Python正则表达式高级分析:模式识别与数据分析实战指南
发布时间: 2024-10-07 06:08:55 阅读量: 25 订阅数: 32 

大学生 Python爬虫入门指南.pptx

# 1. 正则表达式基础概述
正则表达式是一套用于字符串操作的规则和模式,它允许用户通过特定的语法来定义搜索、替换以及验证文本的规则。这使得对数据的提取、分析和处理工作变得简单高效。无论你是进行简单的数据验证还是复杂的文本分析,正则表达式都是不可或缺的工具。
在本章中,我们将带您从零基础开始,了解正则表达式的基本概念、构成及其在数据处理中的重要性。我们将浅入深地介绍正则表达式的起源,以及它在不同编程语言中的实现,如Python、Java、PHP等,然后通过实际案例展示其在处理字符串时的强大功能。
为了更好地掌握正则表达式的使用方法,下一章我们将深入探讨正则表达式的语法及其构成元素,为理解复杂的正则表达式逻辑打下坚实的基础。
# 2. 正则表达式语法详解
正则表达式是一种强大的文本处理工具,用于搜索、匹配和操作字符串。其语法繁杂且功能强大,本章节将深入剖析正则表达式的基础语法,帮助读者理解各种元字符与特殊字符集、模式修饰符、分组和扩展功能,并通过具体实例演示它们的使用方法。
## 2.1 元字符与特殊字符集
### 2.1.1 字符匹配与转义序列
在正则表达式中,元字符具有特殊意义,它们用来构建匹配模式。例如,点号(`.`)表示任意单个字符,星号(`*`)表示前面的字符可以出现零次或多次。要匹配字面上的元字符,需要使用反斜杠(`\`)进行转义。
以点号(`.`)为例,假设我们需要匹配一个字符串中的所有点号,可以使用转义序列`\.`:
```regex
\.
```
下面的Python代码演示了如何使用re模块来搜索文本中所有的点号:
```python
import re
text = "正则表达式.语法详解"
pattern = r"\."
matches = re.findall(pattern, text)
print(matches) # 输出: ['.', '.']
```
### 2.1.2 量词和边界匹配
量词用于指定前面字符的出现次数。例如,`+`表示一次或多次出现,`?`表示零次或一次出现,而花括号`{}`可以用来指定具体出现次数,如`{n}`恰好出现n次,`{n,}`至少出现n次。
边界匹配符则用于指定匹配必须出现在行的开头或结尾,其中`^`表示匹配行的开头,`$`表示匹配行的结尾。
下面的Python代码演示了如何使用量词和边界匹配符:
```python
text = "正则表达式语法详解"
pattern = r"正则*表达式+"
matches = re.findall(pattern, text)
print(matches) # 输出: ['正则表达式']
```
## 2.2 模式修饰符和分组
### 2.2.1 分组、捕获和反向引用
分组是正则表达式中的一个强大特性,允许将表达式的一部分组合在一起,使它们作为一个单元进行匹配。在Python中,可以使用圆括号`()`来创建一个分组。
捕获组会记住其匹配的内容,因此可以使用反向引用在正则表达式的其他部分引用它。例如,`\1`引用第一个分组。
下面的Python代码演示了如何创建分组并使用反向引用:
```python
text = "正则表达式详解"
pattern = r"(正则)(表达式)"
matches = re.search(pattern, text)
if matches:
print(matches.group(0)) # 输出: 正则表达式
print(matches.group(1)) # 输出: 正则
print(matches.group(2)) # 输出: 表达式
print(matches.group(1) + matches.group(2)) # 输出: 正则表达式
```
### 2.2.2 模式修饰符的使用与影响
模式修饰符(也称为标志)可以改变正则表达式的行为。例如,在Python中,`re.I`标志允许忽略大小写,`re.M`标志使`^`和`$`匹配每一行的开头和结尾。
在正则表达式后加上修饰符,像这样`re.search(pattern, text, re.I)`。
下面的Python代码演示了使用修饰符来忽略大小写匹配:
```python
text = "Reguläre Ausdrücke"
pattern = r"Reguläre"
matches = re.search(pattern, text, re.I)
if matches:
print(matches.group(0)) # 输出: Reguläre
```
## 2.3 正则表达式的扩展功能
### 2.3.1 正向与负向前瞻断言
前瞻断言允许你匹配一个位置,该位置满足或不满足一定的条件。正向前瞻断言`(?=...)`表示匹配前面的位置,而负向前瞻断言`(?!...)`表示匹配不前面的位置。
例如,正向前瞻断言可以用来匹配后面跟着数字的字母:
```regex
\b\w+(?=\d)
```
下面的Python代码演示了如何使用正向前瞻断言:
```python
text = "a1 b2 c3"
pattern = r"\b\w+(?=\d)"
matches = re.findall(pattern, text)
print(matches) # 输出: ['a1', 'b2', 'c3']
```
### 2.3.2 回溯引用及其实用案例
回溯引用允许你在同一正则表达式中稍后引用之前捕获的组。这在需要匹配重复模式时非常有用。
例如,要在字符串中匹配重复的单词可以使用如下模式:
```regex
\b(\w+)\b.*\b\1\b
```
下面的Python代码演示了如何使用回溯引用:
```python
text = "Is is the cost of of gasoline going up up"
pattern = r"\b(\w+)\b.*\b\1\b"
matches = re.search(pattern, text)
if matches:
print(matches.group(0)) # 输出: is is
```
以上就是对正则表达式语法的深入解析,掌握了这些基础语法,你将能够有效地构建和使用正则表达式进行文本搜索和处理。在下一章节中,我们将探讨如何将正则表达式应用于Python编程,以及如何处理实际的数据清洗任务。
# 3. Python中的正则表达式应用
在这一章节中,我们将深入探讨正则表达式在Python编程语言中的具体应用。Python凭借其简洁的语法和强大的内置库,已成为数据处理和自动化任务的首选语言。通过应用Python中的`re`模块,我们可以进行复杂的文本匹配、替换以及数据提取等任务。
## 3.1 Python标准库中的re模块
Python的`re`模块提供了一系列功能,让我们能够在字符串中执行搜索、匹配和替换操作。这些功能基于正则表达式这一强大工具,可以识别和操作复杂的文本模式。
### 3.1.1 re模块的主要功能和用法
`re`模块中包含许多用于处理正则表达式的函数,如`re.match()`、`re.search()`、`re.findall()`和`re.sub()`等。每个函数都有其特定的用法,下面以`re.search()`为例进行说明。
**代码示例:**
```python
import re
# 搜索字符串中是否含有数字
result = re.search(r'\d+', 'Hello, there is 123456 number here')
if result:
print('Found number:', result.group()) # 输出找到的第一个数字
```
在上面的代码中,`re.search()`函数寻找字符串中的第一个符合条件的匹配项。正则表达式`r'\d+'`表示匹配一个或多个数字。如果找到匹配项,`result`将包含匹配对象,`result.group()`将返回匹配到的字符串。
### 3.1.2 字符串的匹配、搜索和替换
匹配、搜索和替换是正则表达式最常用的操作。`re`模块提供了`re.match()`, `re.search()`, 和 `re.sub()` 函数来执行这些操作。
**示例:**
```python
# 匹配字符串开头的模式
match = re.match(r'Hello', 'Hello, world!')
if match:
print('Match at the beginning:', match.group())
# 替换字符串中的特定模式
text = 'The rain in Spain falls mainly on the plain'
replaced_text = re.sub(r'Spain', 'France', text)
print(replaced_text) # 输出: T
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 Python 的 re 库为主题,深入探讨正则表达式的各种技巧和应用。从新手入门到专家级应用,涵盖了匹配规则、性能提升、数据提取、调试、Unicode 处理、环视断言、量词选择、编译优化、国际化处理、特殊字符处理和高级分析等各个方面。通过丰富的实例和详尽的讲解,帮助读者掌握正则表达式的精髓,提升数据处理和文本分析能力。无论你是初学者还是经验丰富的开发者,都能从本专栏中受益匪浅,成为一名正则表达式高手。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘ETA6884移动电源的超速充电:全面解析3A充电特性

# 摘要
本文详细探讨了ETA6884移动电源的技术规格、充电标准以及3A充电技术的理论与应用。通过对充电技术的深入分析,包括其发展历程、电气原理、协议兼容性、安全性理论以及充电实测等,我们提供了针对ETA6884移动电源性能和效率的评估。此外,文章展望了未来充电技术的发展趋势,探讨了智能充电、无线充电以
【编程语言选择秘籍】:项目需求匹配的6种语言选择技巧

# 摘要
本文全面探讨了编程语言选择的策略与考量因素,围绕项目需求分析、性能优化、易用性考量、跨平台开发能力以及未来技术趋势进行深入分析。通过对不同编程语言特性的比较,本文指出在进行编程语言选择时必须综合考虑项目的特定需求、目标平台、开发效率与维护成本。同时,文章强调了对新兴技术趋势的前瞻性考量,如人工智能、量子计算和区块链等,以及编程语言如何适应这些技术的变化。通
【信号与系统习题全攻略】:第三版详细答案解析,一文精通

# 摘要
本文系统地介绍了信号与系统的理论基础及其分析方法。从连续时间信号的基本分析到频域信号的傅里叶和拉普拉斯变换,再到离散时间信号与系统的特性,文章深入阐述了各种数学工具如卷积、
微波集成电路入门至精通:掌握设计、散热与EMI策略

# 摘要
本文系统性地介绍了微波集成电路的基本概念、设计基础、散热技术、电磁干扰(EMI)管理以及设计进阶主题和测试验证过程。首先,概述了微波集成电路的简介和设计基础,包括传输线理论、谐振器与耦合结构,以及高频电路仿真工具的应用。其次,深入探讨了散热技术,从热导性基础到散热设计实践,并分析了散热对电路性能的影响及热管理的集成策略。接着,文章聚焦于EMI管理,涵盖了EMI基础知识、
Shell_exec使用详解:PHP脚本中Linux命令行的实战魔法

# 摘要
本文详细探讨了PHP中的Shell_exec函数的各个方面,包括其基本使用方法、在文件操作与网络通信中的应用、性能优化以及高级应用案例。通过对Shell_exec函数的语法结构和安全性的讨论,本文阐述了如何正确使用Shell_exec函数进行标准输出和错误输出的捕获。文章进一步分析了Shell_exec在文件操作中的读写、属性获取与修改,以及网络通信中的Web服
NetIQ Chariot 5.4高级配置秘籍:专家教你提升网络测试效率

# 摘要
NetIQ Chariot是网络性能测试领域的重要工具,具有强大的配置选项和高级参数设置能力。本文首先对NetIQ Chariot的基础配置进行了概述,然后深入探讨其高级参数设置,包括参数定制化、脚本编写、性能测试优化等关键环节。文章第三章分析了Net
【信号完整性挑战】:Cadence SigXplorer仿真技术的实践与思考
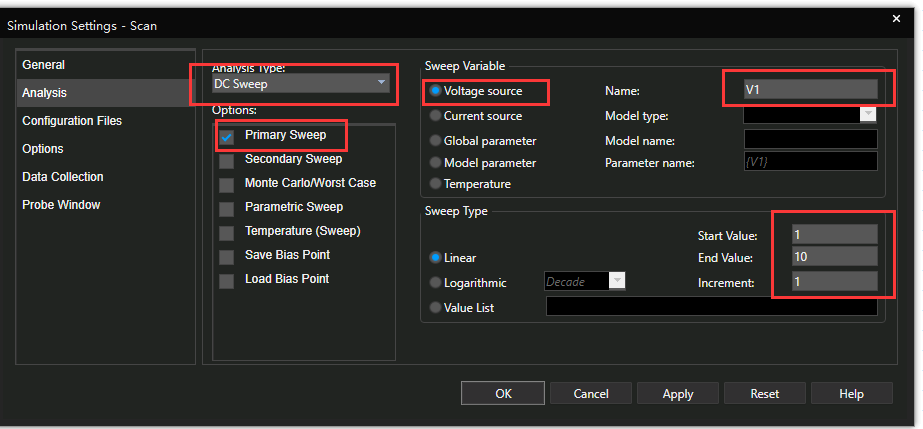
# 摘要
本文全面探讨了信号完整性(SI)的基础知识、挑战以及Cadence SigXplorer仿真技术的应用与实践。首先介绍了信号完整性的重要性及其常见问题类型,随后对Cadence SigXplorer仿真工具的特点及其在SI分析中的角色进行了详细阐述。接着,文章进入实操环节,涵盖了仿真环境搭建、模型导入、仿真参数设置以及故障诊断等关键步骤,并通过案例研究展示了故障诊断流程和解决方案。在高级
【Python面向对象编程深度解读】:深入探讨Python中的类和对象,成为高级程序员!

# 摘要
本文深入探讨了面向对象编程(OOP)的核心概念、高级特性及设计模式在Python中的实现和应用。第一章回顾了面向对象编程的基础知识,第二章详细介绍了Python类和对象的高级特性,包括类的定义、继承、多态、静态方法、类方法以及魔术方法。第三章深入讨论了设计模式的理论与实践,包括创建型、结构型和行为型模式,以及它们在Python中的具体实现。第四
Easylast3D_3.0架构设计全解:从理论到实践的转化
# 摘要
Easylast3D_3.0是一个先进的三维设计软件,其架构概述及其核心组件和理论基础在本文中得到了详细阐述。文中详细介绍了架构组件的解析、设计理念与原则以及性能评估,强调了其模块间高效交互和优化策略的重要性。
【提升器件性能的秘诀】:Sentaurus高级应用实战指南

# 摘要
Sentaurus是一个强大的仿真工具,广泛应用于半导体器件和材料的设计与分析中。本文首先概述了Sentaurus的工具基础和仿真环境配置,随后深入探讨了其仿真流程、结果分析以及高级仿真技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )