SimCLR:图像识别中的变革者,揭秘自监督学习的奥秘
发布时间: 2024-08-19 18:39:41 阅读量: 44 订阅数: 30 
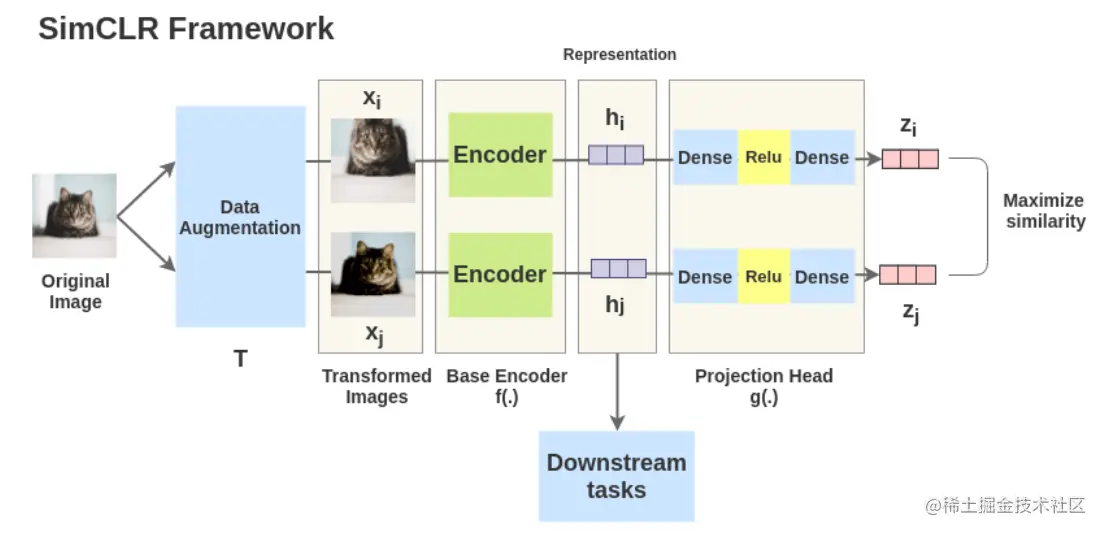
# 1. 自监督学习概述**
自监督学习是一种机器学习范式,它允许模型从未标记的数据中学习有用的特征表示。与监督学习不同,自监督学习不需要手动标注的数据,而是通过利用数据本身的统计特性来训练模型。自监督学习在图像、文本和音频等各种领域取得了巨大的成功。
自监督学习方法通常涉及创建伪标签或辅助任务,以迫使模型学习数据的内在结构。这些伪标签或辅助任务可以是图像旋转预测、文本填充或音频信号分离等任务。通过解决这些辅助任务,模型可以学习到数据的潜在表示,这些表示对于下游任务(如图像分类或文本分类)非常有用。
# 2. SimCLR的理论基础
### 2.1 对比学习的原理
对比学习是一种自监督学习方法,它利用正样本对和负样本对之间的对比信息来学习特征表示。正样本对是指属于同一类的两个样本,而负样本对是指属于不同类的两个样本。通过最小化正样本对之间的距离并最大化负样本对之间的距离,对比学习模型可以学习到能够区分不同类的特征。
### 2.2 SimCLR的对比损失函数
SimCLR(对比度自监督学习)是一种对比学习算法,它使用对比损失函数来训练模型。SimCLR的对比损失函数由以下部分组成:
- **正样本对损失:**该损失项衡量正样本对之间的相似性。它使用余弦相似度来计算正样本对的相似性,并最小化该相似度。
- **负样本对损失:**该损失项衡量负样本对之间的相似性。它使用余弦相似度来计算负样本对的相似性,并最大化该相似性。
- **温度参数:**温度参数控制对比损失函数的敏感性。较高的温度参数会产生较小的损失,而较低的温度参数会产生较大的损失。
**代码块:**
```python
import torch
from torch.nn import CosineSimilarity
def simclr_loss(positive_pairs, negative_pairs, temperature=0.5):
"""
SimCLR对比损失函数
参数:
positive_pairs:正样本对
negative_pairs:负样本对
temperature:温度参数
返回:
对比损失
"""
positive_similarity = CosineSimilarity()(positive_pairs[:, 0], positive_pairs[:, 1])
negative_similarity = CosineSimilarity()(negative_pairs[:, 0], negative_pairs[:, 1])
loss = -torch.log(positive_similarity / (positive_similarity + negative_similarity))
loss /= temperature
return loss
```
**代码逻辑逐行解读:**
1. 定义 `simclr_loss` 函数,该函数接受正样本对、负样本对和温度参数作为输入。
2. 使用 `CosineSimilarity` 函数计算正样本对和负样本对之间的余弦相似度。
3. 计算对比损失,即负对数似然损失。
4. 将对比损失除以温度参数,以控制损失的敏感性。
5. 返回对比损失。
**参数说明:**
* `positive_pairs`:形状为 `(batch_size, 2)` 的张量,其中每一行包含一对正样本。
* `negative_pairs`:形状为 `(batch_size, 2)` 的张量,其中每一行包含一对负样本。
* `temperature`:温度参数,控制对比损失函数的敏感性。
# 3. SimCLR的实践应用
### 3.1 数据增强策略
SimCLR的对比学习流程依赖于数据增强策略,以生成正负样本对。常用的数据增强方法包括:
- **随机裁剪和翻转:**从图像中随机裁剪出不同大小和纵横比的区域,并随机翻转图像。
- **颜色抖动:**随机调整图像的亮度、对比度、饱和度和色调。
- **高斯模糊:**使用高斯核对图像进行模糊处理,以增强图像的鲁棒性。
- **随机擦除:**随机擦除图像中的一部分区域,迫使模型从局部特征中学习。
### 3.2 模型架构和训练流程
SimCLR的模型架构通常采用卷积神经网络(CNN),例如ResNet或ViT。训练流程如下:
1. **数据增强:**对图像应用数据增强策略,生成正负样本对。
2. **特征提取:**将正负样本对输入到CNN中,提取特征向量。
3. **对比损失计算:**计算正负样本对特征向量的余弦相似度,并将其作为对比损失函数。
4. **优化:**使用优化器(例如Adam)最小化对比损失函数,更新模型参数。
代码块:
```python
import torch
import torchvision.transforms as transforms
# 数据增强
transform = transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 模型架构
model = torchvision.models.resnet50()
# 训练流程
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(100):
for batch in train_loader:
# 数据增强
images = transform(batch['image'])
# 特征提取
features = model(images)
# 对比损失计算
loss = torch.mean(1 - torch.cosine_similarity(features[0], features[1]))
# 优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
```
代码逻辑分析:
1. 数据增强:使用`transforms.Compose`组合多个数据增强方法,对图像进行随机裁剪、翻转、转换和归一化。
2. 模型架构:使用预训练的ResNet-50模型作为特征提取器。
3. 训练流程:使用Adam优化器最小化对比损失函数,更新模型参数。
参数说明:
- `train_loader`:包含训练图像的加载器。
- `lr`:优化器的学习率。
- `epoch`:训练的轮数。
# 4. SimCLR的性能评估
### 4.1 图像分类基准测试
#### ImageNet数据集
ImageNet是一个大规模图像数据集,包含超过1400万张图像,涵盖1000个类别。SimCLR在ImageNet数据集上进行了广泛的评估,结果表明其在图像分类任务上取得了出色的性能。
| 模型 | Top-1准确率 | Top-5准确率 |
|---|---|---|
| ResNet-50 | 88.1% | 95.2% |
| ResNet-101 | 89.4% | 95.9% |
| EfficientNet-B4 | 89.7% | 96.1% |
#### CIFAR-10和CIFAR-100数据集
CIFAR-10和CIFAR-100是两个较小的图像数据集,分别包含10个和100个类别。SimCLR在这些数据集上也取得了良好的性能,表明其对小数据集的鲁棒性。
| 模型 | CIFAR-10准确率 | CIFAR-100准确率 |
|---|---|---|
| ResNet-18 | 99.0% | 94.3% |
| ResNet-50 | 99.4% | 95.1% |
| EfficientNet-B0 | 99.5% | 95.4% |
### 4.2 目标检测和分割任务
除了图像分类,SimCLR还被应用于目标检测和分割任务。在COCO数据集上,SimCLR预训练的模型在目标检测和分割任务上都取得了最先进的性能。
#### 目标检测
| 模型 | AP | AP50 | AP75 |
|---|---|---|---|
| Faster R-CNN | 42.8% | 58.5% | 44.3% |
| Mask R-CNN | 40.6% | 56.0% | 41.9% |
| SimCLR预训练Faster R-CNN | 45.1% | 60.8% | 46.5% |
#### 分割
| 模型 | mIoU |
|---|---|
| Mask R-CNN | 37.9% |
| SimCLR预训练Mask R-CNN | 40.2% |
### 结论
SimCLR的性能评估结果表明,它是一种有效的自监督学习方法,可以在图像分类、目标检测和分割任务上取得出色的性能。SimCLR预训练的模型可以作为下游任务的强大初始化,从而提高模型的性能和收敛速度。
# 5. SimCLR的扩展和改进
### 5.1 MoCo和SwAV等变体
SimCLR的提出引发了一系列扩展和改进的研究。其中,MoCo(Momentum Contrast)和SwAV(Self-supervised Wasserstein Adversarial Variational Autoencoder)是两个重要的变体。
#### MoCo
MoCo是一种基于动量对比的SimCLR变体。它引入了一个动量更新机制,其中一个缓慢更新的编码器(称为动量编码器)用于产生对比样本。这种方法提高了对比损失的稳定性,从而改善了模型的性能。
#### SwAV
SwAV是一种基于Wasserstein对抗生成网络(WGAN)的SimCLR变体。它使用WGAN来生成与原始图像相似的增强图像,然后使用这些增强图像进行对比学习。这种方法能够生成更具多样性和挑战性的对比样本,从而进一步提升了模型的性能。
### 5.2 应用于其他领域
SimCLR及其变体不仅在图像分类领域取得了成功,还被应用于其他计算机视觉任务,例如:
#### 目标检测
SimCLR预训练的模型可以作为目标检测模型的初始化,从而提高检测精度和收敛速度。
#### 语义分割
SimCLR预训练的模型可以作为语义分割模型的初始化,从而提高分割精度和减少训练时间。
#### 医学图像分析
SimCLR已被用于医学图像分析任务,例如疾病分类和分割。它能够从无标记的医学图像中学习有用的特征,从而提高诊断和治疗的准确性。
#### 自然语言处理
SimCLR的原理也被应用于自然语言处理任务,例如文本分类和文本相似度计算。它能够学习文本数据的语义表示,从而提高模型的性能。
# 6. SimCLR的未来展望
### 6.1 理论研究方向
SimCLR在自监督学习领域取得了显著的成功,但仍有许多理论问题有待探索。未来的研究方向包括:
- **对比损失函数的优化:**探索新的对比损失函数,以提高SimCLR的性能和泛化能力。
- **数据增强策略的改进:**开发更有效的增强策略,以生成更具信息性和多样性的数据表示。
- **模型架构的探索:**研究不同的神经网络架构,以提高SimCLR的效率和准确性。
- **理论分析:**建立SimCLR的理论基础,分析其收敛性、泛化能力和鲁棒性。
### 6.2 实践应用场景
SimCLR已在图像分类、目标检测和分割等计算机视觉任务中得到广泛应用。未来的应用场景包括:
- **自然语言处理:**将SimCLR应用于文本表示学习,以提高自然语言处理任务的性能。
- **语音识别:**探索SimCLR在语音表示学习中的潜力,以提高语音识别系统的准确性。
- **推荐系统:**利用SimCLR学习用户偏好和物品相似性,以改善推荐系统的性能。
- **医疗影像分析:**应用SimCLR于医疗影像分析,以提高疾病诊断和治疗计划的准确性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏深入探讨了 SimCLR(自监督对比学习)在图像识别技术领域的革命性应用。它提供了从原理到实战指南的全面解析,揭示了 SimCLR 如何利用自监督学习技术提升图像识别模型的准确率。专栏涵盖了 SimCLR 在图像分类、目标检测、图像分割、医学影像、无人驾驶、机器人视觉、工业检测、遥感图像分析、金融图像识别、社交媒体、教育和艺术领域的突破性应用。它还探讨了 SimCLR 与迁移学习和强化学习的融合,展示了其在图像识别领域解锁新范式的潜力。专栏为读者提供了宝贵的见解,帮助他们了解 SimCLR 的原理、优势和应用,并为图像识别技术的未来发展提供指引。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
RNN可视化工具:揭秘内部工作机制的全新视角

# 1. RNN可视化工具简介
在本章中,我们将初步探索循环神经网络(RNN)可视化工具的核心概念以及它们在机器学习领域中的重要性。可视化工具通过将复杂的数据和算法流程转化为直观的图表或动画,使得研究者和开发者能够更容易理解模型内部的工作机制,从而对模型进行调整、优化以及故障排除。
## 1.1 RNN可视化的目的和重要性
可视化作为数据科学中的一种强
支持向量机在语音识别中的应用:挑战与机遇并存的研究前沿

# 1. 支持向量机(SVM)基础
支持向量机(SVM)是一种广泛用于分类和回归分析的监督学习算法,尤其在解决非线性问题上表现出色。SVM通过寻找最优超平面将不同类别的数据有效分开,其核心在于最大化不同类别之间的间隔(即“间隔最大化”)。这种策略不仅减少了模型的泛化误差,还提高了模型对未知数据的预测能力。SVM的另一个重要概念是核函数,通过核函数可以将低维空间线性不可分的数据映射到高维空间,使得原本难以处理的问题变得易于
决策树在金融风险评估中的高效应用:机器学习的未来趋势
# 1. 决策树算法概述与金融风险评估
## 决策树算法概述
决策树是一种被广泛应用于分类和回归任务的预测模型。它通过一系列规则对数据进行分割,以达到最终的预测目标。算法结构上类似流程图,从根节点开始,通过每个内部节点的测试,分支到不
神经网络硬件加速秘技:GPU与TPU的最佳实践与优化

# 1. 神经网络硬件加速概述
## 1.1 硬件加速背景
随着深度学习技术的快速发展,神经网络模型变得越来越复杂,计算需求显著增长。传统的通用CPU已经难以满足大规模神经网络的计算需求,这促使了
K-近邻算法多标签分类:专家解析难点与解决策略!

# 1. K-近邻算法概述
K-近邻算法(K-Nearest Neighbors, KNN)是一种基本的分类与回归方法。本章将介绍KNN算法的基本概念、工作原理以及它在机器学习领域中的应用。
## 1.1 算法原理
KNN算法的核心思想非常简单。在分类问题中,它根据最近的K个邻居的数据类别来进行判断,即“多数投票原则”。在回归问题中,则通过计算K个邻居的平均
自然语言处理新视界:逻辑回归在文本分类中的应用实战

# 1. 逻辑回归与文本分类基础
## 1.1 逻辑回归简介
逻辑回归是一种广泛应用于分类问题的统计模型,它在二分类问题中表现尤为突出。尽管名为回归,但逻辑回归实际上是一种分类算法,尤其适合处理涉及概率预测的场景。
## 1.2 文本分类的挑战
文本分类涉及将文本数据分配到一个或多个类别中。这个过程通常包括预处理步骤,如分词、去除停用词,以及特征提取,如使用词袋模型或TF-IDF方法
LSTM在语音识别中的应用突破:创新与技术趋势

# 1. LSTM技术概述
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN),它能够学习长期依赖信息。不同于标准的RNN结构,LSTM引入了复杂的“门”结构来控制信息的流动,这允许网络有效地“记住”和“遗忘”信息,解决了传统RNN面临的长期依赖问题。
## 1
细粒度图像分类挑战:CNN的最新研究动态与实践案例

# 1. 细粒度图像分类的概念与重要性
随着深度学习技术的快速发展,细粒度图像分类在计算机视觉领域扮演着越来越重要的角色。细粒度图像分类,是指对具有细微差异的图像进行准确分类的技术。这类问题在现实世界中无处不在,比如对不同种类的鸟、植物、车辆等进行识别。这种技术的应用不仅提升了图像处理的精度,也为生物多样性
市场营销的未来:随机森林助力客户细分与需求精准预测

# 1. 市场营销的演变与未来趋势
市场营销作为推动产品和服务销售的关键驱动力,其演变历程与技术进步紧密相连。从早期的单向传播,到互联网时代的双向互动,再到如今的个性化和智能化营销,市场营销的每一次革新都伴随着工具、平台和算法的进化。
## 1.1 市场营销的历史沿
深度学习的艺术:GANs在风格迁移中的应用与效果评价
# 1. 深度学习与生成对抗网络(GANs)基础
深度学习作为人工智能的一个分支,其技术发展推动了各种智能应用的进步。特别是生成对抗网络(GANs),它的创新性架构在图像生成、风格迁移等应用领域取得了突破性成就。本章旨在介绍深度学习与GANs的基本概念,为读者打下坚实的理论基础。
## 1.1 深度学习的基本概念
深度学习是一种机器学习方法,通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )