利用Cookies与Session维持登录状态:Python爬虫技术详解
发布时间: 2024-03-20 19:22:42 阅读量: 43 订阅数: 27 
# 1. 介绍
在网络爬虫领域,维持登录状态对于获取需要登录权限的数据至关重要。而要想实现登录状态的维持,Cookies与Session就成为了不可或缺的利器。本章节将介绍Cookies与Session的概念以及为何在Python爬虫中维持登录状态如此重要。
# 2. Cookies与Session简介
在网络通信中,Cookies与Session是常用的两种机制,用于在客户端(浏览器)和服务器之间保持用户状态的工具。接下来我们将分别介绍Cookies与Session的概念以及它们在Python爬虫中的应用。让我们开始吧!
# 3. 使用Cookies维持登录状态
在Python爬虫中,维持登录状态是非常重要的,因为很多网站需要用户登录后才能访问特定的页面或获取数据。在本节中,我们将详细介绍如何使用Cookies来实现登录状态的维持。
#### 3.1 如何在Python中获取和设置Cookies
首先,我们需要了解如何获取网站设置的Cookies,并在爬虫中设置这些Cookies来实现登录状态的保持。一般来说,网站在用户登录成功后会返回一些身份验证的Cookies,我们需要将这些Cookies保存下来并在后续的请求中带上。
```python
import requests
# 登录网站,获取Cookies
def login_and_get_cookies():
login_url = "http://example.com/login"
credentials = {"username": "your_username", "password": "your_password"}
response = requests.post(login_url, data=credentials)
if response.status_code == 200:
cookies = response.cookies
return cookies
else:
print("Login failed")
return None
# 使用Cookies发送请求
def send_request_with_cookies(cookies):
url = "http://example.com/profile"
response = requests.get(url, cookies=cookies)
if response.status_code == 200:
print(response.text)
else:
print("Failed to fetch profile")
```
上述代码演示了如何通过登录网站获取Cookies,并在后续的请求中带上这些Cookies,以维持登录状态并访问用户的个人资料页面。
#### 3.2 实例:利用Cookies进行登录并保持状态的爬虫实现
接下来,我们将通过一个实例来展示如何利用Cookies来进行登录并保持状态的爬虫实现。假设我们需要登录GitHub并爬取用户的个人信息,代码如下:
```python
import requests
# 登录GitHub并获取Cooki
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了Python爬虫与数据抓取领域的各种技术和实践方法。从初识网络爬虫到利用机器学习技术优化爬虫策略,涵盖了涉及HTTP请求、HTML解析、XPath、CSS选择器、正则表达式等多方面技术应用。读者将通过学习专栏内的文章如何处理反爬虫技术、利用代理IP优化爬虫效率、数据清洗与去重等内容,深入了解如何构建高效稳健的Python爬虫系统。此外,专栏还介绍了爬虫数据持久化存储、分布式爬虫任务调度等实现方法,同时展示了在深度学习、自然语言处理领域的应用案例,为读者提供了全面丰富的Python爬虫技术探索与实践经验。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
OODB数据建模:设计灵活且可扩展的数据库,应对数据变化,游刃有余

# 1. OODB数据建模概述
对象-面向数据库(OODB)数据建模是一种数据建模方法,它将现实世界的实体和关系映射到数据库中。与关系数据建模不同,OODB数据建模将数据表示为对象,这些对象具有属性、方法和引用。这种方法更接近现实世界的表示,从而简化了复杂数据结构的建模。
OODB数据建模提供了几个关键优势,包括:
* **对象标识和引用完整性
Python map函数在代码部署中的利器:自动化流程,提升运维效率

# 1. Python map 函数简介**
map 函数是一个内置的高阶函数,用于将一个函数应用于可迭代对象的每个元素,并返回一个包含转换后元素的新可迭代对象。其语法为:
```python
map(function, iterable)
```
其中,`function` 是要应用的函数,`iterable` 是要遍历的可迭代对象。map 函数通
Python脚本调用与区块链:探索脚本调用在区块链技术中的潜力,让区块链技术更强大

# 1. Python脚本与区块链简介**
**1.1 Python脚本简介**
Python是一种高级编程语言,以其简洁、易读和广泛的库而闻名。它广泛用于各种领域,包括数据科学、机器学习和Web开发。
**1.2 区块链简介**
区块链是一种分布式账本技术,用于记录交易并防止篡改。它由一系列称为区块的数据块组成,每个区块都包含一组交易和指向前一个区块的哈希值。区块链的去中心化和不可变性使其
【实战演练】时间序列预测项目:天气预测-数据预处理、LSTM构建、模型训练与评估

# 1. 时间序列预测概述**
时间序列预测是指根据历史数据预测未来值。它广泛应用于金融、天气、交通等领域,具有重要的实际意义。时间序列数据通常具有时序性、趋势性和季节性等特点,对其进行预测需要考虑这些特性。
# 2. 数据预处理
### 2.1 数据收集和清洗
#### 2.1.1 数据源介绍
时间序列预测模型的构建需要可靠且高质量的数据作为基础。数据源的选择至关重要,它将影响模型的准确性和可靠性。常见的时序数据源包括:
Python Excel数据分析:统计建模与预测,揭示数据的未来趋势
# 1. Python Excel数据分析概述**
**1.1 Python Excel数据分析的优势**
Python是一种强大的编程语言,具有丰富的库和工具,使其成为Excel数据分析的理想选择。通过使用Python,数据分析人员可以自动化任务、处理大量数据并创建交互式可视化。
**1.2 Python Excel数据分析库**
【进阶】强化学习中的奖励工程设计
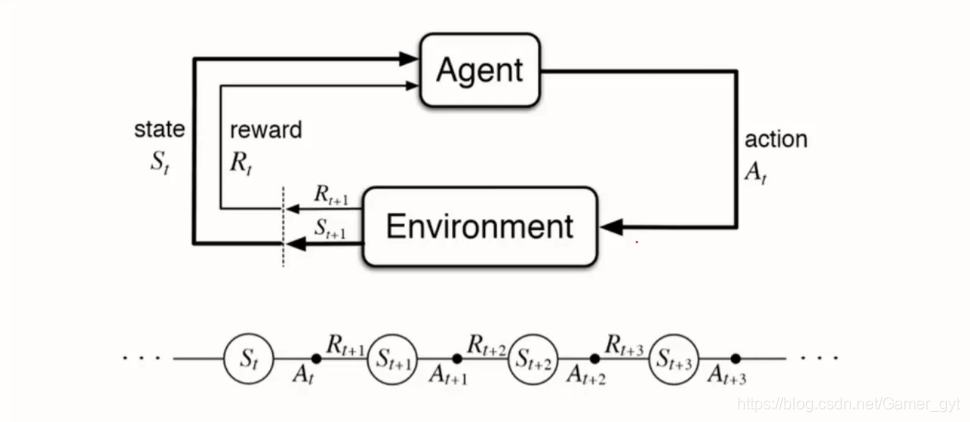
# 1. **2.1 强化学习的数学模型**
强化学习的数学模型建立在马尔可夫决策过程 (MDP) 的基础上。MDP 是一个四元组 (S, A, P, R),其中:
* S
【实战演练】前沿技术应用:AutoML实战与应用

# 1. AutoML概述与原理**
AutoML(Automated Machine Learning),即自动化机器学习,是一种通过自动化机器学习生命周期
【实战演练】综合自动化测试项目:单元测试、功能测试、集成测试、性能测试的综合应用

# 2.1 单元测试框架的选择和使用
单元测试框架是用于编写、执行和报告单元测试的软件库。在选择单元测试框架时,需要考虑以下因素:
* **语言支持:**框架必须支持你正在使用的编程语言。
* **易用性:**框架应该易于学习和使用,以便团队成员可以轻松编写和维护测试用例。
* **功能性:**框架应该提供广泛的功能,包括断言、模拟和存根。
* **报告:**框架应该生成清
【实战演练】构建简单的负载测试工具

# 1. 负载测试基础**
负载测试是一种性能测试,旨在模拟实际用户负载,评估系统在高并发下的表现。它通过向系统施加压力,识别瓶颈并验证系统是否能够满足预期性能需求。负载测试对于确保系统可靠性、可扩展性和用户满意度至关重要。
# 2. 构建负载测试工具
### 2.1 确定测试目标和指标
在构建负载测试工具之前,至关重要的是确定测试目标和指标。这将指导工具的设计和实现。以下是一些需要考虑的关键因素:
【实战演练】虚拟宠物:开发一个虚拟宠物游戏,重点在于状态管理和交互设计。

# 2.1 虚拟宠物的状态模型
### 2.1.1 宠物的基本属性
虚拟宠物的状态由一系列基本属性决定,这些属性描述了宠物的当前状态,包括:
- **生命值 (HP)**:宠物的健康状况,当 HP 为 0 时,宠物死亡。
- **饥饿值 (Hunger)**:宠物的饥饿程度,当 Hunger 为 0 时,宠物会饿死。
- **口渴
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )