Gel-PRO ANALYZER:如何处理和分析复杂数据集
发布时间: 2024-12-16 17:38:32 阅读量: 2 订阅数: 5 

条带分析(Gel-Pro_analyzer).rar

参考资源链接:[Gel-PRO ANALYZER软件:凝胶定量分析完全指南](https://wenku.csdn.net/doc/15xjsnno5m?spm=1055.2635.3001.10343)
# 1. Gel-PRO ANALYZER概述
在现代数据分析领域,工具的高效性与准确性是企业成功的关键。Gel-PRO ANALYZER是这样一款集数据预处理、探索性分析、高级数据分析技术于一身的全面性分析平台。它不仅支持自动化数据处理流程,还能实现复杂数据集的深度学习处理,尤其适用于需要高度定制化分析的场景。
## 1.1 功能定位与应用范围
Gel-PRO ANALYZER旨在简化数据分析流程,提高分析效率。它的应用范围包括但不限于生物信息学、金融分析、市场研究等。通过对大数据集的高效处理与分析,它能为用户提供准确的洞察和决策支持。
## 1.2 核心优势与创新点
Gel-PRO ANALYZER的核心优势在于其独特的算法和直观的用户界面设计。创新点在于它能够处理多种类型的数据格式,并提供了丰富的数据可视化工具,使得非专业人士也能轻松进行复杂的数据操作和分析。此外,它还支持机器学习算法与深度学习框架,为高级分析提供强大的技术支持。
# 2. 数据预处理与清洗
数据预处理和清洗是数据分析和机器学习流程中的关键步骤。它们确保了数据质量,为后续的分析工作打下了坚实的基础。在这一章节中,我们将详细探讨数据导入与格式化、缺失值和异常值的处理,以及数据集的分割与重构等主题。
### 2.1 数据导入与格式化
在进行数据预处理之前,必须首先导入数据并进行初步的格式化处理。格式化的目标是将数据转换为分析工具能够识别和处理的格式,为后续步骤做准备。
#### 2.1.1 支持的文件类型和导入方法
Gel-PRO ANALYZER 支持多种数据格式,包括但不限于CSV、Excel、JSON和SQL数据库。导入这些数据的基本方法包括:
- **CSV/Excel文件**:使用内置的导入工具,选择文件路径后读取数据。
- **JSON文件**:在代码中使用JSON解析库,例如Python中的`json`模块,来读取和解析数据。
- **SQL数据库**:通过编写SQL查询语句,连接数据库,并读取数据。
以下是使用Python导入CSV文件的一个示例代码:
```python
import pandas as pd
# 使用pandas库导入CSV文件
data = pd.read_csv('data.csv')
# 显示数据前五行以检查导入是否成功
print(data.head())
```
该代码块使用了`pandas`库,它是一个广泛使用的数据分析工具包,能够处理包括导入在内的多种数据操作。
#### 2.1.2 数据类型转换和标准化
数据导入之后,接下来需要进行数据类型转换和标准化操作。数据类型转换确保每列数据的类型正确,例如将数字字符串转换为整数或浮点数,将日期字符串转换为日期类型。标准化处理涉及调整不同尺度和量纲的数据,使之在相同的范围内,便于进行比较和计算。
以下是数据类型转换和标准化处理的一个例子:
```python
# 假设data是已经导入的DataFrame
# 将名为 'age' 的列从字符串类型转换为整数
data['age'] = data['age'].astype(int)
# 将名为 'price' 的列从字符串类型转换为浮点数,并进行标准化
data['price'] = data['price'].astype(float)
# 假设价格数据需要标准化到0-1范围
data['price'] = (data['price'] - data['price'].min()) / (data['price'].max() - data['price'].min())
# 检查数据转换后的前五行数据
print(data.head())
```
### 2.2 缺失值和异常值处理
在现实世界的数据集中,缺失值和异常值普遍存在,如果不加以处理,可能会对分析结果产生负面影响。
#### 2.2.1 缺失值识别与填充策略
识别缺失值通常使用数据分析库提供的方法,如`pandas`中的`isnull()`函数。填充缺失值的常见策略包括:
- **删除含有缺失值的行或列**:如果缺失值不多,可以考虑删除。
- **使用均值/中位数/众数填充**:对于数值型数据,用均值或中位数填充;对于类别型数据,用众数填充。
```python
# 使用均值填充数值型数据的缺失值
data['age'] = data['age'].fillna(data['age'].mean())
# 使用众数填充类别型数据的缺失值
data['category'] = data['category'].fillna(data['category'].mode()[0])
```
#### 2.2.2 异常值检测与修正方法
异常值指的是那些与数据集中的其他观测值明显不同的观测值。异常值可能会导致模型预测不准确。异常值检测的方法有很多,例如:
- **箱形图分析**:通过箱形图识别异常值。
- **Z-分数/标准化残差**:计算Z-分数,并找出绝对值大于特定阈值(如3)的点作为异常值。
```python
import numpy as np
# 计算Z-分数
z_scores = np.abs((data - data.mean()) / data.std())
# 假定阈值为3,找出Z-分数大于3的数据点作为异常值
outliers = np.where(z_scores > 3)
```
### 2.3 数据集的分割与重构
在数据预处理阶段的最后,需要对数据集进行分割和重构,以准备后续的分析和模型训练。
#### 2.3.1 训练集与测试集的划分
分割数据集为训练集和测试集是机器学习中常见的做法,目的是在模型训练后评估其性能。一般按80%训练集和20%测试集的比例进行分割。
```python
from sklearn.model_selection import train_test_split
# 分离特征和目标变量
X = data.drop('target', axis=1)
y = data['target']
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 显示分割后的集合大小
print("训练集特征数量: ", X_train.shape)
print("测试集特征数量: ", X_test.shape)
```
#### 2.3.2 特征工程与降维技巧
特征工程涉及对数据集进行变换,从而增强模型的性能。降维是减少数据集中特征数量的过程,常见的方法包括主成分分析(PCA)和特征选择。
```python
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest
# 使用PCA进行降维
pca = PCA(n_components=0.95) # 保留95%的方差
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.transform(X_test)
# 使用SelectKBest选择最佳特征
select_k_best = SelectKBest(f_classif, k=10) # 选择最佳的10个特征
X_train_best = select_k_best.fit_transform(X_train, y_train)
X_test_best = select_k_best.transform(X_test)
# 显示降维和特征选择后的特征数量
print("PCA降维后的训练集特征数量: ", X_train_pca.shape[1])
print("SelectKBest后的训练集特征数量: ", X_train_best.shape[1])
```
通过以上步骤,数据预处理和清洗任务可以有效地完成,为后续的数据分析和模型构建奠定了坚实的基础。在本章节中,我们深入探讨了数据导入、格式化、缺失值与异常值处理、以及数据集的分割与重构等问题,并展示了相关代码示例和逻辑分析,帮助读者更好地理解和执行数据预处理工作。
# 3. 数据探索性分析
## 3.1 描述性统计分析
### 3.1.1 基本统计量的计算与解读
在数据探索性分析的初期,描述性统计分析是了解数据集基本特性的第一步。通过计算最小值、最大值、均值、中位数、标准差等基本统计量,可以初步判断数据的集中趋势和离散程度。这一环节的关键在于对这些统计量的解读与分析。
例如,在一个包含个人收入数据的表格中,我们可以计算出收入的平均值、中位数以及标准差。平均值可以告诉我们总体收入的均等水平,而中位数则更能反映一般人群的收入情况,因为中位数不受极端值的影响。标准差的大小则表明了收入的波动性,标准差越大,收入的分布越分散。
以下是使用Python中的pandas库进行描述性统计分析的示例代码:

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
小米鲁班MTB软件深度剖析:掌握设计精髓,实现高效开发

参考资源链接:[小米手机鲁班MTB V6.0.5-13-33软件参数调整指南](https://wenku.csdn.net/doc/jmd7inyjra?spm=1055.2635.3001.10343)
# 1. 小米鲁班MTB软件概述
小米鲁班MTB软件作为小米公司的新一代管理工具,为企业的项目管
【RX N5多任务处理】:提升性能的4项关键策略

参考资源链接:[Nextchip N5 RX规格书v0.0版本发布](https://wenku.csdn.net/doc/45bayfzh7a?spm=1055.2635.3001.10343)
# 1. 多任务处理在RX N5中的重要性
多任务处理是现代操作系统和微处理器设计的关键组成部分。随着计算机科学的
三菱M70参数全面解读:5步优化设备性能的秘密武器

参考资源链接:[三菱M70关键参数详解:系统、轴数与控制设置](https://wenku.csdn.net/doc/249i46rdgf?spm=1055.2635.3001.10343)
# 1. 三菱M70数控系统的概述
数控系统是现代制造业的核心,它决定着机械设备运行的精度与效率。三菱M70数控系统作为业界一款较为先进的数控系统,广泛应用于各种精密加工设备中。它具备多种高级功能,如自适应控制、多
ELMO驱动器故障急救手册:10大常见问题及快速解决方案

参考资源链接:[ELMO驱动器配置与故障排除指南](https://wenku.csdn.net/doc/6462df54543f844488998bf7?spm=1055.2635.3001.
Sentinel-1 数据集分析:SNAP 遥感数据处理的高效之道

参考资源链接:[SNAP教程:哨兵-1 SAR数据处理入门与关键操作](https://wenku.csdn.net/doc/6401abc5cce7214c316e9718?spm=1055.2635.3001.10343)
# 1. 遥感数据处理概述
遥感技术是通过不
GeoDa坐标系转换完全指南:地理空间数据坐标体系掌握
参考资源链接:[GeoDa使用手册(中文版)](https://wenku.csdn.net/doc/6412b654be7fbd1778d4655b?spm=1055.2635.3001.10343)
# 1. 坐标系转换的基础理论
在地理信息系统(GIS)应用中,坐标系转换是一个至关重要且广泛存在的技术需求。本章将为读者提供坐标系转换的基本概念、数学模型和分类方法,作为深入理解GeoDa等GIS
APT与PPA管理:Ubuntu 14.04软件控制的艺术
参考资源链接:[ubuntu-14.04-desktop-amd64.iso(网盘链接,永久有效)](https://wenku.csdn.net/doc/6412b76ebe7fbd1778d4a452?spm=1055.2635.3001.10343)
# 1. APT与PPA在Ubuntu中的角色与重要性
## 1.1 Ubuntu软件管理概述
Ubunt
EIDORS文档样式定制:个性化外观的终极指南

参考资源链接:[EIDORS教程:电阻抗层析成像步骤解析](https://wenku.csdn.net/doc/62x8x7s0q8?spm=1055.2635.3001.10343)
# 1. EIDORS文档样式定制概述
在信息技术不断进步的今天,文档的样式定制已经成为提升用户体验和品牌价值的重要手段。EIDORS文档样式
【深度学习模型部署】:深入模型转换的实践技术

参考资源链接:[MARS使用教程:代码与数据导出](https://wenku.csdn.net/doc/5vsdzkdy26?spm=1055.2635.3001.10343)
# 1. 深度学习模型部署
【数据质量控制】:云总线平台确保数据准确性的实践方法
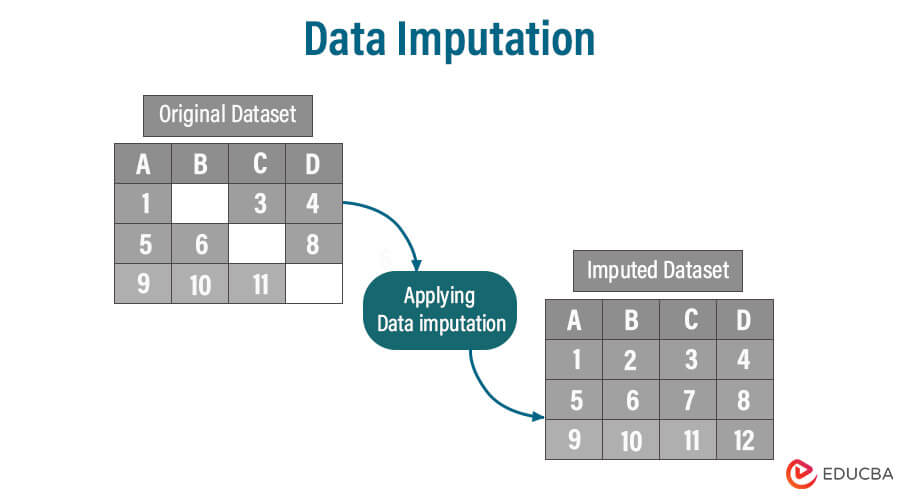
参考资源链接:[阿里云服务总线CSB操作手册](https://wenku.csdn.net/doc/7gabnevyke?spm=1055.2635.3001.10343)
# 1. 数据质量控制在云总线平台的重要性
在当今大数据时代,数据已成为企业和组织最为重要的资产之一。随着企业上云和数字化转型的不断推进,数据质量控制在云总线平台中的作用愈发重要。数据质量直接影响到决策
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )