大数据技术在数据仓库中的应用
发布时间: 2023-12-28 04:29:45 阅读量: 8 订阅数: 20 
# 章节一:介绍大数据技术及数据仓库
## 1.1 大数据技术的基本概念
在当今数字化信息时代,数据量呈指数级增长,传统的数据处理和管理方式已无法满足对海量数据的存储、处理和分析需求。大数据技术因此应运而生。大数据技术是一种针对海量、复杂数据的处理和分析技术,涵盖了数据存储、数据处理、数据管理、数据挖掘等多个方面,旨在通过高效的算法、强大的计算能力和分布式系统架构来应对大规模数据的挑战。
## 1.2 数据仓库的定义和作用
数据仓库是指将企业不同来源、不同格式、不同数据结构的数据集成到一起,建立统一的数据模型,满足用户的数据分析和决策支持需求的信息系统。数据仓库的作用主要包括:数据集成、历史数据存储、数据清洗、数据分析和数据挖掘等。
## 1.3 大数据技术与数据仓库的关系
大数据技术和数据仓库密不可分。大数据技术提供了存储、处理和分析海量数据的技术手段,而数据仓库则是基于这些技术实现了对企业数据的集成、存储和分析,为企业决策提供支持。
以上是对大数据技术及数据仓库的简要介绍,接下来将深入探讨大数据技术在数据仓库中的应用及其影响。
### 章节二:大数据技术在数据仓库架构中的应用
大数据技术在数据仓库架构中发挥着重要作用,它涵盖了数据存储、数据处理以及数据管理等方面的应用。接下来我们将详细介绍大数据技术在数据仓库架构中的具体应用。
#### 2.1 数据存储:Hadoop和HDFS
在数据仓库中,数据存储是至关重要的一环。Hadoop作为大数据存储和分析的核心工具之一,其分布式文件系统HDFS(Hadoop Distributed File System)能够提供高容量、高性能的数据存储服务。接下来,让我们以一个常见的数据仓库存储场景为例,演示Hadoop和HDFS的使用。
```java
// Java代码示例,使用Hadoop API进行数据存储操作
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class HadoopHDFSExample {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path filePath = new Path("/data/warehouse/example.txt");
if (!fs.exists(filePath)) {
fs.createNewFile(filePath);
System.out.println("文件创建成功!");
} else {
System.out.println("文件已存在!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
代码总结:
- 通过Hadoop API,我们可以轻松实现对HDFS的文件操作,包括文件创建、写入等。
- Hadoop的分布式特性使得数据仓库能够支持大规模数据的存储和管理。
结果说明:
- 上述代码可以在Hadoop集群环境中运行,实现对HDFS中的文件创建操作。
#### 2.2 数据处理:MapReduce、Spark等技术
数据处理是数据仓库中的核心环节,大数据技术为数据处理提供了多种选择,包括经典的MapReduce框架以及近年来备受瞩目的Spark等新兴技术。下面我们以使用Spark进行数据处理为例,演示大数据处理技术在数据仓库中的应用。
```python
# Python示例代码,使用Spark进行数据处理
from pyspark import SparkContext
sc = SparkContext("local", "DataWarehouseApp")
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
result = rdd.map(lambda x: x * 2).collect()
for num in result:
print(num)
```
代码总结:
- 使用Spark提供的RDD(弹性分布式数据集)对数据进行处理,实现了对数据的批量处理和计算。
结果说明:
- 以上代码使用了Spark的并行计算能力,将原始数据乘以2后进行输出。
#### 2.3 数据管理:Hive、HBase等工具
数据管理在数据仓库中同样至关重要,Hive和HBase等工具为数据管理提供了便利。下面我们以Hive为例,展示在数据仓库中使用Hive进行数据管理的示例代码。
```sql
-- Hive示例代码,创建数据仓库中的数据表
CREATE TABLE IF NOT EXISTS employee (
id INT,
name STRING,
age INT,
department STRING
) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
LOAD DATA LOCAL INPATH '/path/to/employee_data.csv' OVERWRITE INTO TABLE employee;
```
代码总结:
- 通过Hive的DDL语句,我们可以在数据
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 15个月+AI工具集
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《数据仓库》专栏是一个全面介绍数据仓库的专业知识和实践经验的专栏。从数据仓库的概述与基本原理开始,逐步讲解数据仓库的架构与组成要素、设计与规划策略、ETL过程与工具介绍、数据清洗与质量控制等方面的内容。接着,深入探讨维度建模与数据仓库表设计、星型模式与雪花模式的应用,以及OLAP在数据仓库中的作用与应用。同时,还介绍数据仓库索引与性能优化策略、容灾与备份策略、与数据湖的对比与应用场景等内容。此外,还探讨了大数据技术在数据仓库中的应用、与数据挖掘的结合、数据可视化与报表设计、数据质量管理、实时数据处理技术、信息安全与权限管理、自动化测试与监控策略,以及机器学习与预测分析等领域。通过这些丰富多样的文章,读者可以深入了解数据仓库的各个方面,并将其应用于实际工作中。
专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB圆形Airy光束前沿技术探索:解锁光学与图像处理的未来

# 2.1 Airy函数及其性质
Airy函数是一个特殊函数,由英国天文学家乔治·比德尔·艾里(George Biddell Airy)于1838年首次提出。它在物理学和数学中
卡尔曼滤波MATLAB代码在预测建模中的应用:提高预测准确性,把握未来趋势
# 1. 卡尔曼滤波简介**
卡尔曼滤波是一种递归算法,用于估计动态系统的状态,即使存在测量噪声和过程噪声。它由鲁道夫·卡尔曼于1960年提出,自此成为导航、控制和预测等领域广泛应用的一种强大工具。
卡尔曼滤波的基本原理是使用两个方程组:预测方程和更新方程。预测方程预测系统状态在下一个时间步长的值,而更新方程使用测量值来更新预测值。通过迭代应用这两个方程,卡尔曼滤波器可以提供系统状态的连续估计,即使在存在噪声的情况下也是如此。
# 2. 卡尔曼滤波MATLAB代码
### 2.1 代码结构和算法流程
卡尔曼滤波MATLAB代码通常遵循以下结构:
```mermaid
graph L
爬虫与云计算:弹性爬取,应对海量数据

# 1. 爬虫技术概述**
爬虫,又称网络蜘蛛,是一种自动化程序,用于从网络上抓取和提取数据。其工作原理是模拟浏览器行为,通过HTTP请求获取网页内容,并
【未来人脸识别技术发展趋势及前景展望】: 展望未来人脸识别技术的发展趋势和前景
# 1. 人脸识别技术的历史背景
人脸识别技术作为一种生物特征识别技术,在过去几十年取得了长足的进步。早期的人脸识别技术主要基于几何学模型和传统的图像处理技术,其识别准确率有限,易受到光照、姿态等因素的影响。随着计算机视觉和深度学习技术的发展,人脸识别技术迎来了快速的发展时期。从简单的人脸检测到复杂的人脸特征提取和匹配,人脸识别技术在安防、金融、医疗等领域得到了广泛应用。未来,随着人工智能和生物识别技术的结合,人脸识别技术将呈现更广阔的发展前景。
# 2. 人脸识别技术基本原理
人脸识别技术作为一种生物特征识别技术,基于人脸的独特特征进行身份验证和识别。在本章中,我们将深入探讨人脸识别技
:YOLO目标检测算法的挑战与机遇:数据质量、计算资源与算法优化,探索未来发展方向
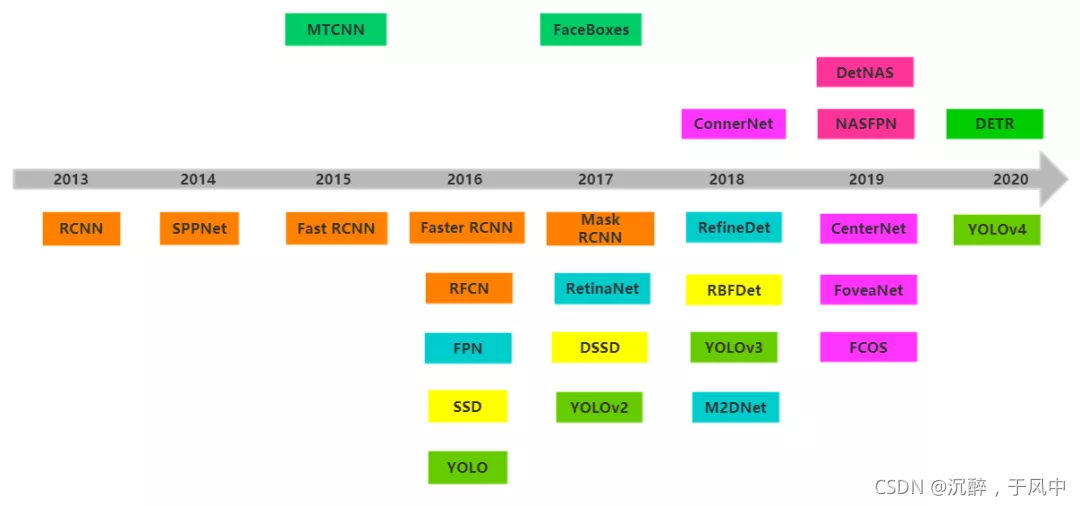
# 1. YOLO目标检测算法简介
YOLO(You Only Look Once)是一种
MATLAB稀疏阵列在自动驾驶中的应用:提升感知和决策能力,打造自动驾驶新未来
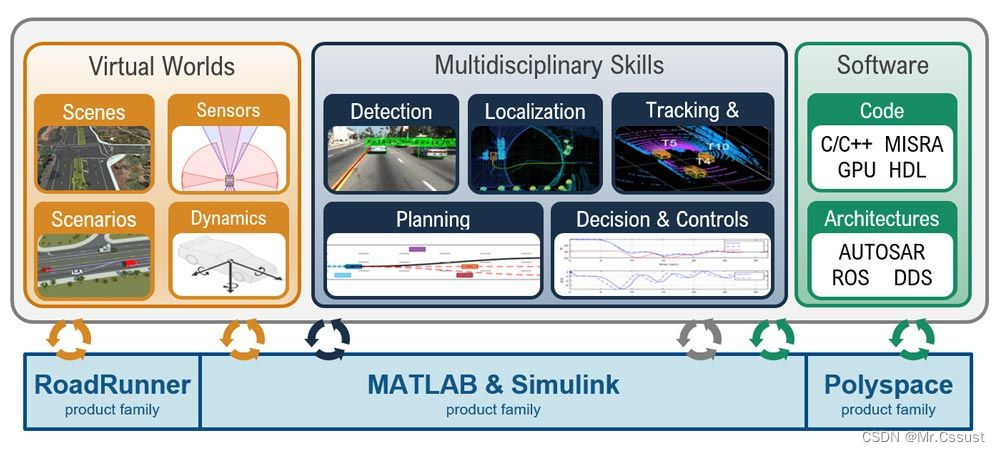
# 1. MATLAB稀疏阵列基础**
MATLAB稀疏阵列是一种专门用于存储和处理稀疏数据的特殊数据结构。稀疏数据是指其中大部分元素为零的矩阵。MATLAB稀疏阵列通过只存储非零元素及其索引来优化存储空间,从而提高计算效率。
MATLAB稀疏阵列的创建和操作涉及以下关键概念:
* **稀疏矩阵格式:**MATLAB支持多种稀疏矩阵格式,包括CSR(压缩行存
【未来发展趋势下的车牌识别技术展望和发展方向】: 展望未来发展趋势下的车牌识别技术和发展方向

# 1. 车牌识别技术简介
车牌识别技术是一种通过计算机视觉和深度学习技术,实现对车牌字符信息的自动识别的技术。随着人工智能技术的飞速发展,车牌识别技术在智能交通、安防监控、物流管理等领域得到了广泛应用。通过车牌识别技术,可以实现车辆识别、违章监测、智能停车管理等功能,极大地提升了城市管理和交通运输效率。本章将从基本原理、相关算法和技术应用等方面介绍
【人工智能与扩散模型的融合发展趋势】: 探讨人工智能与扩散模型的融合发展趋势

# 1. 人工智能与扩散模型简介
人工智能(Artificial Intelligence,AI)是一种模拟人类智能思维过程的技术,其应用已经深入到各行各业。扩散模型则是一种描述信息、疾病或技术在人群中传播的数学模型。人工智能与扩散模型的融合,为预测疾病传播、社交媒体行为等提供了新的视角和方法。通过人工智能的技术,可以更加准确地预测扩散模型的发展趋势,为各
【YOLO目标检测中的未来趋势与技术挑战展望】: 展望YOLO目标检测中的未来趋势和技术挑战
# 1. YOLO目标检测简介
目标检测作为计算机视觉领域的重要任务之一,旨在从图像或视频中定位和识别出感兴趣的目标。YOLO(You Only Look Once)作为一种高效的目标检测算法,以其快速且准确的检测能力而闻名。相较于传统的目标检测算法,YOLO将目标检测任务看作一个回归问题,通过将图像划分为网格单元进行预测,实现了实时目标检测的突破。其独特的设计思想和算法架构为目标检测领域带来了革命性的变革,极大地提升了检测的效率和准确性。
在本章中,我们将深入探讨YOLO目标检测算法的原理和工作流程,以及其在目标检测领域的重要意义。通过对YOLO算法的核心思想和特点进行解读,读者将能够全
【高级数据可视化技巧】: 动态图表与报告生成
# 1. 认识高级数据可视化技巧
在当今信息爆炸的时代,数据可视化已经成为了信息传达和决策分析的重要工具。学习高级数据可视化技巧,不仅可以让我们的数据更具表现力和吸引力,还可以提升我们在工作中的效率和成果。通过本章的学习,我们将深入了解数据可视化的概念、工作流程以及实际应用场景,从而为我们的数据分析工作提供更多可能性。
在高级数据可视化技巧的学习过程中,首先要明确数据可视化的目标以及选择合适的技巧来实现这些目标。无论是制作动态图表、定制报告生成工具还是实现实时监控,都需要根据需求和场景灵活运用各种技巧和工具。只有深入了解数据可视化的目标和调用技巧,才能在实践中更好地应用这些技术,为数据带来
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
15个月+AI工具集
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )