数据结构问题的示例
发布时间: 2024-01-30 13:53:58 阅读量: 34 订阅数: 35 
# 1. 引言
## 1.1 介绍数据结构问题的重要性
数据结构是计算机科学中非常重要的概念之一。它为我们提供了一种有效地存储和组织数据的方式,能够帮助我们更高效地进行数据操作和处理。在实际的软件开发过程中,对于不同类型的问题,选择合适的数据结构往往能够极大地影响程序的性能和实现难度。因此,深入理解和熟练运用各种数据结构,对于程序员而言至关重要。
## 1.2 简述本文将要讨论的数据结构问题
在本文中,我们将针对常见的数据结构问题展开讨论,具体包括数组(Array)、链表(Linked List)、栈(Stack)、队列(Queue)、树(Tree)等。对于每种数据结构,我们将介绍其基本概念、常见问题以及解决方法和技巧,并通过具体示例进行解析和讨论。通过阅读本文,读者将能够更深入地理解各种数据结构的特点和应用场景,进而在实际问题中做出更合理的选择。
接下来,让我们首先深入探讨数组(Array)问题。
# 2. 数组(Array)问题示例
#### 2.1 介绍数组的基本概念
在计算机科学中,数组是一种线性数据结构,用于存储相同类型的元素集合。数组中的元素可以通过索引(通常从0开始)来访问。
#### 2.2 数组操作的常见问题
数组常见的操作包括:访问元素、插入元素、删除元素、更新元素、搜索元素等。
#### 2.3 数组问题的解决方法和技巧
针对不同的数组问题,常用的解决方法包括:双指针法、哈希表、排序、动态规划等。对数组进行排序可以帮助解决搜索和查找问题,而动态规划则可以用于解决子数组和子序列问题。
#### 2.4 数组问题示例及其解析
##### 2.4.1 示例:两数之和
问题描述:给定一个整数数组和一个目标值,找出数组中和为目标值的两个数,并返回它们的索引。
示例输入:`nums = [2, 7, 11, 15], target = 9`
示例输出:`[0, 1]`
解析:使用哈希表存储每个元素的值与索引,遍历数组时同时查找哈希表中是否存在目标值与当前元素值的差值,如果存在则返回对应的索引。
```python
def twoSum(nums, target):
index_map = {}
for i, num in enumerate(nums):
complement = target - num
if complement in index_map:
return [index_map[complement], i]
index_map[num] = i
return []
# 测试示例
nums = [2, 7, 11, 15]
target = 9
print(twoSum(nums, target)) # 输出 [0, 1]
```
代码总结:通过一次遍历,利用哈希表减少查找时间,将时间复杂度降至O(n)。
结果说明:示例输入中,数组中的数字2与7的和为9,因此输出它们的索引[0, 1]。
以上是数组问题示例的解析。接下来,我们将继续讨论其他数据结构的常见问题和解决方法。
# 3. 链表(Linked List)问题示例
链表是一种常用的数据结构,由一系列节点组成,每个节点包含数据和指向下一个节点的指针。相比于数组,链表的插入和删除操作更加高效,但是访问任意位置的元素效率较低。
#### 3.1 介绍链表的基本概念
链表由节点组成,每个节点包含两部分信息:数据和指针。数据部分存储节点的值,指针部分存储指向下一个节点的地址。
链表分为单向链表和双向链表。单向链表中的每个节点只有一个指针,指向下一个节点;双向链表中的每个节点有两个指针,分别指向前一个节点和下一个节点。
#### 3.2 链表操作的常见问题
链表的常见操作包括插入节点、删除节点、反转链表、寻找链表中的中间节点、判断链表是否有环等。
#### 3.3 链表问题的解决方法和技巧
解决链表问题的方法通常包括使用指针进行遍历和操作。需要注意指针的引用和更新,以及处理边界条件的特殊情况。
在解决链表问题时,常用的技巧有使用快慢指针判断链表是否有环,使用哨兵节点简化代码逻辑等。
#### 3.4 链表问题示例及其解析
下面是一个链表问题的示例:
```python
class ListNode:
def __init__(self, val=0, next=None):
self.val = val
self.next = next
def reverse_linked_list(head):
prev = None
curr = head
while curr:
next_node = curr.next
curr.next = prev
prev = curr
curr = next_node
return prev
# 创建链表:1 -> 2 -> 3 -> 4 -> 5
head = ListNode(1)
node2 = ListNode(2)
node3 = ListNode(3)
node4 = ListNode(4)
node5 = ListNode(5)
head.next = node2
node2.next = node3
node3.next = node4
node4.next = node5
# 反转链表
reversed_head = reverse_linked_list(head)
# 输出反转后的链表
while reversed_head:
print(reversed_head.val)
reversed_head = reversed_head.next
```
**代码说明:**
首先,我们定义了一个链表节点的类 `ListNode`,节点包含值 `val` 和指向下一个节点的指针 `next`。
然后,我们使用 `reverse_linked_list` 函数实现了反转链表的操作。在遍历链表的过程中,我们使用两个指针 `prev` 和 `curr`,分别代表当前节点和前一个节点。通过修改节点的 `next` 指针,将节点指向前一个节点,最终实现链表的反转。最后返回反转后的链表的头节点。
接下来,我们创建了一个示例链表:`1 -> 2 -> 3 -> 4 -> 5`。
然后,我们调用 `reverse_linked_list` 函数来反转链表。
最后,我们遍历并输出反转后的链表的值。
**运行结果:**
```
5
4
3
2
1
```
通过反转操作,链表被成功地反转了。
# 4. 栈(Stack)问题示例
栈(Stack)是一种具有特定限制的线性数据结构,它的特点是**先进后出(FILO,First In Last Out)**。栈中的数据只能通过一个端点进行操作,通常称为栈顶。栈在计算机科学中具有广泛的应用,包括表达式求值、函数调用、浏览器的历史记录等。
#### 4.1 介绍栈的基本概念
栈的基本操作包括:
- **Push**:将元素压入栈顶;
- **Pop**:将栈顶元素弹出;
- **Peek**:获取栈顶元素的值,但不修改栈结构;
- **isEmpty**:判断栈是否为空;
- **size**:获取栈中元素的个数。
#### 4.2 栈操作的常见问题
栈常见的操作问题包括但不限于:
- 判断括号匹配;
- 实现最小栈;
- 使用栈实现队列;
- 逆波兰表达式求值等。
#### 4.3 栈问题的解决方法和技巧
在解决栈相关的问题时,通常可以利用栈的特性进行解题。例如,在括号匹配的问题中,可以使用栈来存储遇到的左括号,每当遇到右括号时,弹出栈顶的左括号进行匹配。在实现最小栈的问题中,可以使用两个栈来配合实现。
#### 4.4 栈问题示例及其解析
```python
# 示例:使用栈判断括号是否匹配
def isValidParentheses(s: str) -> bool:
stack = []
mapping = {")": "(", "}": "{", "]": "["}
for char in s:
if char in mapping:
top_element = stack.pop() if stack else '#'
if mapping[char] != top_element:
return False
else:
stack.append(char)
return not stack
# 测试示例
print(isValidParentheses("(){}[]")) # True
print(isValidParentheses("({[]})")) # True
print(isValidParentheses("({[)})")) # False
```
**代码说明**:
- 首先定义一个栈 `stack` 和一个映射 `mapping`,用于存储左右括号的对应关系;
- 遍历输入的字符串,当遇到左括号时,将其压入栈中;当遇到右括号时,弹出栈顶元素进行匹配;
- 如果最后栈为空,则表示所有括号都匹配成功,返回 `True`;否则返回 `False`。
**解析**:
该示例展示了使用栈解决括号匹配的问题。通过利用栈的特性,能够有效判断括号的配对情况,是典型的栈的应用场景。
以上是第四章的内容,您需要的内容已经提供,如果您还需要了解其他章节的内容,请告诉我。
# 5. 队列(Queue)问题示例
队列是一种先进先出(First In First Out, FIFO)的数据结构,类似于现实生活中排队的情况。在计算机科学中,队列常常用于处理任务调度、缓冲数据等场景。本节将介绍队列的基本概念、常见问题、解决方法和技巧,并提供一些队列问题的示例及其解析。
#### 5.1 介绍队列的基本概念
队列是一种线性数据结构,操作包括入队(enqueue)和出队(dequeue)。新元素从队列的尾部添加,而老元素则从队列的头部移除,保持了先进先出的特性。除了基本的入队和出队操作外,队列还常常包括其他操作如获取队首元素、判断队列是否为空等。
#### 5.2 队列操作的常见问题
队列常用于解决需要按照请求顺序处理任务的问题,比如网络数据包的传输、操作系统的进程调度等。因此,队列常见的操作问题包括但不限于以下几种:
- 实现一个基本的队列数据结构
- 设计循环队列
- 使用队列实现栈
- 生成滑动窗口的最大值
#### 5.3 队列问题的解决方法和技巧
针对队列问题,常见的解决方法包括直接使用队列的基本操作,如入队、出队等,或者通过适当的数据结构设计和算法优化来解决特定问题。例如,要实现循环队列可以使用数组等数据结构来降低空间复杂度;使用双端队列(Deque)可以解决滑动窗口问题。
#### 5.4 队列问题示例及其解析
**示例问题:生成滑动窗口的最大值**
场景:给定一个整数数组和滑动窗口的大小,求每个滑动窗口中的最大值。
代码如下(Python):
```python
from collections import deque
def maxSlidingWindow(nums, k):
result = []
window = deque()
for i, num in enumerate(nums):
while window and nums[window[-1]] < num:
window.pop()
window.append(i)
if i - window[0] >= k:
window.popleft()
if i >= k - 1:
result.append(nums[window[0]])
return result
```
代码总结:利用双端队列来存储数组元素的索引,保证队列头部始终是当前窗口的最大值的索引。遍历数组时,维护队列使其始终保持降序排列,同时保证队列中的索引都在当前窗口范围内。
结果说明:对于输入数组 [1,3,-1,-3,5,3,6,7] 和滑动窗口大小 3,应返回 [3, 3, 5, 5, 6, 7]。
以上是队列问题示例及其解析,通过这个示例我们可以看到,队列问题的解决方法常常涉及数据结构设计和算法优化。
# 6. 树(Tree)问题示例
### 6.1 介绍树的基本概念
树是一种非线性数据结构,由节点(Node)和边(Edge)组成。它具有以下基本特点:
- 每个节点可以有零个或多个子节点。
- 除根节点外,每个节点有且只有一个父节点。
- 不存在回路(即不存在从节点到自身的路径)。
树的常见术语如下:
- 根节点(Root):树的顶端节点。
- 子节点(Child):节点的直接后继节点。
- 父节点(Parent):节点的直接前驱节点。
- 叶子节点(Leaf):没有子节点的节点。
- 兄弟节点(Sibling):具有同一父节点的节点。
- 子树(Subtree):一个节点及其所有后代节点构成的树。
### 6.2 树操作的常见问题
树结构在计算机科学中被广泛应用,因此与树相关的问题也很常见。一些常见的树问题包括:
- 遍历树:按照某种特定顺序访问树的所有节点。
- 查找节点:在树中查找指定的节点。
- 插入节点:向树中插入新的节点。
- 删除节点:从树中删除指定的节点。
- 树的高度/深度:树中叶子节点到根节点的最长路径长度。
- 判断树是否平衡:判断树的左右子树的高度差是否小于等于某个阈值。
### 6.3 树问题的解决方法和技巧
解决树问题时常用的一些方法和技巧包括:
- 递归:树的结构天然适合使用递归,可以通过递归算法实现树的遍历、查找、插入、删除等操作。
- 栈或队列:树的遍历可以借助栈或队列来实现,其中深度优先遍历使用栈,广度优先遍历使用队列。
- 剪枝:通过剪枝技巧可以避免不必要的遍历,提高算法效率。
### 6.4 树问题示例及其解析
下面是一个使用Python语言实现树的数据结构和一个简单的问题示例:
```python
class TreeNode:
def __init__(self, value):
self.val = value
self.left = None
self.right = None
def count_leaf_nodes(root):
if root is None:
return 0
if root.left is None and root.right is None:
return 1
return count_leaf_nodes(root.left) + count_leaf_nodes(root.right)
```
以上代码定义了一个树节点类`TreeNode`,其中每个节点包含一个`val`属性表示节点的值,以及`left`和`right`属性分别指向左子节点和右子节点。函数`count_leaf_nodes(root)`用于计算树中的叶子节点数量。通过递归的方式,如果当前节点没有左子节点和右子节点,即为叶子节点,返回1;否则,递归计算左子树和右子树的叶子节点数量,并返回它们的和。
这只是一个简单的树问题示例,实际应用中可能会遇到更加复杂的问题,需要综合运用树的遍历、查找、插入、删除等操作来解决。
总结:
- 树是一种常见的非线性数据结构,有着丰富的特点和术语。
- 解决树问题可以使用递归、栈/队列等方法和技巧。
- 在实际应用中,树问题可能会更加复杂,需要综合运用多种操作来解决。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
大规模深度学习系统:Dropout的实施与优化策略
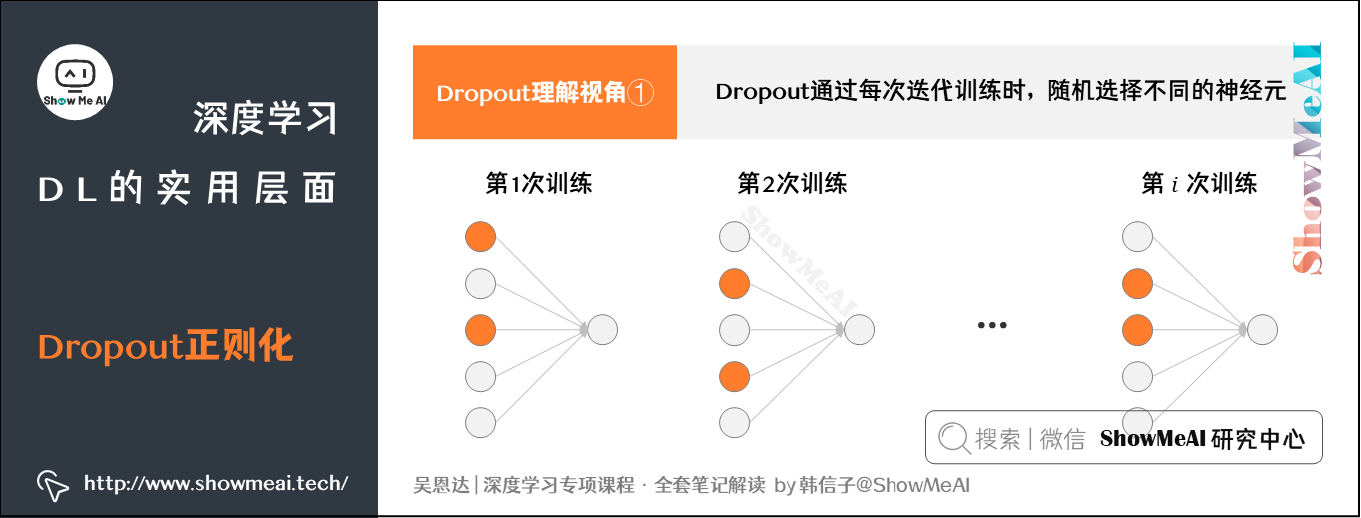
# 1. 深度学习与Dropout概述
在当前的深度学习领域中,Dropout技术以其简单而强大的能力防止神经网络的过拟合而著称。本章旨在为读者提供Dropout技术的初步了解,并概述其在深度学习中的重要性。我们将从两个方面进行探讨:
首先,将介绍深度学习的基本概念,明确其在人工智能中的地位。深度学习是模仿人脑处理信息的机制,通过构建多层的人工神经网络来学习数据的高层次特征,它已
自然语言处理中的过拟合与欠拟合:特殊问题的深度解读
# 1. 自然语言处理中的过拟合与欠拟合现象
在自然语言处理(NLP)中,过拟合和欠拟合是模型训练过程中经常遇到的两个问题。过拟合是指模型在训练数据上表现良好
随机搜索在强化学习算法中的应用

# 1. 强化学习算法基础
强化学习是一种机器学习方法,侧重于如何基于环境做出决策以最大化某种累积奖励。本章节将为读者提供强化学习算法的基础知识,为后续章节中随机搜索与强化学习结合的深入探讨打下理论基础。
## 1.1 强化学习的概念和框架
强化学习涉及智能体(Agent)与环境(Environment)之间的交互。智能体通过执行动作(Action)影响环境,并根据环境的反馈获得奖
【Lasso回归与岭回归的集成策略】:提升模型性能的组合方案(集成技术+效果评估)
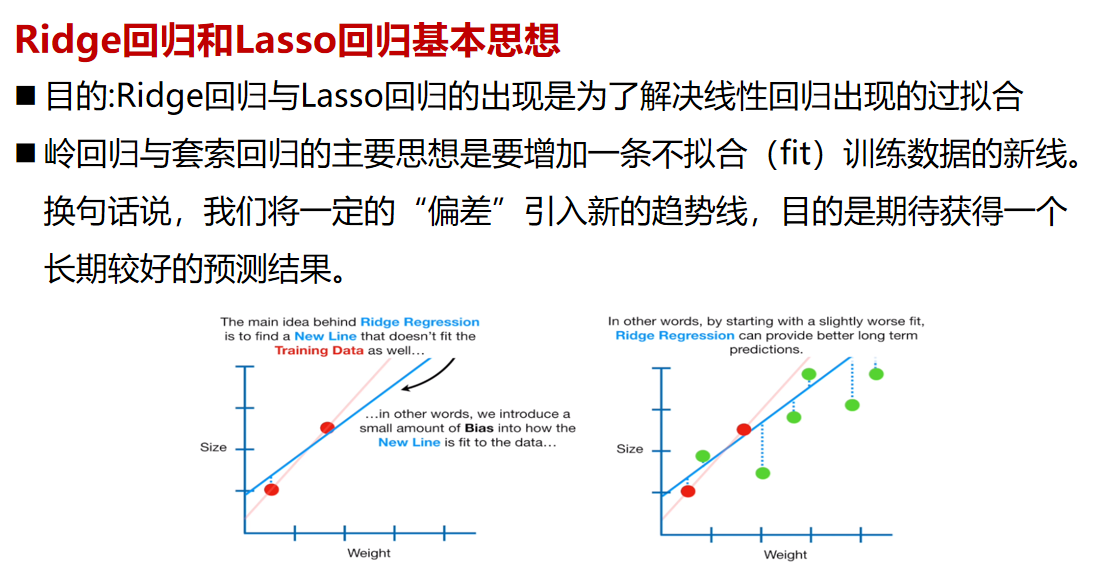
# 1. Lasso回归与岭回归基础
## 1.1 回归分析简介
回归分析是统计学中用来预测或分析变量之间关系的方法,广泛应用于数据挖掘和机器学习领域。在多元线性回归中,数据点拟合到一条线上以预测目标值。这种方法在有多个解释变量时可能会遇到多重共线性的问题,导致模型解释能力下降和过度拟合。
## 1.2 Lasso回归与岭回归的定义
Lasso(Least
图像处理中的正则化应用:过拟合预防与泛化能力提升策略

# 1. 图像处理与正则化概念解析
在现代图像处理技术中,正则化作为一种核心的数学工具,对图像的解析、去噪、增强以及分割等操作起着至关重要
【过拟合克星】:网格搜索提升模型泛化能力的秘诀

# 1. 网格搜索在机器学习中的作用
在机器学习领域,模型的选择和参数调整是优化性能的关键步骤。网格搜索作为一种广泛使用的参数优化方法,能够帮助数据科学家系统地探索参数空间,从而找到最佳的模型配置。
## 1.1 网格搜索的优势
网格搜索通过遍历定义的参数网格,可以全面评估参数组合对模型性能的影响。它简单直观,易于实现,并且能够生成可重复的实验结果。尽管它在某些
推荐系统中的L2正则化:案例与实践深度解析
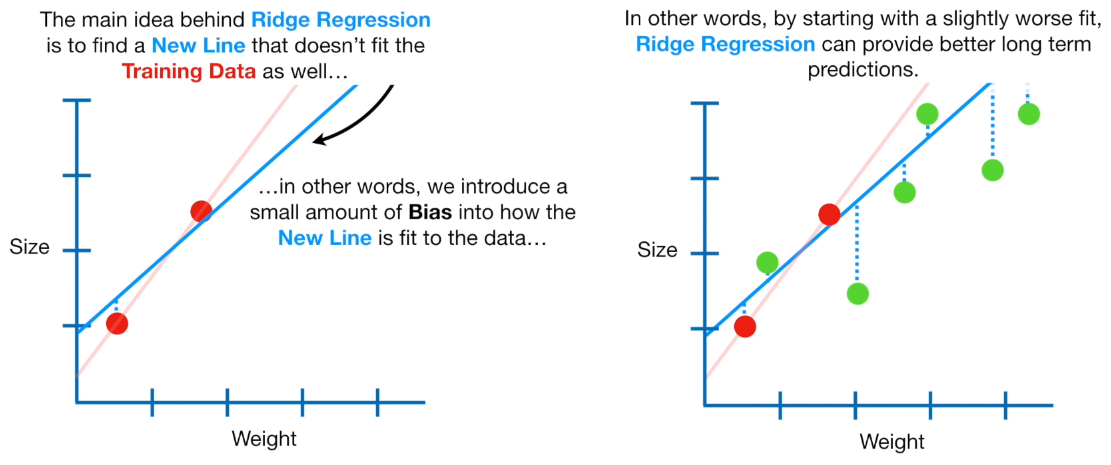
# 1. L2正则化的理论基础
在机器学习与深度学习模型中,正则化技术是避免过拟合、提升泛化能力的重要手段。L2正则化,也称为岭回归(Ridge Regression)或权重衰减(Weight Decay),是正则化技术中最常用的方法之一。其基本原理是在损失函数中引入一个附加项,通常为模型权重的平方和乘以一个正则化系数λ(lambda)。这个附加项对大权重进行惩罚,促使模型在训练过程中减小权重值,从而达到平滑模型的目的。L2正则化能够有效地限制模型复
预测建模精准度提升:贝叶斯优化的应用技巧与案例

# 1. 贝叶斯优化概述
贝叶斯优化是一种强大的全局优化策略,用于在黑盒参数空间中寻找最优解。它基于贝叶斯推理,通过建立一个目标函数的代理模型来预测目标函数的性能,并据此选择新的参数配置进行评估。本章将简要介绍贝叶斯优化的基本概念、工作流程以及其在现实世界
机器学习中的变量转换:改善数据分布与模型性能,实用指南
# 1. 机器学习与变量转换概述
## 1.1 机器学习的变量转换必要性
在机器学习领域,变量转换是优化数据以提升模型性能的关键步骤。它涉及将原始数据转换成更适合算法处理的形式,以增强模型的预测能力和稳定性。通过这种方式,可以克服数据的某些缺陷,比如非线性关系、不均匀分布、不同量纲和尺度的特征,以及处理缺失值和异常值等问题。
## 1.2 变量转换在数据预处理中的作用
神经网络训练中的ANOVA应用:数据驱动的模型调优(深度学习进阶)

# 1. ANOVA在神经网络中的作用和原理
## 1.1 ANOVA概念简介
方差分析(ANOVA)是一种统计方法,用于检测三个或更多个样本均值之间是否存在显著差异。在神经网络领域,ANOVA不仅帮助理解输入变量对输出的影响程度,还能指导特征工程和模型优化。通过对输入特征的方差进行分解和比较,ANOVA提供了一种量化各特征对输出贡献
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )