Landsat8数据分类大揭秘:监督与非监督算法的深度对比
发布时间: 2025-01-06 20:12:21 阅读量: 14 订阅数: 19 
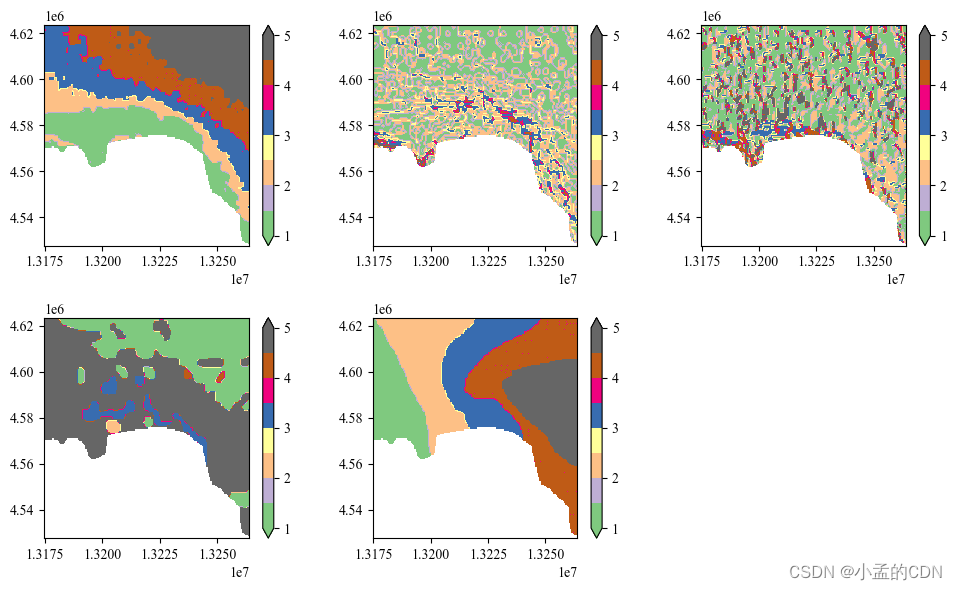
# 摘要
随着遥感技术的发展,Landsat 8数据已成为重要的地表覆盖分析资源。本文详细探讨了监督和非监督分类算法,深入分析了各种算法的基本概念、关键技术和实践应用。通过对最大似然分类、支持向量机分类、决策树分类以及K-均值聚类、层次聚类、密度聚类等关键算法的讨论,文章比较了这些算法在分类准确率和计算效率上的性能差异,并分析了它们在不同应用场景中的适用性。此外,本文还展望了机器学习、深度学习在遥感图像分类中的未来应用,以及数据融合技术和分类算法智能化、自动化的发展趋势,并讨论了面临的技术挑战及相应的解决策略。
# 关键字
Landsat8数据;监督分类;非监督分类;最大似然分类;支持向量机;深度学习
参考资源链接:[Landsat8 OLI数据处理步骤详解](https://wenku.csdn.net/doc/1pgfn781zc?spm=1055.2635.3001.10343)
# 1. Landsat8数据概述
## 1.1 Landsat8卫星简介
Landsat8是美国地质调查局(USGS)与NASA合作发射的地球观测卫星,它的任务是继续进行陆地表面成像,提供连续的数据记录以支持科学研究和技术应用。Landsat8继承并改进了其前身Landsat系列卫星的功能,增加了更多的传感器和新的波段,使得其数据具有更高的质量和应用价值。
## 1.2 Landsat8数据的特点
Landsat8携带了两个主要传感器:陆地成像仪(Operational Land Imager, OLI)和热红外传感器(Thermal Infrared Sensor, TIRS)。OLI数据具有9个波段,包括可见光、近红外和短波红外波段,而TIRS提供2个波段用于测量地表热辐射。该卫星的数据具有高空间分辨率和良好的光谱分辨率,使其成为全球土地覆盖和变化监测的理想选择。
## 1.3 Landsat8数据的应用领域
Landsat8数据广泛应用于农业、林业、城市规划、水资源管理、灾害监测和环境科学研究等领域。它不仅帮助研究人员监测和评估地球表面的长期变化,还能为各种管理决策提供实时的数据支持。因此,理解Landsat8数据的基本特性和应用对于环境监测和资源管理具有重要意义。
# 2. 监督分类算法详解
### 2.1 监督分类基本概念
#### 2.1.1 分类算法的定义与重要性
分类算法是遥感影像分析中的一种重要技术,它通过对影像的像素进行类别划分,将复杂的空间数据转化为人类可理解的结构化信息。监督分类算法需要训练数据集作为参考,通过这些数据集学习地表特征,然后将学习到的信息应用到整个影像数据中进行分类。监督分类在土地覆盖类型识别、资源勘探、农业监测、城市规划等多个领域中有着广泛的应用,因为其高精度和可解释性,成为了研究的热点和应用的首选。
#### 2.1.2 监督分类与非监督分类的区别
监督分类和非监督分类是遥感影像分类的两大主流方法。监督分类依赖于已知的地表覆盖类型训练样本,通过机器学习算法对样本进行学习后,对未知样本进行类别预测;而非监督分类不依赖于事先标记好的样本,而是根据影像本身的统计特性进行聚类。区别于监督分类,非监督分类更侧重于探索数据内在结构和模式,但往往缺乏明确的分类含义,导致应用范围受限。
### 2.2 监督分类的关键算法
#### 2.2.1 最大似然分类
最大似然分类(Maximum Likelihood Classification, MLC)是一种基于概率的监督分类方法,它假定每个类别的数据符合正态分布,并根据这个概率模型来计算给定像素属于某一类的概率,最后将像素分配给概率最大的类别。
在MLC中,每个类别的均值和协方差矩阵是必需的统计参数。实施最大似然分类时,我们需要获取训练样本集的统计数据,并基于这些数据对整个影像进行分类。算法的实现通常涉及到复杂的数学运算和优化过程。
```python
from sklearn.mixture import GaussianMixture
from sklearn.preprocessing import StandardScaler
import numpy as np
import rasterio
# 假设img为加载好的影像数据,classes为训练样本标签,samples为对应的特征样本
# 标准化特征样本
scaler = StandardScaler()
samples_scaled = scaler.fit_transform(samples)
# 使用高斯混合模型实现最大似然分类
gmm = GaussianMixture(n_components=3, covariance_type='full')
gmm.fit(samples_scaled)
# 对影像数据进行分类
labels = gmm.predict(img.reshape(-1, img.shape[-1]))
labels = labels.reshape(img.shape[:2])
# 保存分类结果
with rasterio.open('classified_image.tif', 'w', **img.profile) as dst:
dst.write(labels.astype(rasterio.uint8))
```
在上述代码中,我们首先加载了影像数据和样本标签,并对样本特征进行了标准化处理。然后使用`sklearn`中的`GaussianMixture`模型以高斯分布的形式来模拟每类地物的概率密度函数。最后,我们用模型对整个影像进行分类,并将结果保存为新的影像文件。
#### 2.2.2 支持向量机分类
支持向量机(Support Vector Machine, SVM)是一种强大的监督学习方法,在分类问题上表现出色。SVM通过寻找最佳超平面来区分不同的类别,并能处理非线性可分的情况。
SVM的分类性能很大程度上取决于所选的核函数,常用的核函数包括线性核、多项式核、径向基函数(RBF)核等。对于遥感影像分类,RBF核因其出色的表现而常用。
```python
from sklearn import svm
from sklearn.model_selection import train_test_split
# 假设X为特征数据,y为对应的类别标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建SVM分类器
clf = svm.SVC(gamma='scale')
# 训练模型
clf.fit(X_train, y_train)
# 模型预测
y_pred = clf.predict(X_test)
```
在上述代码段中,我们首先将数据集划分为训练集和测试集,然后创建了一个SVM分类器并用训练集进行训练。训练完成后,我们使用模型对测试集进行了预测。
#### 2.2.3 决策树分类
决策树是一种常见的机器学习算法,它通过一系列规则将数据分割,形成树状的决策结构。在决策树中,每个内部节点代表一个属性上的判断,每个分支代表一个判断结果的输出,而每个叶节点代表一种分类结果。
决策树具有很好的解释性,易于理解和可视化。其分类过程非常直观,符合人类的决策思维,适用于多种类型的分类问题。
```python
from sklearn.tree import DecisionTreeClassifier
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 训练模型
clf.fit(X_train, y_train)
# 模型预测
y_pred = clf.predict(X_test)
```
在上述代码中,我们创建了一个决策树分类器,并使用训练数据集对其进行训练。一旦模型被训练,我们就可以使用它来预测测试数据集的类别。
### 2.3 监督分类实践应用
#### 2.3.1 Landsat8数据的预处理
在使用监督分类算法处理Landsat8影像数据之前,需要先进行必要的预处理。预处理主要包括大气校正、云雾掩膜、去除噪声等步骤。这些步骤的目的是去除或降低影像中不利于分类的元素,以提高分类精度。
大气校正是去除大气对遥感影像影响的过程,是确保分类准确性的关键步骤。云雾掩膜则是移除影像中的云和雾影响区域,这些区域往往导致分类结果不准确。
#### 2.3.2 算法实现与结果评估
实施监督分类算法后,得到的结果需要通过一系列评估步骤来验证其准确性。评估过程通常包括混淆矩阵、总体精度、Kappa系数等指标的计算。混淆矩阵是一种有效的评估分类准确性的方法,它通过真实值和预测值的对比,直观地展示分类效果。
```python
from sklearn.metrics import confusion_matrix, classification_report
# 假设真实标签为y_true,预测标签为y_pred
cm = confusion_matrix(y_true, y_pred)
print(cm)
report = classification_report(y_true, y_pred)
print(report)
```
在上面的代码中,我们使用`sklearn`的`confusion_matrix`函数和`classification_report`函数分别得到了混淆矩阵和分类报告,它们为我们提供了详细的分类性能评估。
# 3. 非监督分类算法详解
### 3.1 非监督分类基本概念
#### 3.1.1 算法原理与适用场景
非监督分类算法是利用数据集中的信息,识别出数据的内在结构和模式,而不是依赖于预先定义的标签或类。与监督分类相比,非监督分类不需要大量的标记数据,因此,在标记数据稀缺的情况下表现出其独特的优势。
- **算法原理**:非监督学习通常依赖于数据自身的分布特性。聚类是最常见的非监督学习任务,其目的是将数据对象根据相似性分成若干个类别或簇。
- **适用场景**:非监督分类适用于探索性数据分析和模式识别。例如,在遥感图像处理中,可用于初步的图像分割和特征提取,为后续的监督分类或目标检测提供基础。
非监督分类算法的关键是其能够从数据中发现隐藏的结构,它不依赖于标签信息,因此在处理未知或未标记数据时显得尤为有用。
#### 3.1.2 数据聚类基础
数据聚类是将数据集合划分为多个由相似数据点组成的簇的过程。这使得数据的组织结构更加清晰,便于分析。聚类技术是研究数据分布的重要工具,也是非监督学习的核心技术之一。
- **聚类方法**:常用的方法包括K-均值聚类、层次聚类、DBSCAN和谱聚类等。
- **评估聚类效果**:聚类效果的好坏通常用轮廓系数(Silhouette Coefficient)、Calinski-Harabasz指数等指标来评估。
聚类分析在遥感数据处理中的应用不仅限于图像分类,还可以用于检测图像中的异常值、图像分割以及数据降维等。
### 3.2 非监督分类的关键算法
#### 3.2.1 K-均值聚类
K-均值是一种广泛使用的聚类算法,其目的是将数据集划分为K个簇。算法将随机选择K个数据点作为初始簇心,然后通过迭代过程将数据点分配到最近的簇心。
```python
from sklearn.cluster import KMeans
import numpy as np
# 假设X是
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Landsat8数据处理详细流程》专栏深入探讨了Landsat8卫星数据的处理技术,从入门到精通,提供实用技巧和黄金法则。该专栏涵盖了从数据预处理、大气校正、云层检测到图像融合、数据分类和热红外波段应用等各个方面。此外,还提供了农业监测、水体监测、森林覆盖变化分析和海洋研究等应用案例,以及数据处理常见问题解答和自动化指南。本专栏旨在帮助读者掌握Landsat8数据处理的全面知识和技能,提升地物识别能力,探索植被动态,保护水域资源,并深入了解海洋和湖泊的奥秘。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【单片机LED驱动秘籍】:10个步骤构建高效电路
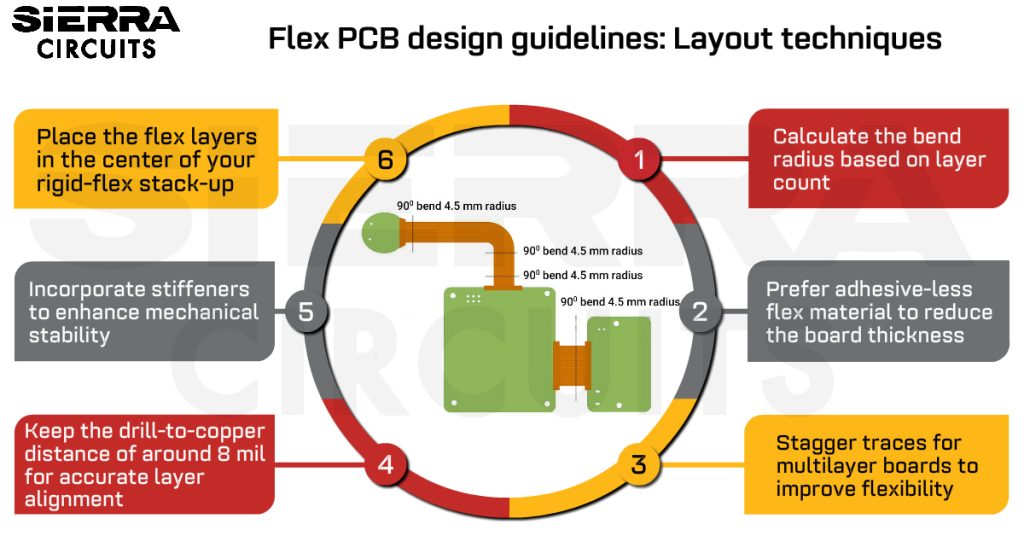
# 摘要
随着技术的不断进步,单片机在LED驱动领域中的应用变得日益广泛。本文旨在概述单片机驱动LED的基本概念、工作原理和接口方式,并深入探讨了单片机编程基础和LED驱动电路设计原则。通过实践操作的详细说明,包括单片机选择、硬件电路搭建及软件程序编写,本文着重于构建高效稳定的LED驱动电路,并展示PW
奥迪Q5_SQ5车载娱乐系统:技术优化策略提升用户体验
# 摘要
本文对奥迪Q5与SQ5车载娱乐系统进行了深入探讨,从技术基础、用户体验优化理论、实践优化措施以及案例研究与效果评估四个方面进行详细分析。技术基础部分涵盖了车载娱乐系统的架构、通信技术和用户界面设计原则。用户体验优化理论部分探讨了用户体验的定义、重要性、用户研究方法和设计原则。实践优化措施部分则具体到奥迪Q5与SQ5的界面与交互、系统性能和定制化功能的改进。案例研究与效果评估部分通过用户反馈分析和优化策略实施案例,展示了如何通过持续评估与反馈循环进行系统优化。最后,本文预测了车载娱乐系统的智能化、安全性与隐私保护以及持续学习与自我优化的未来趋势。
# 关键字
车载娱乐系统;用户体验;
【曲线曲率分析与产品设计】:10个案例研究揭示最佳实践
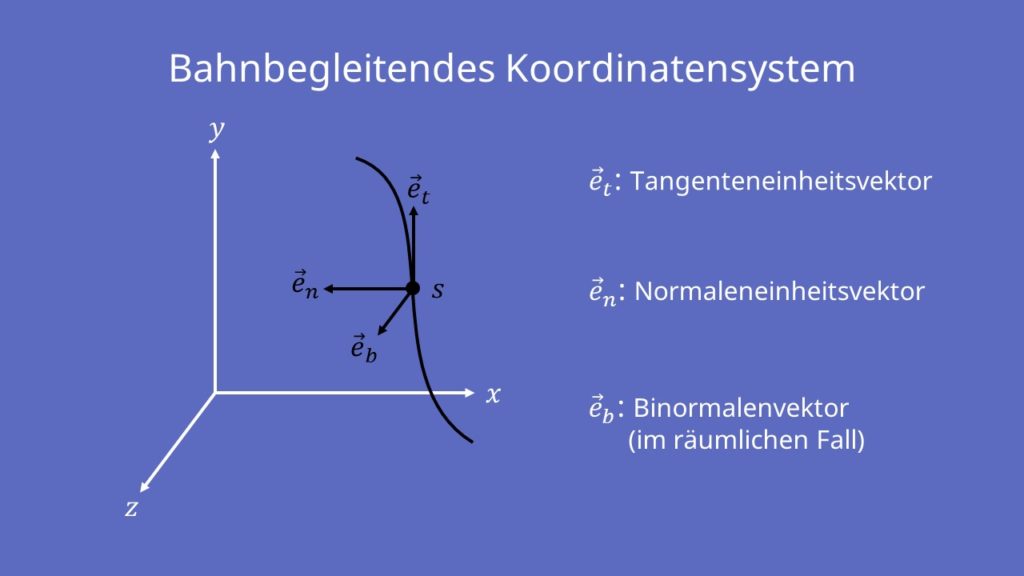
# 摘要
本文详细探讨了曲线曲率分析的基础知识及其在设计领域的重要性,包括曲率的数学理论基础、在产品设计中的实践案例,以及曲率分析工具和技术的进阶应用。文章通过工业设计、建筑设计和用户界面设计等不同领域的案例,分析了曲率分析的实际应用和优化策略。同时,本文还探讨了三维建模软件中的曲率分析工具,曲率分析算法的发展,以及人工智能和新型材料中曲率分析的创新应用。最后
构建智能温控系统:MCP41010项目实战指南

# 摘要
本文综合介绍了智能温控系统的构成、工作原理及其软件设计。首先对MCP41010数字电位器和温度传感器的特性和应用进行了详细阐述,然后深入探讨了智能温控系统软件设计中的控制算法、程序编写与用户界面设计。接着,本文通过实践操作部分展
【微信小程序云开发深度解析】:无服务器架构下的高效后端处理技术
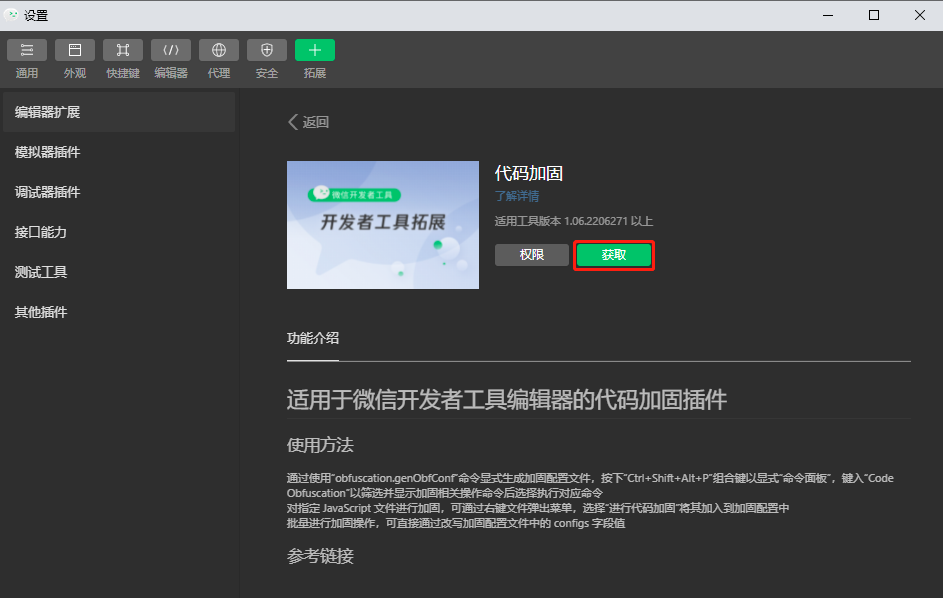
# 摘要
微信小程序云开发作为一种新兴的无服务器架构应用,结合了微信生态系统的便捷性和云技术的强大能力,极大地降低了开发者的门槛。本文首先概述了微信小程序云开发的基本概念和搭建环境的步骤,然后深入探讨了其理论基础,包括无服务器架构的技术原理、数据管理和网络能力。接着,本文通过实践应用章节,详细
【三维设计基础入门】:机械制图与三视图的奥秘

# 摘要
本文系统地介绍了三维设计与机械制图的基本概念、技巧及应用。首先概述了三视图的基本原理,包括其定义、作用以及在机械制图中的重要性。接着,深入探讨了从三视图到三维模型的转换技巧,涵盖了二维草图绘制、模型构建和工程图转换的各个方面。文章进一步分析了三视图在机械设计中的具体应用,包括设计流程、零件与装配图的绘制,以及错误
NET.VB_TCPIP性能优化秘籍:提升通信效率的5大策略

# 摘要
随着互联网应用的不断扩展,.NET VB应用程序在TCPIP通信方面的性能优化显得尤为重要。本文系统地探讨了.NET VB中的TCPIP通信原理,分析了数据传输、连接管理、资源分配等多个关键方面的优化策略。通过提升TCP连接效率、优化数
【SCPI命令进阶宝典】:解决10大SCPI命令执行问题的解决方案

# 摘要
本文全面探讨了SCPI(Standard Commands for Programmable Instruments)命令的各个方面,从基础概念、语法解析、执行问题诊断与解决,到高级应用技巧,以及在自动化测试中的应用,最终展望了其未来发展趋势。SCPI命令是自动化
【深入STM32CubeMX】:性能优化与高级设置技巧
# 摘要
STM32CubeMX作为一款高效的STM32微控制器配置工具,为开发者提供了一站式的硬件抽象层和中间件初始化配置,极大简化了基于STM32的项目开发流程。本文旨在系统地概述STM32CubeMX的核心功能,并深入探讨性能优化策略,包括时钟树和电源管理优化、代码生成及内存管理的最佳实践,以及调试和诊断技巧。同时,文章还将介绍高级配置技巧,如中断管理、外设配置
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )