【YOLOv8边缘计算应用指南】:优化部署与推理性能的技巧
发布时间: 2024-12-12 10:38:35 阅读量: 11 订阅数: 12 

YOLOv8模型部署指南:从训练到实战应用
# 1. YOLOv8简介与边缘计算概述
随着机器学习和深度学习的快速发展,实时目标检测已经成为一项不可或缺的技术,广泛应用于视频监控、自动驾驶、安全等领域。YOLOv8,作为该领域的新晋翘楚,继承了YOLO系列简单、快速、准确的特点,并在模型结构和性能上进行了重要的创新和优化。
YOLOv8的引入,不仅为边缘计算环境下的实时目标检测带来了革新,同时,它的小型化和高效能特性使得它成为边缘计算设备上的理想选择。边缘计算通过将数据处理转移至数据产生的近端,大幅提升了数据处理速度,并减少了对中心服务器的依赖。
在本章中,我们将首先对YOLOv8进行简要介绍,理解其架构并掌握核心优势。然后,我们会探讨边缘计算的概念,以及它如何支持并加速实时AI应用。通过了解这些基础知识,读者将为接下来深入学习YOLOv8模型和边缘计算的实际应用打下坚实的基础。
# 2. YOLOv8模型的理解与准备
## 2.1 YOLOv8模型架构解析
### 2.1.1 YOLOv8模型的基本组成
YOLOv8(You Only Look Once version 8)是当前在物体检测领域处于领先地位的算法之一。YOLOv8是该系列算法的最新版本,相比于之前的版本,它在速度、准确性和轻量级模型设计上都有了显著的提升。YOLOv8的核心架构继承了YOLO系列的“one stage”设计思想,即一次性从图像中检测出所有物体,而不像“two stage”模型那样需要先提取区域建议再进行分类。YOLOv8将图像分割成一个个网格,每个网格负责预测中心点落在其内的物体边界框(bounding box)和概率(confidence)。模型输出包含类别概率和边界框的坐标信息。
YOLOv8模型由三个主要部分组成:输入层(负责接收图像数据)、基础网络(负责提取特征)和输出层(负责生成最终检测结果)。输入层通常会先进行预处理操作,如缩放、归一化等。基础网络部分,YOLOv8采用了类似CSPNet的结构,它通过路径聚合网络(Path Aggregation Network, PANet)和深度可分离卷积(Depthwise Separable Convolution)来减少计算量并提高特征提取的效率。输出层使用了锚框(anchor boxes)技术,并结合了二分类逻辑来对每个锚框进行优化,以决定是否包含目标以及目标的种类。
### 2.1.2 模型创新点与优化路径
YOLOv8相较于之前的版本,引入了新的创新点以提升模型性能。一个重要的创新是引入了自注意力机制(self-attention),这有助于模型在进行目标检测时更关注图像的关键区域,忽略不重要的背景信息。自注意力机制在图像的不同区域之间建起了联系,让模型在推理时可以利用上下文信息,从而更准确地进行物体识别。
另一个优化点是对卷积神经网络(CNN)结构的改进。YOLOv8通过引入多尺度特征融合技术,使得模型可以在不同尺度上检测物体,无论是大型对象还是小型对象都能获得较高的检测精度。此外,YOLOv8通过引入后处理步骤中的一些新技术,比如非极大值抑制(Non-Maximum Suppression, NMS)的改进版本,来进一步提升检测结果的质量。
### 2.2 模型的准备与转换
#### 2.2.1 导出YOLOv8模型
导出YOLOv8模型是将训练好的模型转化为适用于部署的格式。通常情况下,这需要在训练完成后使用特定的框架导出工具。使用PyTorch框架时,可以利用torch.save()函数保存模型参数,并使用torch.jit.trace()函数进行模型跟踪,以导出一个适合推理的模型。对于YOLOv8而言,通常会使用如Darknet框架训练得到的权重文件,并将其转换为ONNX格式或者其他推理引擎支持的格式。
```python
import torch
import torchvision.transforms as transforms
# 假设模型名为yolov8_model,已经完成了训练
model = yolov8_model.eval()
dummy_input = torch.randn(1, 3, 640, 640) # 使用一个典型的输入尺寸进行追踪
# 导出模型到onnx格式
torch.onnx.export(model, dummy_input, "yolov8.onnx", opset_version=11)
```
上述代码展示了如何使用PyTorch来导出一个模型为ONNX格式。在实际操作中,还需确保输入数据的预处理与模型训练时的预处理保持一致。
#### 2.2.2 模型转换工具与方法
模型的转换是让模型能够适配于不同的推理引擎或硬件平台。为了在边缘设备上部署YOLOv8,可能需要使用转换工具,例如TensorRT、TVM或OpenVINO,以实现模型的优化和加速。转换过程通常包含以下几个步骤:
1. 使用原框架导出模型的标准化格式。
2. 利用转换工具进行模型优化,包括图优化、层融合和量化等。
3. 将优化后的模型转换为特定硬件平台能够执行的格式。
以NVIDIA的TensorRT为例,可以通过以下步骤将ONNX格式的模型转换为TensorRT引擎:
```python
import tensorrt as trt
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
trt_runtime = trt.Runtime(TRT_LOGGER)
# 加载ONNX模型
with open("yolov8.onnx", "rb") as model:
onnx_data = model.read()
# 创建TensorRT引擎
engine = trt_runtime.deserialize_cuda_engine(onnx_data)
```
#### 2.2.3 模型量化与压缩
模型量化是一种通过减少模型参数的精度来减小模型体积的方法,这通常会牺牲一些精度来换取推理速度的提升,特别是在资源有限的边缘设备上。量化可以是8位整数(INT8)、16位浮点数(FP16)等形式。
以PyTorch为例,可以使用torch.quantization模块对模型进行量化:
```python
import torch.quantization
# 假设模型名称为model,准备进行量化
model.qconfig = torch.quantization.QConfig(
activation=torch.quantization.defa
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 YOLOv8 迁移学习方法专栏!在这里,您将深入了解如何利用 YOLOv8 预训练模型提升您的目标检测项目。专栏涵盖了广泛的主题,包括:
* 预训练模型部署指南,以优化速度和性能
* YOLOv8 与 TensorFlow 的无缝集成
* 复杂场景目标检测的案例分析
* 准确率和速度双提升的性能提升策略
* 个性化模型构建指南,包括定制化层的添加和训练
* 边缘计算应用指南,以优化部署和推理性能
* 多任务学习指南,以扩展模型功能和应用范围
* 模型量化实战,以减少资源消耗和提高效率
* 与传统机器学习的对比分析,以了解 YOLOv8 的优势
* 模型决策透明化,以揭示模型背后的决策逻辑
通过本专栏,您将掌握 YOLOv8 迁移学习的各个方面,并能够构建和部署高效、准确的目标检测模型。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
音频分析无界限:Sonic Visualiser与其他软件的对比及选择指南
参考资源链接:[Sonic Visualiser新手指南:详尽功能解析与实用技巧](https://wenku.csdn.net/doc/r1addgbr7h?spm=1055.2635.3001.10343)
# 1. 音频分析软件概述与Sonic Visualiser简介
## 1.1 音频分析软件的作用
音频分析软件在数字音频处理领域扮演着至关重要的角色。它们不仅为
多GPU协同新纪元:NVIDIA Ampere架构的最佳实践与案例研究
参考资源链接:[NVIDIA Ampere架构白皮书:A100 Tensor Core GPU详解与优势](https://wenku.csdn.net/doc/1viyeruo73?spm=1055.2635.3001.10343)
# 1. NVIDIA Ampere架构概览
在本章中,我们将深入探究NVIDIA Ampere架构的核心特
【HFSS栅球建模终极指南】:一步到位掌握建模到仿真优化的全流程
参考资源链接:[2015年ANSYS HFSS BGA封装建模教程:3D仿真与分析](https://wenku.csdn.net/doc/840stuyum7?spm=1055.2635.3001.10343)
# 1. HFSS栅球建模入门
## 1.1 栅球建模的必要性与应用
在现代电子设计中,准确模拟电磁场的行为至关重要,特别是在高频应用领域。栅
【MediaKit的跨平台摄像头调用】:实现一次编码,全平台运行的秘诀

参考资源链接:[WPF使用MediaKit调用摄像头](https://wenku.csdn.net/doc/647d456b543f84448829bbfc?spm=1055.2635.3001.10343)
# 1. MediaKit跨
【机器学习优化高频CTA策略入门】:掌握数据预处理、回测与风险管理
参考资源链接:[基于机器学习的高频CTA策略研究:模型构建与策略回测](https://wenku.csdn.net/doc/4ej0nwiyra?spm=1055.2635.3001.10343)
# 1. 机器学习与高频CTA策略概述
## 机器学习与高频交易的交叉
在金融领域,尤其是高频交易(CTA)策略中,机器学习技术已成为一种创新力量,它使交易者能够从历史数据中发现复杂的模
ST-Link V2 原理图解读:从入门到精通的6大技巧
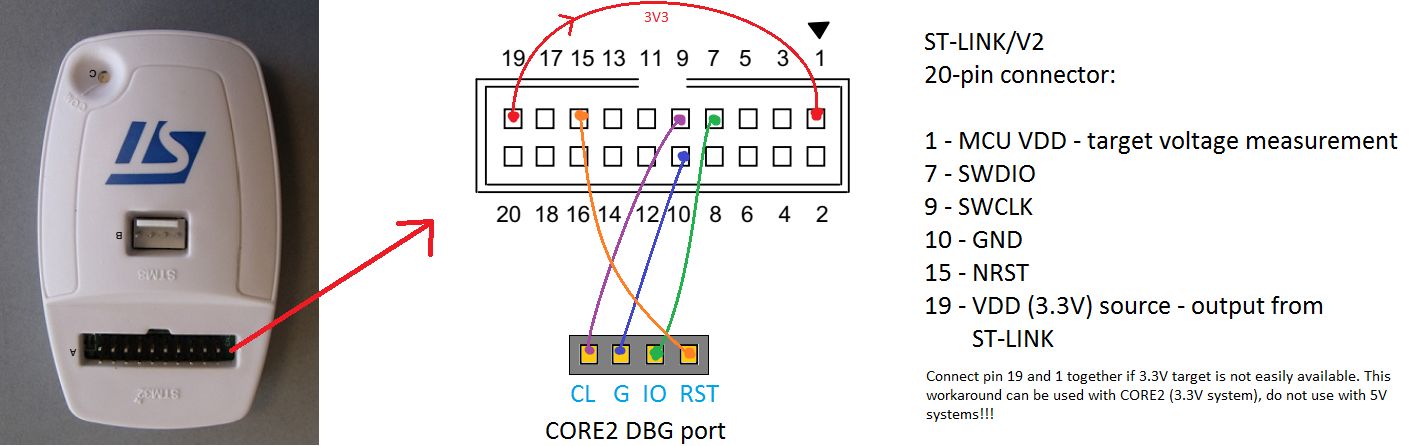
参考资源链接:[STLink V2原理图详解:构建STM32调试下载器](https://wenku.csdn.net/doc/646c5fd5d12cbe7ec3e52906?spm=1055.2635.3001.10343)
# 1. ST-Link V2简介与基础应用
ST-Link V2是一种广泛使用的调试器/编
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )