【Java核心技术揭秘】:IKM测试中的10个必考点精讲
发布时间: 2024-12-06 12:14:46 阅读量: 11 订阅数: 11 

IKM在线测试 JAVA 88题带参考答案
参考资源链接:[Java IKM在线测试:Spring IOC与多线程实战](https://wenku.csdn.net/doc/6412b4c1be7fbd1778d40b43?spm=1055.2635.3001.10343)
# 1. Java核心技术要点概述
Java语言自1995年问世以来,凭借其"一次编写,到处运行"的跨平台特性,成为了企业级应用开发的首选语言之一。本章将概述Java的核心技术要点,包括Java的基本概念、运行机制以及在实际应用中的核心功能。
首先,Java是一种面向对象的编程语言,它通过封装、继承和多态性等面向对象的原则,让代码的结构更为清晰,便于管理和维护。其次,Java拥有丰富的类库,为开发者提供了大量预定义的接口和类,这大大简化了日常开发的工作量。
在企业级应用中,Java的健壮性、安全性、跨平台性等特点使其成为开发关键业务系统不可或缺的语言。本章的讨论将为读者打下坚实的基础,为深入理解后续章节中的高级特性和应用做好铺垫。
# 2. Java基础语法深入分析
## 2.1 数据类型和变量
### 2.1.1 基本数据类型特性
Java的基础数据类型包括了整型、浮点型、字符型和布尔型。它们有固定的大小和不同的取值范围,这直接关系到内存的使用和性能开销。
- **整型**:包括byte、short、int和long四种,它们的取值范围不同。例如,byte的范围是-128到127,而int的范围则是-2^31到2^31-1。在选择数据类型时,应根据实际需要,尽可能选择存储范围较小的类型,以节省内存。
- **浮点型**:有float和double两种,分别占用32位和64位。由于浮点数的表示方法,可能会出现精度丢失的问题,特别是在进行大量计算时。
- **字符型**:使用char表示,占用16位,其表示的是Unicode字符,能够表示大多数语言中的字符。
- **布尔型**:由boolean表示,只有两个值:true和false。
在Java中,变量的声明需要指定其数据类型。例如:
```java
int age = 25;
double salary = 4000.50;
boolean isAvailable = true;
```
**代码逻辑分析:**
在上述代码块中,我们声明了三个不同类型的变量,分别是整型、浮点型和布尔型。每个变量在声明的同时被赋予了初始值。这种类型声明的方式对于Java虚拟机(JVM)来说至关重要,因为JVM需要知道为每个变量分配多少内存空间。
### 2.1.2 引用数据类型和数组
引用数据类型指的是类、接口和数组类型。引用类型的变量存放的是对象的引用,而实际对象则存储在堆内存中。Java中的数组是一种引用类型,是一种可以存储固定大小的相同类型元素的数据结构。
- **数组**:数组在声明时要指定类型和长度。例如:`int[] numbers = new int[10];` 声明了一个包含10个整数的数组。数组可以是单维的,也可以是多维的。
**代码逻辑分析:**
```java
int[] myArray = new int[5]; // 声明一个长度为5的整型数组
myArray[0] = 1; // 为数组的第一个元素赋值
```
在上述代码中,我们首先声明了一个长度为5的整型数组`myArray`。之后,我们通过索引为数组的第一个元素赋值为1。索引从0开始,因此`myArray[0]`代表数组的第一个元素。
**表格展示:**
| 数据类型 | 占用空间 | 取值范围 | 默认值 |
| -------- | -------- | ------------------------------- | ------ |
| byte | 1 字节 | -128 到 127 | 0 |
| short | 2 字节 | -32,768 到 32,767 | 0 |
| int | 4 字节 | -2^31 到 2^31-1 | 0 |
| long | 8 字节 | -2^63 到 2^63-1 | 0L |
| float | 4 字节 | 大约 ±3.40282347E+38F (6-7 有效数字) | 0.0f |
| double | 8 字节 | 大约 ±1.79769313486231570E+308 (15有效数字) | 0.0d |
| boolean | 未定义 | true 或 false | false |
| char | 2 字节 | '\u0000' (即为 0) 到 '\uffff' (即为 65,535) | '\u0000' |
> 注意:在Java中,char类型使用的是16位的Unicode编码,而boolean类型的大小并没有明确定义。
## 2.2 控制流语句
### 2.2.1 条件控制结构
在编写程序时,经常需要根据不同的条件执行不同的代码块。Java提供了if-else、switch-case等条件控制结构来实现这一逻辑。
- **if-else 结构**:根据条件表达式的真假来决定执行哪个代码块。
```java
int score = 85;
if (score > 90) {
System.out.println("优秀");
} else if (score > 80) {
System.out.println("良好");
} else {
System.out.println("及格");
}
```
**逻辑分析:**
在这个if-else结构示例中,我们首先定义了一个名为`score`的变量,它代表了某种评分。接着,通过一系列的条件判断,输出对应的等级。如果`score`大于90分,则输出"优秀";如果大于80分,则输出"良好";否则输出"及格"。这种结构可以根据需要扩展更多的条件判断。
### 2.2.2 循环控制结构
循环控制结构允许重复执行特定的代码块,直到满足某些条件为止。Java中包括for循环、while循环和do-while循环。
- **for循环**:一般用于循环次数已知的情况。
```java
for (int i = 0; i < 5; i++) {
System.out.println("循环次数: " + i);
}
```
**逻辑分析:**
for循环结构定义了循环变量`i`,并且在每次循环结束后修改`i`的值。这里,循环将执行5次,变量`i`从0开始,每次循环后递增1,直到`i`等于5时退出循环。
## 2.3 面向对象编程
### 2.3.1 类与对象的理解
面向对象编程(OOP)是一种编程范式,它使用对象来描述现实世界中的事物。对象是类的实例,而类是创建对象的模板。
- **类**:包含成员变量(属性)和成员方法(行为),用于描述事物的属性和行为。
- **对象**:是根据类创建的实例,具有类中定义的所有属性和方法。
**代码逻辑分析:**
```java
public class Car {
private String brand;
private String model;
private int year;
public Car(String brand, String model, int year) {
this.brand = brand;
this.model = model;
this.year = year;
}
public void startEngine() {
System.out.println("Engine started.");
}
}
// 创建Car对象
Car myCar = new Car("Toyota", "Corolla", 2021);
myCar.startEngine();
```
在上述示例中,首先定义了一个名为`Car`的类,包含了三个私有成员变量以及一个构造方法和一个普通方法。之后,我们创建了一个`Car`的实例`myCar`,并调用了`startEngine`方法来模拟启动引擎。
### 2.3.2 继承、封装、多态的实现与应用
继承、封装和多态是面向对象编程的三大特性。
- **继承**:一个类可以继承另一个类的属性和方法,被继承的类称为父类或超类,继承的类称为子类。在Java中,使用`extends`关键字来实现继承。
```java
public class Vehicle {
protected String color;
public Vehicle(String color) {
this.color = color;
}
public void displayColor() {
System.out.println("This vehicle's color is " + this.color);
}
}
public class Car extends Vehicle {
private int doors;
public Car(String color, int doors) {
super(color); // 调用父类的构造方法
this.doors = doors;
}
public void displayDoors() {
System.out.println("This car has " + this.doors + " doors.");
}
}
```
在上面的代码中,`Car`类继承了`Vehicle`类,并添加了一个新的属性`doors`和一个方法`displayDoors`。`Car`类通过`super`关键字调用了父类的构造方法来初始化继承的属性。
- **封装**:隐藏对象的属性和实现细节,对外只提供公共访问方式。封装通过使用private关键字来实现。
- **多态**:指允许不同类的对象对同一消息做出响应。在Java中,多态主要通过方法重载和方法重写实现。
在OOP中,这三大特性使得程序结构更加清晰,同时增加了代码的复用性和灵活性。通过继承,我们可以将父类的通用属性和方法在子类中继续使用;通过封装,我们可以保护对象的状态不被外部代码随意修改;通过多态,我们可以编写出通用的代码,适应不同类型的对象。
这些概念是Java编程中的基础,并为高级编程提供了坚实的基础。在后续的章节中,我们将进一步探索如何在Java中利用这些面向对象的特性来编写更加灵活和强大的应用程序。
# 3. Java高级特性与API应用
## 3.1 集合框架详解
### 3.1.1 List、Set、Map的区别与选择
在Java的集合框架中,List、Set和Map是最基本的集合类型,它们各自拥有不同的特点和用途。
**List**接口,代表了有序集合,允许存储重复的元素。用户可以通过索引来访问集合中的元素,这使得它非常适合需要排序或者索引访问元素的场景。例如,当需要维护一个元素的添加顺序时,`ArrayList`是首选,而`LinkedList`在需要频繁插入和删除操作的场景下更为合适。
**Set**接口,是一种不允许重复元素的集合类型。它的实现类通常用来进行集合数学运算,如求交集、并集等。`HashSet`基于`HashMap`实现,对于快速检索元素十分有效,而`TreeSet`可以保持元素的排序状态,适用于需要排序的场景。
**Map**接口,是一种键值对集合,每个键映射到一个值。Map结构不记录插入顺序,也不允许键的重复。它特别适用于需要快速检索数据的场景。例如,`HashMap`提供了高效的键值对存储,而`TreeMap`则可以根据键排序。
选择哪种集合类型取决于具体的应用需求:
- 需要有序访问元素时,选用List。
- 需要快速查找元素并且不允许重复时,选用Set。
- 需要通过键来快速检索值时,选用Map。
### 3.1.2 迭代器模式的应用
Java集合框架使用迭代器模式(Iterator Pattern)来遍历集合元素。迭代器是一个对象,它提供了访问容器内元素的方法,而不需要暴露该容器的内部表示。
迭代器模式的主要好处是它提供了一个统一的遍历接口,使得不同的集合类型可以使用相同的遍历方式。这意味着,无论你使用的是List、Set还是Map,都可以通过迭代器来遍历其元素。
迭代器的基本使用方法如下:
```java
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
// 处理每个元素
}
```
迭代器模式允许在遍历过程中删除元素,这是原生的for循环无法做到的:
```java
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
if (shouldRemove(element)) {
iterator.remove(); // 安全地从集合中删除当前元素
}
}
```
## 3.2 异常处理机制
### 3.2.1 异常类层次结构
Java中的异常处理是一种强大的机制,用来处理程序运行时发生的错误。Java异常是通过一个异常类的层次结构来表示的,这个层次结构的根类是`Throwable`。`Throwable`有两个重要的子类:`Error`和`Exception`。
- `Error`类代表了JVM无法处理的严重问题,通常是系统错误或资源不足等情况。这类错误不应该被捕获,程序也无法恢复。
- `Exception`类及其子类代表了可以被程序处理的异常情况。`Exception`又有两个主要子类:`RuntimeException`和非`RuntimeException`。
`RuntimeException`通常是由于编程错误引起的,例如数组越界、空指针访问等。这类异常可以被捕获,但是最佳实践是避免它们的发生。
非`RuntimeException`通常由外部错误条件引起,如文件不存在、网络连接失败等。这类异常应该被程序捕获和处理。
### 3.2.2 自定义异常与异常处理实践
在实际开发中,经常会遇到现有的异常类无法精确描述问题的情况。此时,可以通过创建自定义异常类来补充异常类型。自定义异常应该继承`Exception`类或其子类,并可能覆盖构造函数,添加额外的错误信息。
以下是一个自定义异常类的例子:
```java
public class MyException extends Exception {
public MyException(String message) {
super(message);
}
public MyException(String message, Throwable cause) {
super(message, cause);
}
}
```
在实际代码中,自定义异常需要被合理地抛出和捕获。当异常情况发生时,应该抛出最具体的异常类型。捕获异常时,应该从异常类型最具体开始,逐级向上直到`Exception`,这样可以保证捕获到预期的异常,而不遗漏任何可能发生的异常。
```java
try {
// 可能发生异常的代码
} catch (SpecificException e) {
// 处理特定的异常
} catch (Exception e) {
// 处理其它所有异常
}
```
在异常处理过程中,应该尽量避免捕获`Exception`或`Throwable`,这样做会隐藏程序的错误,使得调试和维护变得更加困难。
## 3.3 输入输出流(I/O)
### 3.3.1 文件读写与字节流、字符流
在Java中,I/O操作主要通过`java.io`包提供的类和接口来实现。处理文件时,主要涉及到字节流和字符流两种类型。字节流(`InputStream`和`OutputStream`)用于处理原始的二进制数据;字符流(`Reader`和`Writer`)则用于处理字符数据,内部进行了字符和字节的转换。
使用字节流和字符流进行文件读写的基本代码如下:
```java
// 字节流文件写入
try (FileOutputStream fos = new FileOutputStream("example.bin")) {
byte[] data = "Hello World".getBytes();
fos.write(data);
}
// 字节流文件读取
try (FileInputStream fis = new FileInputStream("example.bin")) {
byte[] buffer = new byte[1024];
int length;
while ((length = fis.read(buffer)) != -1) {
// 处理读取到的数据
}
}
// 字符流文件写入
try (FileWriter fw = new FileWriter("example.txt")) {
String data = "Hello World";
fw.write(data);
}
// 字符流文件读取
try (FileReader fr = new FileReader("example.txt")) {
char[] buffer = new char[1024];
int length;
while ((length = fr.read(buffer)) != -1) {
// 处理读取到的数据
}
}
```
通常情况下,如果处理的是文本数据,推荐使用字符流,因为它们直接操作字符,更方便处理文本数据。对于非文本的二进制数据,如图片、音频文件等,应该使用字节流。
### 3.3.2 NIO和网络编程基础
Java的NIO(New Input/Output)是一个可以替代标准Java I/O API的I/O库,它提供了更高效的I/O操作方式。NIO基于缓冲区(Buffer)和通道(Channel)的概念,可以实现更灵活的I/O操作。
网络编程是NIO的一个重要应用方向,Java提供了`Socket`和`ServerSocket`等类用于网络通信。NIO中的`Selector`类可用于实现非阻塞的网络通信,允许多个网络连接复用一个线程。
以下是一个简单的NIO网络编程的例子:
```java
// 服务器端代码
Selector selector = Selector.open();
ServerSocketChannel ssc = ServerSocketChannel.open();
ssc.configureBlocking(false);
ssc.bind(new InetSocketAddress(8080));
ssc.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
int readyChannels = selector.select();
if (readyChannels == 0) continue;
Set<SelectionKey> selectedKeys = selector.selectedKeys();
Iterator<SelectionKey> keyIterator = selectedKeys.iterator();
while (keyIterator.hasNext()) {
SelectionKey key = keyIterator.next();
if (key.isAcceptable()) {
// 接受连接
} else if (key.isReadable()) {
// 处理读
} else if (key.isWritable()) {
// 处理写
}
keyIterator.remove();
}
}
```
```java
// 客户端代码
SocketChannel client = SocketChannel.open();
client.connect(new InetSocketAddress("localhost", 8080));
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 发送请求、读取响应等操作...
```
NIO提供了比传统IO更高级的特性,例如异步I/O、缓冲区的零拷贝等,这些特性在需要高性能网络通信的应用中尤为重要。
# 4. Java并发编程与多线程机制
## 4.1 线程与进程概念
在操作系统层面,线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一个进程可以创建和销毁线程,自己拥有多个线程在执行任务时,可以实现并行处理,提高程序的执行效率。
### 4.1.1 Java中的线程模型
Java中,线程的创建和使用是并发编程的核心内容之一。Java提供了两种创建线程的方法:通过继承Thread类和实现Runnable接口。在这两种方式下,都能得到一个Thread对象,该对象代表一个线程,可以被调度执行。
```java
// 使用继承Thread类的方式创建线程
class MyThread extends Thread {
public void run() {
// 这里写上需要执行的任务
}
}
// 使用实现Runnable接口的方式创建线程
class MyRunnable implements Runnable {
public void run() {
// 这里写上需要执行的任务
}
}
// 启动线程
MyThread thread = new MyThread();
thread.start();
MyRunnable runnable = new MyRunnable();
Thread thread = new Thread(runnable);
thread.start();
```
通过上述代码可以看出,无论是通过继承Thread类还是通过实现Runnable接口来创建线程,最终都是通过调用线程对象的start()方法来启动线程的。该方法会导致JVM创建一个新的执行栈,并开始执行run()方法中的代码。
### 4.1.2 线程状态与生命周期
Java线程具有以下几种状态:NEW(新建)、RUNNABLE(可运行)、BLOCKED(阻塞)、WAITING(等待)、TIMED_WAITING(计时等待)、TERMINATED(终止)。线程的状态转换是由线程的调度机制决定的。
- NEW:线程已被创建,但尚未启动。调用start()方法后,状态会变为RUNNABLE。
- RUNNABLE:线程正在JVM中执行,可能正在运行,也可能正在等待CPU分配时间片。
- BLOCKED:线程被阻塞,等待一个监视器锁(synchronized)。
- WAITING:线程无限期等待另一个线程执行特定操作,例如Object.wait()。
- TIMED_WAITING:线程在指定的时间内等待另一个线程执行操作,例如Thread.sleep(long millis)。
- TERMINATED:线程的run()方法执行完毕或出现异常退出。
## 4.2 线程同步与锁机制
同步是多线程编程中的一个关键概念。由于多线程可以同时操作共享数据,导致数据状态不一致的问题,因此需要引入同步机制来协调线程之间的操作。
### 4.2.1 同步代码块与同步方法
Java提供了synchronized关键字,用于控制线程对共享资源的访问。synchronized可以用于方法声明,或者方法内部的一个代码块。
```java
public class Counter {
private int count = 0;
// 同步方法
public synchronized void increment() {
count++;
}
// 同步代码块
public void decrement() {
synchronized(this) {
count--;
}
}
}
```
在上述例子中,increment方法和decrement方法中的同步代码块确保了每次只有一个线程能够修改count变量的值。使用synchronized关键字可以保证在方法或者代码块执行时,只有一个线程可以进入临界区。
### 4.2.2 死锁的避免与处理
死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种僵局,若无外力作用,它们都将无法推进下去。在Java多线程环境中,死锁同样可能发生,因此需要采取措施进行避免和处理。
避免死锁的常用策略包括:
- 避免一个线程在等待其他线程释放资源的时候持有锁。
- 使用超时机制来解除锁定。
- 尽量减少锁的持有时间。
- 为锁定的资源设置一个全局的顺序,并确保所有线程都按照该顺序获取锁。
处理死锁时,可以通过JVM提供的工具如jstack来分析线程的堆栈信息,从而定位死锁发生的原因和位置。
## 4.3 高级并发API
随着Java版本的迭代,JDK引入了许多高级并发API,这些API使得并发编程更加简便和高效。
### 4.3.1 线程池的使用与原理
线程池是实现线程管理的一种机制,它可以复用一组线程来执行不同任务。使用线程池可以减少在创建和销毁线程上所花的时间和资源,尤其在大量短任务并发执行时,可以显著提高性能。
Java中通过Executor框架来实现线程池管理。Executor框架有多种实现,其中ThreadPoolExecutor是最为灵活的一个实现,它使用了典型的生产者-消费者模式。
```java
ExecutorService executor = Executors.newFixedThreadPool(10); // 创建固定大小的线程池
for (int i = 0; i < 100; i++) {
executor.submit(new Task()); // 提交任务到线程池
}
executor.shutdown(); // 关闭线程池
```
### 4.3.2 并发集合与原子操作类
并发集合专为多线程环境设计,它们能够安全地在多个线程之间共享数据。常见的并发集合包括ConcurrentHashMap、CopyOnWriteArrayList等。
原子操作类则提供了一种原子性操作的方式,如AtomicInteger、AtomicLong等,能够解决在并发环境下进行计数器、累加器等操作的安全问题。
```java
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
// 使用原子操作更新值
map.merge("key", 1, Integer::sum);
// 使用原子操作递增
AtomicInteger atomicInteger = new AtomicInteger(0);
atomicInteger.incrementAndGet();
```
在上述代码中,ConcurrentHashMap使用merge方法实现了线程安全的值更新操作。AtomicInteger使用incrementAndGet方法实现了线程安全的自增操作。
通过这些高级并发API的应用,开发者可以更简单、高效地开发出安全且性能优越的多线程应用程序。
# 5. Java内存模型与性能调优
## 5.1 垃圾回收机制
在Java中,垃圾回收(Garbage Collection, GC)是一个自动化管理内存的机制。它负责识别和清除不再被引用的对象,从而为新对象腾出空间。了解Java的垃圾回收机制对于提升应用性能至关重要,尤其是在处理大型应用或系统时。
### 5.1.1 垃圾回收算法与选择
Java虚拟机(JVM)提供了多种垃圾回收算法,常见的包括标记-清除、复制、标记-整理和分代收集算法。不同垃圾回收器如Serial GC、Parallel GC、CMS和G1 GC,它们各自有不同的特点和适用场景。选择合适的垃圾回收算法和垃圾回收器,可以优化内存使用和提升性能。
以G1 GC为例,它是Java 9中推荐的垃圾回收器。G1 GC设计用于替代CMS,它将堆内存划分为多个区域,允许它在不牺牲单次垃圾回收时间的前提下,同时进行内存区域的整理和压缩。G1 GC的工作流程通常包括以下步骤:
- 初始标记
- 并发标记
- 最终标记
- 筛选回收
### 5.1.2 调优策略与工具
垃圾回收调优是一个试错过程。调优时需要关注的几个关键指标包括:延迟、吞吐量和内存占用。为了达到这些目标,可以调整JVM启动参数,如堆内存大小(-Xms和-Xmx),新生代与老年代的比例(-XX:NewRatio),以及各种垃圾回收器特有的参数。
Java提供了多个工具来监控和分析垃圾回收过程:
- `jstat`: 跟踪垃圾回收堆的统计信息。
- `jmap`: 生成堆转储文件,用于分析堆内对象的分配情况。
- `jhat`: 分析堆转储文件。
- `VisualVM`: 一个图形化界面工具,提供实时性能监控和故障排查功能。
### 示例代码块 - 使用jstat监控GC活动
```bash
jstat -gc <pid> <interval> <count>
```
在上面的命令中,`<pid>` 是Java进程ID,`<interval>` 是打印间隔时间(毫秒),`<count>` 是打印次数。
## 5.2 性能监控与分析
对Java应用程序进行性能监控和分析,是确保其稳定运行和及时发现潜在问题的重要环节。JVM提供了一系列性能监控工具来帮助开发者实时监控运行时性能和资源使用情况。
### 5.2.1 JVM性能监控工具
JVM提供了一些内置的监控和管理工具,例如:
- `jvisualvm`: 提供了丰富的图形界面,可以实时监控JVM的内存使用情况、线程状态、CPU使用率等。
- `jstack`: 打印出指定Java进程的线程堆栈信息,对于诊断死锁和线程问题很有帮助。
- `jconsole`: 提供基本的监控视图,包括JVM内存使用、类加载情况和线程信息。
### 5.2.2 性能问题定位与解决
性能问题的定位通常遵循以下步骤:
1. 使用监控工具识别系统瓶颈,如内存泄漏、CPU使用率过高或I/O延迟。
2. 进行线程分析以发现死锁或线程饥饿。
3. 对日志文件进行深入分析,确定异常模式或性能降级的时间点。
4. 分析堆转储文件,识别内存泄漏或内存占用高的对象。
5. 根据分析结果采取行动,如优化代码、增加资源或调整JVM参数。
## 5.3 性能优化最佳实践
性能优化是一项复杂且持续的工作,它要求开发者对应用程序的业务逻辑、代码结构和运行环境有深入的理解。
### 5.3.1 代码优化技巧
- 避免创建不必要的对象,尤其是在循环和高频调用的代码中。
- 使用高效的数据结构和算法,减少计算和存储开销。
- 利用对象池技术复用对象,减少频繁的内存分配和回收。
- 使用局部变量代替实例变量,以减少同步的需要。
- 对于循环,将最不可能发生的变化放在循环内部。
### 5.3.2 系统架构优化案例
在系统架构层面,可以通过以下方式进行优化:
- 使用缓存减少对数据库的读取压力。
- 采用负载均衡分散访问请求,提高系统的可用性和扩展性。
- 引入消息队列处理异步任务,提升系统响应速度。
- 对第三方服务的调用进行限流和降级,以减少系统间依赖的风险。
- 采用微服务架构,按业务模块拆分应用,提升系统的可维护性和扩展性。
以上是Java内存模型与性能调优的核心内容。在实际操作中,开发者需要根据具体的应用场景和需求,不断实践和调整上述提到的各个策略。性能优化是一个动态的过程,开发者应当持续监控应用的运行状态,实时应对出现的各种性能挑战。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入剖析数字通信:MFSK vs MPSK技术全解析及实战应用(2023年最新版)

# 摘要
本文深入探讨了数字通信领域中的MFSK和MPSK技术,首先介绍了数字通信基础与调制技术概述,随后分别分析了MFSK和MPSK技术的理论基础、关键技术以及在现代通信中的应用实例。在比较与选择章节,本文对MFSK与MPSK的性能和应用场景进行了对比,并展望了未来技术的发展趋势。最后,通过实战项目和案例分析,展示了MFSK与MPSK技术的实际应用,并提出了项目优化建议。文章旨在为通信工程师提供一个全面的技术参考,促进通信技
【办公软件效能升级】:Word与Excel中GIF动态图10大实用技巧和最佳实践
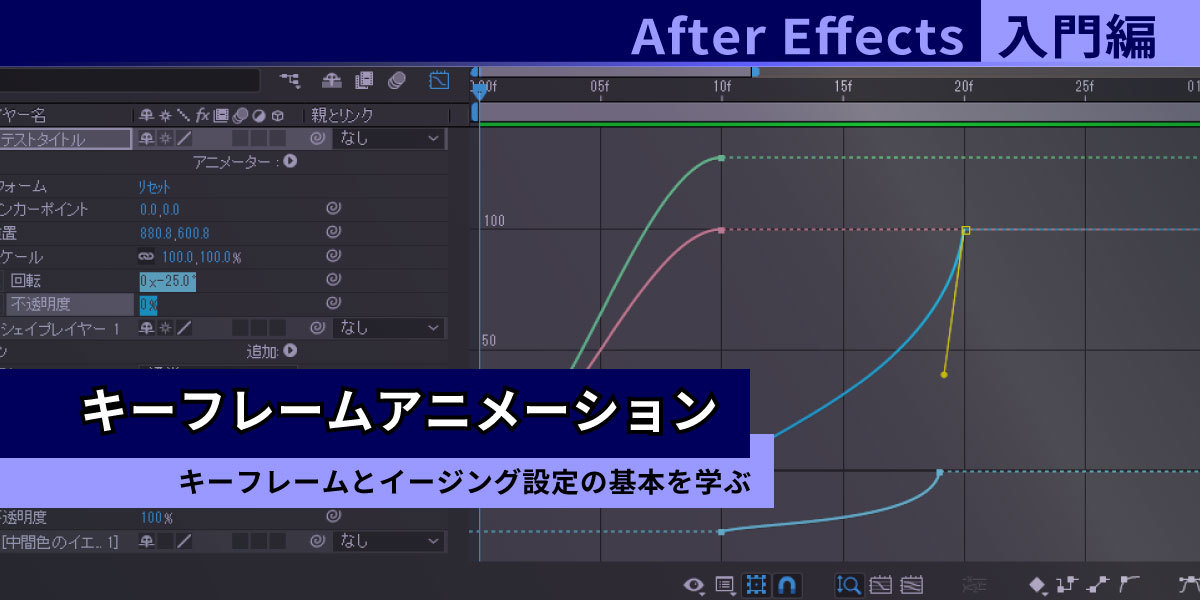
# 摘要
本文详细探讨了GIF动态图在现代办公软件中的应用及其对提升办公效率和文档表现力的重要性。第一章介绍了GIF动态图在办公软件中的魅力和作用,第二章和第三章分别深入剖析了Word和Excel中嵌入、操作GIF动态图的技巧和高级应用。第四章提出了GIF动态图在办公自动化中的最佳实践,包括简化任务和增强团队协作。最后,第五章展望了办公软件中GIF技术的未来趋势,特别是其技术发展和效能最大化。通过本文,读者将获得全面的指导,以便在日常工作中有效
PSCAD进阶秘籍:深入挖掘高级功能提升仿真效率

# 摘要
本文详细介绍了PSCAD软件的功能、操作以及高级应用,为电力系统仿真提供了全面的指导和实践案例。文章首先概述了PSCAD的基本操作,并深入探讨了其高级功能,包括模块化建模、多工况仿真、用户自定义组件和脚本编写。随后,本文提出了提升PSCAD仿真效率的策略,涉及模型优化、并行计算应用及自动化测试。在案例分析章节,文章通过复杂电力系统、变频驱动系统和分布式电源系统的仿真案例,深入解析了PSCAD的仿真能力
实时交通信息解读:三大地图服务的高效交通数据处理技术

# 摘要
实时交通信息对于优化城市交通、提高道路使用效率和改善驾驶体验至关重要。随着技术进步,地图服务公司通过先进的数据采集、存储、处理架构,能够实时处理海量交通数据,为用户提供准确的交通信息服务。本文探讨了实时交通数据处理的技术架构,包括传感器数据集成、分布式数据库优化、流数据处理框架以及高级数据分析技术。同时,本文分析了实时交通数据分析在流量预测、交通事件自动检测等方面的应用,并讨论了
芯片性能大比拼:紫光展锐6710HDTV与其他竞品深度对比

# 摘要
本论文旨在深入探讨紫光展锐6710HDTV芯片的性能特点,并与竞品芯片进行技术对比分析。通过对紫光展锐6710HDTV的核心架构、能效优化和硬件设计的全面剖析,评估其在游戏性能、多任务处理和视频图像处理等应用场景中的表现。同时,论文还将探讨芯片在集成人工智能与机器学习技术、5G通信技术的挑战,并考虑可持续发展与绿色计算的需求。最后,基于市场竞争力分析和消费者预期
选购指南:如何精准解读台达变频器参数及选型技巧
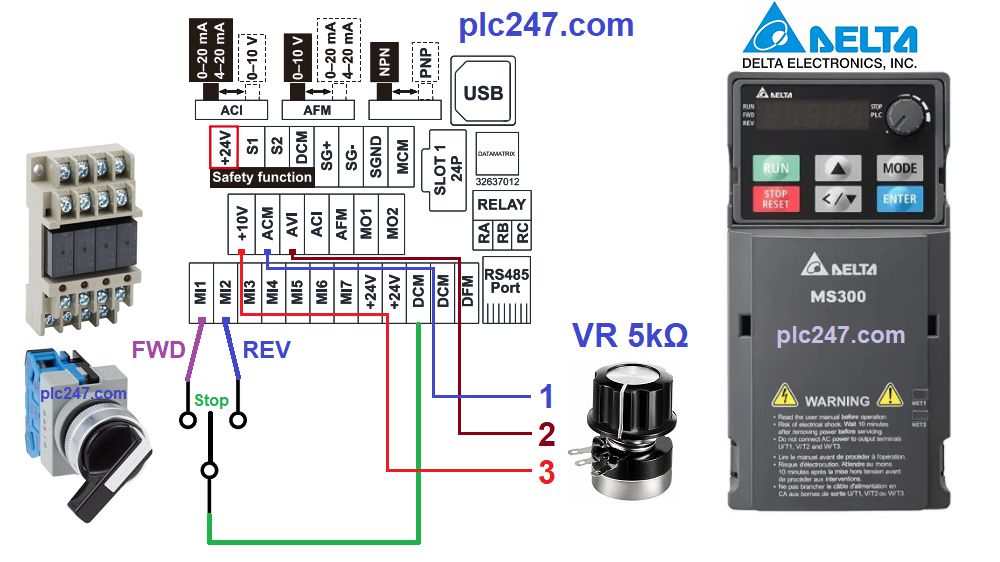
# 摘要
本文全面介绍了台达变频器的基础知识、参数解读、选型技巧以及实践应用。首先,本文对台达变频器进行了基础介绍,并详细解读了其各类参数,包括额定参数、性能参数等,并对参数与应用场景的关系进行了分析。其次,本文提供了台达变频器选型的技巧,分析了不同应用场景对变频器选择的影响,并通过案例展示了实际选型过程。最后,本文探讨了台达变频器的实际安装要点、参数调试与优化技巧,以及在节能和环保方面的高级应用。通
EIP通信秘籍:提升欧姆龙FH视觉与CP1H PLC间的数据交换效率
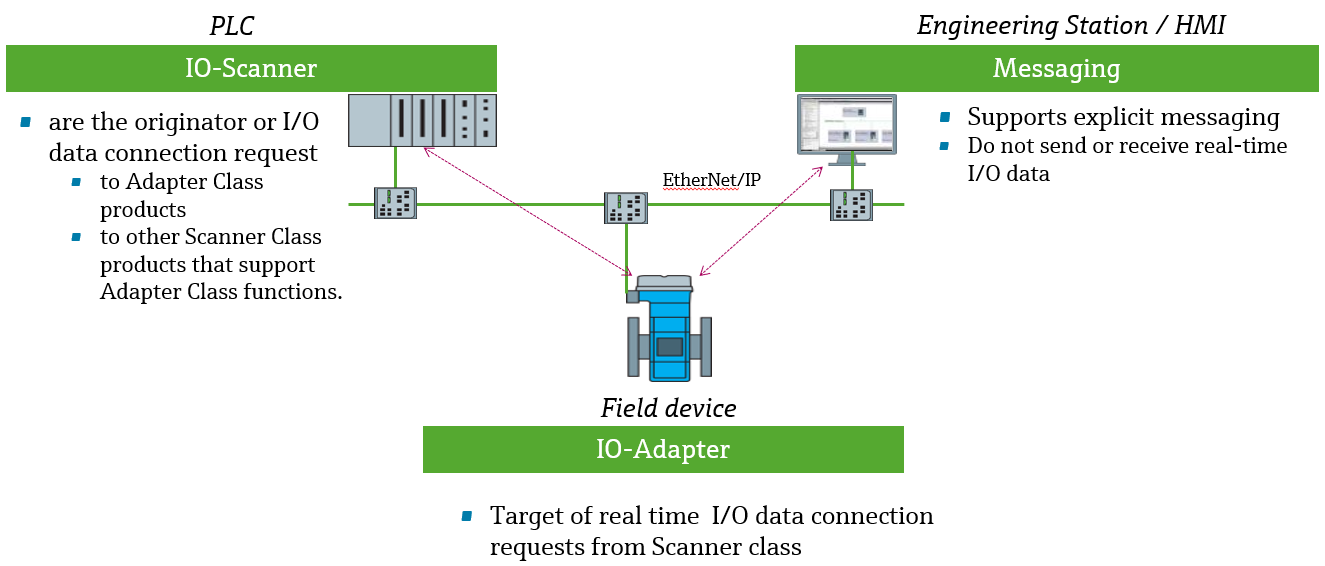
# 摘要
本文全面探讨了企业集成协议(EIP)通信在工业自动化领域中的作用、效率提升策略、故障诊断与维护方法,以及在智能制造中的应用前景。首先介绍了EIP通信的基础知识及其在工业自动化中的重要性。随后,详细解析了EIP协议与OMRON FH视觉系统交互的原理、方法和通信配置。第三章提出了提高EIP通信效率的策略,包括数据交换性能优化理论和编程实践
GraphPad Prism 5数据简化:多变量图形化的智慧之道
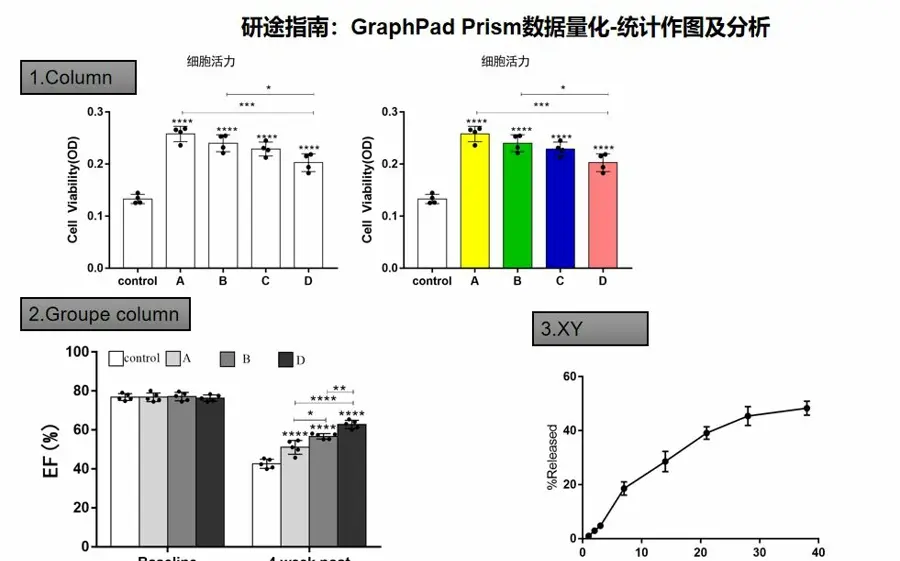
# 摘要
本文介绍了GraphPad Prism 5软件,涵盖了其功能和数据分析、图形化的重要性。我们探讨了数据简化理论基础,包括其目的、作用和多变量数据简化的理论依据,并展示了在数据分析中应用实例。此外,本文详细阐述了Prism 5中的数据操作和数据简化技术,以及如何在图形化中实现多变量数据的有效表达。最后,重点介绍了Prism
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )