Spark RDD: 弹性分布式数据集详解
发布时间: 2023-12-11 16:07:47 阅读量: 95 订阅数: 25 

Spark RDD弹性分布式数据集
# 章节一:介绍Spark RDD
Apache Spark是一个快速、通用、可扩展的分布式计算系统,提供了高级API(如RDD)来允许用户使用Java、Scala、Python和R编写大规模并行应用程序。在Spark中,RDD(弹性分布式数据集)是其核心概念之一,对于理解和使用Spark具有重要意义。
## 什么是RDD
RDD(Resilient Distributed Dataset)即弹性分布式数据集,是Spark的核心抽象。它代表一个可并行操作的不可变数据集合,在各个节点上分布存储,提供了容错机制和基于内存的计算能力。RDD可以从HDFS、Hive、HBase等数据源创建,也可以通过在驱动程序中对一个集合调用parallelize方法来构建。
## RDD的特性和优势
RDD具有以下特性和优势:
- **容错性(Fault Tolerance)**:RDD通过记录每个RDD的转换操作来实现弹性,一旦某个分区数据丢失,可以通过转换操作重新计算,保证了数据可靠性。
- **内存计算**:RDD支持内存计算,能够在内存中快速进行数据处理,极大地提升了计算性能。
- **不可变性**:RDD是不可变的数据结构,一旦创建就不可被修改,可以避免并发访问的数据一致性问题。
- **虚拟化**:RDD通过记录转换操作而不实际执行,可以有效地优化执行计划,提升计算性能。
## RDD与传统数据集的对比
相比传统的数据集(如数组、列表等),RDD具有以下不同之处:
- **分布式**:RDD可以在集群上进行并行计算,适用于大规模数据处理。
- **容错**:RDD具有容错性,可以自动恢复部分数据的丢失。
- **懒加载**:RDD采用懒加载机制,在调用行动操作之前,转换操作并不会立即执行,可以有效地优化计算过程。
## 章节二:RDD的基本操作
在本章中,我们将详细介绍Spark RDD的基本操作。这些操作包括RDD的创建和初始化、RDD的转换操作以及RDD的行动操作。
### RDD的创建和初始化
在Spark中,我们可以通过不同的方式来创建和初始化RDD。下面是几种常见的方式:
#### 1. 并行集合(Parallelized Collections)
通过并行集合,我们可以将已有的集合转换为RDD。以下是一个使用并行集合的例子:
```python
from pyspark import SparkContext
# 创建SparkContext对象
sc = SparkContext(master="local", appName="RDD Example")
# 创建并行集合的RDD
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
# 打印RDD的内容
rdd.collect()
```
#### 2. 外部存储(External Datasets)
Spark支持从外部存储系统(如HDFS、HBase等)中加载数据并创建RDD。以下是一个使用外部存储的例子:
```python
from pyspark import SparkContext
# 创建SparkContext对象
sc = SparkContext(master="local", appName="RDD Example")
# 从文本文件中创建RDD
rdd = sc.textFile("hdfs://path/to/file.txt")
# 打印RDD的内容
rdd.collect()
```
#### 3. 数据转换
RDD提供了多种转换操作,用于对数据进行处理和转换。以下是几个常见的转换操作:
- `map()`:对RDD中的每个元素应用一个函数,并返回新的RDD。如下面的例子,将RDD中的每个元素乘以2:
```python
rdd = sc.parallelize([1, 2, 3, 4, 5])
new_rdd = rdd.map(lambda x: x * 2)
```
- `filter()`:对RDD中的每个元素应用一个函数,并返回满足条件的元素组成的新的RDD。如下面的例子,过滤出RDD中的偶数:
```python
rdd = sc.parallelize([1, 2, 3, 4, 5])
new_rdd = rdd.filter(lambda x: x % 2 == 0)
```
- `flatMap()`:与`map()`类似,但每个输入元素可以映射到零个或多个输出元素。如下面的例子,将每个字符串拆分为单词:
```python
rdd = sc.parallelize(["Hello Spark", "Hello World"])
new_rdd = rdd.flatMap(lambda x: x.split(" "))
```
### RDD的行动操作
RDD的行动操作是触发计算并返回结果的操作。以下是几个常见的行动操作:
#### 1. collect()
`collect()`操作用于将RDD中的所有元素返回到驱动器程序。请注意,如果RDD太大而无法放入驱动器程序的内存中,则不应使用`collect()`操作。
```python
rdd = sc.parallelize([1, 2, 3, 4, 5])
result = rdd.collect()
```
#### 2. count()
`count()`操作用于返回RDD中的元素数量。
```python
rdd = sc.parallelize([1, 2, 3, 4, 5])
count = rdd.count()
```
#### 3. first()
`first()`操作用于返回RDD中的第一个元素。
```python
rdd = sc.parallelize([1, 2, 3, 4, 5])
first_element = rdd.first()
```
## 章节三:RDD的持久化
在使用Spark进行大规模数据处理时,RDD的持久化是一项非常重要的技术,可以显著提高计算性能和效率。本章节将介绍RDD的持久化概念、基本的持久化级别以及持久化操作的最佳实践方法。
### RDD的持久化概念
RDD的持久化是指将RDD的计算结果缓存到内存或者磁盘中,以便之后的重用。在RDD被持久化之后,每当需要使用RDD时,Spark就可以直接从缓存中读取数据,而不需要重新计算RDD。这样可以避免重复计算,提高计算效率。
### 基本的持久化级别
Spark提供了多种不同的持久化级别,可以根据具体情况选择适合的级别,以平衡性能和内存占用。
1. MEMORY_ONLY:将RDD的计算结果以Java对象的形式存储在内存中。如果内存空间不足,可能会导致部分数据需要重新计算。
2. MEMORY_AND_DISK:将RDD的计算结果以Java对象的形式存储在内存中,如果内存空间不足,多余的数据会溢出到磁盘上。这个级别可以保证数据的可靠性,但读取速度可能会受到磁盘访问速度的影响。
3. MEMORY_ONLY_SER:将RDD的计算结果以序列化的方式存储在内存中。相比于MEMORY_ONLY级别,这个级别可以节省内存空间,但在读取数据时需要反序列化。
4. MEMORY_AND_DISK_SER:将RDD的计算结果以序列化的方式存储在内存中,如果内存空间不足,多余的数据会溢出到磁盘上。这个级别可以在保证数据可靠性的同时,减少内存占用。
5. OFF_HEAP:将RDD的计算结果存储在堆外内存中,可以提高内存使用效率。
### 持久化操作的最佳实践
在使用RDD进行持久化操作时,以下是一些最佳实践方法:
1. 根据具体需求选择合适的持久化级别,权衡性能和内存占用。
2. 对于需要频繁访问的RDD,可以使用cache()方法进行持久化,在多次使用时可以节省计算时间。
3. 对于需重复使用的RDD,可以使用persist()方法指定持久化级别。
4. 在RDD不再需要使用时,及时调用unpersist()方法释放内存空间。
5. 在持久化大规模RDD时,可以使用checkpoint()方法将数据存储到磁盘上,以便后续的恢复和重用。
综上所述,RDD的持久化是Spark中的重要技术之一,可以提高计算性能和效率,对于大规模数据处理具有重要意义。合理选择持久化级别和使用最佳实践方法,可以充分发挥RDD的优势,提高数据处理的效率。
*代码示例见下:*
```python
# 创建RDD
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
# 使用cache()方法进行持久化
rdd.cache()
# 使用persist()方法指定持久化级别
rdd.persist(StorageLevel.MEMORY_AND_DISK)
# 使用unpersist()方法释放内存空间
rdd.unpersist()
# 使用checkpoint()方法持久化到磁盘
sc.setCheckpointDir("/tmp/checkpoint")
rdd.checkpoint()
```
以上代码示例展示了RDD的持久化操作,包括使用cache()方法进行内存持久化、使用persist()方法指定持久化级别、使用unpersist()方法释放内存空间以及使用checkpoint()方法将数据持久化到磁盘上。
持久化的操作可以根据实际需求进行选择,并结合最佳实践方法,以提高计算性能和数据处理效率。
### 章节四:RDD的依赖关系
在Spark中,RDD的依赖关系是非常重要的概念,它直接影响到任务的调度和性能优化。在本章节中,我们将深入探讨RDD的依赖关系,包括窄依赖与宽依赖的理解,依赖关系对任务调度的影响,以及最佳实践下如何优化RDD的依赖关系。
#### 窄依赖与宽依赖的理解
在Spark中,每个RDD都会记录其父RDD或者父RDDs,这种关系被称为依赖关系。依赖关系分为窄依赖和宽依赖两种类型。
窄依赖(Narrow Dependency):当子RDD的每一个分区只依赖于父RDD中的一个或多个分区的数据时,我们称这种依赖关系为窄依赖。窄依赖的特点是父RDD的一个分区仅会贡献到子RDD的一个或多个分区中。这种依赖关系可以让每个父分区的数据仅被用于计算一个子分区,因此不会发生shuffle操作,是一种高效的依赖关系。
宽依赖(Wide Dependency):当子RDD的分区依赖于多个父RDD的分区数据时,我们称这种依赖关系为宽依赖。宽依赖会导致数据重分区(shuffle),它会将父RDD的某些分区数据混合在一起,然后再重新组织分发到子RDD的各个分区中。这种依赖关系会导致数据的重新组织和网络传输,因此较为耗时。
#### 依赖关系对任务调度的影响
依赖关系直接影响到任务之间的调度关系。如果RDD的转换操作产生的依赖关系是窄依赖,Spark会尽可能地将其父RDD和子RDD放到同一个Executor上连续执行,从而提高性能。而当依赖关系是宽依赖时,Spark就需要进行数据的shuffle操作,这会导致跨节点之间的数据传输和重组,从而影响任务的性能。
#### 最佳实践:优化RDD的依赖关系
1. 尽量避免宽依赖的产生,可以通过合理的数据分区、使用`coalesce`或`repartition`等手段来减少shuffle操作。
2. 对于宽依赖的场景,可以通过调整`spark.shuffle.partitions`参数来优化shuffle过程中的分区数量,从而减少数据的传输量和网络开销。
## 章节五:RDD的并行计算
在Spark中,RDD的并行计算是其核心功能之一。RDD的并行计算能够将数据分割为多个分区,并在集群中的多个节点上进行并行处理,大大提高了数据处理的效率。本章将介绍RDD的分区机制、并行计算模型以及数据本地性优化原则。
### RDD的分区机制
在Spark中,RDD的分区是将数据集划分为更小的部分,每个分区都可以在集群中的不同节点上处理。RDD的分区机制可以根据数据的规模、资源的分配情况等因素来划分数据,从而实现并行处理。Spark提供了默认的分区机制,同时也支持自定义分区。
### RDD的并行计算模型
RDD的并行计算是通过将操作应用于每个分区来实现的,每个分区可以在不同节点上同时进行计算。Spark使用惰性求值的方式,在执行行动操作时才会触发计算。执行计算时,Spark会根据依赖关系来调度任务,将任务分配到不同的节点上执行。
### RDD的数据本地性优化原则
在RDD的并行计算中,数据本地性是指尽量将任务调度到存储有数据的节点上执行,减少数据传输的开销。Spark提供了数据本地性优化的机制,可以根据数据和节点之间的距离来选择最佳执行节点。在编写RDD程序时,可以通过合理的数据分区和使用合适的操作来提高数据本地性。
### 章节六:RDD的应用案例
在实际的大数据处理中,Spark RDD 可以应用于各种场景,以下是 RDD 的几个典型应用案例:
#### 1. 实时日志分析
在大规模的网络系统中,实时日志分析是一个常见的需求。通过 Spark RDD,可以实时地读取和处理大量的日志数据,进行实时统计分析和异常检测。例如,可以使用 RDD 对日志数据进行清洗、过滤、聚合等操作,从而实时监控系统状态、绘制实时报表和可视化展示。
```python
# 代码示例
from pyspark import SparkContext
sc = SparkContext("local", "LogAnalysisApp")
logs_rdd = sc.textFile("hdfs://path_to_log_file") # 从HDFS加载日志文件
error_logs_rdd = logs_rdd.filter(lambda line: "ERROR" in line) # 过滤出错误日志
error_count = error_logs_rdd.count() # 统计错误日志数量
print("实时错误日志数量:", error_count)
```
通过上述代码,我们可以实时加载日志文件,使用 RDD 进行过滤操作,统计并输出错误日志的数量。
#### 2. 大规模数据处理
在大数据处理场景下,Spark RDD 可以用于大规模的数据处理任务,如数据清洗、特征抽取、数据转换等。通过 RDD 的并行计算能力,可以高效地处理海量的数据,实现复杂的数据处理逻辑。
```java
// 代码示例
JavaRDD<String> dataRDD = sparkContext.textFile("hdfs://path_to_data_file"); // 从HDFS加载数据
JavaPairRDD<String, Integer> wordCountRDD = dataRDD
.flatMap(line -> Arrays.asList(line.split(" ")).iterator())
.mapToPair(word -> new Tuple2<>(word, 1))
.reduceByKey(Integer::sum); // 计算单词出现次数
wordCountRDD.saveAsTextFile("hdfs://output_path"); // 保存结果到HDFS
```
上述 Java 代码展示了如何使用 RDD 进行大规模数据处理,包括单词计数和结果保存到 HDFS。
#### 3. 机器学习与图分析中的应用
Spark 提供了丰富的机器学习库(MLlib)和图计算库(GraphX),这些库底层都是基于 RDD 进行计算的。借助 RDD 的并行计算能力,可以高效地进行机器学习模型训练、图算法计算等任务。
```scala
// 代码示例
import org.apache.spark.graphx._
import org.apache.spark.rdd.RDD
// 构建一个简单的图
val vertices: RDD[(Long, String)] = ...
val edges: RDD[Edge[Int]] = ...
val graph: Graph[String, Int] = Graph(vertices, edges)
// 使用 RDD 进行图计算
val cc = graph.connectedComponents().vertices
cc.collect().foreach(println)
```
上述 Scala 代码展示了如何使用 RDD 进行简单图的构建和计算,这是图分析中常见的操作。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏为您介绍了Spark在大数据处理中的作用以及其各个方面的使用指南。首先,我们将向您提供关于Spark的简介,以及它如何在大数据处理中发挥重要作用的信息。然后,我们将为您提供关于如何安装和配置Spark的详细指南。接下来,我们将教您如何使用Spark进行简单的数据处理,并详细解释弹性分布式数据集(RDD)和DataFrame的工作原理。我们还将讲解Spark SQL的使用方法,包括数据查询和分析。此外,我们还涵盖了Spark Streaming、Spark MLlib和Spark GraphX等领域的知识,以及Spark与Hadoop生态系统的集成方法。我们还将为您介绍如何调优和优化Spark的性能,并展示Spark在数据清洗、推荐系统、自然语言处理、物联网数据处理、实时分析和数据可视化等领域的应用实践。通过本专栏,您将深入了解Spark并掌握其在大规模数据处理中的挑战和应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
TSPL2高级打印技巧揭秘:个性化格式与样式定制指南

# 摘要
TSPL2打印语言作为工业打印领域的重要技术标准,具备强大的编程能力和灵活的控制指令,广泛应用于各类打印设备。本文首先对TSPL2打印语言进行概述,详细介绍其基本语法结构、变量与数据类型、控制语句等基础知识。接着,探讨了TSPL2在高级打印技巧方面的应用,包括个性化打印格式设置、样
JFFS2文件系统设计思想:源代码背后的故事
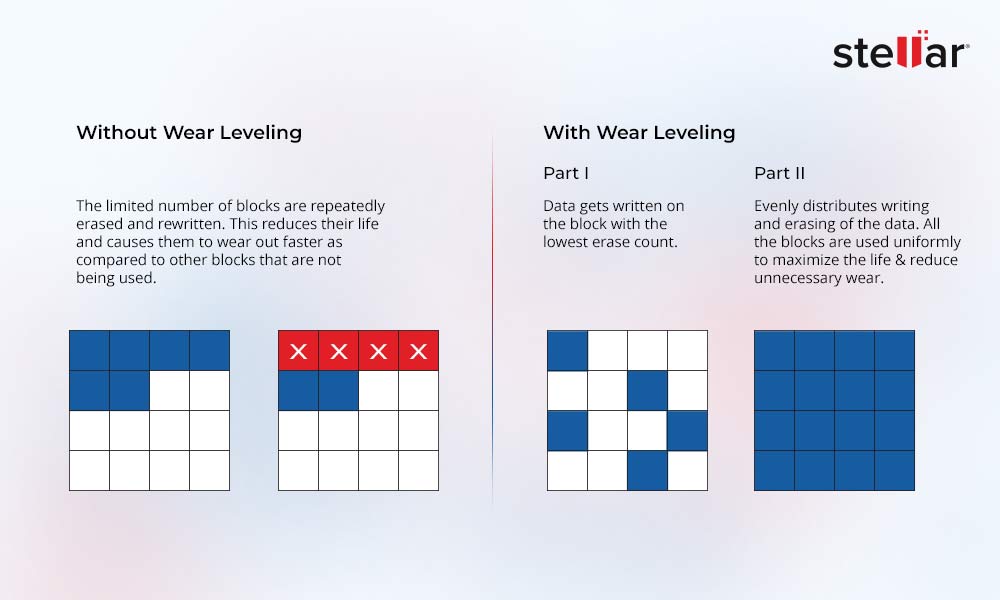
# 摘要
本文对JFFS2文件系统进行了全面的概述和深入的分析。首先介绍了JFFS2文件系统的基本理论,包括文件系统的基础概念和设计理念,以及其核心机制,如红黑树的应用和垃圾回收机制。接着,文章深入剖析了JFFS2的源代码,解释了其结构和挂载过程,以及读写操作的实现原理。此外,针对JFFS2的性能优化进行了探讨,分析了性能瓶颈并提出了优化策略。在此基础上,本文还研究了J
EVCC协议版本兼容性挑战:Gridwiz更新维护攻略

# 摘要
本文对EVCC协议进行了全面的概述,并探讨了其版本间的兼容性问题,这对于电动车充电器与电网之间的有效通信至关重要。文章分析了Gridwiz软件在解决EVCC兼容性问题中的关键作用,并从理论和实践两个角度深入探讨了Gridwiz的更新维护策略。本研究通过具体案例分析了不同EVCC版本下Gridwiz的应用,并提出了高级维护与升级技巧。本文旨在为相关领域的工程师和开发者提供有关EVCC协议及其兼容性维护
计算机组成原理课后答案解析:张功萱版本深入理解

# 摘要
计算机组成原理是理解计算机系统运作的基础。本文首先概述了计算机组成原理的基本概念,接着深入探讨了中央处理器(CPU)的工作原理,包括其基本结构和功能、指令执行过程以及性能指标。然后,本文转向存储系统的工作机制,涵盖了主存与缓存的结构、存储器的扩展与管理,以及高速缓存的优化策略。随后,文章讨论了输入输出系统与总线的技术,阐述了I/O系统的
CMOS传输门故障排查:专家教你识别与快速解决故障
# 摘要
CMOS传输门故障是集成电路设计中的关键问题,影响电子设备的可靠性和性能。本文首先概述了CMOS传输门故障的普遍现象和基本理论,然后详细介绍了故障诊断技术和解决方法,包括硬件更换和软件校正等策略。通过对故障表现、成因和诊断流程的分析,本文旨在提供一套完整的故障排除工具和预防措施。最后,文章展望了CMOS传输门技术的未来挑战和发展方向,特别是在新技术趋势下如何面对小型化、集成化挑战,以及智能故障诊断系统和自愈合技术的发展潜力。
# 关键字
CMOS传输门;故障诊断;故障解决;信号跟踪;预防措施;小型化集成化
参考资源链接:[cmos传输门工作原理及作用_真值表](https://w
KEPServerEX秘籍全集:掌握服务器配置与高级设置(最新版2018特性深度解析)
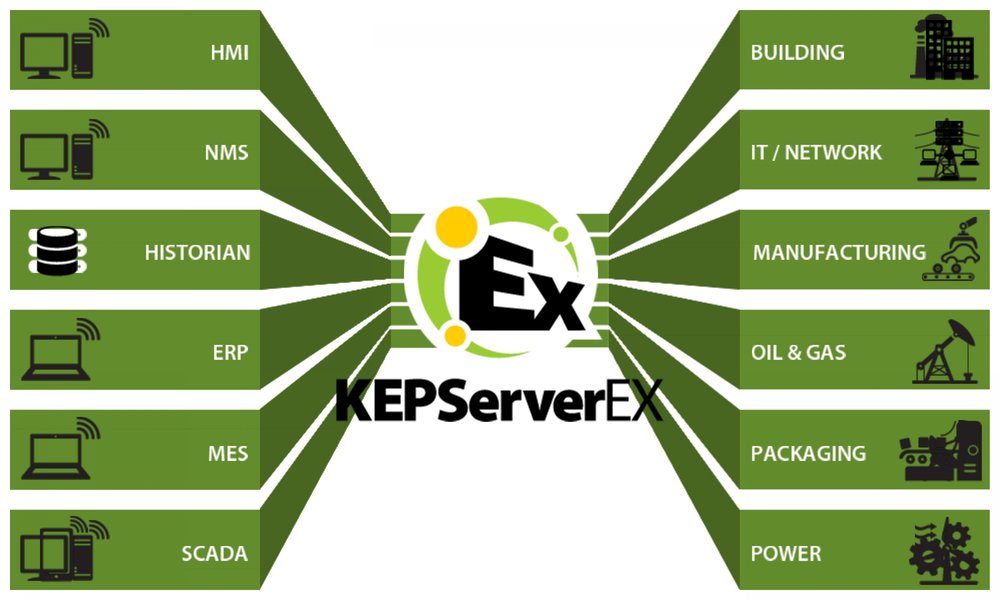
# 摘要
KEPServerEX作为一种广泛使用的工业通信服务器软件,为不同工业设备和应用程序之间的数据交换提供了强大的支持。本文从基础概述入手,详细介绍了KEPServerEX的安装流程和核心特性,包括实时数据采集与同步,以及对通讯协议和设备驱动的支持。接着,文章深入探讨了服务器的基本配置,安全性和性能优化的高级设
【域控制新手起步】:一步步掌握组策略的基本操作与应用
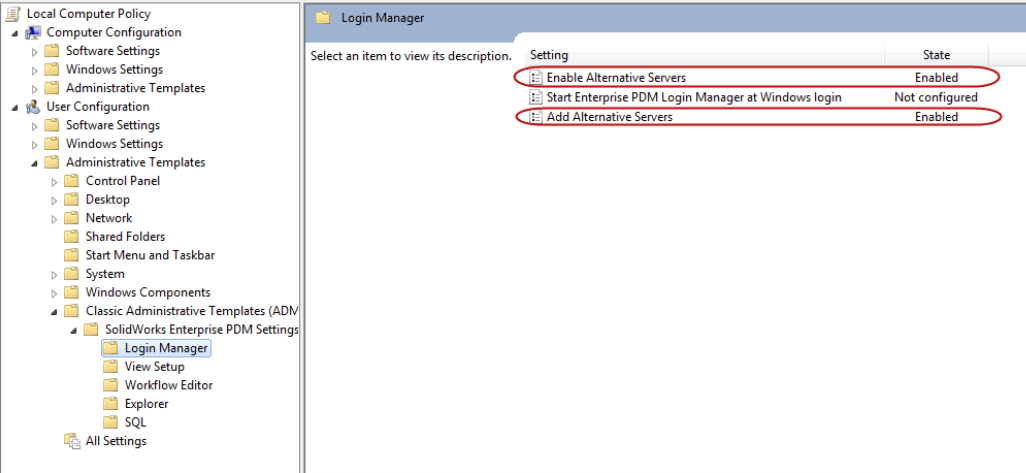
# 摘要
组策略是域控制器中用于配置和管理网络环境的重要工具。本文首先概述了组策略的基本概念和组成部分,并详细解释了其作用域与优先级规则,以及存储与刷新机制。接着,文章介绍了组策略的基本操作,包括通过管理控制台GPEDIT.MSC的使用、组策略对象(GPO)的管理,以及部署和管理技巧。在实践应用方面,本文探讨了用户环境管理、安全策略配置以及系统配置与优化。此
【SolidWorks自动化工具】:提升重复任务效率的最佳实践

# 摘要
本文全面探讨了SolidWorks自动化工具的开发和应用。首先介绍了自动化工具的基本概念和SolidWorks API的基础知识,然后深入讲解了编写基础自动化脚本的技巧,包括模型操作、文件处理和视图管理等。接着,本文阐述了自动化工具的高级应用
Android USB音频设备通信:实现音频流的无缝传输
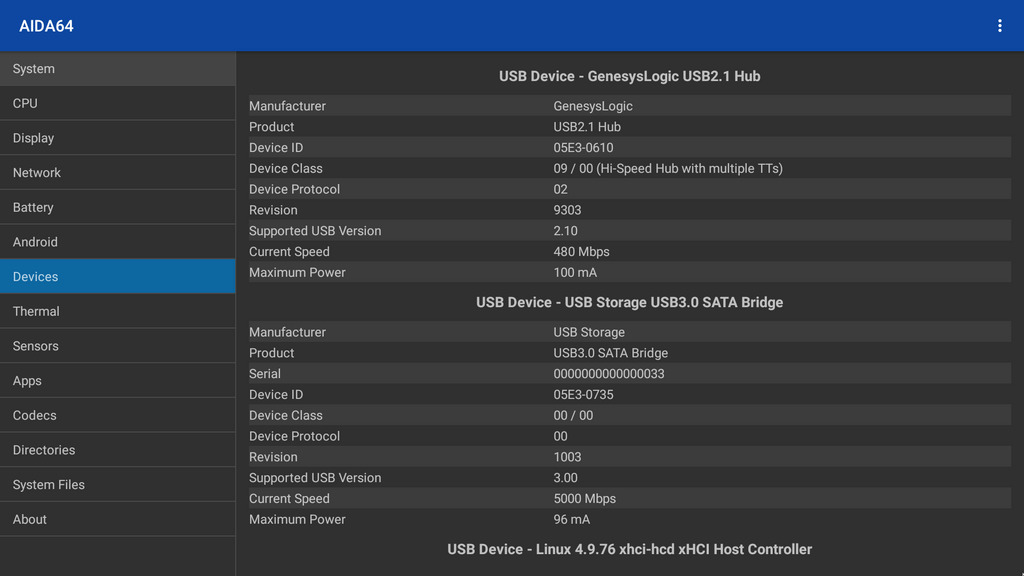
# 摘要
随着移动设备的普及,Android平台上的USB音频设备通信已成为重要话题。本文从基础理论入手,探讨了USB音频设备工作原理及音频通信协议标准,深入分析了Android平台音频架构和数据传输流程。随后,实践操作章节指导读者了解如何设置开发环境,编写与测试USB音频通信程序。文章深入讨论了优化音频同步与延迟,加密传输音频数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )