Werkzeug中的身份验证和授权】:保护你的Web应用:安全实践与案例分析
发布时间: 2024-10-17 17:54:08 阅读量: 47 订阅数: 46 

基于 Flask 的 Web 应用程序搭建与安全性提升

# 1. Werkzeug身份验证与授权基础
在本章节中,我们将探索Werkzeug框架中身份验证和授权的基本概念和原理。这些是构建安全Web应用的基础,它们确保了只有经过验证和授权的用户才能访问敏感信息和功能。
## 1.1 身份验证与授权的概念
身份验证是验证用户身份的过程,通常涉及用户名和密码的匹配。它确保了请求来自声称的用户。而授权则是在用户身份验证后,决定用户是否有权限执行特定操作的过程。
### 1.1.1 身份验证的重要性
身份验证对于Web应用的安全至关重要。没有它,任何用户都可以假装成另一个人来访问数据或执行操作,这可能导致数据泄露或恶意行为。
### 1.1.2 身份验证的方法
常见的身份验证方法包括基本认证(Basic Auth)和摘要认证(Digest Auth)。Werkzeug提供了这些机制的实现,同时也支持更复杂的OAuth认证。
通过本章的学习,你将理解Werkzeug中的身份验证和授权的基本概念,并为后续章节的深入学习打下坚实的基础。
# 2. ```
# 第二章:Werkzeug中身份验证的机制与实践
## 2.1 身份验证理论基础
### 2.1.1 身份验证的概念与重要性
身份验证是保障系统安全的重要环节,确保用户是其所声明身份的个体,进而授权用户对系统资源的访问。在一个Web应用中,身份验证通常意味着确认用户的身份并给予相应的访问权限。身份验证的实施不仅可以保护敏感信息,还可以限制对系统功能的访问,确保只有授权用户能够执行特定操作。
身份验证机制通常包括以下几个关键要素:
- 凭证:用户必须提供的信息,比如用户名和密码。
- 验证器:用于检验用户凭证的组件或服务。
- 会话管理:在用户成功验证后,用于跟踪用户状态的系统。
### 2.1.2 常见的身份验证方法
现代Web应用中通常采用以下几种身份验证方法:
- 基于密码的验证:最常见的方式,涉及用户名和密码的组合。
- 双因素认证(2FA):在此基础上增加了额外的验证层,比如手机短信验证码或生物识别。
- 单点登录(SSO):允许用户使用一组登录凭证访问多个应用。
## 2.2 Werkzeug身份验证实现
### 2.2.1 Werkzeug中内置的身份验证工具
Werkzeug是一个强大的Web工具包,它提供了用于处理身份验证的基础工具。例如,Werkzeug内置了用于处理HTTP基本认证和摘要认证的函数。以下是一个使用Werkzeug处理HTTP基本认证的简单示例:
```python
from werkzeug.security import check_password_hash
from werkzeug.wrappers import Request, Response
# 假定这是从数据库获取的用户信息
user = {
'username': 'admin',
'password_hash': '生成的安全密码哈希值'
}
@Request.application
def application(request):
auth = request.authorization
if auth and check_password_hash(user['password_hash'], auth.password):
return Response('Hello, %s!' % auth.username)
return Response('Invalid credentials', 401,
{'WWW-Authenticate': 'Basic realm="Login Required"'})
```
在这个示例中,我们创建了一个简单的Werkzeug WSGI应用,它检查请求的HTTP基本认证头部。如果凭证正确,将返回欢迎消息;否则,返回认证错误。
### 2.2.2 自定义身份验证中间件
除了内置工具,Werkzeug也支持自定义身份验证中间件,允许开发者根据具体需求设计身份验证流程。以下是创建自定义中间件的一个例子:
```python
from werkzeug.utils import redirect
from flask import Flask, request, make_response
app = Flask(__name__)
# 自定义身份验证函数
def check_auth(username, password):
# 这里应有实际的认证逻辑
return username == 'admin' and password == 'secret'
@app.before_request
def require_auth():
auth = request.authorization
if not auth or not check_auth(auth.username, auth.password):
return make_response(redirect('***'))
# 保护的路由
@app.route('/protected')
def protected():
return 'Access granted'
if __name__ == '__main__':
app.run()
```
在上述代码中,我们定义了一个`check_auth`函数,用于验证用户名和密码,以及一个`before_request`装饰器注册的`require_auth`中间件,它在每次请求处理之前检查身份验证。如果认证失败,用户会被重定向到登录页面。
## 2.3 身份验证的实战演练
### 2.3.1 创建基本登录系统
在本节中,我们将通过一个实战演练来创建一个基本的登录系统。该系统将包含用户登录和登出的基本功能。
### 2.3.2 高级安全特性集成
除了基本的登录功能,我们还可以考虑集成一些高级安全特性,例如限制登录尝试次数、使用HTTPS、实现双因素认证等,来提高系统的整体安全性。
请注意,以上章节内容只是一个概览,每个子章节都需要更详细的内容填充,包括对代码逻辑的逐行解读分析、图表的展示、安全实践的讨论等。在实际操作中,还需确保遵循最佳安全实践,并提供实际运行的代码示例,为读者提供更深入的学习体验。
```
# 3. Werkzeug中的授权策略与实现
在上一章中,我们已经探讨了身份验证的理论基础以及在Werkzeug中的实现方式。接下来,我们将深入讨论如何利用Werkzeug来实现授权,这是确保Web应用安全的另一道防线。授权是控制用户对系统资源访问的过程,与身份验证紧密相连,但关注点在于用户可以做什么,而不仅仅是用户是谁。
## 3.1 授权理论基础
### 3.1.1 授权与身份验证的关系
身份验证是确认用户身份的过程,通常与用户登录系统相关。而授权则是在确认了用户身份之后,根据用户的角色或权限来限制其对系统资源的访问。简而言之,没有身份验证,授权就没有意义;而没有授权,即使身份验证通过,用户也可能访问到不应访问的资源。
在Web应用中,授权通常发生在身

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Werkzeug 库文件学习》专栏深入探讨了 Werkzeug,这是一个强大的 Python 库,用于构建和维护 Web 应用程序。它涵盖了广泛的主题,从掌握 WSGI 规范到精通 Jinja2 模板引擎,再到构建 RESTful API 的技巧。专栏还提供了有关错误处理、数据解析、WSGI 服务器、调试工具、性能优化、安全性指南、异步编程、测试工具、信号和事件处理以及与数据库集成的专家见解。通过深入分析和实际示例,该专栏旨在帮助开发人员充分利用 Werkzeug 的功能,构建高效、灵活且安全的 Web 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
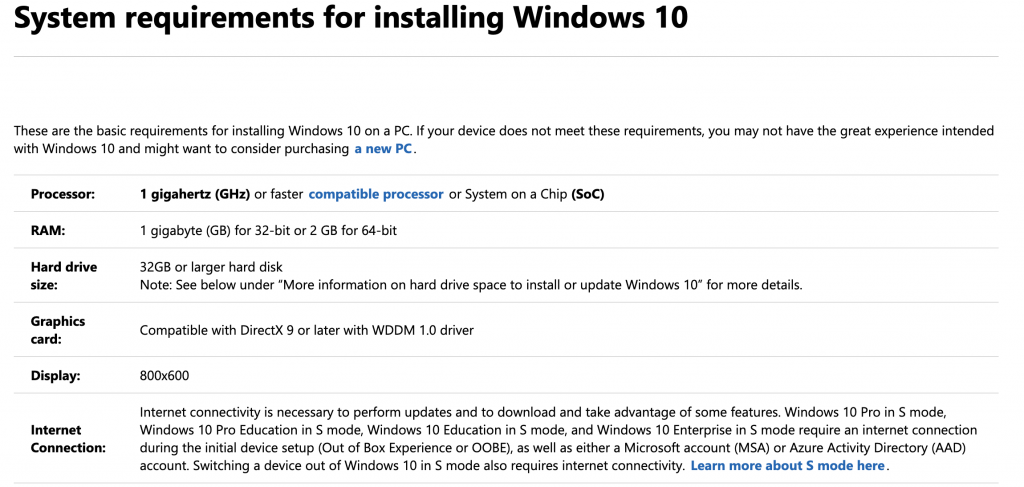
【系统兼容性深度揭秘】:Win10 x64上的TensorFlow与CUDA完美匹配指南
# 摘要
本文详细探讨了在深度学习框架中系统兼容性的重要性,并深入介绍了CUDA的安装、配置以及TensorFlow环境的搭建过程。文章分析了不同版本CUDA与GPU硬件及NVIDIA驱动程序的兼容性需求,并提供了详细的安装步骤和故障排除方法。针对TensorFlow的安装与环境搭建,文章阐述了版本选择、依赖
先农熵数学模型:计算方法深度解析

# 摘要
先农熵模型作为一门新兴的数学分支,在理论和实际应用中显示出其独特的重要性。本文首先介绍了先农熵模型的概述和理论基础,阐述了熵的起源、定义及其在信息论中的应用,并详细解释了先农熵的定义和数学角色。接着,文章深入探讨了先农熵模型的计算方法,包括统计学和数值算法,并分析了软件实现的考量。文中还通过多个应用场景和案例,展示了先农熵模型在金融分析、生物信息学和跨学科研究中的实际应用。最后,本文提出了
【24小时精通电磁场矩量法】:从零基础到专业应用的完整指南

# 摘要
本文系统地介绍了电磁场理论与矩量法的基本概念和应用。首先概述了电磁场与矩量法的基本理论,包括麦克斯韦方程组和电磁波的基础知识,随后深入探讨了矩量法的理论基础,特别是基函数与权函数选择、阻抗矩阵和导纳矩阵的构建。接着,文章详述了矩量法的计算步骤,涵盖了实施流程、编程实现以及结果分析与验证。此外,本文还探讨了矩量法在天线分析、微波工程以及雷达散射截面计算等不同场景的应用,并介绍了高频近似技术、加速技术和
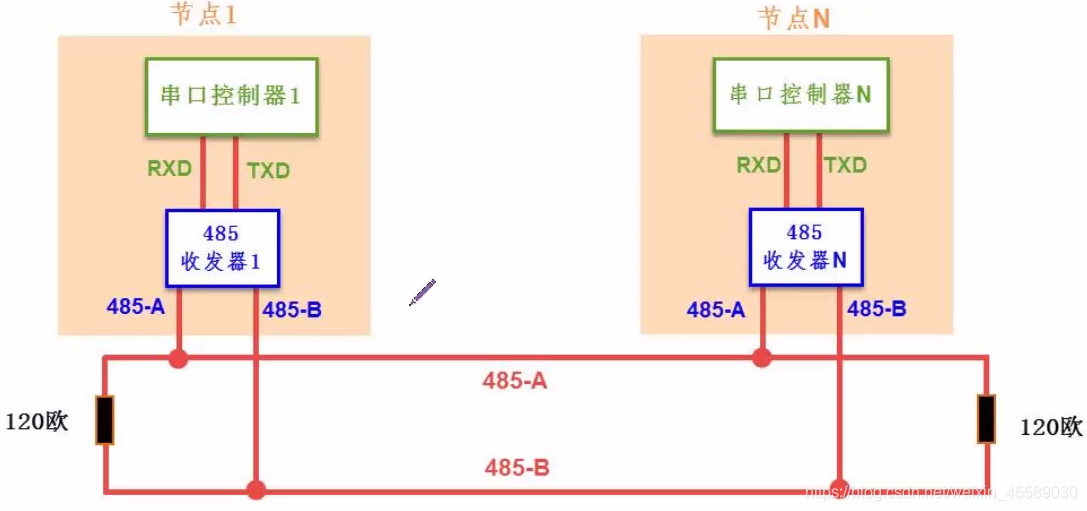
RS485通信原理与实践:揭秘偏置电阻最佳值的计算方法
# 摘要
RS485通信作为一种广泛应用的串行通信技术,因其较高的抗干扰能力和远距离传输特性,在工业控制系统和智能设备领域具有重要地位。
【SOEM多线程编程秘籍】:线程同步与资源竞争的管理艺术

# 摘要
本文针对SOEM多线程编程提供了一个系统性的学习框架,涵盖多线程编程基础、同步机制、资源竞争处理、实践案例分析以及进阶技巧,并展望了未来发展趋势。首先,介绍了多线程编程的基本概念和线程同步机制,包括同步的必要性、锁的机制、同步工具的使用等。接着,深入探讨了资源竞争的识别、预防策略和调试技巧。随后
SRIO Gen2在嵌入式系统中的实现:设计要点与十大挑战分析

# 摘要
本文对SRIO Gen2技术在嵌入式系统中的应用进行了全面概述,探讨了设计要点、面临的挑战、实践应用以及未来发展趋势。首先,文章介绍了SRIO Gen2的基本概念及其在嵌入式系统中的系统架构和硬件设计考虑。随后,文章深入分析了SRIO Gen2在嵌入式系统中遇到的十大挑战,包括兼容性、性能瓶颈和实时性能要求。在实践应用方面,本文讨论了硬件设计、软件集成优化以及跨平台部署与维护的策略。最后,文章展望了SRI
【客户满意度提升神器】:EFQM模型在IT服务质量改进中的效果

# 摘要
本论文旨在深入分析EFQM模型在提升IT服务质量方面的作用和重要性。通过对EFQM模型基本原理、框架以及评估准则的阐述,本文揭示了其核心理念及实践策略,并探讨了如何有效实施该模型以改进服务流程和建立质量管理体系。案例研究部分强调了EFQM模型在实际IT服务中的成功应用,以及它如何促进服务创新和持续改进。最后,本论文讨论了应用EFQM模型时可能遇到的挑战,以及未来的发展趋势,包括
QZXing进阶技巧:如何优化二维码扫描速度与准确性?

# 摘要
随着移动设备和电子商务的迅速发展,QZXing作为一种广泛应用的二维码扫描技术,其性能直接影响用户体验。本文首先介绍了QZXing的基础知识及其应用场景,然后深入探讨了QZXing的理论架构,包括二维码编码机制、扫描流程解析,以及影响扫描速度与准确性的关键因素。为了优化扫描速度,文章提出了一系列实践策略,如调整解码算法、图像预处理技术,以及线程和并发优化。此外,本文还探讨了提升扫描准
【架构设计的挑战与机遇】:保险基础数据模型架构设计的思考

# 摘要
保险业务的高效运行离不开科学合理的架构设计,而基础数据模型作为架构的核心,对保险业务的数据化和管理至关重要。本文首先阐述了架构设计在保险业务中的重要性,随后介绍了保险基础数据模型的理论基础,包括定义、分类及其在保险领域的应用。在数据模型设计实践中,本文详细讨论了设计步骤、面向对象技术及数据库选择与部署
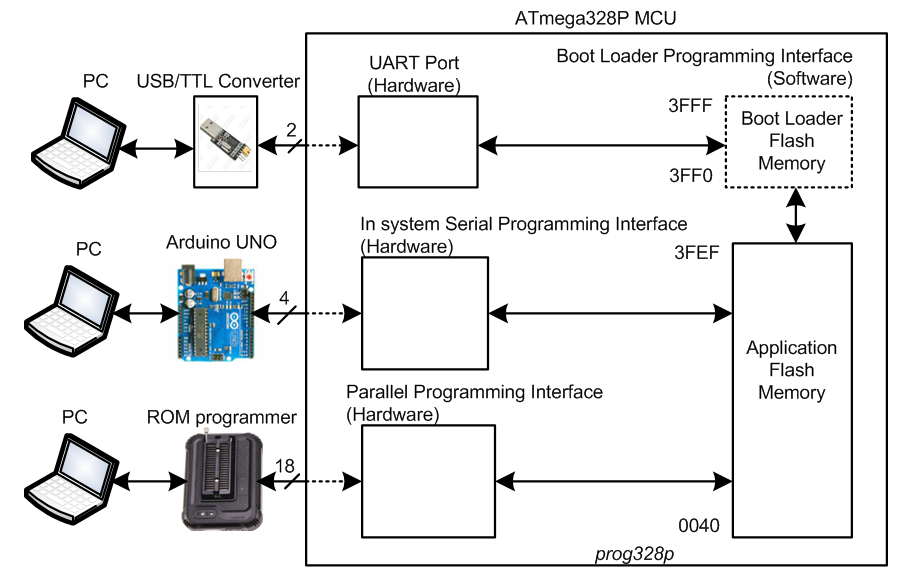
【AVR编程效率提升宝典】:遵循avrdude 6.3手册,实现开发流程优化
# 摘要
本文深入探讨了AVR编程和开发流程,重点分析了avrdude工具的使用与手册解读,从而为开发者提供了一个全面的指南。文章首先概述了avrdude工具的功能和架构,并进一步详细介绍了其安装、配置和在AVR开发中的应用。在开发流程优化方面,本文探讨了如何使用avrdude简化编译、烧录、验证和调
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )