【编译器警告处理手册】:模板特化引发的警告信息解决方案
发布时间: 2024-10-21 00:00:44 阅读量: 41 订阅数: 31 

comsol单相变压器温度场三维模型,可以得到变压器热点温度,流体流速分布
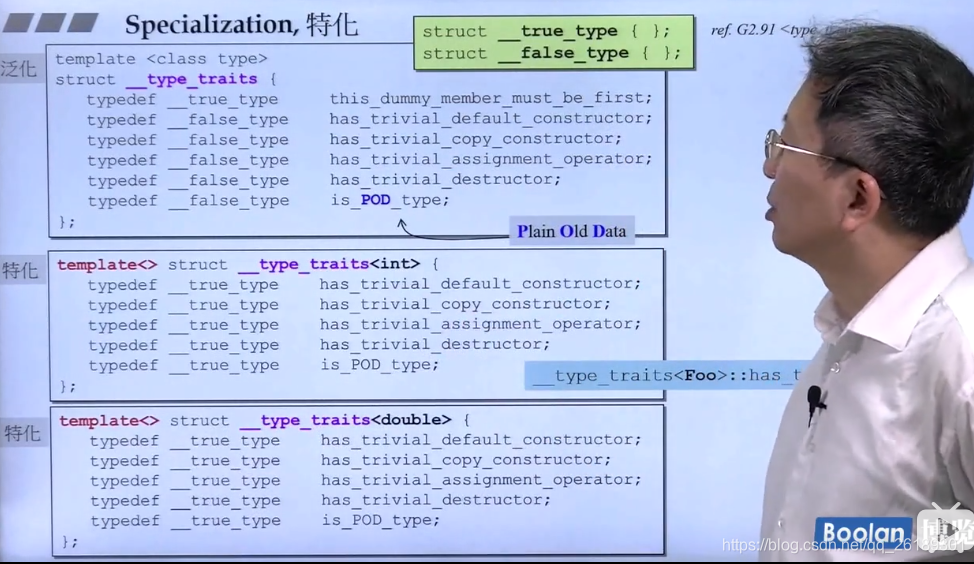
# 1. 模板特化和编译器警告概述
在现代C++编程中,模板特化与编译器警告是确保代码质量和维护性的关键因素。模板特化提供了通用模板的定制化解决方案,而编译器警告则是检查代码潜在问题的重要工具。本章将对模板特化的概念进行简单介绍,并概述编译器警告的重要作用,为后续章节深入探讨奠定基础。
## 1.1 模板特化的简介
模板特化允许开发者为特定类型的模板实例提供定制化实现。它是一种编译时多态性,可以使通用模板在面对特殊需求时,能够有更高效的处理方式。
例如,假设有一个通用模板函数,它对所有类型都适用,但在处理某些特定类型时,可能需要特殊的处理逻辑。这时,模板特化可以定义一个新的函数,专门针对这些特定类型,优化其行为。
## 1.2 编译器警告的作用
编译器警告是帮助开发者识别可能的代码缺陷、性能瓶颈和不安全实践的机制。虽然它们不会阻止程序编译,但警告信息往往提示程序员可能需要关注的代码部分。
例如,当模板代码中出现一些不明原因的警告时,可能意味着模板实例化过程中存在类型不匹配或其他问题。因此,了解和分析警告信息,能够帮助我们优化模板代码,提高程序的稳定性和性能。
在接下来的章节中,我们将深入探讨模板特化的理论基础,并学习如何处理由模板特化引发的编译器警告。
# 2. 模板特化的理论基础
在深入探讨模板特化的理论基础之前,了解模板编程是至关重要的。模板编程是C++等语言中强大的泛型编程特性,它允许开发者编写与数据类型无关的代码,从而提高代码的复用性。而模板特化,作为模板编程的一部分,提供了一种机制,使得开发者可以根据特定类型或模板参数对标准模板行为进行定制。
## 2.1 模板特化的概念和作用
### 2.1.1 模板编程的基本原理
模板编程的核心在于抽象和泛型。通过定义模板,开发者可以创建能够处理不同类型数据的通用函数或类。这种泛型的实现不仅增强了代码的可读性,也提高了其可维护性。
#### 模板的种类
在C++中,模板主要分为两种:函数模板和类模板。
- **函数模板**:允许创建可以接受不同类型参数的通用函数。编译器会根据实际参数类型实例化相应的函数版本。
```cpp
template <typename T>
T max(T a, T b) {
return (a > b) ? a : b;
}
```
- **类模板**:类似函数模板,但用于创建可以处理不同类型数据的通用类。
```cpp
template <typename T>
class Stack {
// Class implementation
};
```
### 2.1.2 模板特化的定义和使用场景
模板特化是指为特定的模板参数提供特定的实现版本。这种机制尤其有用,当标准模板在处理某些特定类型时表现不佳,或者需要针对特定类型进行优化时。
#### 模板特化的语法
特化有全特化和偏特化两种形式:
- **全特化**:针对所有模板参数提供具体类型。
```cpp
template <>
class Stack<int> {
// Specialization for int type
};
```
- **偏特化**:为部分模板参数提供具体类型。
```cpp
template <typename T>
class Stack<T*> {
// Specialization for pointer types
};
```
## 2.2 编译器警告的类型和来源
模板编程虽然强大,但它也带来了一定的复杂性,这在编译时会表现为各种警告和错误。编译器警告通常发生在模板特化过程中的类型匹配、隐式转换和其他编译时检查。
### 2.2.1 常见的编译器警告类型
不同的编译器会有不同的警告机制,但通常包括以下几种:
- **类型不匹配警告**:当模板实例化过程中,期望类型与实际类型不匹配时产生。
- **未使用变量警告**:模板内部声明但未使用的变量会导致此类警告。
- **隐式转换警告**:当模板中发生隐式类型转换时,编译器会发出警告。
### 2.2.2 模板特化可能引发的警告信息
模板特化过程中可能会出现特定的警告:
- **特化定义冲突警告**:当全特化和偏特化互相冲突时,编译器会发出警告。
- **不完全特化警告**:如果模板特化的声明不完全符合模板定义,会收到此类警告。
#### 模板特化编译器警告分析
例如,当模板全特化与部分特化的声明不一致时,可能导致编译器产生混淆:
```cpp
template <typename T>
class Example {
// Generic implementation
};
template <typename T>
class Example<T*> {
// Partial specialization for pointer types
};
template <>
class Example<int> {
// Full specialization, which may conflict with partial specialization
};
```
编译器在此种情况下会发出警告,因为它难以决定使用哪个特化版本。程序员需要调整特化声明,确保清晰无歧义。
下一章,我们将深入探讨模板特化引发警告的诊断技术,包括静态代码分析工具的应用和编译器诊断选项的深入分析,以帮助开发者识别和解决这些潜在问题。
# 3. 模板特化引发警告的诊断技术
模板特化是C++模板编程中的一项高级特性,它允许程序员为特定类型的模板实例提供自定义实现,从而实现更高效的代码或更精细的类型控制。然而,模板特化也可能导致编译器产生难以理解的警告,特别是在复杂模板代码中,这可能会干扰开发流程。本章将探讨模板特化引发警告的诊断技术,帮助开发者有效地识别和解决这些问题。
## 3.1 静态代码分析工具的应用
### 3.1.1 选择合适的静态分析工具
在面对模板特化时,选择合适的静态代码分析工具是至关重要的。现代的静态分析工具能够深入分析模板代码,识别出潜在的警告和错误。常见的静态分析工具有Clang-Tidy、Cppcheck、SonarQube等。这些工具能够针对模板特化进行专门的检查,包括但不限于未特化模板的错误使用、特化定义的不一致性以及潜在的类型匹配问题。
例如,Clang-Tidy是一个与Clang编译器紧密集成的静态分析工具,它能够检测出模板特化过程中的各种问题。当使用Clang-Tidy检查模板特化代码时,可以使用如`-checks=`标志来启用特定的检查模块。
### 3.1.2 解读工具提供的警告信息
静态分析工具提供的警告信息通常非常丰富,但是需要开发者具备一定的解读能力。Clang-Tidy提供的警

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 C++ 模板特化的概念、最佳实践和应用。通过一系列文章,您将了解模板特化的核心原理,掌握实例解析和性能提升策略,避免常见陷阱。专栏还涵盖了全特化和偏特化应用场景,以及 SFIAE 技术在模板特化中的应用。此外,您将学习类型萃取高级技巧,提高代码复用性,编写有效的单元测试,并了解模板特化在库设计和编译器优化中的作用。通过深入理解模板特化,您将能够编写更高效、可维护性更强的 C++ 代码。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Omni-Peek教程】:掌握网络性能监控与优化的艺术

# 摘要
网络性能监控与优化是确保网络服务高效运行的关键环节。本文首先概述了网络性能监控的重要性,并对网络流量分析技术以及网络延迟和丢包问题进行了深入分析。接着,本文介绍了Omni-Peek工具的基础操作与实践应用,包括界面介绍、数据包捕获与解码以及实时监控等。随后,文章深入探讨了网络性能问题的诊断方法,从应用层和网络层两方面分析问题,并探讨了系统资源与网络性能之间的关系。最后,提出了网络性能优
公钥基础设施(PKI)深度剖析:构建可信的数字世界
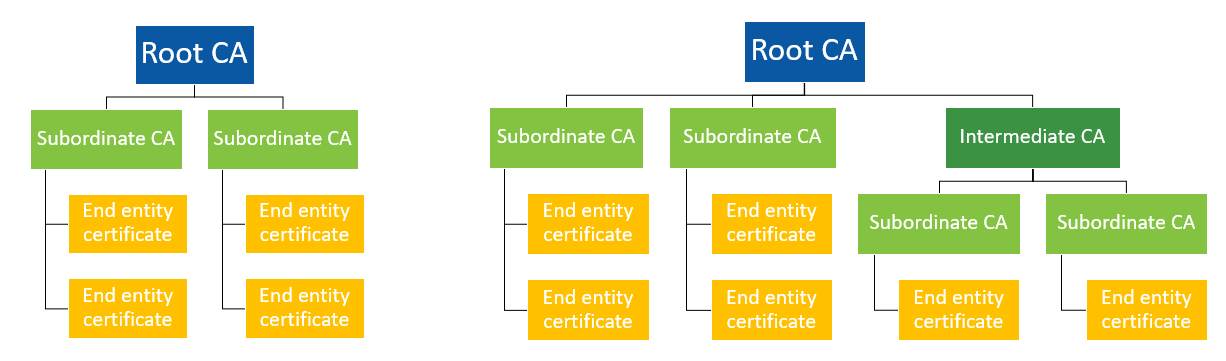
# 摘要
公钥基础设施(PKI)是一种广泛应用于网络安全领域的技术,通过数字证书的颁发与管理来保证数据传输的安全性和身份验证。本文首先对PKI进行概述,详细解析其核心组件包括数字证书的结构、证书认证机构(CA)的职能以及证书颁发和撤销过程。随后,文章探讨了PKI在SSL/TLS、数字签名与身份验证、邮件加密等领域的应用实践,指出其在网络安全中的重要性。接着,分析了PKI实施过程中的
硬件工程师的挑战:JESD22-A104F温度循环测试中的故障诊断与解决方案

# 摘要
JESD22-A104F温度循环测试是电子组件可靠性评估的重要方法,本文概述了其原理、故障分析、实践操作指南及解决方案。文中首先介绍了温度循环测试的理论基础,阐释了测试标准和对电子组件影响的原理。接着,分析了硬件故障类型及其诊断方法,强调了故障诊断工具的应用。第三章深入探讨了测试设备的配置、测试流程及问题应对策略。第四章则集中于
机器人动力学计算基础:3种方法利用Robotics Toolbox轻松模拟

# 摘要
本论文探讨了机器人动力学计算的基础知识,并对Robotics Toolbox的安装、配置及其在机器人建模和动力学模拟中的应用进行了详细介绍。通过对机器人连杆表示、运动学计算方法的阐述,以及Robotics Toolbox功能的介绍,本文旨在提供机器人建模的技术基础和实践指南。此外,还比较了基于拉格朗日方程、牛顿-欧拉方法和虚功原理的三种动力学模拟方法,并
【AST2400兼容性分析】:与其他硬件平台的对比优势

# 摘要
本文全面探讨了AST2400硬件平台的兼容性问题,从兼容性理论基础到与其他硬件平台的实际对比分析,再到兼容性实践案例,最后提出面临的挑战与未来发展展望。AS
【线性规划在电影院座位设计中的应用】:座位资源分配的黄金法则
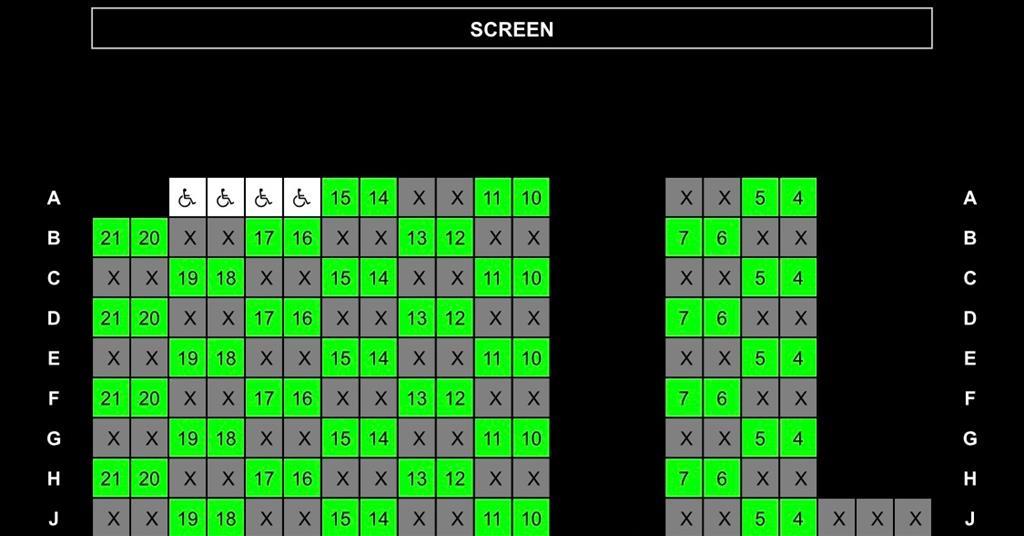
# 摘要
本文系统介绍了线性规划的基本概念、数学基础及其在资源分配中的应用,特别关注了电影院座位设计这一具体案例。文章首先概述了线性规划的重要性,接着深入分析了线性规划的理论基础、模型构建过程及求解方法。然后,本文将线性规划应用于电影院座位设计,包括资源分配的目标与限制条件,以及实际案例的模型构建与求解过程。文章进一步讨论
【语义分析与错误检测】:编译原理中的5大常见错误处理技巧

# 摘要
语义分析与错误检测是编译过程中的关键步骤,直接影响程序的正确性和编译器的健壮性。本文从编译器的错误处理机制出发,详细探讨了词法分析、语法分析以及语义分析中错误的
【PCB Layout信号完整性:深入分析】
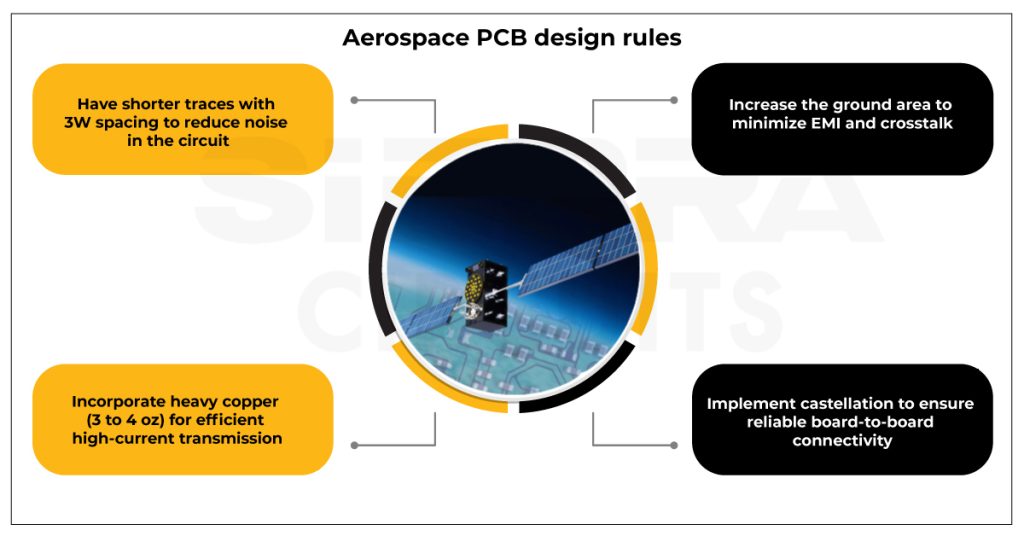
# 摘要
本文深入探讨了PCB布局与信号完整性之间的关系,并从理论基础到实验测试提供了全面的分析。首先,本文阐述了信号完整性的关键概念及其重要性,包括影响因素和传输理论基础。随后,文章详细介绍了PCB布局设计的实践原则,信号层与平面设计技巧以及接地与电源设计的最佳实践。实验与测试章节重点讨论了信号完整性测试方法和问题诊断策略。最后,文章展望了新兴技术
【文件和参数精确转换】:PADS数据完整性提升的5大策略
# 摘要
在数字化时代背景下,文件和参数的精确转换对保持数据完整性至关重要。本文首先探讨了数据完整
MapReduce深度解析:如何从概念到应用实现精通

# 摘要
MapReduce作为一种分布式计算模型,在处理大数据方面具有重要意义。本文首先概述了MapReduce的基本概念及其计算模型,随后深入探讨了其核心理论,包括编程模型、数据流和任务调度、以及容错机制。在实践应用技巧章节中,本文详细介绍了Hadoop环境的搭建、MapReduce程序的编写和性能优化,并通过具体案例分析展示了MapReduce在数据分析中的应用。接着,文章探讨了MapR
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )