Spark简介及其在大数据处理中的作用
发布时间: 2023-12-11 15:58:00 阅读量: 87 订阅数: 25 
# 1. 简介
## 1.1 什么是Spark
Spark是一种快速、通用、可扩展的大数据处理和计算引擎。它提供了丰富的高级API,包括用于批处理、实时流处理、机器学习和图计算等的库。Spark的设计目标是为了提供一种更简单、更高效的大数据处理解决方案。
## 1.2 Spark的历史发展
Spark最初由加州大学伯克利分校的AMPLab实验室开发,并于2010年开源。它在开源社区中迅速获得了广泛的关注和应用,并于2014年成为Apache软件基金会的顶级项目。经过多年的发展,Spark已成为大数据处理领域最受欢迎和广泛使用的框架之一。
## 1.3 Spark与传统大数据处理框架的区别
相比于传统的大数据处理框架,如Hadoop MapReduce,Spark具有许多显著的优势。首先,Spark引入了弹性分布式数据集(RDD)这一抽象概念,使得数据可以在内存中进行高效的处理,相比磁盘I/O的MapReduce更快。其次,Spark的计算模型支持多种操作,如Map、Reduce、Filter、Join等,更加灵活和易用。此外,Spark还提供了丰富的API和库,方便开发者进行批处理、实时流处理、机器学习和图计算等任务。所有这些特点使得Spark在大数据处理中表现出色,得到了广泛应用。
**代码示例:**
```python
# 导入Spark相关库
from pyspark import SparkContext, SparkConf
# 创建Spark配置对象
conf = SparkConf().setAppName("HelloSpark").setMaster("local")
# 创建Spark上下文对象
sc = SparkContext(conf=conf)
# 创建RDD并执行操作
rdd = sc.parallelize([1, 2, 3, 4, 5])
result = rdd.map(lambda x: x * 2).collect()
# 输出结果
for num in result:
print(num)
```
**代码说明:**
以上代码展示了使用Spark进行简单的数据处理的示例。首先,通过创建SparkConf对象来配置Spark应用的参数,如应用名称和运行模式。然后,创建SparkContext对象来连接Spark集群。接下来,通过parallelize方法创建一个RDD,并使用map操作对每个元素进行乘以2的操作。最后,通过collect方法将结果收集到本地并输出。在这个示例中,Spark提供了简洁且易于理解的API来完成数据处理任务。
**代码总结:**
这段代码展示了Spark的基本使用方式,包括了Spark的配置、上下文创建、RDD的创建和操作等。通过这个简单的例子,我们可以看到Spark的代码风格简洁,易于理解和使用。
**结果说明:**
## 2. Spark的核心概念
Spark是一个基于内存计算的开源分布式计算框架,它具有以下核心概念和特点。
### 2.1 弹性分布式数据集(RDD)
弹性分布式数据集(Resilient Distributed Datasets,简称RDD)是Spark中最重要的核心概念之一。RDD是一种抽象的数据结构,代表着包含分区(partition)的、容错(fault-tolerant)的、可并行操作的数据集合。RDD具有以下特点:
- 容错性:RDD可以通过记录操作的日志来重构丢失的分区,从而保证数据的容错性。
- 不可变性:RDD的数据是不可变的,任何对数据的转换操作都会生成一个新的RDD。
- 计算延迟性:RDD是惰性计算的,只有当需要对RDD进行计算时才会进行实际的计算。
- 分区并行性:RDD可以划分成多个分区,这些分区可以在集群中的不同节点上并行计算。
Spark提供了丰富的操作API,如map、reduce、filter、join等,可以通过这些操作对RDD进行转换和动作。
以下是一个使用Spark创建RDD并进行转换和动作操作的示例代码:
```python
from pyspark import SparkContext
# 创建SparkContext对象
sc = SparkContext("local", "example")
# 创建RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 对RDD进行转换操作
rdd2 = rdd.map(lambda x: x * 2)
# 对RDD进行动作操作
result = rdd2.reduce(lambda x, y: x + y)
# 输出结果
print(result) # 输出:30
# 关闭SparkContext对象
sc.stop()
```
在上面的示例中,我们使用SparkContext对象创建了一个RDD,并对其进行了转换操作(每个元素乘以2),然后再进行了动作操作(所有元素求和),最后输出结果为30。
### 2.2 Spark的计算模型
Spark的计算模型是基于RDD的有向无环图(Directed Acyclic Graph,简称DAG)。当对RDD应用转换操作时,Spark会将转换操作转化为一个DAG,然后根据需要进行优化和执行。Spark的计算模型具有以下特点:
- 数据流模型:每个转换操作都会生成一个新的RDD,形成一个有向无环图。
- 延迟计算:Spark采用延迟计算的策略,只有当遇到需要输出结果的动作操作时才会触发计算。
- 任务划分:Spark将DAG划分成一系列的任务(task),并在集群中的多个节点上并行执行。
- 依赖关系:每个RDD都会记录其父RDD和子RDD,以便计算过程中进行依赖关系的控制和数据的恢复。
Spark的计算模型使得Spark能够灵活地优化和执行任务,并且可以适应各种大数据处理场景。
### 2.3 Spark的内存管理机制
Spark通过内存管理机制来提高计算性能。相比于传统的磁盘读写方式,Spark将数据存储在内存中,大大减少了读写时间,提高了计算的速度。Spark的内存管理机制主要包括以下几个方面:
- 堆内存管理:Spark将内存划分为堆内存和堆外内存。堆内存用于存储RDD的数据和运行中间结果,而堆外内存用于存储RDD的元数据和序列化数据。
- 数据序列化:Spark使用高效的数据序列化技术,将数据在内存中进行压缩和存储,减少内存的占用和数据的传输时间。
- 内存管理策略:Spark提供了多种内存管理策略,如分页式存储、数据磁盘溢出和内存预留等,可以根据应用的需求进行配置。
### 3. Spark的组件及其作用
在本章中,我们将介绍Spark的主要组件以及它们在大数据处理中的作用。
#### 3.1 Spark Core
Spark Core是Spark的基础模块,提供了分布式计算的功能。它包括了RDD(弹性分布式数据集)的定义和操作,以及任务调度和资源管理等核心功能。Spark Core提供了对于数据集的抽象层,并通过分布式计算模型实现了高效的数据处理和计算能力。
#### 3.2 Spark SQL
Spark SQL是一个用于结构化数据处理的模块,它提供了对结构化数据的高级查询功能。Spark SQL支持使用SQL语言查询数据,可以将数据从不同的数据源(如Hive、Parquet、Avro等)加载到Spark中,并提供了DataFrame和DataSet这两种更高层次的数据抽象。
#### 3.3 Spark Streaming
Spark Streaming是Spark的流式处理模块,它提供了实时数据处理的能力。Spark Streaming使用类似批处理的方式进行流式计算,将实时数据流切分成一系列的小批量数据,然后根据定义的计算逻辑进行处理。Spark Streaming支持与各种数据源的连接,并可以与Spark Core、Spark SQL以及其他Spark组件无缝集成。
#### 3.4 Spark MLlib
Spark MLlib是Spark的机器学习库,提供了丰富的机器学习算法和工具。MLlib支持常见的机器学习和统计学习任务,如分类、回归、聚类、推荐等。MLlib提供了易于使用的API,并可以与Spark的其他组件无缝集成,从而实现大规模的机器学习和数据挖掘任务。
#### 3.5 Spark GraphX
Spark GraphX是Spark的图计算库,用于处理图结构数据。GraphX提供了一系列用于图计算的算法和操作,包括图的构建、遍历、聚合等功能。GraphX可以与Spark的其他组件集成,实现复杂的图计算和分析任务。
## 4. Spark在大数据处理中的作用
Spark是一个强大的大数据处理框架,其在大数据处理中具有多个重要作用。
### 4.1 加速数据处理和计算
Spark通过将数据存储在内存中,并利用其弹性分布式数据集(RDD)提供的高效计算模型,可以大大加速数据处理和计算的过程。相比于传统的硬盘存储和MapReduce计算模型,Spark能够将计算结果保存在内存中,从而避免了磁盘I/O的开销,大大提高了处理速度。
```python
# 示例代码1:使用Spark进行数据处理
from pyspark import SparkContext
# 创建SparkContext对象
sc = SparkContext("local", "Data Processing")
# 读取数据文件
data = sc.textFile("data.txt")
# 对数据进行处理
result = data.flatMap(lambda line: line.split(" ")).map(lambda word: (word, 1)).reduceByKey(lambda a, b: a + b)
# 输出结果
result.collect()
```
代码解释:
1. 首先,创建一个SparkContext对象,即Spark的入口点。
2. 然后,使用`textFile`方法读取文本文件中的数据。
3. 接下来,通过`flatMap`将每一行的单词拆分成单个词语,并使用`map`将每个单词映射成`(word, 1)`的键值对。
4. 最后,使用`reduceByKey`对相同的键进行聚合操作,得到每个单词的出现次数。
5. 最终,使用`collect`方法将结果以列表形式返回并输出。
该示例代码展示了如何使用Spark进行数据处理,利用其高效的计算模型和内存存储能力,大大提高了数据处理的速度。
### 4.2 处理大规模数据集
Spark的分布式计算能力使得它能够处理大规模的数据集。Spark将数据集划分为多个分区,并在集群中的多个节点上并行计算,从而充分利用集群资源。而且,Spark还提供了丰富的操作和转换API,使得处理大规模数据集变得更加容易和高效。
```java
// 示例代码2:使用Spark处理大规模数据集
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
public class LargeDataProcessing {
public static void main(String[] args) {
// 创建SparkConf对象
SparkConf conf = new SparkConf().setAppName("Large Data Processing").setMaster("local");
// 创建JavaSparkContext对象
JavaSparkContext sc = new JavaSparkContext(conf);
// 读取大规模数据集
JavaRDD<String> data = sc.textFile("data.txt");
// 对数据进行处理
JavaRDD<String> result = data.filter(line -> line.contains("Spark"));
// 输出结果
result.collect().forEach(System.out::println);
}
}
```
代码解释:
1. 首先,创建一个SparkConf对象,并设置应用程序名称和运行模式为本地模式。
2. 然后,创建一个JavaSparkContext对象,作为Spark的入口点。
3. 接下来,使用`textFile`方法读取大规模数据集。
4. 然后,使用`filter`方法过滤包含关键词"Spark"的数据。
5. 最后,使用`collect`方法将结果以列表形式返回,并使用`forEach`方法遍历输出每一行数据。
该示例代码展示了如何使用Spark处理大规模数据集,利用其分布式计算和丰富的操作API,可以方便地对大规模数据集进行处理和筛选。
### 4.3 实时数据分析
Spark提供了Spark Streaming组件,可以用于实时数据分析和处理。Spark Streaming可以将实时数据流划分为小批次,然后以微批次的方式进行处理,从而实现接近实时的数据处理和分析。Spark Streaming还可以与其他Spark组件和外部数据源进行集成,支持各种不同类型的实时数据源。
```scala
// 示例代码3:使用Spark Streaming进行实时数据分析
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.SparkConf
object RealTimeAnalytics {
def main(args: Array[String]) {
// 创建SparkConf对象
val conf = new SparkConf().setAppName("Real-time Analytics").setMaster("local[2]")
// 创建StreamingContext对象,每2秒处理一次数据
val ssc = new StreamingContext(conf, Seconds(2))
// 从TCP Socket中读取实时数据流
val lines = ssc.socketTextStream("localhost", 9999)
// 对实时数据进行处理
val result = lines.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
// 输出结果
result.print()
// 开始实时数据处理
ssc.start()
ssc.awaitTermination()
}
}
```
代码解释:
1. 首先,创建一个SparkConf对象,并设置应用程序名称和运行模式为本地模式。
2. 然后,创建一个StreamingContext对象,设置每2秒处理一次数据。
3. 接下来,使用`socketTextStream`方法从TCP Socket中读取实时数据流。
4. 然后,使用`flatMap`将每一行的单词拆分成单个词语,并使用`map`将每个单词映射成`(word, 1)`的键值对。
5. 最后,使用`reduceByKey`对相同的键进行聚合操作,并使用`print`方法输出结果。
6. 开始实时数据处理并等待处理完成。
该示例代码展示了如何使用Spark Streaming进行实时数据分析,Spark Streaming能够以微批次的方式处理实时数据流,并提供了丰富的操作和转换方法,便于对实时数据进行处理和分析。
### 4.4 机器学习和图计算
Spark提供了Spark MLlib和Spark GraphX组件,用于机器学习和图计算。Spark MLlib是一个强大的机器学习库,提供了丰富的机器学习算法和工具,方便进行大规模数据集的机器学习任务。Spark GraphX是一个图计算库,支持图的构建、转换和计算,可以用于社交网络分析、推荐系统等领域。
```python
# 示例代码4:使用Spark MLlib进行机器学习任务
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml import Pipeline
# 加载数据
data = spark.read.format("libsvm").load("data.txt")
# 特征向量化
assembler = VectorAssembler(inputCols=data.columns[1:5], outputCol="features")
assembled_data = assembler.transform(data)
# 划分训练集和测试集
training_data, test_data = assembled_data.randomSplit([0.7, 0.3])
# 训练逻辑回归模型
lr = LogisticRegression(labelCol="label", featuresCol="features")
pipeline = Pipeline(stages=[assembler, lr])
model = pipeline.fit(training_data)
# 预测测试集
predictions = model.transform(test_data)
# 评估模型
evaluator = BinaryClassificationEvaluator(labelCol="label", rawPredictionCol="rawPrediction")
accuracy = evaluator.evaluate(predictions)
# 输出结果
print("Accuracy = %.2f" % (accuracy * 100))
```
代码解释:
1. 首先,使用`format`方法加载数据文件,数据以LibSVM格式进行存储。
2. 然后,使用`VectorAssembler`将数据的多个特征组合为一个特征向量。
3. 接下来,在加载的数据上划分训练集和测试集。
4. 然后,创建一个逻辑回归模型,并构建一个包含数据处理和训练模型的Pipeline。
5. 接着,使用Pipeline来训练模型,并在测试集上进行预测。
6. 最后,使用`BinaryClassificationEvaluator`评估模型的准确性,输出准确率。
该示例代码展示了如何使用Spark MLlib进行机器学习任务,Spark MLlib提供了丰富的机器学习算法和工具,方便进行大规模数据集的机器学习任务。
## 5. Spark在实际应用中的案例
### 5.1 电商行业中的个性化推荐
个性化推荐是电商行业中非常重要的一项应用。通过分析用户的浏览历史、购买记录、兴趣爱好等信息,Spark可以帮助电商企业为用户提供定制化的商品推荐,从而提升用户体验和销售额。
在个性化推荐的实现中,Spark可以利用其机器学习库Spark MLlib来进行用户画像的构建和用户兴趣预测。具体步骤如下:
1. 数据准备:将用户的浏览历史、购买记录等数据进行清洗和加工,转化为适合机器学习算法处理的格式。
2. 特征提取:根据用户的行为数据,提取用户的特征向量,如浏览的商品类别、购买的价格区间等。
3. 模型训练:使用Spark MLlib中的机器学习算法,如协同过滤、分类算法等,对用户的特征向量进行训练,构建用户兴趣模型。
4. 推荐商品:根据用户的特征向量和兴趣模型,通过Spark的推荐引擎生成个性化的商品推荐列表,推送给用户。
通过这样的方式,电商企业可以根据用户的个性化需求,精准地推荐商品,提高用户的购买转化率和用户忠诚度。
### 5.2 金融领域中的风险控制
在金融领域中,风险控制是关键的任务之一。Spark可以帮助金融机构实时地分析和监控各种风险,如欺诈风险、信用风险、市场风险等,以保证金融机构的稳健经营。
Spark的实时数据处理和流式计算能力非常适合金融领域的风险控制。通过实时监控用户交易数据、市场行情数据等,在Spark Streaming组件的支持下,可以快速识别出潜在的风险情况,并及时采取相应的措施。
另外,Spark的机器学习库MLlib可以应用于金融领域的风险预测和评估。通过对历史交易数据进行分析和建模,可以构建出风险预测模型,用于对未来交易的风险进行预测和控制。
### 5.3 互联网广告的精准投放
互联网广告行业需要根据用户的兴趣、行为等信息,将广告投放给最合适的用户群体,以提高广告的效果和点击率。Spark可以帮助广告公司实现精准的广告投放。
Spark的大规模数据处理能力和机器学习库MLlib可以帮助广告公司进行大规模数据的清洗和处理,构建用户兴趣模型,并根据用户的兴趣模型和广告主的需求,将广告投放给最匹配的用户。
另外,Spark的实时数据处理能力可以支持实时竞价广告等场景。通过对实时产生的用户行为数据进行处理和分析,可以根据用户的实时兴趣和上下文环境,实时选择合适的广告进行投放。
总之,Spark在互联网广告领域可以提供高效、精准的广告投放服务,帮助广告公司提升广告效果和点击率。
## 6. Spark的未来发展趋势
Spark作为一个开源框架,一直致力于提供更强大和高效的大数据处理能力。在未来的发展中,Spark将继续不断地优化和增强自身的功能,以满足不断增长的大数据处理需求。
以下是Spark未来发展的一些趋势:
### 6.1 增强实时处理和流式计算能力
随着实时数据处理的需求越来越高,Spark将进一步加强其实时处理和流式计算能力。目前,Spark Streaming已经提供了对实时数据流的支持,但在大规模实时处理和低延迟计算方面还有进一步的提升空间。未来的版本中,我们可以期待更多的优化和改进,使Spark在实时处理和流式计算方面更加出色。
### 6.2 更好的与其他大数据技术集成
随着大数据技术的不断发展,Spark需要与其他技术进行更好的集成,以提供更多样化的解决方案。目前,Spark已经与Hadoop等大数据生态系统中的主要组件进行了集成,如HDFS、YARN等。未来,我们可以预见Spark将继续扩展与其他大数据技术的集成,如与分布式存储系统如Ceph、分布式计算引擎如Flink等的集成,使用户能够更灵活地使用不同的大数据工具。
### 6.3 集群资源管理和调度的优化
在大规模数据处理中,有效管理和调度集群资源是非常重要的。Spark当前已经有了基本的集群资源调度机制,如Spark Standalone模式和与YARN的集成,但仍然存在一些挑战和瓶颈。未来,Spark将继续优化集群资源管理和调度的算法和机制,以提高整个集群的利用率和性能,并减少用户的负担。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏为您介绍了Spark在大数据处理中的作用以及其各个方面的使用指南。首先,我们将向您提供关于Spark的简介,以及它如何在大数据处理中发挥重要作用的信息。然后,我们将为您提供关于如何安装和配置Spark的详细指南。接下来,我们将教您如何使用Spark进行简单的数据处理,并详细解释弹性分布式数据集(RDD)和DataFrame的工作原理。我们还将讲解Spark SQL的使用方法,包括数据查询和分析。此外,我们还涵盖了Spark Streaming、Spark MLlib和Spark GraphX等领域的知识,以及Spark与Hadoop生态系统的集成方法。我们还将为您介绍如何调优和优化Spark的性能,并展示Spark在数据清洗、推荐系统、自然语言处理、物联网数据处理、实时分析和数据可视化等领域的应用实践。通过本专栏,您将深入了解Spark并掌握其在大规模数据处理中的挑战和应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电子组件可靠性快速入门:IEC 61709标准的10个关键点解析
# 摘要
电子组件可靠性是电子系统稳定运行的基石。本文系统地介绍了电子组件可靠性的基础概念,并详细探讨了IEC 61709标准的重要性和关键内容。文章从多个关键点深入分析了电子组件的可靠性定义、使用环境、寿命预测等方面,以及它们对于电子组件可靠性的具体影响。此外,本文还研究了IEC 61709标准在实际应用中的执行情况,包括可靠性测试、电子组件选型指导和故障诊断管理策略。最后,文章展望了IEC 61709标准面临的挑战及未来趋势,特别是新技术对可靠性研究的推动作用以及标准的适应性更新。
# 关键字
电子组件可靠性;IEC 61709标准;寿命预测;故障诊断;可靠性测试;新技术应用
参考资源
KEPServerEX扩展插件应用:增强功能与定制解决方案的终极指南
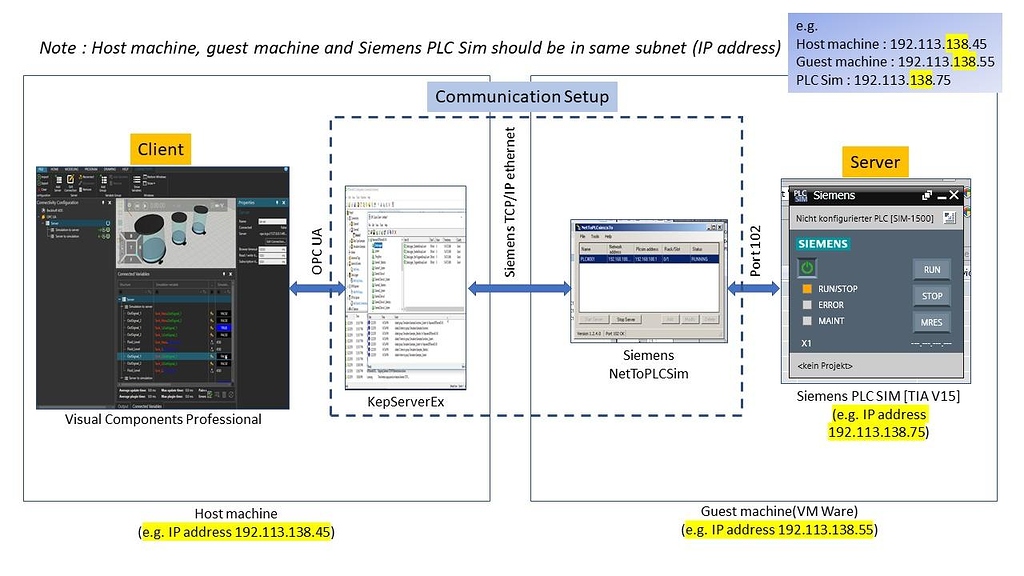
# 摘要
本文全面介绍了KEPServerEX扩展插件的概况、核心功能、实践案例、定制解决方案以及未来的展望和社区资源。首先概述了KEPServerEX扩展插件的基础知识,随后详细解析了其核心功能,包括对多种通信协议的支持、数据采集处理流程以及实时监控与报警机制。第三章通过
【Simulink与HDL协同仿真】:打造电路设计无缝流程

# 摘要
本文全面介绍了Simulink与HDL协同仿真技术的概念、优势、搭建与应用过程,并详细探讨了各自仿真环境的配置、模型创建与仿真、以及与外部代码和FPGA的集成方法。文章进一步阐述了协同仿真中的策略、案例分析、面临的挑战及解决方案,提出了参数化模型与自定义模块的高级应用方法,并对实时仿真和硬件实现进行了深入探讨。最
高级数值方法:如何将哈工大考题应用于实际工程问题
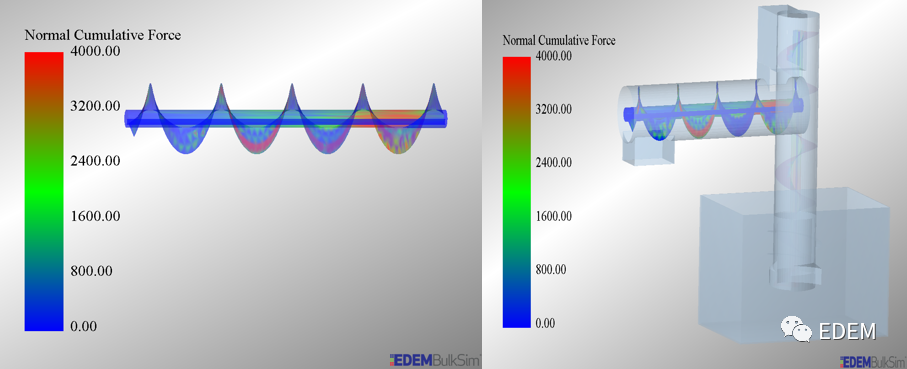
# 摘要
数值方法作为工程计算中不可或缺的工具,在理论研究和实际应用中均显示出其重要价值。本文首先概述了数值方法的基本理论,包括数值分析的概念、误差分类、稳定性和收敛性原则,以及插值和拟合技术。随后,文章通过分析哈工大的考题案例,探讨了数值方法在理论应用和实际问
深度解析XD01:掌握客户主数据界面,优化企业数据管理

# 摘要
客户主数据界面作为企业信息系统的核心组件,对于确保数据的准确性和一致性至关重要。本文旨在探讨客户主数据界面的概念、理论基础以及优化实践,并分析技术实现的不同方法。通过分析客户数据的定义、分类、以及标准化与一致性的重要性,本文为设计出高效的主数据界面提供了理论支撑。进一步地,文章通过讨论数据清洗、整合技巧及用户体验优化,指出了实践中的优化路径。本文还详细阐述了技术栈选择、开发实践和安
Java中的并发编程:优化天气预报应用资源利用的高级技巧
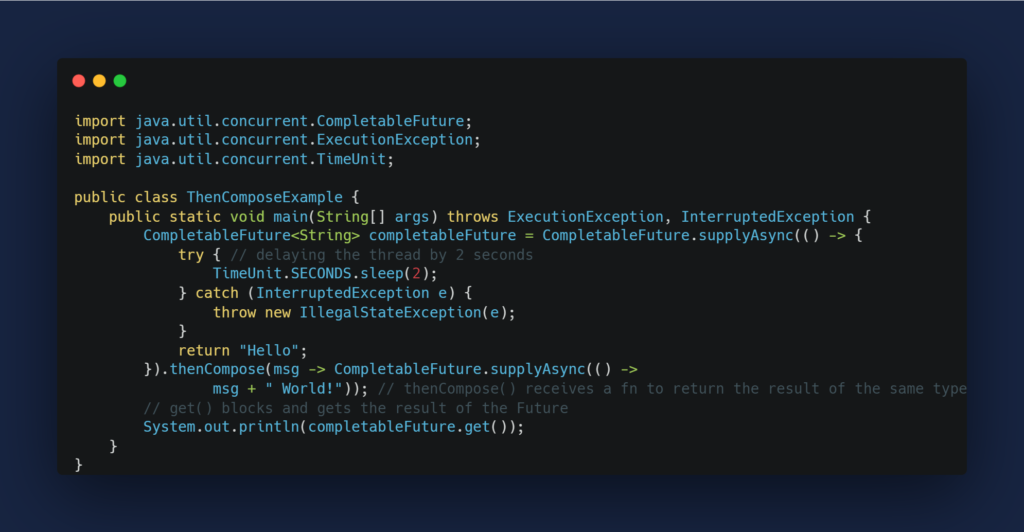
# 摘要
本论文针对Java并发编程技术进行了深入探讨,涵盖了并发基础、线程管理、内存模型、锁优化、并发集合及设计模式等关键内容。首先介绍了并发编程的基本概念和Java并发工具,然后详细讨论了线程的创建与管理、线程间的协作与通信以及线程安全与性能优化的策略。接着,研究了Java内存模型的基础知识和锁的分类与优化技术。此外,探讨了并发集合框架的设计原理和
计算机组成原理:并行计算模型的原理与实践
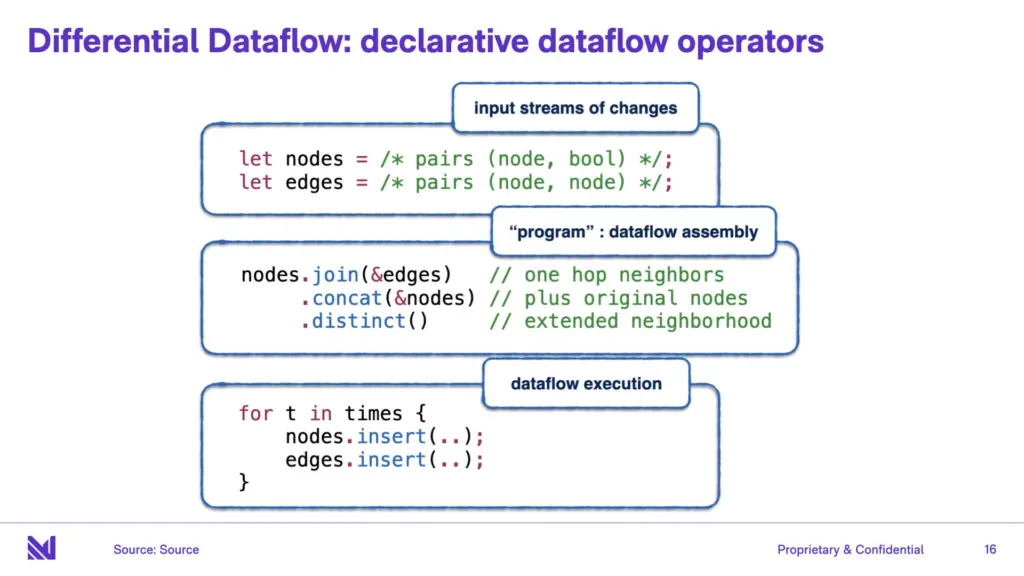
# 摘要
随着计算需求的增长,尤其是在大数据、科学计算和机器学习领域,对并行计算模型和相关技术的研究变得日益重要。本文首先概述了并行计算模型,并对其基础理论进行了探讨,包括并行算法设计原则、时间与空间复杂度分析,以及并行计算机体系结构。随后,文章深入分析了不同的并行编程技术,包括编程模型、语言和框架,以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )