Django ORM秘籍:揭秘models.sql模块的内部工作机制
发布时间: 2024-10-17 02:08:35 阅读量: 21 订阅数: 15 

# 1. Django ORM和models.sql模块概述
在本章中,我们将初步介绍Django ORM和`models.sql`模块的概念及其在现代Web开发中的重要性。Django作为一个高级的Python Web框架,它的ORM(Object-Relational Mapping)系统为开发者提供了与数据库交互的强大抽象层,使得数据库操作更为直观和高效。`models.sql`模块是Django ORM中不可或缺的一部分,它负责将Django定义的模型(Model)映射到数据库的表结构,并提供了迁移和数据库结构生成的能力。
在接下来的章节中,我们将深入探讨`models.sql`模块的理论基础和实践操作,帮助读者全面掌握其使用方法、高级特性以及进阶应用,从而在项目开发中更好地利用这一强大的工具。
## 2.1 Django ORM的基本原理
### 2.1.1 ORM的定义和优势
ORM是“对象关系映射”(Object-Relational Mapping)的缩写,它是一种编程技术,用于在不同的系统之间转换数据。在Django中,ORM允许开发者使用Python对象的方式来操作数据库,而不需要直接编写SQL语句。
ORM的主要优势包括:
- **抽象数据库操作**:开发者不需要编写复杂的SQL代码,可以直接通过Python代码操作数据库。
- **数据库无关性**:ORM提供了数据库抽象层,使得底层数据库的更换对业务逻辑影响最小。
- **代码可维护性**:使用ORM编写的代码通常更易于理解和维护。
## 2.2 Django ORM的工作流程
### 2.2.1 Django ORM的工作流程
Django ORM的工作流程大致可以分为以下几个步骤:
1. 定义模型(Model):在Django应用中定义数据模型,ORM会自动将其转换为数据库表。
2. 数据库迁移(Migrations):使用`manage.py migrate`命令,Django会创建或更新数据库表结构。
3. 数据操作:通过ORM API进行数据的增删改查(CRUD)操作。
4. 数据库交互:ORM将操作转换为对应的SQL语句并执行。
了解这些基本概念和工作流程,将为接下来深入学习`models.sql`模块打下坚实的基础。
# 2. models.sql模块的理论基础
## 2.1 Django ORM的基本原理
### 2.1.1 ORM的定义和优势
在本章节中,我们将深入探讨Django ORM的基本原理,首先是ORM(Object-Relational Mapping)的定义和它带来的优势。ORM是一种技术,用于在不同的系统之间转换数据。它在关系型数据库和对象之间提供了一个概念性的映射,使得开发者可以用面向对象的方式来操作数据库。
ORM的主要优势在于它提供了一个抽象层,允许开发者不用直接写SQL语句就能进行数据库操作。这样的抽象层简化了数据库操作,提高了开发效率,同时也使得代码更加清晰和易于维护。此外,ORM还帮助开发者避免了SQL注入等安全问题,因为ORM框架会自动处理参数的转义和引用。
### 2.1.2 Django ORM的工作流程
Django ORM的工作流程是本章节的重点。Django ORM的核心是将Python中的类映射到数据库中的表。每个数据库表对应一个模型类,类的属性对应表的列。通过定义模型类,开发者可以创建、查询、更新和删除数据库中的记录。
工作流程大致如下:
1. **模型定义**:在`models.py`文件中定义模型类,Django ORM自动将这些类映射到数据库表。
2. **迁移操作**:使用`manage.py`工具生成数据库迁移文件,将模型类的变更同步到数据库结构中。
3. **数据库操作**:通过模型类实例进行CRUD操作,Django ORM自动将这些操作转换为对应的SQL语句。
这个流程使得开发者可以用Python代码来操作数据库,而不需要编写SQL语句,从而提高了开发效率和代码的可读性。
## 2.2 models.sql模块的结构和作用
### 2.2.1 models.sql模块的组成
在本章节中,我们将探讨`models.sql`模块的组成。`models.sql`模块是Django ORM中用于操作数据库的核心组件之一。它主要负责生成SQL语句,用于数据库的创建、修改和同步。
`models.sql`模块主要包含以下几个组件:
- **SQLGeneration**:负责生成创建和修改数据库表的SQL语句。
- **SQLDelete**:负责生成删除记录的SQL语句。
- **SQLInsert**:负责生成插入新记录的SQL语句。
- **SQLUpdate**:负责生成更新记录的SQL语句。
这些组件共同协作,使得Django ORM可以透明地处理数据库操作。
### 2.2.2 models.sql模块的作用和重要性
本章节将重点介绍`models.sql`模块的作用和重要性。`models.sql`模块在Django项目中扮演着至关重要的角色。它负责将模型类的定义转换为数据库的SQL语句,使得开发者可以专注于业务逻辑的实现,而不需要深入了解数据库的具体实现。
`models.sql`模块的主要作用包括:
- **自动化数据库操作**:自动生成创建、修改和删除数据库表的SQL语句。
- **维护数据一致性**:确保数据库结构与模型类定义的一致性。
- **提供抽象层**:隐藏数据库的具体操作细节,简化开发过程。
`models.sql`模块的重要性体现在它为开发者提供了一个高层次的数据库操作接口,大大提高了开发效率和代码的可维护性。
## 2.3 models.sql模块与数据库的交互
### 2.3.1 数据库连接和配置
在本章节中,我们将探讨`models.sql`模块如何与数据库进行连接和配置。数据库的配置是Django项目设置中至关重要的一环,它决定了数据如何被存储和访问。
Django使用数据库连接池来管理数据库连接,这样可以减少连接和关闭数据库连接的开销。数据库连接池通过配置文件`settings.py`中的`DATABASES`设置来实现。
一个典型的数据库配置示例如下:
```python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.sqlite3',
'NAME': BASE_DIR / 'db.sqlite3',
}
}
```
在这个配置中,我们定义了默认的数据库引擎为`django.db.backends.sqlite3`,数据库文件名为`db.sqlite3`。
### 2.3.2 数据库操作的执行过程
数据库操作的执行过程是本章节的另一个重点。在Django中,当模型类被实例化并进行操作时,`models.sql`模块会将这些操作转换为对应的SQL语句,并通过数据库连接执行。
这个过程大致包括以下几个步骤:
1. **模型类实例化**:创建模型类的实例。
2. **操作转换**:将模型类的操作转换为SQL语句。
3. **SQL语句执行**:通过数据库连接执行SQL语句。
4. **结果处理**:将执行结果返回给模型类实例。
这个过程对于开发者来说是透明的,开发者只需要操作模型类实例,而不需要直接编写SQL语句。
```mermaid
graph LR
A[模型类实例化] --> B[操作转换]
B --> C[SQL语句执行]
C --> D[结果处理]
```
以上是一个简化的流程图,展示了从模型类实例化到结果处理的过程。
# 3. models.sql模块的实践操作
## 3.1 models.sql模块的使用方法
### 3.1.1 创建和修改数据库结构
在本章节中,我们将详细介绍如何使用`models.sql`模块来创建和修改数据库结构。`models.sql`模块是Django ORM中用于数据库迁移和数据同步的一个重要组成部分,它允许开发者通过Django的模型定义来控制数据库的结构,包括表的创建、修改和删除。
首先,我们需要了解`models.sql`模块的工作原理。当我们定义了模型类(`models.Model`)并执行迁移命令时,Django会根据模型类中定义的字段和属性生成相应的SQL语句,这些SQL语句将用于创建对应的数据库表。
下面是一个简单的示例,展示了如何定义一个模型类并使用`models.sql`模块来创建数据库表:
```python
# models.py
from django.db import models
class MyModel(models.Model):
name = models.CharField(max_length=100)
description = models.TextField()
```
```shell
# 迁移命令
python manage.py makemigrations
python manage.py migrate
```
执行上述命令后,Django会生成以下SQL语句:
```sql
CREATE TABLE "app_mymodel" (
"id" serial NOT NULL PRIMARY KEY,
"name" varchar(100) NOT NULL,
"description" text NOT NULL
);
```
这个过程可以通过查看迁移文件来验证,迁移文件通常位于每个应用的`migrations`目录下。
### 3.1.2 数据库迁移和数据同步
数据库迁移是Django ORM的核心功能之一,它允许开发者在模型变化时更新数据库结构,而无需手动编写SQL语句。`models.sql`模块在背后支持这个过程,通过生成和执行迁移文件来实现。
当模型类发生变化时,例如添加、删除字段或者更改字段属性,我们需要创建新的迁移文件。Django提供了一个`makemigrations`命令来自动化这个过程:
```shell
# 创建迁移文件
python manage.py makemigrations app_name
```
创建迁移文件后,我们可以使用`migrate`命令来应用迁移,从而更新数据库结构:
```shell
# 应用迁移
python manage.py migrate app_name
```
在迁移过程中,Django会记录迁移的历史,确保每次迁移都是可追踪和可回滚的。这使得数据库结构的管理变得非常灵活和可靠。
### 3.1.3 数据库迁移的高级应用
除了创建和修改表之外,`models.sql`模块还支持更复杂的数据库迁移操作,例如添加索引、更改表名或者字段名等。这些操作可以通过编写自定义迁移函数来实现。
例如,我们可能需要在`MyModel`模型上添加一个索引来加速查询。我们可以创建一个迁移文件并添加如下操作:
```python
# migrations/0002_add_index_to_mymodel.py
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('app_name', '0001_initial'),
]
operations = [
migrations.RunSQL(
"CREATE INDEX mymodel_name_idx ON app_name_mymodel (name);",
state_operations=[
migrations.AlterField(
model_name='mymodel',
name='name',
field=models.CharField(max_length=100, unique=True),
),
],
),
]
```
这个迁移操作首先执行一个原始的`CREATE INDEX` SQL语句来创建索引,然后使用`state_operations`参数来同步模型状态。
### 3.1.4 数据库同步的注意事项
在进行数据库迁移和同步时,有一些注意事项需要开发者牢记。首先,每次迁移都应该在开发环境中进行充分测试,确保迁移不会破坏现有的数据和功能。其次,生产环境的数据库迁移应该谨慎进行,确保有完整的数据备份和恢复计划。
此外,数据库迁移是一个不可逆的过程,一旦应用了迁移,就很难撤销。因此,开发者应该谨慎对待迁移操作,确保每次迁移都是必要的,并且遵循最佳实践。
### 3.1.5 数据库迁移的示例分析
让我们通过一个具体的示例来分析数据库迁移的过程。假设我们有一个用户模型`User`,现在需要添加一个新字段`age`。
首先,我们在模型中添加字段:
```python
# models.py
class User(models.Model):
name = models.CharField(max_length=100)
# 添加新字段
age = models.IntegerField(default=18)
```
然后,我们创建迁移文件:
```shell
# 创建迁移文件
python manage.py makemigrations app_name
```
生成的迁移文件可能如下所示:
```python
# migrations/0002_add_age_to_user.py
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('app_name', '0001_initial'),
]
operations = [
migrations.AddField(
model_name='user',
name='age',
field=models.IntegerField(default=18),
),
]
```
最后,我们应用迁移来更新数据库结构:
```shell
# 应用迁移
python manage.py migrate app_name
```
执行后,数据库中的`User`表将添加一个新列`age`。
### 3.1.6 数据库迁移的最佳实践
在进行数据库迁移时,有一些最佳实践可以帮助开发者更高效地管理数据库结构。首先,应该定期审查模型定义和数据库迁移文件,确保它们的整洁和一致性。其次,应该为每个迁移创建清晰的描述信息,以便未来的开发者理解迁移的目的和内容。
此外,应该尽量避免在生产环境中直接执行迁移操作,而是通过版本控制和自动化部署流程来管理迁移。这样可以确保迁移的可追溯性和可重复性。
通过遵循这些最佳实践,开发者可以更安全、更高效地使用`models.sql`模块来管理和维护数据库结构。
## 3.2 models.sql模块的高级特性
### 3.2.1 自定义数据库操作
`models.sql`模块不仅支持标准的迁移操作,还允许开发者执行自定义的数据库操作。这为开发者提供了强大的灵活性,可以处理更复杂的数据库交互。
例如,我们可以定义一个自定义迁移操作来添加或删除一个数据库触发器。以下是一个示例:
```python
# migrations/0003_add_trigger_to_mymodel.py
from django.db import migrations, models
class Migration(migrations.Migration):
dependencies = [
('app_name', '0002_add_age_to_user'),
]
operations = [
migrations.RunSQL(
sql="CREATE TRIGGER update_modified_time BEFORE UPDATE ON app_name_mymodel FOR EACH ROW EXECUTE FUNCTION update_modified_column();",
reverse_sql="DROP TRIGGER IF EXISTS update_modified_time ON app_name_mymodel;",
),
]
```
在这个示例中,我们定义了一个迁移操作来创建一个触发器,该触发器在`MyModel`表的记录更新时自动更新一个时间戳字段。
### 3.2.2 数据库事务处理
数据库事务是保证数据一致性和完整性的关键机制。在Django中,可以使用`models.sql`模块来控制事务的边界,确保迁移操作的原子性。
在Django迁移中,默认情况下,每个迁移操作都是在一个事务中执行的。这意味着如果迁移过程中发生错误,整个迁移会被回滚,数据库状态不会被部分更新。
如果你的迁移操作需要分阶段执行,并且希望在发生错误时只回滚当前阶段的操作,你可以使用`atomic`块来控制事务的边界:
```python
# migrations/0004阶段性迁移.py
from django.db import migrations
class Migration(migrations.Migration):
def forwards(self, schema_editor):
with schema_editor.connection.cursor() as cursor:
cursor.execute("ALTER TABLE app_name_mymodel ADD COLUMN new_column INT;")
# 假设这里发生错误,事务将被回滚
cursor.execute("ALTER TABLE app_name_mymodel ADD COLUMN another_new_column TEXT;")
def backwards(self, schema_editor):
with schema_editor.connection.cursor() as cursor:
cursor.execute("ALTER TABLE app_name_mymodel DROP COLUMN new_column;")
cursor.execute("ALTER TABLE app_name_mymodel DROP COLUMN another_new_column;")
operations = [
migrations.RunPython(forwards, backwards),
]
```
在这个示例中,我们定义了一个迁移操作,它尝试在一个事务中添加两个新列。如果其中一个操作失败,整个事务将被回滚,数据库状态不会受到影响。
### 3.2.3 数据库操作的执行逻辑
数据库迁移操作的执行逻辑需要仔细设计,以确保迁移的稳定性和效率。在Django中,可以通过编写自定义迁移函数来实现复杂的逻辑。
以下是一个示例,展示了如何编写一个自定义迁移函数来处理数据迁移:
```python
# migrations/0005数据迁移.py
from django.db import migrations, models
def forwards_data_migration(apps, schema_editor):
User = apps.get_model('app_name', 'User')
# 假设我们要为每个用户添加一个年龄字段
for user in User.objects.all():
user.age = 25 # 假设默认年龄为25
user.save()
def backwards_data_migration(apps, schema_editor):
User = apps.get_model('app_name', 'User')
for user in User.objects.all():
user.delete() # 删除用户记录
class Migration(migrations.Migration):
dependencies = [
('app_name', '0004阶段性迁移'),
]
operations = [
migrations.RunPython(forwards_data_migration, backwards_data_migration),
]
```
在这个示例中,我们定义了一个数据迁移操作,它会遍历所有用户记录,并为每个用户添加一个年龄字段。`forwards_data_migration`函数定义了正向迁移逻辑,而`backwards_data_migration`函数定义了回滚逻辑。
### 3.2.4 数据库迁移的事务边界分析
在数据库迁移过程中,事务边界的设计至关重要。正确地管理事务边界可以确保数据的一致性和迁移的可靠性。
Django迁移默认在一个事务中执行所有操作。这意味着如果迁移过程中发生错误,整个迁移会被回滚,数据库状态不会被部分更新。
有时,我们可能需要分阶段执行迁移操作,并且希望在发生错误时只回滚当前阶段的操作。这时,我们可以使用`atomic`块来控制事务的边界:
```python
# migrations/0006分阶段迁移.py
from django.db import migrations
class Migration(migrations.Migration):
def forwards(self, schema_editor):
with schema_editor.connection.cursor() as cursor:
cursor.execute("ALTER TABLE app_name_mymodel ADD COLUMN new_column INT;")
# 假设这里发生错误,事务将被回滚
cursor.execute("ALTER TABLE app_name_mymodel ADD COLUMN another_new_column TEXT;")
def backwards(self, schema_editor):
with schema_editor.connection.cursor() as cursor:
cursor.execute("ALTER TABLE app_name_mymodel DROP COLUMN new_column;")
cursor.execute("ALTER TABLE app_name_mymodel DROP COLUMN another_new_column;")
operations = [
migrations.RunPython(forwards, backwards),
]
```
在这个示例中,我们定义了一个迁移操作,它尝试在一个事务中添加两个新列。如果其中一个操作失败,整个事务将被回滚,数据库状态不会受到影响。
### 3.2.5 数据库迁移的常见问题分析
在进行数据库迁移时,开发者可能会遇到一些常见问题。理解这些问题的原因和解决方案对于确保迁移的顺利进行至关重要。
一个常见的问题是迁移过程中的数据丢失或损坏。这通常是由于不正确的迁移逻辑或者数据库操作的错误导致的。为了避免这种情况,开发者应该在开发和测试环境中充分测试迁移操作,并确保有完整的数据备份。
另一个常见问题是迁移的性能问题。随着数据库规模的增长,迁移操作可能会变得非常缓慢。为了优化迁移性能,开发者可以考虑以下策略:
1. 分批处理大量数据,而不是一次性迁移所有数据。
2. 使用数据库的批量操作API,例如`bulk_create`或`bulk_update`,以减少数据库交互次数。
3. 在迁移过程中监控数据库性能,以识别和优化性能瓶颈。
### 3.2.6 解决方案和优化策略
针对数据库迁移过程中可能遇到的问题,开发者可以采取一些策略来优化迁移过程。以下是一些常见的解决方案和优化策略:
#### 数据库迁移的性能优化
迁移性能优化是数据库迁移中的一个重要方面。随着数据库规模的增长,迁移操作可能会变得非常缓慢。为了优化迁移性能,开发者可以考虑以下策略:
1. **分批处理大量数据**:而不是一次性迁移所有数据,可以将数据分批处理,每次处理一小部分数据。这样可以减少对数据库的负载,并降低迁移过程中出现问题的风险。
```python
# 分批处理用户数据迁移
from django.db import migrations
def forwards_batch_migration(apps, schema_editor):
User = apps.get_model('app_name', 'User')
batch_size = 1000
start_id = 0
while True:
users = User.objects.filter(id__gt=start_id)[:batch_size]
if not users:
break
# 处理用户数据
for user in users:
# 更新用户信息
pass
start_id += batch_size
class Migration(migrations.Migration):
operations = [
migrations.RunPython(forwards_batch_migration),
]
```
#### 数据库迁移的错误处理
迁移过程中可能会遇到各种错误,例如数据不一致或数据库操作失败。为了有效地处理这些错误,开发者可以采取以下策略:
1. **使用try-except块**:在迁移操作中使用try-except块来捕获并处理错误。这样可以避免迁移失败后整个迁移过程被中断。
```python
# 使用try-except处理迁移错误
from django.db import migrations, IntegrityError
def forwards_error_handling(apps, schema_editor):
User = apps.get_model('app_name', 'User')
try:
for user in User.objects.all():
user.age = 25
user.save()
except IntegrityError as e:
print(f"An error occurred: {e}")
class Migration(migrations.Migration):
operations = [
migrations.RunPython(forwards_error_handling),
]
```
#### 数据库迁移的日志记录
为了更好地理解和监控迁移过程,开发者可以实施日志记录策略。通过记录详细的迁移日志,可以追踪迁移操作的执行情况,并在出现问题时快速定位问题原因。
```python
# 记录迁移日志
import logging
logger = logging.getLogger(__name__)
def forwards_logging(apps, schema_editor):
User = apps.get_model('app_name', 'User')
try:
for user in User.objects.all():
user.age = 25
user.save()
***(f"User {user.id} has been updated.")
except Exception as e:
logger.error(f"Error occurred while updating user {user.id}: {e}")
class Migration(migrations.Migration):
operations = [
migrations.RunPython(forwards_logging),
]
```
#### 数据库迁移的版本控制
将数据库迁移纳入版本控制系统是确保迁移过程的可追溯性和可重复性的关键步骤。通过使用版本控制系统,开发者可以跟踪每次迁移的变化,并在需要时回滚到之前的版本。
```shell
# 将迁移文件添加到版本控制
git add migrations/
git commit -m "Add database migrations"
```
#### 数据库迁移的自动化测试
自动化测试是确保迁移操作正确性和稳定性的关键。通过编写迁移测试用例,开发者可以在迁移前后验证数据库的状态,确保迁移不会破坏现有的数据和功能。
```python
# 编写迁移测试用例
import unittest
class MigrationTestCase(unittest.TestCase):
def test_migration(self):
# 测试迁移前后的数据库状态
pass
if __name__ == '__main__':
unittest.main()
```
#### 数据库迁移的持续集成
将数据库迁移纳入持续集成(CI)流程可以进一步提高迁移的可靠性和效率。通过在CI环境中自动化迁移过程,开发者可以在合并代码之前验证迁移的正确性。
```yaml
# CI流程配置示例(GitHub Actions)
name: Database Migration
on:
push:
branches:
- main
jobs:
migration:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Python
uses: actions/setup-python@v2
with:
python-version: '3.x'
- name: Install dependencies
run: |
python -m pip install -r requirements.txt
- name: Run migrations
run: |
python manage.py migrate
```
通过以上策略,开发者可以优化数据库迁移过程,确保迁移的效率和稳定性。
# 4. models.sql模块的进阶应用
## 4.1 models.sql模块与Django信号的结合
### 4.1.1 Django信号的原理和作用
Django信号是框架中一个强大的功能,它允许开发者在Django的模型和数据库操作之间进行解耦合的交互。信号的工作原理类似于发布/订阅模式,当一个模型发生特定事件(如保存、删除等)时,会触发一个信号,开发者可以定义一个或多个接收器(receivers)来响应这些事件。
信号的作用主要体现在以下几个方面:
- **解耦合**:信号允许你订阅模型事件,而不需要修改模型本身或者模型的方法。
- **代码复用**:通过信号,相同的逻辑可以应用于多个模型而无需重复代码。
- **灵活的插件系统**:信号可以作为创建插件或者扩展的一个机制,使得开发者可以在不修改核心代码的情况下扩展Django的功能。
### 4.1.2 models.sql模块与Django信号的应用实例
假设我们需要在模型数据保存后自动更新一个统计字段,我们可以使用Django的`post_save`信号来实现这一功能。
首先,定义一个信号接收器:
```python
from django.db.models.signals import post_save
from django.dispatch import receiver
from django.db.models import F
from .models import MyModel, StatisticModel
@receiver(post_save, sender=MyModel)
def update_statistic(sender, instance, created, **kwargs):
if created:
# 只有当对象首次创建时才更新统计字段
StatisticModel.objects.update_or_create(
defaults={'total': F('total') + 1}
)
```
在这个例子中,每当`MyModel`的一个实例被保存时,`update_statistic`函数就会被调用。如果实例是新创建的(通过`created`参数判断),它会增加`StatisticModel`的`total`字段值。
### 4.1.3 Django信号的工作流程
Django信号的工作流程可以分为以下几个步骤:
1. **定义信号**:使用`Signal()`创建一个新的信号实例。
2. **连接信号**:使用`connect()`方法将信号连接到一个接收器函数。
3. **发送信号**:通过调用`send()`方法发送信号,可以传递自定义参数。
4. **执行接收器**:当信号被发送时,所有连接到该信号的接收器将被执行。
这个流程图展示了Django信号的工作流程:
```mermaid
graph LR
A[定义信号] --> B[连接信号到接收器]
B --> C[发送信号]
C --> D[执行接收器函数]
```
### 4.1.4 models.sql模块与Django信号的高级应用
除了基本的使用场景,models.sql模块与Django信号的结合还可以用于更复杂的场景,比如:
- **数据库事务处理**:在模型的`pre_save`和`post_save`信号中处理数据库事务,确保数据的一致性。
- **缓存同步**:当模型数据发生变化时,自动更新缓存。
- **异步处理**:将耗时的操作放到异步任务中处理,避免阻塞主线程。
例如,我们可以在`pre_save`信号中启动一个异步任务来处理数据同步:
```python
from django.dispatch import receiver
from django.db.models.signals import pre_save
from .models import MyModel
from .tasks import async_process_data
@receiver(pre_save, sender=MyModel)
def start_async_process(sender, instance, **kwargs):
async_process_data.delay(instance.id)
```
在这个例子中,我们使用了Django的`asynctasks`模块来定义一个异步任务`async_process_data`,它将在模型数据保存之前异步执行。
## 4.2 models.sql模块的性能优化
### 4.2.1 性能优化的基本原则
在使用models.sql模块进行数据库操作时,性能优化是一个重要的考虑因素。以下是几个基本原则:
- **最小化数据库交互**:减少不必要的数据库查询,尽量使用批量操作。
- **使用索引**:在合适的字段上创建索引,以加快查询速度。
- **避免N+1查询**:使用`select_related`和`prefetch_related`来减少数据库查询次数。
- **缓存**:使用Django的缓存框架来缓存频繁读取的数据。
### 4.2.2 实际操作中的性能优化技巧
在实际操作中,我们可以采用以下技巧来优化models.sql模块的性能:
- **数据库查询优化**:合理使用`filter()`, `exclude()`, `order_by()`等方法,并且注意它们的组合使用。
- **使用raw SQL**:对于复杂的查询,直接使用SQL语句可能会更高效。
- **查询集优化**:利用Django的查询集(QuerySet)缓存机制,避免重复执行相同的查询。
- **数据库连接池**:使用连接池来管理数据库连接,减少连接创建和销毁的开销。
下面是一个使用`select_related`和`prefetch_related`的例子:
```python
from .models import MyModel, RelatedModel
# 使用select_related优化关联查询
objects = MyModel.objects.select_related('related_field')
# 使用prefetch_related优化反向关联查询
objects = MyModel.objects.prefetch_related('related_set')
```
在这个例子中,`select_related`用于优化通过外键关联的查询,而`prefetch_related`用于优化通过多对多关系或反向外键关联的查询。
## 4.3 models.sql模块的扩展和定制
### 4.3.1 模块的扩展方法
models.sql模块提供了多种扩展点,允许开发者根据需求定制模块的行为。以下是一些常用的扩展方法:
- **自定义字段类型**:创建继承自`models.Field`的自定义字段类型。
- **模型方法和属性**:在模型中定义方法和属性来增加业务逻辑。
- **元选项(Meta options)**:在模型的内部类`Meta`中定义额外的选项,如数据库表名、管理命令等。
### 4.3.2 定制模块的实践案例
假设我们需要一个自定义的JSON字段类型,可以这样做:
```python
from django.db import models
import json
class JSONField(models.TextField):
def from_db_value(self, value, expression, connection):
if value is None:
return value
return json.loads(value)
def to_python(self, value):
if isinstance(value, str):
return json.loads(value)
return value
def get_prep_value(self, value):
if value is None:
return value
return json.dumps(value)
class MyModel(models.Model):
data = JSONField()
```
在这个例子中,我们创建了一个`JSONField`类,它继承自`models.TextField`,并重写了`from_db_value`, `to_python`, 和`get_prep_value`方法来处理JSON数据的序列化和反序列化。
这个自定义字段可以像其他Django字段一样使用,提供了一个灵活的方式来处理JSON数据。
通过本章节的介绍,我们深入了解了models.sql模块与Django信号的结合、性能优化技巧以及模块的扩展和定制方法。这些知识能够帮助开发者更有效地使用Django框架,实现高性能、高可维护性的Web应用。
# 5. models.sql模块的进阶应用
## 4.1 models.sql模块与Django信号的结合
### 4.1.1 Django信号的原理和作用
在Django框架中,信号(Signals)是一种提供了一种松耦合的通信机制,允许某个事件发生时通知其他系统组件。Django的信号框架用于在Django的内部组件和我们的应用代码之间发送通知。信号的核心思想是允许解耦,即在不同部分的代码中定义和注册回调函数,当某个动作发生时,这些回调函数将被自动调用。
信号的工作原理是通过发射器(Sender)发出一个信号(Signal),当某个事件(如模型的保存操作)触发时,所有连接到该信号的接收器(Receiver)将按顺序执行。
信号的作用主要体现在以下几个方面:
- **减少代码的耦合性**:信号允许我们在不直接修改原有代码的情况下,扩展或修改应用的行为。
- **实现跨模块通信**:通过信号,可以实现模型、视图、模板等不同模块之间的通信,而无需显式地调用它们。
- **实现可插拔性**:开发者可以创建自定义的信号处理逻辑,并通过连接到Django内部信号来实现特定的功能。
### 4.1.2 models.sql模块与Django信号的应用实例
在结合`models.sql`模块和Django信号时,我们可以实现一些高级功能,例如在模型保存后自动同步数据库结构或在数据库操作完成后触发自定义行为。
例如,我们可以创建一个信号接收器,在模型实例保存后自动同步数据库结构:
```python
from django.db.models.signals import post_save
from django.dispatch import receiver
from myapp.models import MyModel
from myapp.models.sql import sync_database_structure
@receiver(post_save, sender=MyModel)
def sync_db(sender, instance, created, **kwargs):
if created: # 只有在创建新实例时才同步数据库结构
sync_database_structure(sender)
def sync_database_structure(sender):
# 这里可以是自定义的同步数据库结构逻辑
# 例如,检查数据库结构是否与models.sql定义一致,并进行必要的调整
pass
```
在这个例子中,我们定义了一个信号接收器`sync_db`,它会在`MyModel`实例保存后触发。如果这是一个新创建的实例(`created`参数为`True`),则调用`sync_database_structure`函数来同步数据库结构。
## 4.2 models.sql模块的性能优化
### 4.2.1 性能优化的基本原则
在实际应用中,对`models.sql`模块的性能优化通常遵循以下基本原则:
- **最小化数据库交互**:尽量减少数据库访问次数,合并多个查询或更新操作。
- **使用索引**:为经常查询的字段创建索引,以加快查询速度。
- **避免复杂的查询**:简化查询逻辑,避免使用复杂的子查询或JOIN操作。
- **使用缓存**:对于重复的数据库查询,可以使用Django的缓存框架来存储结果,减少数据库的负担。
- **批量操作**:使用Django ORM的`bulk_create`、`bulk_update`或`delete`方法来进行批量操作,而不是单条记录操作。
### 4.2.2 实际操作中的性能优化技巧
在实际操作中,我们可以采取以下一些性能优化技巧:
- **优化查询集**:使用`.select_related()`和`.prefetch_related()`来优化关系字段的查询。
- **自定义管理器**:使用自定义管理器来封装数据库操作逻辑,例如提供批量创建或更新的方法。
- **数据库事务**:合理使用数据库事务,减少锁定资源的时间,提高并发性能。
例如,我们可以使用自定义管理器来优化模型的批量操作:
```python
from django.db import models
class MyModelManager(models.Manager):
def bulk_create_safe(self, objs):
# 批量创建对象,但不立即保存到数据库
objs_to_create = []
for obj in objs:
objs_to_create.append(self.model(**obj.__dict__))
# 创建数据库连接
connection = self.model._meta.db_table.split(".")[0]
with connection.cursor() as cursor:
cursor.execute("SET TRANSACTION ISOLATION LEVEL READ COMMITTED")
cursor.execute("BEGIN TRANSACTION")
# 批量插入数据
for obj in objs_to_create:
cursor.execute("INSERT INTO %s (...) VALUES (%s)" % (
self.model._meta.db_table,
", ".join(["%s"] * len(obj._meta.fields)),
), tuple(obj.__dict__.values()))
# 提交事务
cursor.execute("COMMIT")
# 反序列化对象
objs = [self.model(**values) for values in objs_to_create]
return objs
class MyModel(models.Model):
# 模型字段定义
pass
MyModel.objects = MyModelManager()
```
在这个例子中,我们定义了一个自定义管理器`MyModelManager`,其中包含了一个`bulk_create_safe`方法,该方法可以在数据库事务中批量插入数据,从而提高性能。
## 4.3 models.sql模块的扩展和定制
### 4.3.1 模块的扩展方法
扩展`models.sql`模块通常涉及以下几种方法:
- **自定义SQL语句**:在模型的`Meta`内部类中,可以通过`sql_table`、`sql_select`等属性来自定义SQL语句。
- **使用自定义函数**:编写自定义函数来生成或修改SQL语句,然后在模型中使用这些函数。
- **注册自定义处理器**:通过编写自定义的数据库操作处理器,可以在数据库操作前后执行自定义逻辑。
例如,我们可以在模型中自定义SQL语句来优化查询:
```python
from django.db import models
class MyModel(models.Model):
# 模型字段定义
class Meta:
sql_table = 'my_custom_table_name'
sql_select = 'SELECT ..., COUNT(*) as count FROM ...'
```
在这个例子中,我们通过自定义`sql_table`和`sql_select`属性来指定模型对应的表名和查询语句。
### 4.3.2 定制模块的实践案例
在实际应用中,我们可能会遇到需要高度定制`models.sql`模块的场景。例如,我们需要根据不同的业务需求生成不同的数据库结构。
以下是一个实践案例,展示了如何使用自定义函数来生成不同的数据库结构:
```python
from django.db import models
from django.db.migrations.state import StateApps
def generate_sql(apps: StateApps, schema_editor):
# 根据不同的条件生成不同的SQL语句
if apps.schema_editor.connection.vendor == 'sqlite':
sql = "CREATE TABLE IF NOT EXISTS my_table ..."
else:
sql = "CREATE TABLE my_table ..."
# 执行SQL语句
with schema_editor.connection.cursor() as cursor:
cursor.execute(sql)
class Migration(migrations.Migration):
dependencies = [
('myapp', '0001_initial'),
]
operations = [
migrations.RunSQL(generate_sql),
]
```
在这个例子中,我们定义了一个迁移操作,它在执行时会调用`generate_sql`函数来生成SQL语句。这个函数根据数据库的类型来决定生成的SQL语句,从而实现了对不同数据库的支持。
通过以上章节的介绍,我们了解了如何结合`models.sql`模块与Django信号进行应用扩展,以及如何进行性能优化和模块的扩展和定制。这些进阶应用能够帮助我们更好地利用Django ORM的优势,构建高效、稳定的应用程序。
# 6. models.sql模块的常见问题和解决方案
## 6.1 常见问题分析
在使用Django的`models.sql`模块时,开发者可能会遇到一系列问题,这些问题通常涉及到数据库迁移、数据同步以及数据库操作的性能等。以下是一些常见的问题及其分析:
### 6.1.1 数据库迁移失败
在进行数据库迁移时,可能会遇到迁移失败的问题,这通常是因为迁移文件与数据库状态不同步或迁移脚本中存在错误。例如,当数据库结构与迁移文件中的定义不一致时,迁移操作可能会失败。
#### 解决方案
- **检查迁移文件**:确保所有迁移文件都已正确创建,并且按照正确的顺序执行。
- **检查数据库状态**:使用`python manage.py migrate --plan`命令来查看即将执行的迁移操作。
- **手动修正**:如果发现问题,可以手动修正数据库结构,或者重置迁移状态后重新执行。
### 6.1.2 数据同步延迟
在数据同步过程中,可能会遇到数据延迟的问题,这通常是由于同步脚本的效率低下或网络延迟造成的。
#### 解决方案
- **优化同步脚本**:确保同步脚本高效且没有不必要的操作。
- **使用更稳定的网络**:网络问题是导致数据同步延迟的常见原因,确保使用稳定的网络连接。
### 6.1.3 数据库性能问题
数据库操作可能会遇到性能瓶颈,尤其是在高并发的情况下。
#### 解决方案
- **分析慢查询**:使用数据库的慢查询日志功能来找出性能瓶颈。
- **优化索引**:确保数据库表的索引是最优的,以加快查询速度。
## 6.2 解决方案和优化策略
针对上一节中提到的问题,以下是一些具体的解决方案和优化策略:
### 6.2.1 数据库迁移解决方案
#### 代码示例
```python
# 检查迁移状态
python manage.py migrate --plan
# 重置迁移状态
python manage.py migrate zero
```
### 6.2.2 数据同步优化策略
#### 代码示例
```python
# 假设有一个同步脚本
def sync_data():
# 获取数据
data = get_data_from_source()
# 更新到数据库
update_database(data)
```
### 6.2.3 数据库性能优化策略
#### 代码示例
```python
# 创建索引
CREATE INDEX idx_column_name ON table_name (column_name);
# 分析慢查询
EXPLAIN ANALYZE SELECT * FROM table_name WHERE condition;
```
### 6.2.4 数据库连接池配置
数据库连接池是提高数据库性能的有效手段,它可以减少频繁建立和关闭数据库连接的开销。
#### 配置示例
```python
# settings.py 中的数据库配置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'db_name',
'USER': 'db_user',
'PASSWORD': 'db_password',
'HOST': 'localhost',
'PORT': '5432',
'OPTIONS': {
'connect_timeout': 5,
'options': '-c statement_timeout=30000'
},
'TEST': {
'CHARSET': 'utf8mb4',
'COLLATION': 'utf8mb4_unicode_ci',
},
}
}
```
### 6.2.5 使用数据库分析工具
使用数据库自带的分析工具,如`EXPLAIN ANALYZE`,可以帮助开发者了解查询执行计划和性能瓶颈。
#### 操作步骤
1. 登录数据库管理工具。
2. 执行`EXPLAIN ANALYZE`命令。
3. 分析输出结果,找出性能瓶颈。
通过上述解决方案和优化策略,可以有效解决在使用`models.sql`模块时遇到的一些常见问题,并提升数据库操作的性能。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探究了 Django ORM 中至关重要的 models.sql 模块,揭示了其内部工作机制、执行流程、SQL 编译过程以及在迁移、性能优化、数据模型设计、自定义 SQL、复杂查询、事务管理、最佳实践、数据库 API、安全、模型层应用、源码实现、查询集优化和自动化测试中的关键作用。通过一系列文章,本专栏旨在帮助开发者充分理解 models.sql,从而提升 Django ORM 的使用效率,构建更健壮、高效的数据库应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据库备份与恢复:实验中的备份与还原操作详解

# 1. 数据库备份与恢复概述
在信息技术高速发展的今天,数据已成为企业最宝贵的资产之一。为了防止数据丢失或损坏,数据库备份与恢复显得尤为重要。备份是一个预防性过程,它创建了数据的一个或多个副本,以备在原始数据丢失或损坏时可以进行恢复。数据库恢复则是指在发生故障后,将备份的数据重新载入到数据库系统中的过程。本章将为读者提供一个关于
定时器与中断管理:51单片机音乐跑马灯编程核心技法
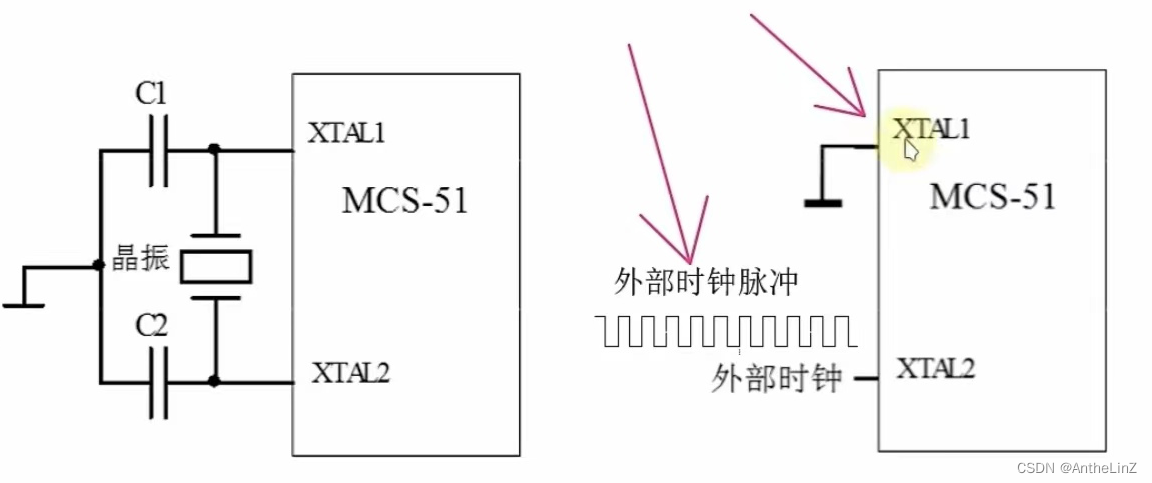
# 1. 定时器与中断管理基础
在嵌入式系统开发中,定时器和中断管理是基础但至关重要的概念,它们是实现时间控制、响应外部事件和处理数据的核心组件。理解定时器的基本原理、中断的产生和管理方式,对于设计出高效的嵌入式应用是必不可少的。
## 1.1 定时器的概念
定时器是一种可以测量时间间隔的硬件资源,它通过预设的计数值进行计数,当达到设定值时产生时间事件。在单片机和微控制器中,定时器常用于任务调度、延时、
热管理问题深度剖析:负载调制放大器的冷却与散热策略

# 1. 热管理问题概述
随着电子设备不断向小型化、高性能方向发展,热管理问题变得日益重要。热管理,简单来说,就是对电子设备内部热量生成与散发进行有效控制的过程。这一过程对保障设备稳定运行、延长使用寿命、提升性能表现至关重要。
## 1.1 热管理的必要性
电子设备工作时,其内部的半导体器件、集成电路等会因电流通过产生热量,而热量的积累会导致设备温度升高。当温度超过一定
Python编程风格

# 1. Python编程风格概述
Python作为一门高级编程语言,其简洁明了的语法吸引了全球众多开发者。其编程风格不仅体现在代码的可读性上,还包括代码的编写习惯和逻辑构建方式。好的编程风格能够提高代码的可维护性,便于团队协作和代码审查。本章我们将探索Python编程风格的基础,为后续深入学习Python编码规范、最佳实践以及性能优化奠定基础。
在开始编码之前,开发者需要了解和掌握Python的一些核心
Vue组件设计模式:提升代码复用性和可维护性的策略

# 1. Vue组件设计模式的理论基础
在构建复杂前端应用程序时,组件化是一种常见的设计方法,Vue.js框架以其组件系统而著称,允许开发者将UI分成独立、可复用的部分。Vue组件设计模式不仅是编写可维护和可扩展代码的基础,也是实现应用程序业务逻辑的关键。
## 组件的定义与重要性
组件是Vue中的核心概念,它可以封装HTML、CSS和JavaScript代码,以供复用。理解
【SpringBoot日志管理】:有效记录和分析网站运行日志的策略

# 1. SpringBoot日志管理概述
在当代的软件开发过程中,日志管理是一个关键组成部分,它对于软件的监控、调试、问题诊断以及性能分析起着至关重要的作用。SpringBoot作为Java领域中最流行的微服务框架之一,它内置了强大的日志管理功能,能够帮助开发者高效地收集和管理日志信息。本文将从概述SpringBoot日志管理的基础
【电子密码锁用户交互设计】:提升用户体验的关键要素与设计思路

# 1. 电子密码锁概述与用户交互的重要性
## 1.1 电子密码锁简介
电子密码锁作为现代智能家居的入口,正逐步替代传统的物理钥匙,它通过数字代码输入来实现门锁的开闭。随着技术的发展,电子密码锁正变得更加智能与安全,集成指纹、蓝牙、Wi-Fi等多种开锁方式。
## 1.2 用户交互
【制造业时间研究:流程优化的深度分析】

# 1. 制造业时间研究概念解析
在现代制造业中,时间研究的概念是提高效率和盈利能力的关键。它是工业工程领域的一个分支,旨在精确测量完成特定工作所需的时间。时间研究不仅限于识别和减少浪费,而且关注于创造一个更为流畅、高效的工作环境。通过对流程的时间分析,企业能够优化生产布局,减少非增值活动,从而缩短生产周期,提高客户满意度。
在这一章中,我们将解释时间研究的核心理念和定义,探讨其在制造业中的作用和重要性。通过
直播推流成本控制指南:PLDroidMediaStreaming资源管理与优化方案
# 1. 直播推流成本控制概述
## 1.1 成本控制的重要性
直播业务尽管在近年来获得了爆发式的增长,但随之而来的成本压力也不容忽视。对于直播平台来说,优化成本控制不仅能够提升财务表现,还能增强市场竞争力。成本控制是确保直播服务长期稳定运
【MATLAB雷达信号处理】:理论与实践结合的实战教程
# 1. MATLAB雷达信号处理概述
在当今的军事与民用领域中,雷达系统发挥着至关重要的作用。无论是空中交通控制、天气监测还是军事侦察,雷达信号处理技术的应用无处不在。MATLAB作为一种强大的数学软件,以其卓越的数值计算能力、简洁的编程语言和丰富的工具箱,在雷达信号处理领域占据着举足轻重的地位。
在本章中,我们将初步介绍MATLAB在雷达信号处理中的应用,并
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )