【Python量化交易框架剖析:简化开发的开源工具】
发布时间: 2024-12-15 19:07:04 阅读量: 13 订阅数: 14 

基于Python的开源量化交易平台开发框架

参考资源链接:[Python量化交易全面指南:从入门到实战](https://wenku.csdn.net/doc/7vf9wi218o?spm=1055.2635.3001.10343)
# 1. Python量化交易框架概述
## 1.1 量化交易简介
量化交易是一种使用数学模型和计算机程序进行交易决策的方法。它依赖于算法和统计模型来分析市场数据,旨在通过自动化流程捕捉市场机会。量化交易的兴起,特别是在引入Python后,为金融分析和交易带来了革命性的变化。
## 1.2 Python作为量化工具的优势
Python语言因其简洁明了的语法和强大的库支持,在量化交易领域获得了广泛的青睐。Python能够轻松处理复杂的数据结构,对接金融市场数据,并通过丰富的科学计算和可视化库支持决策过程。这些特性使得Python成为金融工程师和交易员理想的选择。
## 1.3 量化交易框架的作用
量化交易框架是为量化交易策略的开发、测试和部署提供支持的软件结构。它们通常包括数据处理、策略开发、回测、风险管理和执行等核心组件。一个好的框架能够大幅提高开发效率,保障交易策略的性能和稳定性。接下来的章节将深入探讨Python中的常用量化交易框架,以及如何有效地利用它们构建和优化量化交易平台。
# 2.1 量化交易基本概念
量化交易是一种基于数学模型的交易方式,其核心思想是通过数学模型来指导投资决策。这种方式可以大大减少投资者的主观情绪影响,提高交易的客观性和准确性。
### 2.1.1 量化交易定义及优势
量化交易的定义是使用数学模型来预测市场趋势,从而制定买卖决策的一种交易方式。这种交易方式的优势在于其客观性。数学模型不受情绪影响,可以持续稳定地执行策略。此外,量化交易还可以处理大量的数据,进行复杂的计算,这是一般交易者难以做到的。
### 2.1.2 常见量化交易策略简介
常见的量化交易策略包括动量策略、套利策略、对冲策略等。动量策略是基于历史数据,寻找价格上涨或下跌的趋势,并据此进行交易。套利策略则是寻找市场中的价格差异,通过买入价格较低的资产,卖出价格较高的资产来获利。对冲策略则是通过同时进行多空操作,降低风险,获取稳定的收益。
## 2.2 Python在量化交易中的角色
Python是一种高级编程语言,因其简洁的语法和强大的库支持,在量化交易领域得到了广泛的应用。
### 2.2.1 Python语言特点
Python的语法简洁明了,易于学习和使用。同时,Python拥有丰富的库,涵盖了数据处理、数据分析、机器学习等多个领域,非常适合进行量化交易的开发工作。
### 2.2.2 Python在金融市场分析中的应用
Python在金融市场分析中的应用非常广泛,从数据采集、数据清洗、数据可视化到策略开发、策略回测、性能评估,Python都可以做到。Python的Pandas库、NumPy库、Matplotlib库等,在数据处理和可视化方面提供了强大的支持。而Python的Scikit-learn库、TensorFlow库、Keras库等,则在机器学习和深度学习方面提供了强大的支持。
## 2.3 金融市场数据获取与处理
获取准确、及时的金融市场数据是量化交易的第一步,数据的清洗和预处理则是确保数据质量的关键。
### 2.3.1 数据采集方法与API使用
金融市场数据可以通过多种方式获取,包括API接口、爬虫技术等。API是一种非常方便的数据获取方式,许多金融数据服务商都提供了API接口,可以直接获取所需的数据。Python的requests库和BeautifulSoup库,可以方便地实现API调用和网页数据的爬取。
### 2.3.2 数据清洗与预处理技巧
数据清洗和预处理是数据科学工作中非常重要的一步。在获取原始数据后,需要对其进行清洗和预处理,以保证数据的质量。数据清洗包括去除重复数据、填充缺失值、处理异常值等。数据预处理则包括数据归一化、数据编码、特征选择等。Python的Pandas库在数据清洗和预处理方面提供了强大的支持。
```python
import pandas as pd
# 假设df是已经获取的DataFrame数据
# 数据清洗示例:去除重复数据
df_cleaned = df.drop_duplicates()
# 数据预处理示例:填充缺失值
df_filled = df_cleaned.fillna(method='ffill')
# 数据预处理示例:数据归一化
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df_scaled = pd.DataFrame(scaler.fit_transform(df_filled), columns=df_filled.columns)
```
通过上述Python代码,我们可以实现数据的清洗和预处理。在实际应用中,根据数据的特点和需求,可能需要进行更复杂的数据处理。
在接下来的内容中,我们将继续深入探讨量化交易框架的构建与应用,包括量化交易策略的开发与优化、量化交易平台的性能评估、以及实战案例的分析与总结。量化交易不仅仅是一项技术活动,它还涉及到金融市场学、数学建模、数据科学等多个领域的知识,是IT行业与金融行业交叉融合的产物。通过量化交易的学习和实践,我们可以更好地理解金融市场的运作机制,提升交易技能,实现财富的稳健增长。
# 3. 常用Python量化交易框架实践
## 3.1 Zipline框架入门与应用
### 3.1.1 Zipline框架简介
Zipline是一个开放源代码的Python库,它用于算法交易回测,特别是在金融市场研究和量化分析中。它是Quantopian平台的回测引擎,并且可以独立安装和使用。Zipline旨在提供一个易于理解和使用的回测系统,允许用户专注于交易策略的研究和开发,而不必担心底层的数据处理和回测引擎的细节。
Zipline的设计着重于清晰和模块化,支持自定义数据源、交易算法、市场模拟器和统计分析。它特别适合需要进行复杂回测和策略评估的量化分析师和投资者。
### 3.1.2 创建策略与回测演示
在Zipline中创建策略的基本步骤包括定义算法的初始化(`initialize`函数)和交易逻辑(`handle_data`函数)。下面是创建一个简单移动平均交叉策略的示例。
首先安装Zipline库:
```bash
pip install zipline
```
然后创建一个Python文件,定义策略:
```python
from zipline.api import order_target_percent, record, symbol
def initialize(context):
context.asset = symbol('AAPL')
def handle_data(context, data):
prices = data.history(context.asset, 'price', 100, '1d')
short_window = 40
long_window = 100
short_mavg = prices[-short_window:].mean()
long_mavg = prices[-long_window:].mean()
if short_mavg > long_mavg:
order_target_percent(context.asset, 1.0)
elif short_mavg < long_mavg:
order_target_percent(context.asset, 0.0)
record(AAPL=data.current(context.asset, 'price'))
```
在定义了策略之后,接下来是运行回测。假设我们已经保存了策略到一个文件`zipline_strategy.py`中,回测可以通过以下代码执行:
```python
import zipline
from zipline.data.bundles import load
# 加载数据包,这里以csvdir为例
load('csvdir')
# 执行回测
results = zipline.run_algorithm(
initialize=initialize,
handle_data=handle_data,
start=pd.Timestamp('2018-01-01', tz='utc'),
end=pd.Timestamp('2020-01-01', tz='utc'),
bundle='csvdir',
analyze=False
)
# 可视化结果
import pyfolio as pf
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供了一系列关于 Python 量化交易的教程,涵盖从基础到高级的各个方面。它将指导你从数据处理到实时交易系统构建的整个过程。专栏内容包括:
* 数据处理:了解如何获取和处理金融市场数据。
* 风险管理:学习策略优化和风险控制技术,以管理你的交易风险。
* 多因子模型:探索多因子模型在量化交易中的应用。
* 交易机器人:构建你的自动化交易机器人。
* 开源工具:了解简化量化交易开发的开源框架。
* 遗传算法:利用遗传算法优化你的交易策略。
* 回测:设计历史数据回测框架,以评估你的策略表现。
* VaR:深入了解价值在风险 (VaR) 在量化交易中的应用。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Omni-Peek教程】:掌握网络性能监控与优化的艺术

# 摘要
网络性能监控与优化是确保网络服务高效运行的关键环节。本文首先概述了网络性能监控的重要性,并对网络流量分析技术以及网络延迟和丢包问题进行了深入分析。接着,本文介绍了Omni-Peek工具的基础操作与实践应用,包括界面介绍、数据包捕获与解码以及实时监控等。随后,文章深入探讨了网络性能问题的诊断方法,从应用层和网络层两方面分析问题,并探讨了系统资源与网络性能之间的关系。最后,提出了网络性能优
公钥基础设施(PKI)深度剖析:构建可信的数字世界
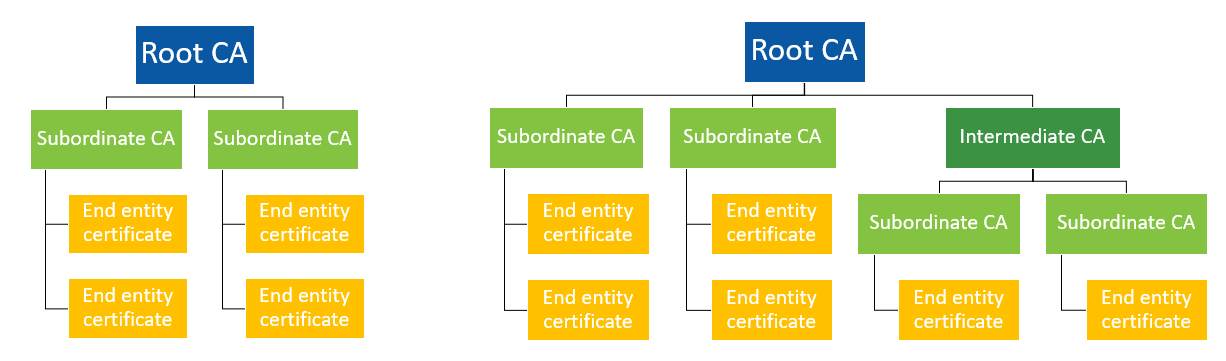
# 摘要
公钥基础设施(PKI)是一种广泛应用于网络安全领域的技术,通过数字证书的颁发与管理来保证数据传输的安全性和身份验证。本文首先对PKI进行概述,详细解析其核心组件包括数字证书的结构、证书认证机构(CA)的职能以及证书颁发和撤销过程。随后,文章探讨了PKI在SSL/TLS、数字签名与身份验证、邮件加密等领域的应用实践,指出其在网络安全中的重要性。接着,分析了PKI实施过程中的
硬件工程师的挑战:JESD22-A104F温度循环测试中的故障诊断与解决方案

# 摘要
JESD22-A104F温度循环测试是电子组件可靠性评估的重要方法,本文概述了其原理、故障分析、实践操作指南及解决方案。文中首先介绍了温度循环测试的理论基础,阐释了测试标准和对电子组件影响的原理。接着,分析了硬件故障类型及其诊断方法,强调了故障诊断工具的应用。第三章深入探讨了测试设备的配置、测试流程及问题应对策略。第四章则集中于
机器人动力学计算基础:3种方法利用Robotics Toolbox轻松模拟

# 摘要
本论文探讨了机器人动力学计算的基础知识,并对Robotics Toolbox的安装、配置及其在机器人建模和动力学模拟中的应用进行了详细介绍。通过对机器人连杆表示、运动学计算方法的阐述,以及Robotics Toolbox功能的介绍,本文旨在提供机器人建模的技术基础和实践指南。此外,还比较了基于拉格朗日方程、牛顿-欧拉方法和虚功原理的三种动力学模拟方法,并
【AST2400兼容性分析】:与其他硬件平台的对比优势

# 摘要
本文全面探讨了AST2400硬件平台的兼容性问题,从兼容性理论基础到与其他硬件平台的实际对比分析,再到兼容性实践案例,最后提出面临的挑战与未来发展展望。AS
【线性规划在电影院座位设计中的应用】:座位资源分配的黄金法则
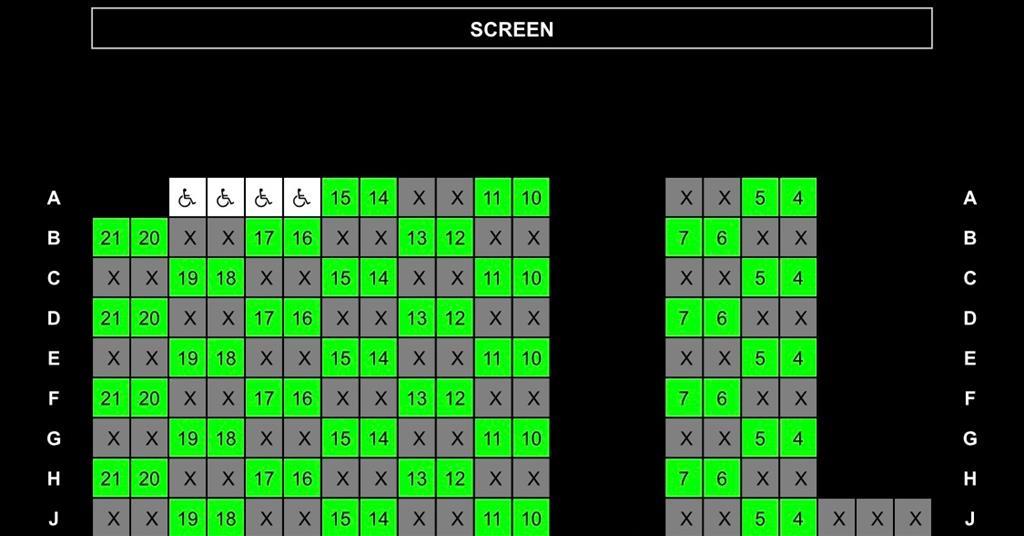
# 摘要
本文系统介绍了线性规划的基本概念、数学基础及其在资源分配中的应用,特别关注了电影院座位设计这一具体案例。文章首先概述了线性规划的重要性,接着深入分析了线性规划的理论基础、模型构建过程及求解方法。然后,本文将线性规划应用于电影院座位设计,包括资源分配的目标与限制条件,以及实际案例的模型构建与求解过程。文章进一步讨论
【语义分析与错误检测】:编译原理中的5大常见错误处理技巧

# 摘要
语义分析与错误检测是编译过程中的关键步骤,直接影响程序的正确性和编译器的健壮性。本文从编译器的错误处理机制出发,详细探讨了词法分析、语法分析以及语义分析中错误的
【PCB Layout信号完整性:深入分析】
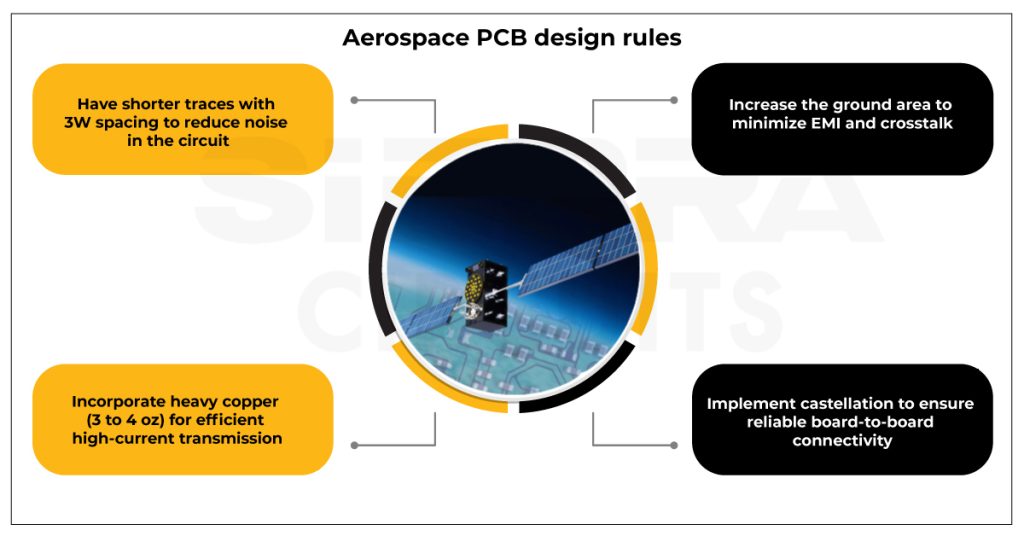
# 摘要
本文深入探讨了PCB布局与信号完整性之间的关系,并从理论基础到实验测试提供了全面的分析。首先,本文阐述了信号完整性的关键概念及其重要性,包括影响因素和传输理论基础。随后,文章详细介绍了PCB布局设计的实践原则,信号层与平面设计技巧以及接地与电源设计的最佳实践。实验与测试章节重点讨论了信号完整性测试方法和问题诊断策略。最后,文章展望了新兴技术
【文件和参数精确转换】:PADS数据完整性提升的5大策略
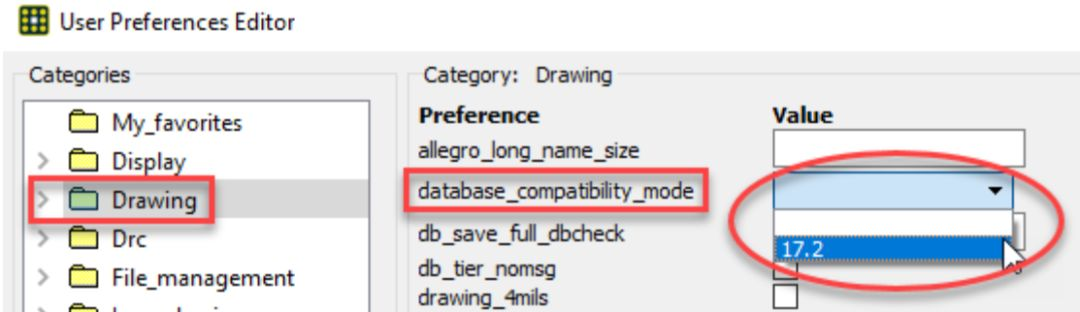
# 摘要
在数字化时代背景下,文件和参数的精确转换对保持数据完整性至关重要。本文首先探讨了数据完整
MapReduce深度解析:如何从概念到应用实现精通

# 摘要
MapReduce作为一种分布式计算模型,在处理大数据方面具有重要意义。本文首先概述了MapReduce的基本概念及其计算模型,随后深入探讨了其核心理论,包括编程模型、数据流和任务调度、以及容错机制。在实践应用技巧章节中,本文详细介绍了Hadoop环境的搭建、MapReduce程序的编写和性能优化,并通过具体案例分析展示了MapReduce在数据分析中的应用。接着,文章探讨了MapR
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )