Python数据提取升级技巧:从正则表达式到re库进阶应用
发布时间: 2024-10-07 05:34:09 阅读量: 5 订阅数: 9 

# 1. Python数据提取的基本概念和方法
在当今信息高度发展的时代,数据提取成为了每个IT从业者必须掌握的技能之一。Python作为一种高效的编程语言,在数据提取领域发挥着重要作用。本章将对Python数据提取进行基础概念的介绍和方法概述,为后续深入学习打下坚实的基础。
## 1.1 数据提取的重要性
数据提取是获取和处理信息的关键步骤。无论是Web开发、数据分析还是自动化脚本,数据提取都扮演着不可或缺的角色。通过掌握数据提取技能,可以极大地提高工作效率,实现从各种数据源中抽取有用信息的目标。
## 1.2 Python数据提取的方法概述
Python通过内置的库以及第三方库提供了丰富的数据提取方法,如使用`requests`库进行网络请求,使用`BeautifulSoup`解析HTML/XML文档,或是利用`pandas`库处理表格数据。本章将介绍这些基础方法,并展示如何利用这些方法来获取和提取数据。
## 1.3 数据提取的基本流程
数据提取通常遵循以下流程:确定数据源、选择合适的提取方法、编写提取脚本、执行脚本并验证结果、处理和存储提取数据。理解并掌握这一流程对于成功提取数据至关重要。
通过本章的学习,读者将对Python数据提取有一个宏观的认识,并为进一步学习具体的数据提取技术打下基础。
# 2. 正则表达式的使用和优化
## 正则表达式的理论基础
### 正则表达式的定义和组成
正则表达式(Regular Expression),简称Regex,是一种文本模式,包括普通字符(例如,每个字母和数字)和特殊字符(称为"元字符")。它提供了一种灵活而强大的方式来匹配字符串的文本模式,广泛应用于文本搜索、替换、数据提取等领域。正则表达式的组成元素主要包括字符类、量词、锚点、分组和引用等。
### 正则表达式的规则和语法
正则表达式的规则和语法是学习正则表达式的重点,理解了这些规则和语法,我们就可以编写出满足各种文本匹配需求的正则表达式。例如,字符类`[abc]`表示匹配任何一个括号中的字符,量词`*`表示前面的字符可以出现零次或多次,锚点`^`和`$`分别表示匹配字符串的开始和结束位置,分组`(exp)`用来捕获匹配的文本等。
## 正则表达式在Python中的应用
### Python中的正则表达式模块
Python通过内置的`re`模块支持正则表达式。`re`模块提供了多种功能来处理正则表达式,如`re.search()`, `re.match()`, `re.findall()`和`re.sub()`等。要使用这些功能,首先需要导入`re`模块。下面是一个简单的示例:
```python
import re
pattern = r'hello'
text = 'hello world'
match = re.search(pattern, text)
if match:
print("Found the pattern:", match.group())
```
### 正则表达式的常见用法和示例
正则表达式的常见用法包括精确匹配、模式替换、提取信息和数据验证等。例如,要验证一个字符串是否为有效的电子邮件地址,可以编写如下正则表达式:
```python
email_pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'
email = '***'
if re.match(email_pattern, email):
print(f"{email} is a valid email address.")
else:
print(f"{email} is not a valid email address.")
```
## 正则表达式的性能优化
### 正则表达式的性能问题和解决方案
正则表达式虽然功能强大,但在某些情况下可能会导致性能问题。例如,复杂或不恰当的正则表达式可能会导致回溯现象,从而降低匹配效率。性能问题的解决方案包括编写效率更高的正则表达式、使用合适的正则表达式函数(如`re.finditer()`代替`re.findall()`)以及在可能的情况下避免使用正则表达式。
### 正则表达式的高级优化技巧
正则表达式的高级优化技巧可能包括以下几点:
- 避免在正则表达式中使用不必要的捕获组,因为它们会增加额外的性能开销。
- 使用非捕获组`(?:...)`来替代普通捕获组`(...)`,在不需要引用匹配内容的场景下使用非捕获组。
- 在可能的情况下,使用正则表达式的预编译功能。Python中的`***pile()`方法可以将正则表达式编译成一个正则表达式对象,从而提高后续匹配操作的效率。
```python
# 预编译正则表达式
email_patternCompiled = ***pile(r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$')
# 使用预编译的正则表达式对象进行匹配
if email_patternCompiled.match(email):
print(f"{email} is a valid email address.")
else:
print(f"{email} is not a valid email address.")
```
为了深入理解正则表达式的性能优化,下面将展示一个使用`re.finditer()`方法来替代`re.findall()`的示例:
```python
import re
import timeit
# 使用 re.findall()
def findall_example(pattern, string):
return re.findall(pattern, string)
# 使用 re.finditer()
def finditer_example(pattern, string):
return [match.group() for match in re.finditer(pattern, string)]
# 测试字符串和模式
test_string = 'This is a test string for testing the findall and finditer methods of the re module.'
test_pattern = r'\b\w+\b'
# 使用 timeit 测试两种方法的性能
findall_time = timeit.timeit('findall_example(test_pattern, test_string)', globals=globals(), number=1000)
finditer_time = timeit.timeit('finditer_example(test_pattern, test_string)', globals=globals(), number=1000)
print(f"re.findall() took {findall_time:.6f} seconds")
print(f"re.finditer() took
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Python编程实践】:Winreg模块在应用配置管理中的巧妙运用

# 1. Winreg模块的简介与配置管理基础
在现代IT运营中,Windows注册表管理是一个不可或缺的环节。Winreg模块是Python标准库的一部分,旨在提供对Windows注册表的访问和操作。通过它,开发者可以以编程方式读取、修改、创建或删除注册表项和值,这对于系统配置、应用部署和软件维护至关重
【Django缓存安全性探讨】

# 1. Django缓存机制概述
在Web开发中,缓存是提升性能和扩展性的关键技术之一。Django,作为一个功能强大的Python Web框架,提供了丰富的缓存支持,可以帮助开发者减轻数据库的
【定制你的随机函数】:在Python random库基础上进行创新扩展

# 1. Python random库概述与原理
Python的random库是进行随机数生成的基石,它为用户提供了丰富的随机数生成工具。它基于确定性算法,通过种子的初始化来产生一系列看似随机的数列,这种数列
【django.views.generic.list_detail与第三方服务集成】:邮件、消息推送等服务的无缝集成

# 1. Django视图基础与通用类视图介绍
在这一章中,我们将从基础层面了解Django框架的视图系统,并深入探讨其通用类视图的组成和作用。Django作为一款流行的Python Web框架,其内置的通用类视图(generic class-based views)极大地方便了开发者的编程工作,通过继承已有的类视图,可以
【Site模块深度定制】:自定义搜索路径与加载顺序
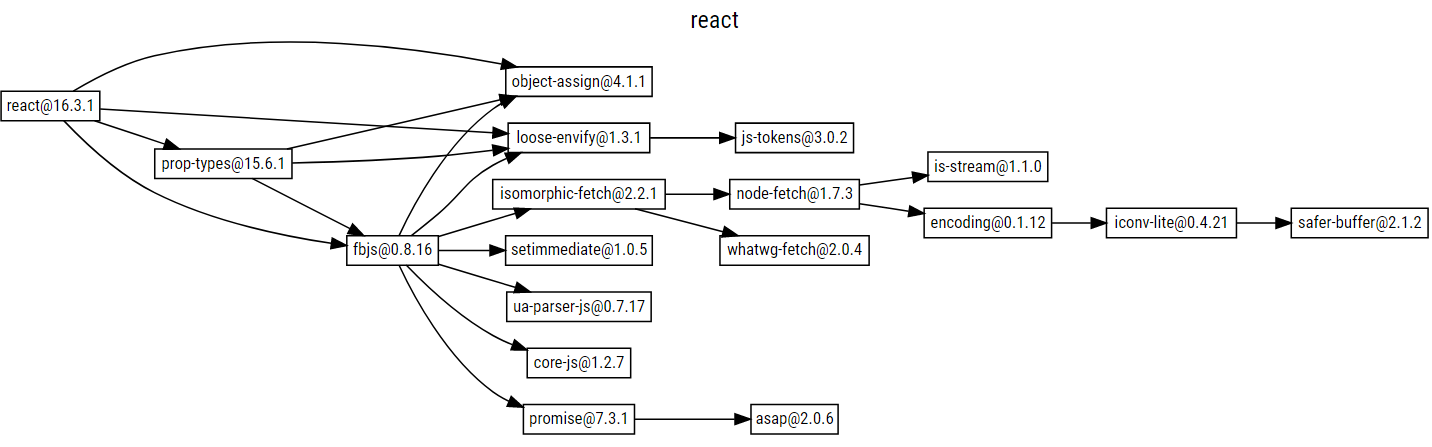
# 1. Site模块深度定制概述
Site模块是IT系统中的核心组件,它控制着数据的存储、管理和检索。本章将提供Site模块深度定制的概览,介绍定制的概念、目的以及它在提升系统性能和用户体验方面的重要作用。
## 1.1 定制的必要性
在高度竞争的IT环境中,Site模块的定制可以帮助企业根据自身需求调整功能,从而获得竞争优势。定制化允许更精细的控制和优化系统,以满足特定的业务
【Python时间模块的创新应用】:开发独特功能的时间相关技巧
# 1. Python时间模块基础
Python作为一门强大的编程语言,不仅提供了丰富的模块库,而且还内置了一些非常实用的功能模块。其中,Python的时间模块是一个经常被应用到各种项目中的功能模块,它提供了多种处理日期和时间的工具。掌握时间模块的基础知识是进行更高级时间处理的先决条件。本章节将带你了解Python时间模块的基本用法,让你在编程时能够轻松处理时间数据。
## 1.1 获取当前时间
要开始使用Python的时间模块,第一步通常是要获取当前时间。Python标准库中的`datetime`模块可以轻松完成这一任务。以下是一段示例代码:
```python
import dat
Python datetime模块时间序列分析:深入理解时间周期性的10个技巧
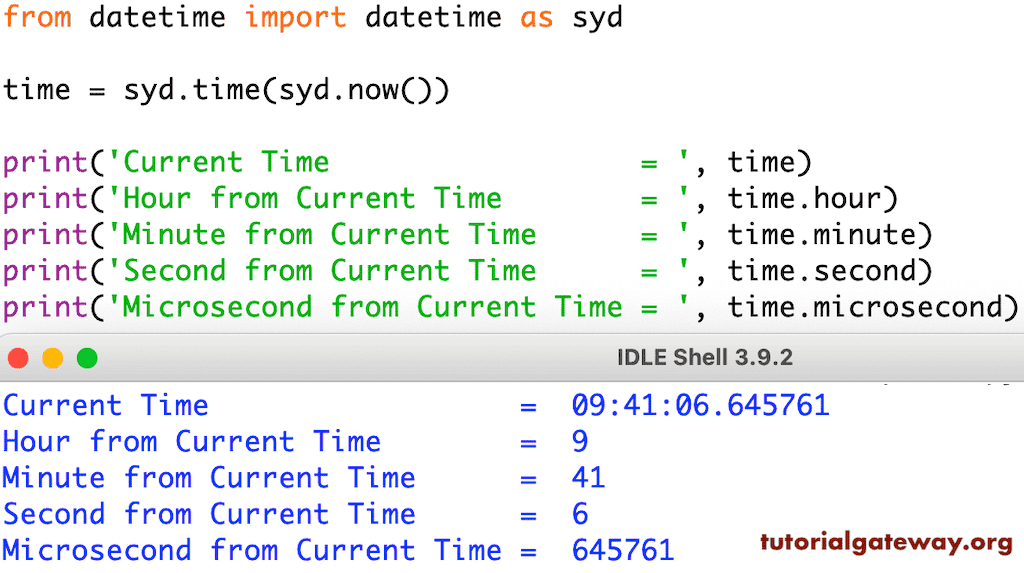
# 1. Python datetime模块概述
## 1.1 datetime模块的作用与重要性
Python的datetime模块是处理日期和时间的标准库之一。它提供了一套丰富的接口,用于获取系统当前时间、创建日期时间对象、执行时间计算以及格式化日期时间数据等。无论是在数据分析、日志记录还是系统监控等众多场景中,datetime模块都扮演着至关重要的角色,使得开发人员能够更加简便地处理时间信息,
Python正则表达式高级分析:模式识别与数据分析实战指南

# 1. 正则表达式基础概述
正则表达式是一套用于字符串操作的规则和模式,它允许用户通过特定的语法来定义搜索、替换以及验证文本的规则。这使得对数据的提取、分析和处理工作变得简单高效。无论你是进行简单的数据验证还是复杂的文本分析,正则表达式都是不可或缺的工具。
在本章中,我们将带您从零基础开始,了解正则表达式的基本概念、构成及其在数据处理中的重要性。我们将浅入深地介绍正则
【os模块与Numpy】:提升数据处理速度,文件读写的优化秘籍

# 1. os模块与Numpy概述
在现代数据科学和软件开发中,对文件系统进行有效管理以及高效地处理和分析数据是至关重要的。Python作为一种广泛使用的编程语言,提供了一系列内置库和工具以实现这些任务。其中,`os`模块和`Numpy`库是两个极其重要的工具,分别用于操作系统级别的文件和目录管理,以及数值计算。
`os`模块提供了丰富的方法和函数,这些方法和函数能够执行各种文件系统操作,比如目录和文件
Twisted Python中的日志记录和监控:实时跟踪应用状态的高效方法

# 1. Twisted Python概述和日志记录基础
## 1.1 Twisted Python简介
Twisted是Python编程语言的一个事件驱动的网络框架。它主要用于编写基于网络的应用程序,支持多种传输层协议。Twisted的优势在
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )