uboot启动过程详解
发布时间: 2023-12-14 14:41:09 阅读量: 44 订阅数: 32 

Uboot启动流程详解
# 第一章:介绍uboot
1.1 uboot简介
1.2 uboot的作用和重要性
1.3 uboot的特点和优势
### 2. 第二章:uboot的编译和配置
2.1 uboot源码获取
2.2 uboot的编译步骤
2.3 uboot的配置选项和参数说明
当然可以!以下是文章第三章节的内容:
## 第三章:uboot启动流程
uboot的启动流程包括三个主要步骤:加载、初始化和执行。在本章中,我们将详细介绍uboot的启动流程,并解释每个步骤的具体操作和功能。
### 3.1 启动代码的加载过程
uboot的启动代码位于存储介质上的某个特定地址,例如Flash的起始地址。启动过程的第一步是将启动代码加载到内存中,以便后续的执行。
加载启动代码的过程通常由硬件平台的引导装置(例如内存控制器或外设控制器)完成。具体的加载过程可能因硬件平台而异,但通常包括以下步骤:
1. 首先,硬件平台将从Flash或其他存储介质中读取启动代码的二进制数据。
2. 然后,硬件平台将数据按照指定的地址范围写入内存。
3. 最后,硬件平台将控制权转交给内存中的启动代码,以进行后续的初始化和执行。
### 3.2 启动代码的初始化和准备
一旦启动代码加载到内存中,uboot会执行一系列的初始化和准备工作,以确保系统环境的正常设置和配置。
具体的初始化和准备工作可能包括以下内容:
1. 首先,uboot会对内存进行初始化,包括设置内存映射表、配置内存管理器等。
2. 接下来,uboot会对外设进行初始化,例如串口、网络接口等,以确保后续的通信和交互。
3. 同时,uboot还会读取并解析存储设备上的配置文件(如uboot环境变量),以获取系统参数和用户设置。
### 3.3 启动代码的执行和跳转
完成初始化和准备之后,uboot将开始执行启动代码中的主要功能和操作,并最终跳转到操作系统或其他引导程序。
启动代码的执行过程通常包括以下步骤:
1. 首先,uboot会解析存储设备上的启动命令,例如bootargs和bootcmd等。
2. 根据启动命令的参数和设置,uboot会执行相应的操作,例如加载内核镜像、设定启动参数等。
3. 最后,uboot会跳转到内核镜像的入口地址,将控制权交给操作系统,完成启动过程。
通过以上步骤,uboot成功完成了整个启动流程,将系统从硬件平台引导到操作系统。
本章节详细介绍了uboot的启动流程,包括启动代码的加载、初始化和执行过程。下一章节将会继续讲解uboot启动过程中的关键环节。
希望本章能够帮助读者更好地理解uboot的启动流程和操作过程。
*代码示例待补充。
## 第四章:uboot启动过程中的关键环节
### 4.1 启动地址和参数的传递
在uboot启动过程中,启动地址和参数的传递是非常关键的环节。通常,在启动设备时,uboot需要知道从哪里加载内核镜像以及如何配置内核启动参数。这些信息需要在启动命令中进行传递。
#### 场景
假设我们的uboot需要从SD卡的第一个分区加载内核镜像,并传递启动参数给内核。
#### 代码
```c
// 首先设置内核的启动地址
#define KERNEL_LOAD_ADDR 0x8000
// 加载内核镜像
load mmc 0:1 ${kernel_load_addr} uImage
// 设置内核启动参数
setenv bootargs console=ttyS0,115200 root=/dev/mmcblk0p2 rw rootwait
```
#### 注释
- `load mmc 0:1 ${kernel_load_addr} uImage`:加载SD卡第一个分区中的uImage文件,并将其加载到内存的KERNEL_LOAD_ADDR处。
- `setenv bootargs console=ttyS0,115200 root=/dev/mmcblk0p2 rw rootwait`:设置内核的启动参数,包括控制台设置和根文件系统参数等。
#### 代码总结
通过上述代码,我们实现了在uboot启动过程中设置内核的启动地址和传递启动参数的过程。
#### 结果说明
设置了内核的启动地址和传递了启动参数之后,uboot在启动内核时就能正确加载内核镜像并传递正确的启动参数给内核,从而确保系统能够成功启动。
### 4.2 启动命令的解析和执行
在uboot的启动过程中,启动命令的解析和执行是非常关键的环节。uboot需要根据用户输入的启动命令,解析并执行对应的操作。
#### 场景
假设用户输入了一个uboot启动命令,需要uboot解析并执行对应的操作。
#### 代码
```c
// 获取用户输入的启动命令
char *cmdline = "bootm 0x8000";
// 解析并执行启动命令
run_command(cmdline, 0);
```
#### 注释
- `bootm 0x8000`:用户输入的启动命令,表示启动内核镜像地址为0x8000处的内核。
#### 代码总结
通过上述代码,我们模拟了用户输入一个启动命令,并通过`run_command`函数进行解析和执行。
#### 结果说明
通过解析和执行启动命令,uboot能够根据用户输入的命令正确加载并启动对应的内核镜像,从而完成系统的启动过程。
### 4.3 启动过程中的异常处理和错误提示
在uboot的启动过程中,异常处理和错误提示是非常重要的环节。当出现启动过程中的错误或异常情况时,uboot需要能够及时发现并给出相应的错误提示。
#### 场景
假设在启动过程中,uboot发现内核镜像文件损坏或者启动参数设置错误,需要给出相应的错误提示。
#### 代码
```c
// 检测内核镜像文件是否合法
if (!image_check_magic((void *)KERNEL_LOAD_ADDR)) {
printf("Error: Invalid kernel image\n");
// 执行相应的错误处理操作
// ...
}
// 检测启动参数是否设置正确
if (check_bootargs_validity() != 0) {
printf("Error: Invalid bootargs\n");
// 执行相应的错误处理操作
// ...
}
```
#### 注释
- `image_check_magic((void *)KERNEL_LOAD_ADDR)`:检测内核镜像是否合法的函数调用。
- `check_bootargs_validity()`:检测启动参数是否设置正确的函数调用。
#### 代码总结
通过上述代码,我们演示了在uboot启动过程中如何检测并处理内核镜像和启动参数的异常情况。
#### 结果说明
当出现内核镜像文件损坏或者启动参数设置错误等异常情况时,uboot能够及时发现并给出相应的错误提示,从而帮助用户快速排查和解决问题,确保系统能够正常启动。
### 5. 第五章:uboot启动流程中的扩展功能
在实际的uboot启动流程中,除了基本的启动过程外,还可以通过一些扩展功能来增强uboot的灵活性和适用性。本章将介绍uboot启动流程中的扩展功能,包括启动脚本的编写和使用、启动选项的配置和调试,以及启动过程中的自定义操作和扩展功能。
#### 5.1 启动脚本的编写和使用
启动脚本是uboot启动过程中非常重要的一部分,通过编写启动脚本可以实现一系列启动操作的自动化。下面是一个简单的uboot启动脚本示例,以展示其编写和使用方法:
```shell
# Sample Uboot启动脚本示例
# 该脚本用于启动Linux内核
# 设置内核启动参数
setenv bootargs 'root=/dev/mmcblk0p2 rw rootwait console=ttyS0,115200n8'
# 加载内核镜像
fatload mmc 0:1 0x80000000 zImage
# 加载设备树
fatload mmc 0:1 0x81000000 my_board.dtb
# 启动内核
bootz 0x80000000 - 0x81000000
```
上述示例中,首先通过`setenv`设置了内核的启动参数,然后使用`fatload`命令从MMC设备加载内核镜像和设备树,最后使用`bootz`命令启动内核。通过这样的启动脚本,可以简化启动时的手动操作,提高启动效率。
#### 5.2 启动选项的配置和调试
uboot提供了丰富的启动选项配置,可以通过启动命令行参数来对启动过程进行定制和调试。例如,可以通过`bootdelay`设置启动延迟时间,通过`bootcmd`设置默认启动命令,还可以通过`bootargs`设置内核启动参数等。
在调试过程中,还可以使用`printenv`命令来查看当前的环境变量配置,使用`setenv`命令来动态修改环境变量,以便进行启动选项的调试和定制。这些启动选项的灵活配置能够帮助开发者更好地理解和调试uboot的启动过程。
#### 5.3 启动过程中的自定义操作和扩展功能
除了基本的启动脚本和启动选项配置外,uboot还支持用户自定义操作和扩展功能。例如,可以通过uboot提供的API接口来实现自定义的启动命令,可以在启动过程中进行特定设备的初始化操作,还可以实现特定硬件的驱动和控制功能等。
通过这样的自定义操作和扩展功能,可以使uboot更好地适应不同的硬件平台和应用场景,提高uboot的通用性和灵活性。
以上是关于uboot启动流程中的扩展功能的介绍,包括启动脚本的编写和使用、启动选项的配置和调试,以及启动过程中的自定义操作和扩展功能。这些功能可以帮助开发者更好地理解和利用uboot,并为实际应用场景提供更多可能性。
当然可以,以下是文章第六章节【uboot的优化和定制】的具体内容:
## 6. 第六章:uboot的优化和定制
在实际应用中,为了提升uboot的性能和适应特定场景的需求,我们可以对uboot进行优化和定制。本章将介绍一些常见的优化和定制方法。
### 6.1 uboot启动速度的优化
uboot的启动速度对于嵌入式系统来说非常重要,因此我们可以采取一些措施来提升uboot的启动速度。以下是一些常见的优化方法:
1. 精简代码:可以根据实际需求裁剪uboot的功能,去除不需要的模块和驱动,减小代码体积。
2. 优化编译选项:通过调整编译选项,去除冗余代码和无关符号,减小可执行文件的体积。
3. 启用快速启动模式:一些平台支持快速启动模式,可以通过配置相关寄存器来实现快速启动,提升启动速度。
4. 减少不必要的初始化步骤:根据具体需求,可以跳过一些不必要的初始化和检测步骤,如初始化显示屏等。
### 6.2 uboot功能的定制和裁剪
uboot提供了丰富的功能和模块,但是在实际应用中,并不是所有功能都会被使用到。为了减小内存占用和提高启动速度,我们可以定制和裁剪uboot的功能,只保留需要的模块和驱动。以下是一些常见的定制和裁剪方法:
1. 配置菜单:uboot提供了配置菜单,可以根据需求选择需要的功能模块和驱动,在编译时自动生成对应的配置文件。
2. Kconfig工具:uboot使用Kconfig来管理配置选项,可以使用Kconfig工具手动配置和裁剪uboot功能。
3. 脚本编译:通过编写脚本,手动指定需要编译的文件和选项,实现定制和裁剪功能。
### 6.3 uboot启动过程的改进和调整
除了优化和定制功能外,我们还可以对uboot的启动过程进行改进和调整,以适应不同场景和需求。以下是一些常见的改进和调整方法:
1. 更换和调整启动模式:根据具体需求,可以选择不同的启动模式,如串口启动、网络启动等。
2. 添加自定义逻辑:在uboot启动过程中,可以添加自定义的逻辑和操作,如检测硬件状态、读取配置文件等。
3. 修改启动顺序和流程:根据特定场景的需求,可以修改uboot的启动顺序和流程,以适应不同的应用场景。
综上所述,通过优化和定制uboot的功能以及改进和调整uboot的启动过程,我们可以提升uboot的性能和适应性,更好地满足实际应用需求。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了嵌入式系统中的关键组件uboot,旨在帮助开发人员深入理解其内部工作原理和应用技巧。从uboot启动过程详解、环境变量配置和使用,到裸机编程、串口调试技巧,再到Bootloader加载Linux内核、设备树原理和实战,专栏内容丰富多样。我们还将深入探讨SPI Flash编程、网卡驱动开发与调试、NAND Flash编程技巧,以及文件系统加载和格式化等实际应用案例。此外,我们还将介绍裸机调试工具链、环境变量存储原理、裸机编程与控制寄存器、串口引导与调试技术等内容。最后,专栏还将涉及Bootloader自定义配置实战、定时器原理与应用、I2C总线编程与调试、USB驱动开发与调试技巧,以及Flash文件系统编程与优化和内存布局与管理。通过本专栏的学习,读者将能够全面掌握uboot的工作原理和丰富的应用技巧,为嵌入式系统开发提供强有力的支持。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
揭秘ETA6884移动电源的超速充电:全面解析3A充电特性

# 摘要
本文详细探讨了ETA6884移动电源的技术规格、充电标准以及3A充电技术的理论与应用。通过对充电技术的深入分析,包括其发展历程、电气原理、协议兼容性、安全性理论以及充电实测等,我们提供了针对ETA6884移动电源性能和效率的评估。此外,文章展望了未来充电技术的发展趋势,探讨了智能充电、无线充电以
【编程语言选择秘籍】:项目需求匹配的6种语言选择技巧

# 摘要
本文全面探讨了编程语言选择的策略与考量因素,围绕项目需求分析、性能优化、易用性考量、跨平台开发能力以及未来技术趋势进行深入分析。通过对不同编程语言特性的比较,本文指出在进行编程语言选择时必须综合考虑项目的特定需求、目标平台、开发效率与维护成本。同时,文章强调了对新兴技术趋势的前瞻性考量,如人工智能、量子计算和区块链等,以及编程语言如何适应这些技术的变化。通
【信号与系统习题全攻略】:第三版详细答案解析,一文精通

# 摘要
本文系统地介绍了信号与系统的理论基础及其分析方法。从连续时间信号的基本分析到频域信号的傅里叶和拉普拉斯变换,再到离散时间信号与系统的特性,文章深入阐述了各种数学工具如卷积、
微波集成电路入门至精通:掌握设计、散热与EMI策略

# 摘要
本文系统性地介绍了微波集成电路的基本概念、设计基础、散热技术、电磁干扰(EMI)管理以及设计进阶主题和测试验证过程。首先,概述了微波集成电路的简介和设计基础,包括传输线理论、谐振器与耦合结构,以及高频电路仿真工具的应用。其次,深入探讨了散热技术,从热导性基础到散热设计实践,并分析了散热对电路性能的影响及热管理的集成策略。接着,文章聚焦于EMI管理,涵盖了EMI基础知识、
Shell_exec使用详解:PHP脚本中Linux命令行的实战魔法

# 摘要
本文详细探讨了PHP中的Shell_exec函数的各个方面,包括其基本使用方法、在文件操作与网络通信中的应用、性能优化以及高级应用案例。通过对Shell_exec函数的语法结构和安全性的讨论,本文阐述了如何正确使用Shell_exec函数进行标准输出和错误输出的捕获。文章进一步分析了Shell_exec在文件操作中的读写、属性获取与修改,以及网络通信中的Web服
NetIQ Chariot 5.4高级配置秘籍:专家教你提升网络测试效率

# 摘要
NetIQ Chariot是网络性能测试领域的重要工具,具有强大的配置选项和高级参数设置能力。本文首先对NetIQ Chariot的基础配置进行了概述,然后深入探讨其高级参数设置,包括参数定制化、脚本编写、性能测试优化等关键环节。文章第三章分析了Net
【信号完整性挑战】:Cadence SigXplorer仿真技术的实践与思考
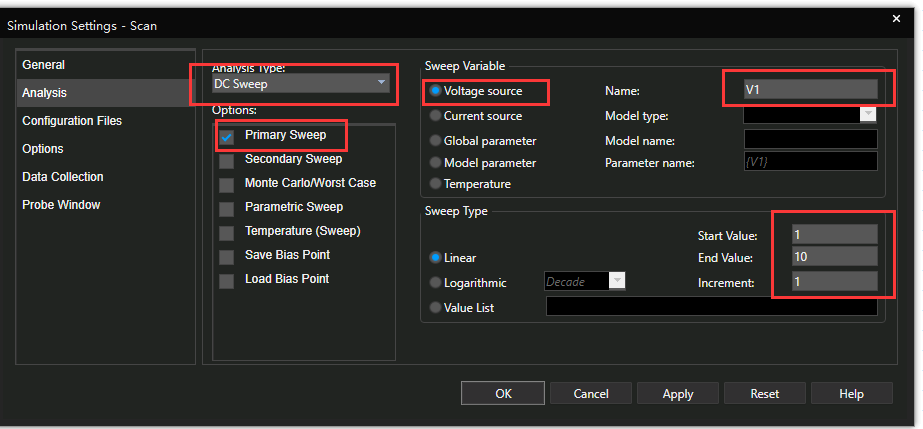
# 摘要
本文全面探讨了信号完整性(SI)的基础知识、挑战以及Cadence SigXplorer仿真技术的应用与实践。首先介绍了信号完整性的重要性及其常见问题类型,随后对Cadence SigXplorer仿真工具的特点及其在SI分析中的角色进行了详细阐述。接着,文章进入实操环节,涵盖了仿真环境搭建、模型导入、仿真参数设置以及故障诊断等关键步骤,并通过案例研究展示了故障诊断流程和解决方案。在高级
【Python面向对象编程深度解读】:深入探讨Python中的类和对象,成为高级程序员!

# 摘要
本文深入探讨了面向对象编程(OOP)的核心概念、高级特性及设计模式在Python中的实现和应用。第一章回顾了面向对象编程的基础知识,第二章详细介绍了Python类和对象的高级特性,包括类的定义、继承、多态、静态方法、类方法以及魔术方法。第三章深入讨论了设计模式的理论与实践,包括创建型、结构型和行为型模式,以及它们在Python中的具体实现。第四
Easylast3D_3.0架构设计全解:从理论到实践的转化
# 摘要
Easylast3D_3.0是一个先进的三维设计软件,其架构概述及其核心组件和理论基础在本文中得到了详细阐述。文中详细介绍了架构组件的解析、设计理念与原则以及性能评估,强调了其模块间高效交互和优化策略的重要性。
【提升器件性能的秘诀】:Sentaurus高级应用实战指南

# 摘要
Sentaurus是一个强大的仿真工具,广泛应用于半导体器件和材料的设计与分析中。本文首先概述了Sentaurus的工具基础和仿真环境配置,随后深入探讨了其仿真流程、结果分析以及高级仿真技
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )