攻略与优化技巧
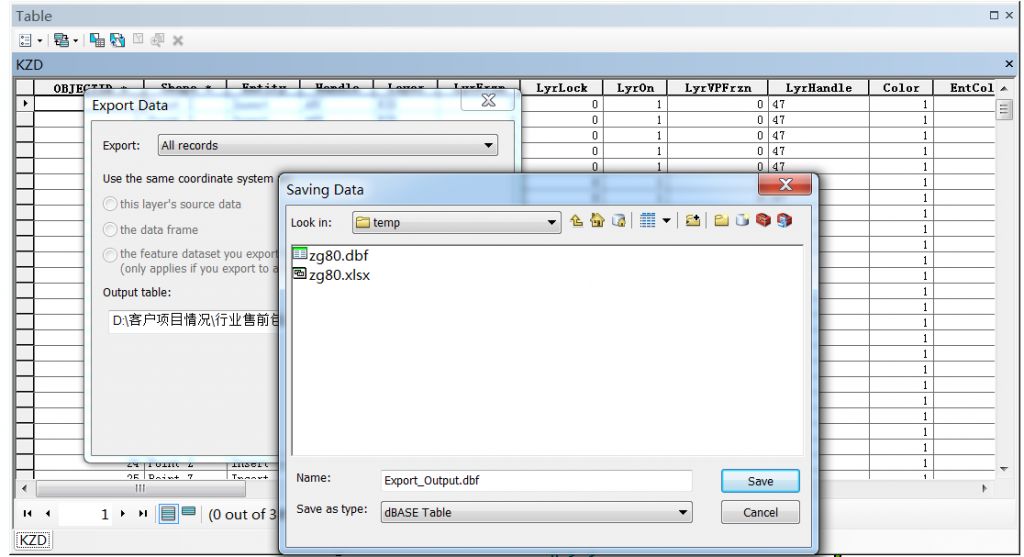
# 摘要
本文全面介绍了坐标转换的相关概念、基础理论、实战攻略和优化技巧,重点分析了从西安80坐标系统到WGS84坐标系统的转换过程。文中首先概述了坐标系统的种类及其重要性,进而详细阐述了坐标转换的数学模型,并探讨了实战中工具选择、数据准备、代码编写、调试验证及性能优化等关键步骤。此外,本文还探讨了提升坐标转换效率的多种优化技巧,包括算法选择、数据处理策略,以及工程实践中的部
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )