使用iptables限制访问
发布时间: 2024-02-26 23:30:25 阅读量: 39 订阅数: 31 

使用iptables限制流量请求
# 1. 简介
## 1.1 什么是iptables?
在Linux操作系统中,iptables是一个用来配置和管理防火墙规则的工具。它可以帮助用户限制网络数据包的传输,从而提高网络安全性。
## 1.2 为什么需要限制访问?
限制网络访问可以帮助防止恶意攻击、数据泄露以及网络拥塞。通过使用iptables,用户可以根据需求灵活地设置规则,控制网络数据包的流动。
## 1.3 iptables的基本工作原理
iptables基于一系列规则(rules)来过滤网络数据包。当数据包到达主机时,iptables将根据预先设置的规则来决定如何处理这些数据包,可以允许或者拒绝它们的传输。iptables提供了丰富的功能,包括限制特定IP地址的访问、阻止特定端口的通信等。
# 2. 设置iptables
在开始使用iptables之前,你需要确保已经安装了这个工具,并且了解一些基本的命令和默认策略的配置。让我们逐步来了解。
#### 2.1 安装iptables
首先,你需要在你的系统上安装iptables。大多数Linux发行版默认都会包含iptables,但如果你的系统没有安装,你可以使用以下命令来安装:
```bash
# 在Debian/Ubuntu上安装iptables
sudo apt-get update
sudo apt-get install iptables
# 在CentOS上安装iptables
sudo yum install iptables
```
#### 2.2 基本的iptables命令
一旦安装完成,你就可以开始使用iptables来配置你的防火墙了。以下是一些基本的iptables命令:
- `iptables -L`:显示当前iptables规则
- `iptables -F`:清除所有规则
- `iptables -A`:添加一条新规则
- `iptables -D`:删除一条规则
#### 2.3 配置iptables默认策略
iptables默认有三种链:INPUT(入站)、FORWARD(转发)、OUTPUT(出站)。你可以使用以下命令来配置默认策略:
```bash
# 设置默认策略为拒绝所有输入流量
iptables -P INPUT DROP
# 设置默认策略为允许所有输出流量
iptables -P OUTPUT ACCEPT
# 设置默认策略为拒绝所有转发流量
iptables -P FORWARD DROP
```
通过上述命令,你可以将默认策略设置为拒绝所有输入流量,允许所有输出流量,并拒绝所有转发流量。随后,你可以根据需要添加具体的规则来进一步限制访问。
在下一章节中,我们将讨论如何设置iptables来限制入站访问。
# 3. 限制入站访问
在网络安全中,限制入站访问是至关重要的。通过设置适当的入站规则,可以有效地控制哪些流量被允许进入系统,从而提高系统的安全性。本章将介绍如何使用iptables来限制入站访问,并讨论如何限制特定IP地址的访问以及如何记录和分析防火墙日志。
#### 3.1 设置入站规则
要设置入站规则,首先需要了解系统当前的iptables配置。可以使用以下命令查看当前的iptables规则:
```bash
sudo iptables -L
```
接下来,可以使用iptables命令添加入站规则。例如,要允许SSH流量进入系统,可以使用以下命令:
```bash
sudo iptables -A INPUT -p tcp --dport 22 -j ACCEPT
```
#### 3.2 限制特定IP地址的访问
有时候,需要限制特定IP地址的访问。这可以通过iptables的源IP地址过滤功能来实现。例如,如果希望禁止特定IP地址(比如`192.168.1.100`)访问系统,可以使用以下命令:
```bash
sudo iptables -A INPUT -s 192.168.1.100 -j DROP
```
#### 3.3 防火墙日志记录与分析
除了设置规则以限制入站访问外,还可以通过配置防火墙日志来记录所有被阻止的流量,以便进一步分析和审查。可以使用以下命令启用防火墙日志记录:
```bash
sudo iptables -A INPUT -j LOG --log-prefix "iptables: "
```
日志记录将有助于发现潜在的攻击或异常流量,同时也有助于了解哪些规则生效以及流量是如何处理的。
通过本章的内容,可以了解到如何设置入站规则、限制特定IP地址的访问以及配置防火墙日志记录与分析,从而提高系统的安全性和网络访问的可控性。
# 4. 限制出站访问
在网络安全中,不仅要控制进入系统的流量,还需要限制系统向外发送的流量。使用iptables可以有效地设置出站访问规则,以确保系统在网络通信中符合安全要求。下面将介绍如何使用iptables来限制出站访问。
### 4.1 设置出站规则
要设置出站规则,可以使用iptables的OUTPUT链。通过在OUTPUT链上添加适当的规则,可以限制哪些数据包可以从系统发出。以下是一个示例,阻止系统向特定IP地址发送数据包的规则:
```bash
# 允许所有出站流量
iptables -P OUTPUT ACCEPT
# 阻止系统向特定IP地址(示例为192.168.1.100)发送数据包
iptables -A OUTPUT -d 192.168.1.100 -j DROP
```
上面的代码片段中,首先将OUTPUT链的默认策略设置为接受所有出站流量,然后添加了一条规则,如果数据包的目的地是192.168.1.100,则将其丢弃。
### 4.2 阻止特定端口的访问
除了限制特定IP地址外,还可以根据端口号来限制出站访问。以下是一个示例,阻止系统向外部服务器的80端口(HTTP)发送数据包的规则:
```bash
# 阻止系统向外部服务器的80端口发送数据包
iptables -A OUTPUT -p tcp --dport 80 -j DROP
```
上述规则将阻止系统通过80端口与外部服务器进行HTTP通信。
### 4.3 阻止特定协议的访问
在某些情况下,可能需要阻止系统使用特定的协议进行出站通信。以下是一个示例,阻止系统使用ICMP协议向外部节点发送数据包的规则:
```bash
# 阻止系统使用ICMP协议向外部节点发送数据包
iptables -A OUTPUT -p icmp -j DROP
```
通过上述规则,可以有效地限制系统对外部节点的ICMP通信。
通过设置出站规则,可以更好地控制系统与外部世界的通信,从而提高系统的安全性和稳定性。确保根据实际需求设置适当的出站规则,以符合安全最佳实践。
# 5. 高级iptables用法
在使用iptables时,除了基本的阻止和允许特定IP地址或端口的访问之外,还可以通过一些高级用法来更加灵活地控制网络访问。下面将介绍一些高级iptables用法,帮助你更好地保护网络安全。
#### 5.1 使用连接跟踪来限制访问
在iptables中,可以使用连接跟踪机制来跟踪网络连接的状态,从而实现更精细的访问控制。通过连接跟踪,可以根据连接的状态(如NEW,ESTABLISHED,RELATED,INVALID)来设置规则。
```python
# 允许已建立的连接通过
iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
# 阻止无效的连接
iptables -A INPUT -m conntrack --ctstate INVALID -j DROP
```
**代码总结:** 上述规则通过连接状态来判断是否允许通过防火墙,有效防止了一些通常情况下难以察觉的攻击。
**结果说明:** 通过连接跟踪机制,可以有效地防范一些连接状态异常或非法的网络访问,提高网络的安全性。
#### 5.2 设置时间限制的访问规则
有时候我们需要根据时间段来限制特定的访问,比如只允许在白天访问某个服务。iptables也提供了设置时间限制的访问规则的功能。
```python
# 只允许工作日的访问
iptables -A INPUT -m time --weekdays Mon,Tue,Wed,Thu,Fri -j ACCEPT
# 限制访问时间段为9:00 - 17:00
iptables -A INPUT -m time --timestart 09:00 --timestop 17:00 -j ACCEPT
```
**代码总结:** 通过设置时间限制的访问规则,可以更加精细地控制网络访问的时间范围,增加网络访问的安全性。
**结果说明:** 设置时间限制的访问规则可以有效地限制网络访问的时间段,保障网络在非工作时间段的安全。
#### 5.3 配置端口转发和网络地址转换(NAT)
除了基本的访问控制,iptables还支持端口转发和网络地址转换(NAT)功能,可以帮助实现内部网络和外部网络之间的通信。
```python
# 设置端口转发,将外部访问的80端口转发到内部服务器的8080端口
iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8080
# 设置网络地址转换,将内网IP地址转换为公网IP地址
iptables -t nat -A POSTROUTING -s 192.168.1.0/24 -o eth0 -j MASQUERADE
```
**代码总结:** 端口转发和网络地址转换可以帮助内部服务器与外部网络进行通信,提供更灵活的网络配置选项。
**结果说明:** 通过配置端口转发和网络地址转换,可以实现内网服务器与外部网络的通信,帮助实现更加灵活和安全的网络环境。
# 6. 最佳实践和注意事项
在使用iptables时,遵循最佳实践和注意事项是至关重要的。下面将介绍一些关键的内容:
#### 6.1 如何避免常见的iptables配置错误
避免常见的iptables配置错误对于网络安全至关重要。以下是一些建议:
- 在添加新规则之前,请确保你理解规则的含义和影响。
- 注意规则的顺序,iptables按顺序逐条匹配规则,确保更具体的规则在更一般的规则之前。
- 使用适当的规则格式,例如正确指定IP地址、端口和协议。
- 定期审查已有规则,及时清理不再需要的规则。
#### 6.2 定期审查和更新iptables规则
定期审查和更新iptables规则是确保网络安全的重要步骤。建议:
- 定期检查规则是否仍然适用于当前网络环境。
- 更新规则以反映最新的安全威胁和网络需求。
- 确保规则文档完整,并为每个规则添加适当的注释以便日后维护。
#### 6.3 保护iptables规则免受恶意攻击
保护iptables规则免受恶意攻击至关重要,以下是一些建议:
- 使用强密码保护iptables配置文件。
- 限制对iptables配置文件的访问权限。
- 定期监控日志以检测潜在的恶意行为。
- 考虑定期备份iptables规则以防止意外丢失。
遵循这些最佳实践和注意事项,可以帮助你更好地管理和维护iptables规则,确保系统网络安全。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏将深入探讨配置iptables防火墙如何增强服务器安全,并结合Selinux进行全面防护。通过Linux运维实践与Selinux概述,帮助读者深入理解iptables-snat-dnat的原理与配置技巧,同时探讨Selinux的工作原理与策略管理。进一步介绍如何对firewalld进行深入配置,以及使用iptables限制访问的方法与技巧。此外,专栏还将详细讲解如何与Selinux结合使用iptables,以及如何开启Selinux强制模式来提升服务器的安全性。通过配置防火墙规则,读者将能够全面了解如何利用iptables和Selinux保护服务器,从而提升服务器的安全性与稳定性。
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Android应用中的MAX30100集成完全手册:一步步带你上手
# 摘要
本文综合介绍了MAX30100传感器的搭建和应用,涵盖了从基础硬件环境的搭建到高级应用和性能优化的全过程。首先概述了MAX30100的工作原理及其主要特性,然后详细阐述了如何集成到Arduino或Raspberry Pi等开发板,并搭建相应的硬件环境。文章进一步介绍了软件环境的配置,包括Arduino IDE的安装、依赖库的集成和MAX30100库的使用。接着,通过编程实践展示了MAX30100的基本操作和高级功能的开发,包括心率和血氧饱和度测量以及与Android设备的数据传输。最后,文章探讨了MAX30100在Android应用中的界面设计、功能拓展和性能优化,并通过实际案例分析
【AI高手】:掌握这些技巧,A*算法解决8数码问题游刃有余
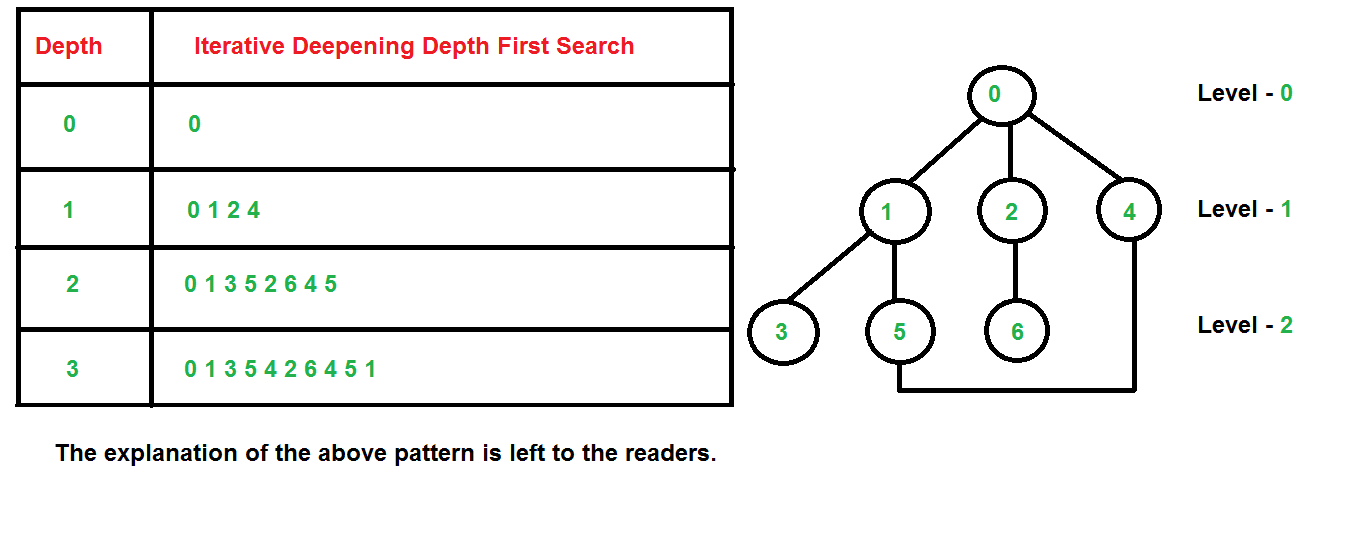
# 摘要
A*算法是计算机科学中广泛使用的一种启发式搜索算法,尤其在路径查找和问题求解领域表现出色。本文首先概述了A*算法的基本概念,随后深入探讨了其理论基础,包括搜索算法的分类和评价指标,启发式搜索的原理以及评估函数的设计。通过结合著名的8数码问题,文章详细介绍了A*算法的实际操作流程、编码前的准备、实现步骤以及优化策略。在应用实例部分,文章通过具体问题的实例化和算法的实现细节,提供了深入的案例分析和问题解决方法。最后,本文展望
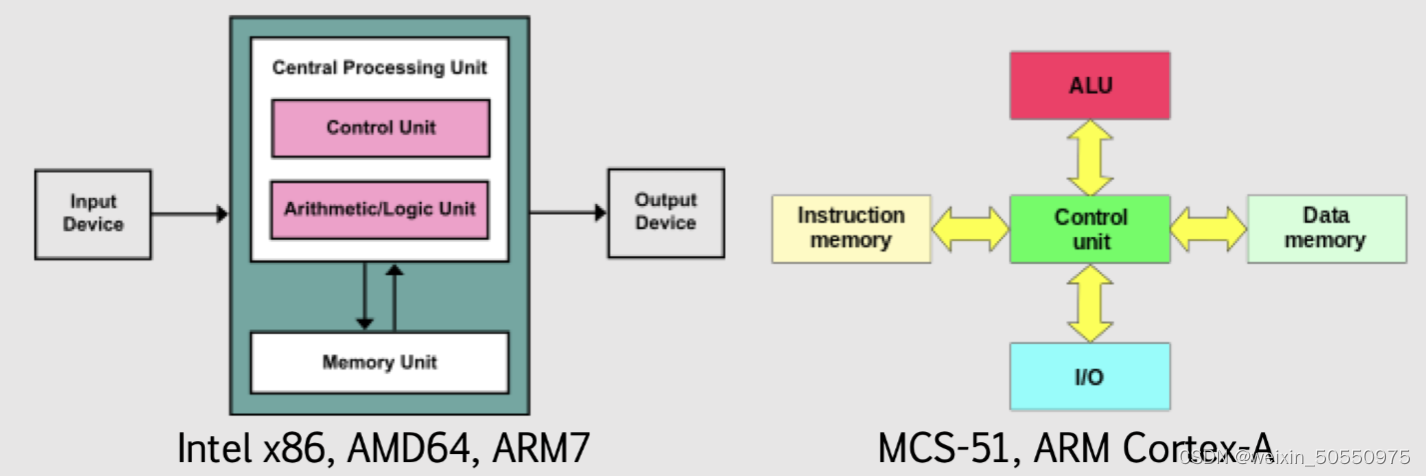
【硬件软件接口艺术】:掌握提升系统协同效率的关键策略
# 摘要
硬件与软件接口是现代计算系统的核心,它决定了系统各组件间的通信效率和协同工作能力。本文首先概述了硬件与软件接口的基本概念和通信机制,深入探讨了硬件通信接口标准的发展和主流技术的对比。接着,文章分析了软件接口的抽象层次,包括系统调用、API以及驱动程序的作用。此外,本文还详细介绍了同步与异步处理机制的原理和实践。在探讨提升系统协同效率的关键技术方面,文中阐述了缓存机制优化、多线程与并行处理,以及
PFC 5.0二次开发宝典:API接口使用与自定义扩展
# 摘要
本文深入探讨了PFC 5.0的技术细节、自定义扩展的指南以及二次开发的实践技巧。首先,概述了PFC 5.0的基础知识和标准API接口,接着详细分析了AP
【台达VFD-B变频器与PLC通信集成】:构建高效自动化系统的不二法门

# 摘要
本文综合介绍了台达VFD-B变频器与PLC通信的关键技术,涵盖了通信协议基础、变频器设置、PLC通信程序设计、实际应用调试以及高级功能集成等各个方面。通过深入探讨通信协议的基本理论,本文阐述了如何设置台达VFD-B变频器以实现与PLC的有效通信,并提出了多种调试技巧与参数优化策略,以解决实际应用中的常见问题。此外,本文
【ASM配置挑战全解析】:盈高经验分享与解决方案

# 摘要
自动存储管理(ASM)作为数据库管理员优化存储解决方案的核心技术,能够提供灵活性、扩展性和高可用性。本文深入介绍了ASM的架构、存储选项、配置要点、高级技术、实践操作以及自动化配置工具。通过探讨ASM的基础理论、常见配置问题、性能优化、故障排查以及与RAC环境的集成,本文旨在为数据库管理员提供全面的配置指导和操作建议。文章还分析了ASM在云环境中的应用前景、社区资源和
【自行车码表耐候性设计】:STM32硬件防护与环境适应性提升

# 摘要
本文详细探讨了自行车码表的设计原理、耐候性设计实践及软硬件防护机制。首先介绍自行车码表的基本工作原理和设计要求,随后深入分析STM32微控制器的硬件防护基础。接着,通过研究环境因素对自行车码表性能的影响,提出了相应的耐候性设计方案,并通过实验室测试和现场实验验证了设计的有效性。文章还着重讨论了软件防护机制,包括设计原则和实现方法,并探讨了软硬件协同防护
STM32的电源管理:打造高效节能系统设计秘籍
# 摘要
随着嵌入式系统在物联网和便携设备中的广泛应用,STM32微控制器的电源管理成为提高能效和延长电池寿命的关键技术。本文对STM32电源管理进行了全面的概述,从理论基础到实践技巧,再到高级应用的探讨。首先介绍了电源管理的基本需求和电源架构,接着深入分析了动态电压调节技术、电源模式和转换机制等管理策略,并探讨了低功耗模式的实现方法。进一步地,本文详细阐述了软件工具和编程技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )