数据仓库概述与基本原理
发布时间: 2023-12-28 04:07:12 阅读量: 37 订阅数: 21 

数据仓库概述
# 第一章:数据仓库概述
## 1.1 什么是数据仓库?
数据仓库是一个用于存储和管理企业数据的系统,它将来自不同来源的数据集成在一起,并为决策支持和商业智能应用提供高效的数据分析能力。
## 1.2 数据仓库的发展历程
数据仓库的概念最早由比尔·英蒂(Bill Inmon)和拉尔夫·金(Ralph Kimball)等人提出,经过几十年的发展,数据仓库在企业中得到了广泛的应用。
## 1.3 数据仓库与数据库管理系统的区别
数据仓库与传统的数据库管理系统(DBMS)不同,数据库管理系统侧重于日常的事务处理和数据存储,而数据仓库专注于对大量数据进行分析和查询,用于支持决策制定和业务智能的需求。
## 第二章:数据仓库架构
数据仓库架构是数据仓库系统中非常重要的一部分,它包括了整个系统的组织结构、数据流程、以及各个组成部分之间的关系。一个良好的数据仓库架构可以提高系统的灵活性、可维护性和性能。在这一章节中,我们将深入探讨数据仓库的结构和组成部分。
### 2.1 数据仓库体系结构概述
数据仓库的体系结构通常包括了数据的抽取(Extraction)、转换(Transformation)、加载(Loading)以及最终的数据展现和分析。总体来说,数据仓库的体系结构可以分为以下几个层次:数据源层、数据存储层、数据处理层和数据展现层。
数据源层主要包括了内部系统、外部数据源、实时数据源等,通过数据抽取技术将数据抽取到数据仓库中。数据存储层包括了数据仓库的存储设施,通常包括数据湖、数据仓库和元数据存储等。数据处理层包括了数据的清洗、转换、集成等数据处理操作。数据展现层则是用户最终进行数据分析和报表展现的地方。
### 2.2 数据仓库的分层架构
数据仓库的分层架构通常分为底层数据存储层、中间数据处理层和顶层数据展现层。底层数据存储层主要负责数据的存储和管理,中间数据处理层主要包括了数据的清洗、转换、抽取等操作,顶层数据展现层则是用户进行数据分析和可视化的地方。
在实际应用中,为了提高系统的性能和灵活性,有时会在数据处理层之间增加一层数据仓库服务器层,用来协调和管理数据处理操作。
### 2.3 数据仓库的主要组成部分
数据仓库的主要组成部分包括了数据存储设施、元数据管理、数据抽取与加载工具、数据处理引擎、数据查询与分析工具等。这些组成部分共同构成了一个完整的数据仓库系统,每个组成部分都发挥着重要的作用,保证了数据仓库系统的正常运行和高效使用。
在接下来的章节中,我们将会对数据仓库的设计原则、基本原理、应用以及未来发展趋势进行更加深入的探讨。
### 第三章:数据仓库设计原则
数据仓库设计是构建一个高效、易用的数据仓库系统的关键步骤。在这一章节中,我们将介绍数据仓库设计的基本原则和方法。
#### 3.1 星型模式与雪花模式
在数据仓库设计中,常用的数据模型包括星型模式和雪花模式。星型模式将数据仓库中的事实表和维度表组织成星型结构,而雪花模式则在此基础上进一步规范化维度表,使其形成多个维度表和子维度表的结构。下面是一个简单的星型模式的SQL示例:
```sql
-- 创建事实表
CREATE TABLE fact_sales (
product_id INT,
date_id INT,
amount DECIMAL
);
-- 创建维度表
CREATE TABLE dim_product (
product_id INT,
product_name VARCHAR,
category_id INT
);
CREATE TABLE dim_date (
date_id INT,
date DATE,
month INT,
year INT
);
```
#### 3.2 维度建模与事实表
在数据仓库设计中,维度建模是一种重要的设计方法。维度建模是以业务过程和业务需求为基础,通过对实体、维度、度量等概念的建模,建立起描述业务过程的模型,从而构建数据仓库中的维度表和事实表。以下是一个简单的维度建模的Python示例:
```python
# 创建维度表
class DimCustomer:
def __init__(self, customer_id, customer_name, address):
self.customer_id = customer_id
self.customer_name = customer_name
self.address = address
# 创建事实表
class FactSales:
def __init__(self, product_id, date_id, customer_id, amount):
self.product_id = product_id
self.date_id = date_id
self.customer_id = customer_id
self.amount = amount
```
#### 3.3 数据抽取、转换和加载(ETL)流程
数据仓库设计中,ETL流程是非常重要的一环。ETL包括数据抽取(Extract)、数据转换(Transform)和数据加载(Load)三个过程,通过这一过程可以将来自不同数据源的数据导入数据仓库,经过清洗、转换和整合后存储到目标数据库中。下面是一个简单的数据仓库ETL流程的Java示例:
```java
// 数据抽取
public class ExtractData {
public void extractFromMultipleSources() {
// 从多个数据源中抽取数据
}
}
// 数据转换
public class TransformData {
public void transformAndIntegrate() {
// 对数据进行转换和整合
}
}
// 数据加载
public class LoadData {
public void loadIntoWarehouse() {
// 将数据加载到数据仓库中
}
}
```
通过上述示例,我们对数据仓库设计原则中的星型模式与雪花模式、维度建模与事实表、以及ETL流程进行了简要介绍。这些原则和流程是构建高效数据仓库系统的重要基础,可以帮助企业更好地组织和管理数据。
### 4. 第四章:数据仓库的基本原理
数据仓库的基本原理包括数据存储方式、元数据管理与数据字典、数据仓库的数据查询与分析。以下将分别介绍这三个方面的内容。
#### 4.1 数据仓库的数据存储方式
数据仓库的数据存储方式通常采用多维模型,包括星型模型和雪花模型。其中,星型模型以中心的事实表与周围的维度表组成星型结构,而雪花模型在星型模型的基础上,维度表再进行规范化拆分,形成更多层级的结构。这种多维模型的存储方式有利于快速查询和多维分析。
```python
# 代码示例:创建星型模型的数据表
CREATE TABLE fact_sales (
sales_id INT PRIMARY KEY,
date_id INT,
product_id INT,
customer_id INT,
sales_amount DECIMAL
);
CREATE TABLE dim_date (
date_id INT PRIMARY KEY,
date DATE,
year INT,
month INT,
day INT
);
CREATE TABLE dim_product (
product_id INT PRIMARY KEY,
product_name VARCHAR(100),
category VARCHAR(50)
);
CREATE TABLE dim_customer (
customer_id INT PRIMARY KEY,
customer_name VARCHAR(100),
city VARCHAR(50)
);
```
**代码总结:** 上述代码示例中,展示了使用SQL语句创建了一个星型模型的数据表,包括事实表fact_sales和维度表dim_date、dim_product和dim_customer。
**结果说明:** 通过该数据表结构,可以实现对销售数据进行多维分析,便于从不同维度进行查询与分析。
#### 4.2 元数据管理与数据字典
元数据是描述数据的数据,对于数据仓库来说,元数据起着至关重要的作用。数据仓库中的元数据包括了数据表的定义、数据来源、数据质量等信息,而数据字典则是元数据的集合,用于描述数据的属性、含义和关系。通过良好的元数据管理与数据字典,可以提高数据的可理解性与可维护性。
```java
// 代码示例:定义数据字典的数据结构
public class DataDictionary {
private String tableName;
private List<DataAttribute> attributes;
// 省略其他代码
}
public class DataAttribute {
private String attributeName;
private String attributeType;
private String description;
// 省略其他代码
}
```
**代码总结:** 上述代码展示了使用Java语言定义了数据字典的数据结构,包括表名tableName和属性列表attributes,每个属性包括属性名attributeName、属性类型attributeType和描述信息description。
**结果说明:** 通过使用数据字典,可以清晰地了解数据表的属性及其含义,有助于数据的理解与使用。
#### 4.3 数据仓库的数据查询与分析
数据仓库的最终目的是为了支持数据的查询与分析,通常采用OLAP(联机分析处理)工具进行多维分析。OLAP工具可以实现数据的切片、切块、钻取和旋转等操作,为决策支持与业务分析提供强大的功能。
```javascript
// 代码示例:使用JavaScript实现数据仓库的多维分析
function slice(data, dimension, value) {
// 根据维度值进行数据切片操作
}
function dice(data, dimension1, value1, dimension2, value2) {
// 根据两个维度值进行数据切块操作
}
function drillDown(data, dimension) {
// 钻取操作,展开到更细粒度的数据
}
function pivot(data, rows, columns, measures) {
// 旋转操作,改变数据的展示方式
}
```
**代码总结:** 上述代码使用JavaScript定义了进行数据切片、切块、钻取和旋转的操作函数,实现多维分析的功能。
**结果说明:** 通过使用多维分析工具,可以方便地对数据进行多维度的查询与分析,帮助企业进行决策和业务优化。
通过以上章节内容的介绍,读者可以更加全面地了解数据仓库的基本原理,包括数据存储方式、元数据管理与数据字典以及数据查询与分析的相关知识。
## 第五章:数据仓库的应用
数据仓库不仅是用于数据存储和分析的平台,还广泛应用于各种领域,包括商业智能、决策支持系统和数据挖掘。在这一章节中,我们将深入探讨数据仓库在不同应用场景下的具体应用。
### 5.1 商业智能与数据分析
数据仓库作为商业智能(BI)系统的基础架构,为企业决策者提供了准确、一致、可靠的数据。通过数据仓库,企业可以进行多维度的数据分析,发现业务中的潜在趋势和模式,从而做出更加明智的决策。商业智能工具常与数据仓库集成,通过直观的可视化方式展示数据分析结果,帮助用户更好地理解数据并快速作出决策。
```python
# 示例代码: 使用Python的pandas库进行数据分析
import pandas as pd
# 从数据仓库中读取数据
data = pd.read_sql("SELECT * FROM sales_data", conn)
# 进行销售数据分析
total_sales = data['sales_amount'].sum()
average_sales = data['sales_amount'].mean()
print("总销售额:", total_sales)
print("平均销售额:", average_sales)
```
**代码总结:** 示例代码通过Python的pandas库连接数据仓库,读取销售数据并进行简单的数据分析,计算总销售额和平均销售额。
**结果说明:** 通过数据仓库进行的数据分析,得出了销售数据的总额和平均值,为企业决策提供了有力支持。
### 5.2 决策支持系统与数据挖掘
数据仓库在决策支持系统(DSS)中扮演着重要的角色,通过对多维数据的分析和挖掘,帮助企业高层管理者做出战略性的决策。同时,数据仓库也为数据挖掘提供了丰富的数据源,包括关联分析、聚类、分类等数据挖掘算法的应用。
```java
// 示例代码: 使用Java的Weka库进行数据挖掘
import weka.associations.Apriori;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
// 从数据仓库中获取数据并转换为Weka格式
DataSource source = new DataSource("jdbc:mysql://localhost:3306/mydatabase");
Instances data = source.getDataSet();
// 使用Apriori算法进行关联分析
Apriori model = new Apriori();
model.buildAssociations(data);
System.out.println(model);
```
**代码总结:** 示例代码使用Java的Weka库连接数据仓库,获取数据并利用Apriori算法进行关联分析。
**结果说明:** 通过数据仓库进行的数据挖掘,得出了数据之间的关联规则,为决策支持系统提供了宝贵的信息。
### 5.3 数据仓库在企业中的应用案例
许多企业已经成功应用数据仓库来改善业务流程、提高运营效率和优化决策过程。例如,零售行业利用数据仓库分析销售数据和顾客行为,制定更科学的促销策略;金融机构通过数据仓库进行风险管理和客户关系分析,提升服务质量和客户满意度。
总之,数据仓库在各个行业都有着广泛的应用,为企业提供了丰富的数据支持,帮助他们更好地理解业务并做出明智的决策。
通过本章的介绍,我们深入了解了数据仓库在商业智能、决策支持系统和数据挖掘领域中的具体应用,希望读者能够有更清晰的认识和理解。
### 6. 第六章:数据仓库的发展趋势
数据仓库作为信息化领域的重要组成部分,随着信息技术的不断发展和应用,也在不断演进和完善。在当前和未来的发展中,数据仓库面临着一些新的趋势和挑战,我们将在本章中对数据仓库的发展趋势进行探讨。
#### 6.1 云数据仓库与大数据存储
随着云计算和大数据技术的快速发展,云数据仓库和大数据存储成为了数据仓库领域的热门话题。传统的数据仓库往往面临存储和计算能力的限制,而云数据仓库和大数据存储可以借助云平台和分布式计算技术,实现海量数据的存储和处理,为用户提供更加灵活、可扩展的数据存储解决方案。
```python
# 示例代码:使用云数据仓库服务Amazon Redshift进行数据存储和查询
import boto3
# 连接到Amazon Redshift
client = boto3.client('redshift', region_name='us-west-2', aws_access_key_id='YOUR_ACCESS_KEY', aws_secret_access_key='YOUR_SECRET_KEY')
# 创建查询
response = client.execute_statement(
ClusterIdentifier='mycluster',
Database='mydatabase',
SecretArn='arn:aws:secretsmanager:us-west-2:123456789012:secret:mycluster/myuser-1aA2bB',
Sql="SELECT * FROM mytable;"
)
# 获取查询结果
results = client.get_statement_result(Id=response['Id'])
print(results)
```
通过使用云数据仓库和大数据存储,企业可以更好地应对日益增长的数据量和复杂的数据分析需求,提升数据处理和分析效率。
#### 6.2 数据仓库自动化与智能化发展
随着人工智能和自动化技术的发展,数据仓库的建设和运维也将迎来更多智能化的解决方案。自动化数据治理、智能化的数据质量管理、基于AI的数据分析等技术将逐渐应用到数据仓库领域,帮助企业更好地管理和分析数据,提升数据利用价值,降低运维成本。
```java
// 示例代码:使用智能化数据分析工具进行数据仓库分析
import com.ibm.cognos.analytics.*;
import com.ibm.cognos.studio.*;
// 连接到智能化数据分析工具
AnalyticsConnection connection = new AnalyticsConnection("https://my-analytics-tool.com", "my_username", "my_password");
connection.connect();
// 执行智能化数据分析
AnalysisResult result = connection.executeAnalysis("SELECT * FROM my_cube");
System.out.println(result);
```
数据仓库的自动化与智能化发展将使得数据处理和分析更加高效、智能化,为企业决策和业务发展提供更强有力的支持。
#### 6.3 未来数据仓库的发展方向与挑战
在未来的发展中,数据仓库可能面临着更多新技术和新挑战。从传统数据仓库走向大数据、机器学习、边缘计算等领域,数据仓库需要不断调整和升级自身的架构和技术,以适应未来信息化的发展趋势。
同时,数据安全、隐私保护、数据治理等方面也是未来数据仓库发展的重要挑战,需要数据仓库领域的专业人士不断探索和创新,以确保数据的安全可靠和合规性。
综上所述,数据仓库的未来发展充满了机遇和挑战,我们期待数据仓库能够不断演进,更好地为企业的信息化建设和业务发展提供支持。
以上是关于数据仓库的发展趋势的详细内容,希望能够为您带来一定的启发和帮助。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《数据仓库》专栏是一个全面介绍数据仓库的专业知识和实践经验的专栏。从数据仓库的概述与基本原理开始,逐步讲解数据仓库的架构与组成要素、设计与规划策略、ETL过程与工具介绍、数据清洗与质量控制等方面的内容。接着,深入探讨维度建模与数据仓库表设计、星型模式与雪花模式的应用,以及OLAP在数据仓库中的作用与应用。同时,还介绍数据仓库索引与性能优化策略、容灾与备份策略、与数据湖的对比与应用场景等内容。此外,还探讨了大数据技术在数据仓库中的应用、与数据挖掘的结合、数据可视化与报表设计、数据质量管理、实时数据处理技术、信息安全与权限管理、自动化测试与监控策略,以及机器学习与预测分析等领域。通过这些丰富多样的文章,读者可以深入了解数据仓库的各个方面,并将其应用于实际工作中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
扇形菜单高级应用

# 摘要
扇形菜单作为一种创新的用户界面设计方式,近年来在多个应用领域中显示出其独特优势。本文概述了扇形菜单设计的基本概念和理论基础,深入探讨了其用户交互设计原则和布局算法,并介绍了其在移动端、Web应用和数据可视化中的应用案例
C++ Builder高级特性揭秘:探索模板、STL与泛型编程

# 摘要
本文系统性地介绍了C++ Builder的开发环境设置、模板编程、标准模板库(STL)以及泛型编程的实践与技巧。首先,文章提供了C++ Builder的简介和开发环境的配置指导。接着,深入探讨了C++模板编程的基础知识和高级特性,包括模板的特化、非类型模板参数以及模板
【深入PID调节器】:掌握自动控制原理,实现系统性能最大化

# 摘要
PID调节器是一种广泛应用于工业控制系统中的反馈控制器,它通过比例(P)、积分(I)和微分(D)三种控制作用的组合来调节系统的输出,以实现对被控对象的精确控制。本文详细阐述了PID调节器的概念、组成以及工作原理,并深入探讨了PID参数调整的多种方法和技巧。通过应用实例分析,本文展示了PID调节器在工业过程控制中的实际应用,并讨
【Delphi进阶高手】:动态更新百分比进度条的5个最佳实践

# 摘要
本文针对动态更新进度条在软件开发中的应用进行了深入研究。首先,概述了进度条的基础知识,然后详细分析了在Delphi环境下进度条组件的实现原理、动态更新机制以及多线程同步技术。进一步,文章探讨了数据处理、用户界面响应性优化和状态视觉呈现的实践技巧,并提出了进度
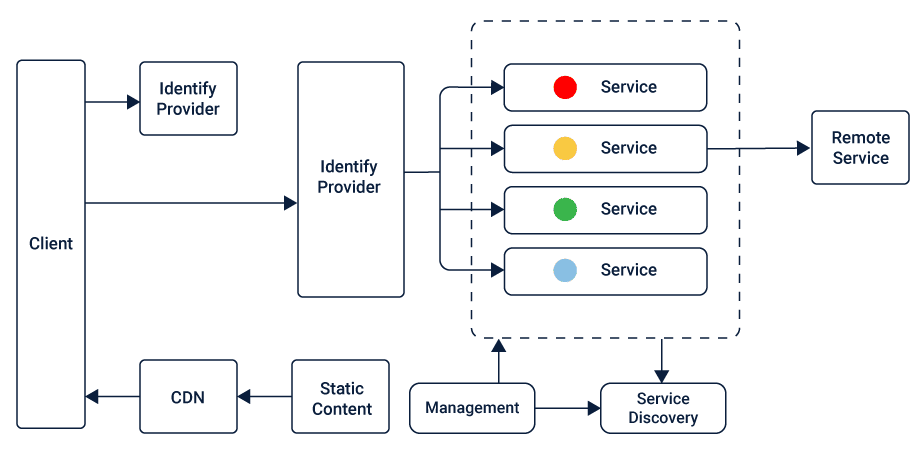
【TongWeb7架构深度剖析】:架构原理与组件功能全面详解
# 摘要
TongWeb7作为一个复杂的网络应用服务器,其架构设计、核心组件解析、性能优化、安全性机制以及扩展性讨论是本文的主要内容。本文首先对TongWeb7的架构进行了概述,然后详细分析了其核心中间件组件的功能与特点,接着探讨了如何优化性能监控与分析、负载均衡、缓存策略等方面,以及安全性机制中的认证授权、数据加密和安全策略实施。最后,本文展望
【S参数秘籍解锁】:掌握驻波比与S参数的终极关系
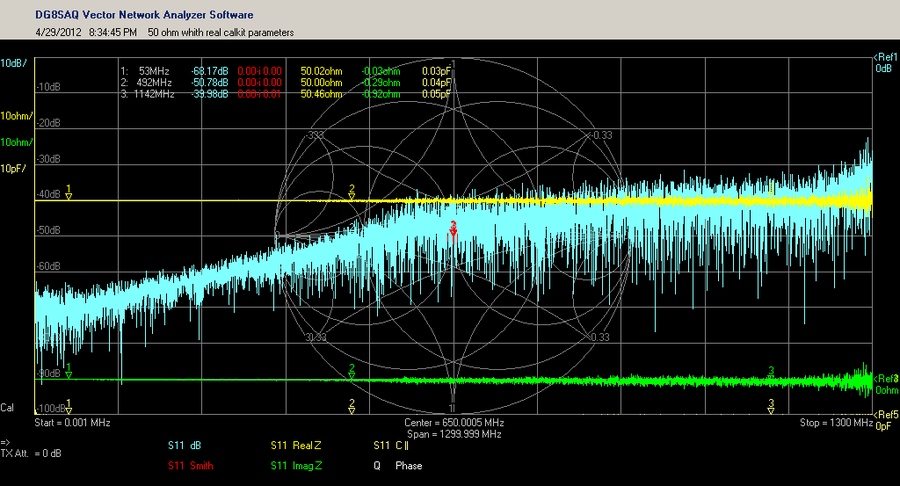
# 摘要
本论文详细阐述了驻波比与S参数的基础理论及其在微波网络中的应用,深入解析了S参数的物理意义、特性、计算方法以及在电路设计中的实践应用。通过分析S参数矩阵的构建原理、测量技术及仿真验证,探讨了S参数在放大器、滤波器设计及阻抗匹配中的重要性。同时,本文还介绍了驻波比的测量、优化策略及其与S参数的互动关系。最后,论文探讨了S参数分析工具的使用、高级分析技巧,并展望
【嵌入式系统功耗优化】:JESD209-5B的终极应用技巧
# 摘要
本文首先概述了嵌入式系统功耗优化的基本情况,随后深入解析了JESD209-5B标准,重点探讨了该标准的框架、核心规范、低功耗技术及实现细节。接着,本文奠定了功耗优化的理论基础,包括功耗的来源、分类、测量技术以及系统级功耗优化理论。进一步,本文通过实践案例深入分析了针对JESD209-5B标准的硬件和软件优化实践,以及不同应用场景下的功耗优化分析。最后,展望了未来嵌入式系统功耗优化的趋势,包括新兴技术的应用、JESD209-5B标准的发展以及绿色计算与可持续发展的结合,探讨了这些因素如何对未来的功耗优化技术产生影响。
# 关键字
嵌入式系统;功耗优化;JESD209-5B标准;低功耗
ODU flex接口的全面解析:如何在现代网络中最大化其潜力
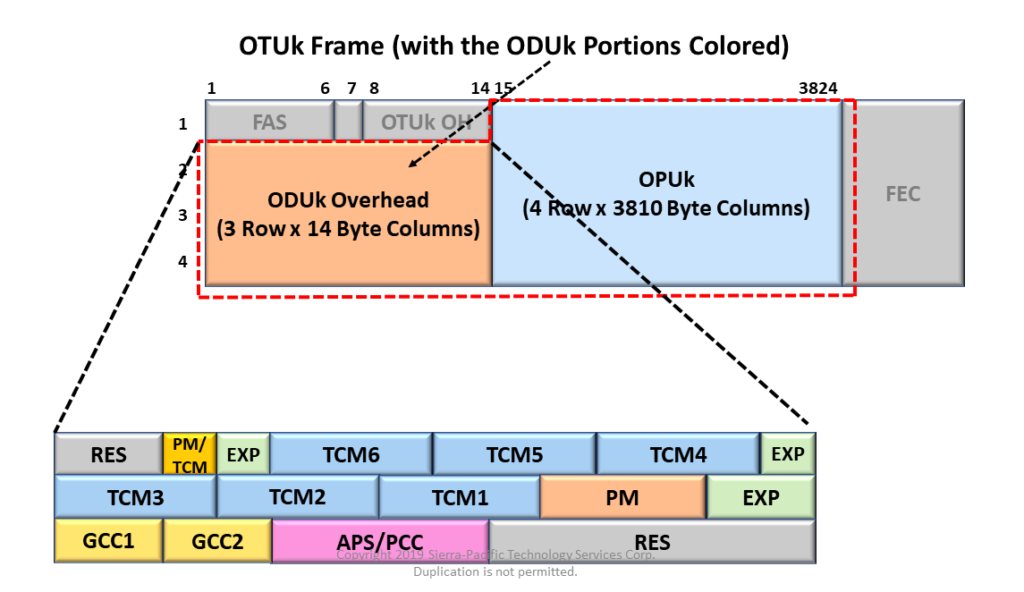
# 摘要
ODU flex接口作为一种高度灵活且可扩展的光传输技术,已经成为现代网络架构优化和电信网络升级的重要组成部分。本文首先概述了ODU flex接口的基本概念和物理层特征,紧接着深入分析了其协议栈和同步机制,揭示了其在数据中心、电信网络、广域网及光纤网络中的应用优势和性能特点。文章进一步
如何最大化先锋SC-LX59的潜力
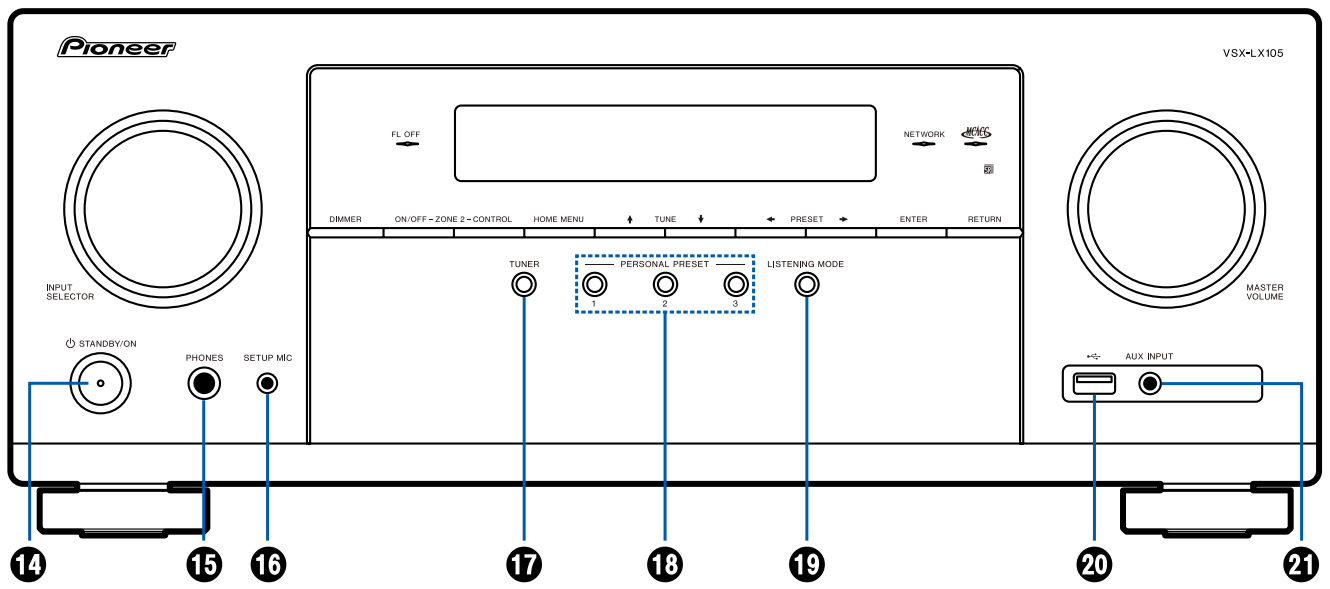
# 摘要
先锋SC-LX59作为一款高端家庭影院接收器,其在音视频性能、用户体验、网络功能和扩展性方面均展现出巨大的潜力。本文首先概述了SC-LX59的基本特点和市场潜力,随后深入探讨了其设置与配置的最佳实践,包括用户界面的个性化和音画效果的调整,连接选项与设备兼容性,以及系统性能的调校。第三章着重于先锋SC-LX59在家庭影院中的应用,特别强调了音视频极致体验、智能家居集成和流媒体服务的充分利用。在高
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )