数据预处理艺术:为机器学习和数据分析做好数据准备
发布时间: 2024-07-20 15:58:14 阅读量: 46 订阅数: 41 
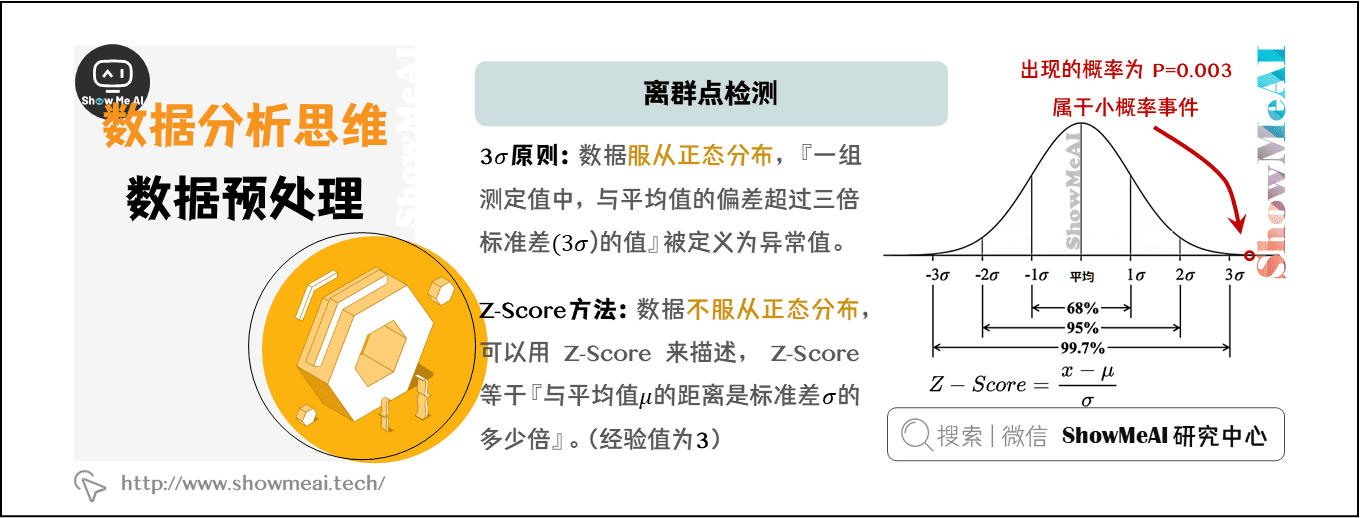
# 1. 数据预处理概述**
数据预处理是机器学习和数据分析过程中至关重要的一步,它涉及到将原始数据转换为适合建模和分析的格式。数据预处理的目的是提高数据的质量、一致性和可解释性,从而提高模型的性能和结果的可信度。
数据预处理的主要任务包括:
* 数据清洗:处理缺失值、异常值和不一致性,以确保数据的完整性和准确性。
* 数据转换:将数据转换为建模所需的格式,例如标准化、归一化和特征编码。
* 特征工程:选择、转换和创建新特征,以增强模型的性能和可解释性。
# 2.1 数据质量评估和清洗
数据质量评估和清洗是数据预处理中的关键步骤,旨在识别和修复数据中的错误、缺失值和不一致性。通过执行这些任务,可以提高后续数据分析和建模的准确性和可靠性。
### 2.1.1 数据类型转换和标准化
**数据类型转换**
数据类型转换涉及将数据从一种类型转换为另一种类型,例如从字符串到数字或从日期到时间戳。这对于确保数据的一致性和兼容性至关重要,因为它允许不同的数据源和应用程序以相同的方式处理数据。
**代码块:**
```python
import pandas as pd
df = pd.DataFrame({
"age": ["25", "30", "28", "22", "32"],
"salary": ["$50,000", "$60,000", "$55,000", "$45,000", "$65,000"]
})
# 将 "age" 列转换为整数
df["age"] = df["age"].astype(int)
# 将 "salary" 列转换为浮点数
df["salary"] = df["salary"].str.replace("$", "").astype(float)
```
**逻辑分析:**
* `astype()` 方法用于转换数据类型。
* 对于 "age" 列,将其转换为整数,因为年龄通常以整数表示。
* 对于 "salary" 列,首先使用 `str.replace()` 方法删除美元符号,然后将其转换为浮点数,因为工资通常以浮点数表示。
**数据标准化**
数据标准化涉及将数据转换为具有相同范围或分布的形式。这有助于消除数据中的偏差和异常值,并使数据更易于比较和分析。
**代码块:**
```python
# 对 "age" 列进行标准化
df["age_std"] = (df["age"] - df["age"].mean()) / df["age"].std()
# 对 "salary" 列进行标准化
df["salary_std"] = (df["salary"] - df["salary"].mean()) / df["salary"].std()
```
**逻辑分析:**
* 标准化公式为 `(x - μ) / σ`,其中 `x` 是数据值,`μ` 是均值,`σ` 是标准差。
* `age_std` 和 `salary_std` 列表示了每个数据点与相应均值的标准差偏差。
### 2.1.2 缺失值处理和插补
**缺失值处理**
缺失值处理涉及识别和处理数据集中缺失的值。缺失值可能是由于各种原因造成的,例如数据收集错误或传感器故障。
**代码块:**
```python
# 识别缺失值
df.isnull().sum()
# 删除缺失值
df.dropna()
# 填充缺失值
df["age"].fillna(df["age"].mean(), inplace=True)
```
**逻辑分析:**
* `isnull()` 方法返回一个布尔值 DataFrame,其中 `True` 表示缺失值。
* `sum()` 方法计算每个列中缺失值的个数。
* `dropna()` 方法删除所有包含缺失值的列或行。
* `fillna()` 方法用指定的值(在本例中为均值)填充缺失值。
**缺失值插补**
缺失值插补涉及使用统计方法估计缺失值。这对于保留数据中的信息并避免因缺失值而导致偏差至关重要。
**代码块:**
```python
# 使用均值插补缺失值
df["age"].fillna(df["age"].mean(), inplace=True)
# 使用中位数插补缺失值
df["salary"].fillna(df["salary"].median(), inplace=True)
```
**逻辑分析:**
* 均值插补用缺失值的均值来填充缺失值。
* 中位数插补用缺失值的中位数来填充缺失值。
# 3. 数据预处理实践
### 3.1 Python中的数据预处理库
#### 3.1.1 NumPy和Pandas简介
NumPy和Pandas是Python中用于数据处理和分析的两个强大的库。NumPy提供了一个多维数组对象,用于高效地存储和操作数值数据,而Pandas提供了一个数据框对象,用于存储和操作具有行和列结构的表格数据。
**NumPy**
* **ndarray:** NumPy的核心数据结构,是一个多维数组,可以存储各种数据类型,如整数、浮点数和布尔值。
* **数学运算:** NumPy提供了一系列数学运算,包括加法、减法、乘法、除法和指数。
* **线性代数:** NumPy支持线性代数运算,如矩阵乘法、求逆和特征值分解。
**Pandas**
* **DataFrame:** Pandas的核心数据结构,是一个表格数据结构,由行和列组成。
* **数据操作:** Pandas提供了一系列数据操作函数,如过滤、排序、分组和聚合。
* **数据合并:** Pandas可以轻松地合并来自不同来源的数据集,并基于共同的键进行连接。
#### 3.1.2 数据操作和转换
NumPy和Pandas提供了广泛的数据操作和转换功能,包括:
* **类型转换:** 将数据从一种类型转换为另一种类型,如整数转换为浮点数。
* **缺失值处理:** 处理缺失值,如删除缺失值或用均值或中位数填充缺失值。
* **数据标准化:** 将数据缩放到一个统一的范围,以提高模型的性能。
* **数据分箱:** 将连续数据划分为离散的箱,以简化分析和建模。
### 3.2 数据预处理管道构建
#### 3.2.1 数据预处理步骤的组织
数据预处理管道是一个有序的步骤序列,用于将原始数据转换为模型训练所需的格式。管道组织有助于确保数据预处理过程的可重复性和可维护性。
**管道步骤:**
* **数据加载:** 从各种来源加载数据。
* **数据清洗:** 处理缺失值、异常值和数据类型转换。
* **特征工程:** 选择和转换特征,以提高模型性能。
* **数据转换:** 将数据转换为模型训练所需的格式。
#### 3.2.2 管道优化和并行化
为了提高数据预处理管道的效率,可以采用以下优化和并行化技术:
* **向量化操作:** 使用NumPy和Pandas的向量化操作,同时对多个数据元素执行操作。
* **多线程处理:** 将数据预处理任务并行化到多个线程,以充分利用多核CPU。
* **分布式处理:** 在集群或云环境中分布数据预处理任务,以处理大数据集。
**代码示例:**
```python
import numpy as np
import pandas as pd
# 创建一个NumPy数组
arr = np.array([1, 2, 3, 4, 5])
# 创建一个Pandas数据框
df = pd.DataFrame({'name': ['John', 'Mary', 'Bob'], 'age': [20, 25, 30]})
# 使用NumPy进行数学运算
print(arr + 1) # 加法
# 使用Pandas进行数据操作
print(df.head(2)) # 显示前两行
print(df.groupby('age').mean()) # 按年龄分组并求均值
```
# 4. 数据预处理进阶应用**
**4.1 自然语言处理中的数据预处理**
自然语言处理(NLP)任务通常涉及处理大量文本数据,因此数据预处理在NLP中至关重要。
**4.1.1 文本分词和词干化**
* **文本分词:**将文本分解为单个单词或词组。
* **词干化:**将单词还原为其基本形式,例如将“running”还原为“run”。
```python
import nltk
# 文本分词
text = "Natural language processing is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human (natural) languages."
tokens = nltk.word_tokenize(text)
print(tokens)
# 词干化
stemmer = nltk.stem.PorterStemmer()
stemmed_tokens = [stemmer.stem(token) for token in tokens]
print(stemmed_tokens)
```
**4.1.2 文本特征提取和表示**
* **词袋模型:**将文本表示为单词出现频率的向量。
* **TF-IDF:**一种加权词袋模型,考虑单词在文本和语料库中的频率。
```python
from sklearn.feature_extraction.text import CountVectorizer
# 词袋模型
vectorizer = CountVectorizer()
X = vectorizer.fit_transform([text])
print(X.toarray())
# TF-IDF
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer()
X_tfidf = transformer.fit_transform(X)
print(X_tfidf.toarray())
```
**4.2 图像处理中的数据预处理**
图像处理任务通常涉及处理大量图像数据,因此数据预处理在图像处理中也很重要。
**4.2.1 图像增强和降噪**
* **图像增强:**改善图像的对比度、亮度和其他属性。
* **降噪:**去除图像中的噪声。
```python
import cv2
# 图像增强
image = cv2.imread("image.jpg")
enhanced_image = cv2.equalizeHist(image)
cv2.imshow("Enhanced Image", enhanced_image)
cv2.waitKey(0)
# 降噪
denoised_image = cv2.fastNlMeansDenoising(image)
cv2.imshow("Denoised Image", denoised_image)
cv2.waitKey(0)
```
**4.2.2 图像特征提取和分类**
* **图像特征提取:**从图像中提取描述性特征。
* **图像分类:**将图像分类到不同的类别。
```python
import numpy as np
# 图像特征提取
features = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
# 图像分类
from sklearn.svm import SVC
classifier = SVC()
classifier.fit(features, [0, 1, 2])
```
# 5. 数据预处理最佳实践
### 5.1 数据预处理的自动化和可重复性
#### 5.1.1 数据预处理脚本和工作流
* 使用脚本语言(如 Python 或 R)编写数据预处理代码,以实现自动化和可重复性。
* 创建可重用的函数和模块,以封装常见的预处理任务。
* 使用工作流管理工具(如 Apache Airflow 或 Luigi)编排数据预处理步骤,实现端到端的自动化。
#### 5.1.2 版本控制和协作
* 使用版本控制系统(如 Git)跟踪数据预处理代码和脚本的更改。
* 鼓励团队协作,通过代码审查和合并请求确保代码质量。
* 建立清晰的版本控制策略,以管理不同版本的代码和数据。
### 5.2 数据预处理的性能优化
#### 5.2.1 数据结构和算法选择
* 选择合适的 Python 数据结构,如 NumPy 数组或 Pandas 数据框,以优化数据处理速度。
* 使用高效的算法,如 NumPy 的广播机制或 Pandas 的向量化操作。
#### 5.2.2 云计算和分布式处理
* 利用云计算平台(如 AWS 或 Azure)提供的大规模计算资源。
* 使用分布式处理框架(如 Apache Spark 或 Dask)并行化数据预处理任务,提高处理速度。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了一份全面的数据预处理指南,涵盖了从入门到精通的各个方面。它揭示了数据预处理的关键步骤,指导读者掌握数据预处理的艺术,为机器学习和数据分析做好数据准备。专栏深入探讨了数据预处理中的常见挑战和解决方案,并介绍了提升数据质量和模型性能的最佳实践。此外,它还介绍了自动化数据预处理的技术,以及特征工程、缺失值处理、异常值处理、数据转换、数据标准化、数据归一化、数据抽样、数据清洗、数据集成、数据探索、数据验证、数据可视化和数据文档等关键主题。专栏还讨论了大数据挑战,为处理大数据集中的数据预处理问题提供了见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【软件管理系统设计全攻略】:从入门到架构的终极指南
# 摘要
随着信息技术的飞速发展,软件管理系统成为支持企业运营和业务创新的关键工具。本文从概念解析开始,系统性地阐述了软件管理系统的需求分析、设计、数据设计、开发与测试、部署与维护,以及未来的发展趋势。重点介绍了系统需求分析的方法论、系统设计的原则与架构选择、数据设计的基础与高级技术、以及质量保证与性能优化。文章最后
【硬盘修复的艺术】:西数硬盘检测修复工具的权威指南(全面解析WD-L_WD-ROYL板支持特性)

# 摘要
本文深入探讨了硬盘修复的基础知识,并专注于西部数据(西数)硬盘的检测修复工具。首先介绍了西数硬盘的内部结构与工作原理,随后阐述了硬盘故障的类型及其原因,包括硬件与软件方面的故障。接着,本文详细说明了西数硬盘检测修复工具的检测和修复理论基础,以及如何实践安装、配置和
【sCMOS相机驱动电路信号完整性秘籍】:数据准确性与稳定性并重的分析技巧

# 摘要
本文针对sCMOS相机驱动电路信号完整性进行了系统的研究。首先介绍了信号完整性理论基础和关键参数,紧接着探讨了信号传输理论,包括传输线理论基础和高频信号传输问题,以及信号反射、串扰和衰减的理论分析。本文还着重分析了电路板布局对信号完整性的影响,提出布局优化策略以及高速数字电路的布局技巧。在实践应用部分,本文提供了信号完整性测试工具的选择,仿真软件的应用,
能源转换效率提升指南:DEH调节系统优化关键步骤
# 摘要
能源转换效率对于现代电力系统至关重要,而数字电液(DEH)调节系统作为提高能源转换效率的关键技术,得到了广泛关注和研究。本文首先概述了DEH系统的重要性及其基本构成,然后深入探讨了其理论基础,包括能量转换原理和主要组件功能。在实践方法章节,本文着重分析了DEH系统的性能评估、参数优化调整,以及维护与故障排除策略。此外,本文还介绍了DEH调节系统的高级优化技术,如先进控制策略应用、系统集成与自适应技术,并讨论了节能减排的实现方法。最后,本文展望了DEH系统优化的未来趋势,包括技术创新、与可再生能源的融合以及行业标准化与规范化发展。通过对DEH系统的全面分析和优化技术的研究,本文旨在为提
【AT32F435_AT32F437时钟系统管理】:精确控制与省电模式

# 摘要
本文系统性地探讨了AT32F435/AT32F437微控制器中的时钟系统,包括其基本架构、配置选项、启动与同步机制,以及省电模式与能效管理。通过对时钟系统的深入分析,本文强调了在不同应用场景中实现精确时钟控制与测量的重要性,并探讨了高级时钟管理功能。同时,针对时钟系统的故障预防、安全机制和与外围设备的协同工作进行了讨论。最后,文章展望了时
【MATLAB自动化脚本提升】:如何利用数组方向性优化任务效率
# 摘要
本文深入探讨MATLAB自动化脚本的构建与优化技术,阐述了MATLAB数组操作的基本概念、方向性应用以及提高脚本效率的实践案例。文章首先介绍了MATLAB自动化脚本的基础知识及其优势,然后详细讨论了数组操作的核心概念,包括数组的创建、维度理解、索引和方向性,以及方向性在数据处理中的重要性。在实际应用部分,文章通过案例分析展示了数组方向性如何提升脚本效率,并分享了自动化
现代加密算法安全挑战应对指南:侧信道攻击防御策略
# 摘要
侧信道攻击利用信息泄露的非预期通道获取敏感数据,对信息安全构成了重大威胁。本文全面介绍了侧信道攻击的理论基础、分类、原理以及实际案例,同时探讨了防御措施、检测技术以及安全策略的部署。文章进一步分析了侧信道攻击的检测与响应,并通过案例研究深入分析了硬件和软件攻击手段。最后,本文展望了未来防御技术的发展趋势,包括新兴技术的应用、政策法规的作用以及行业最佳实践和持续教育的重要性。
# 关键字
侧信道攻击;信息安全;防御措施;安全策略;检测技术;防御发展趋势
参考资源链接:[密码编码学与网络安全基础:对称密码、分组与流密码解析](https://wenku.csdn.net/doc/64
【科大讯飞语音识别技术完全指南】:5大策略提升准确性与性能

# 摘要
本论文综述了语音识别技术的基础知识和面临的挑战,并着重分析了科大讯飞在该领域的技术实践。首先介绍了语音识别技术的原理,包括语音信号处理基础、自然语言处理和机器学习的应用。随
【现场演练】:西门子SINUMERIK测量循环在多样化加工场景中的实战技巧
# 摘要
本文旨在全面介绍西门子SINUMERIK测量循环的理论基础、实际应用以及优化策略。首先概述测量循环在现代加工中心的重要作用,继而深入探讨其理论原理,包括工件测量的重要性、测量循环参数设定及其对工件尺寸的影响。文章还详细分析了测量循环在多样化加工场景中的应用,特别是在金属加工和复杂形状零件制造中的挑战,并提出相应的定制方案和数据处理方法。针对多轴机床的测量循环适配,探讨了测量策略和同步性问题。此外,本文还探讨了测量循环的优化方法、提升精确度的技巧,以及西门子SINUMERIK如何融合新兴测量技术。最后,本文通过综合案例分析与现场演练,强调了理论与实践的结合,并对未来智能化测量技术的发展
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )