Python Web微服务架构:Docker和Kubernetes的部署秘籍
发布时间: 2024-10-15 13:11:02 阅读量: 29 订阅数: 50 

Docker+Kubernetes(k8s)微服务容器化实践1

# 1. Python Web微服务架构概述
## 1.1 微服务架构的兴起
微服务架构作为一种软件架构模式,近年来在IT行业迅速崛起。它通过将大型复杂的单体应用拆分成小型的、独立的服务来提高系统的可维护性、可扩展性和可部署性。Python因其简洁的语法和强大的库支持,成为开发微服务应用的理想选择。
## 1.2 Python与微服务的契合点
Python的动态类型和快速开发能力使得它在微服务架构中扮演着重要角色。Python的Web框架如Flask和Django,提供了快速构建RESTful API的能力,而像Tornado和Twisted这样的异步框架则适合构建高性能的服务。
## 1.3 微服务架构的优势与挑战
微服务架构的优势在于其灵活性和可扩展性。服务可以根据需求独立扩展,从而优化资源使用并降低运维成本。然而,微服务也带来了分布式系统的复杂性,如服务发现、负载均衡、故障恢复等问题,需要通过适当的工具和策略来管理。
# 2. Docker容器化技术
## 2.1 Docker基础知识
### 2.1.1 Docker的安装与配置
Docker是一个开源的应用容器引擎,它允许开发者打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口(类似iPhone的app)。
#### 安装Docker
Docker的安装相对简单,以下是基于Ubuntu系统的安装步骤:
1. 更新软件包索引:
```bash
sudo apt-get update
```
2. 安装Docker的依赖包:
```bash
sudo apt-get install apt-transport-https ca-certificates curl software-properties-common
```
3. 添加Docker的官方GPG密钥:
```bash
curl -fsSL ***
```
4. 设置稳定版仓库:
```bash
sudo add-apt-repository "deb [arch=amd64] *** $(lsb_release -cs) stable"
```
5. 再次更新软件包索引:
```bash
sudo apt-get update
```
6. 安装Docker CE(社区版):
```bash
sudo apt-get install docker-ce
```
7. 验证安装:
```bash
sudo docker run hello-world
```
如果系统输出了“Hello from Docker!”的信息,说明Docker已成功安装。
#### 配置Docker
Docker安装完成后,我们可以进行一些基本配置,例如设置开机自启动、更改存储位置等。
1. 设置Docker开机自启动:
```bash
sudo systemctl enable docker
```
2. 配置Docker存储位置,可以提高Docker的性能:
```bash
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"data-root": "/mnt/docker-data"
}
EOF
sudo systemctl restart docker
```
### 2.1.2 Docker镜像和容器的概念
#### Docker镜像
Docker镜像是一个轻量级、可执行的独立软件包,包含运行某个软件所需的所有内容,我们称之为容器的蓝图。每个镜像都由一系列的层(layers)组成,这些层代表了创建镜像过程中的不同阶段。
Docker Hub提供了大量官方和第三方镜像,例如,我们可以拉取一个Ubuntu镜像:
```bash
sudo docker pull ubuntu
```
#### Docker容器
容器是镜像的运行实例,我们可以创建、启动、停止、移动或删除容器。容器与虚拟机类似,但它们更轻量级。一个容器包含了一个应用程序及其所有的依赖包,而无需任何额外的依赖。
创建并启动一个容器:
```bash
# 创建并启动一个Ubuntu容器,并在其中运行/bin/bash
sudo docker run -it ubuntu /bin/bash
```
通过以上命令,我们成功启动了一个Ubuntu容器,并且进入了容器的bash环境。
#### 总结
在本章节中,我们介绍了Docker的基本概念,包括如何安装和配置Docker,以及Docker镜像和容器的基本知识。通过实践操作,我们了解了如何拉取官方镜像和创建运行容器。这些基础知识对于理解和使用Docker至关重要,为后续的高级操作和应用打下了坚实的基础。
# 3. Kubernetes集群管理
## 3.1 Kubernetes核心概念
### 3.1.1 Kubernetes集群架构
Kubernetes集群由一组节点组成,这些节点可以分为两类:主节点(Master)和工作节点(Node)。主节点是集群的控制平面,负责整个集群的管理和调度。工作节点则是运行应用的服务器。
#### 集群组件
- **API Server**:集群的控制接口,所有的操作都是通过API Server来进行的。
- **Scheduler**:负责分配调度容器运行在哪个节点上。
- **Controller Manager**:运行控制器进程,负责维护集群的状态。
- **etcd**:一个分布式的键值存储系统,用于存储所有集群数据。
- **Worker Node**:运行容器化应用程序的节点。
#### 节点组件
- **Kubelet**:确保容器都运行在Pod中。
- **Kube-Proxy**:维护节点网络规则,实现服务抽象。
- **Container Runtime**:如Docker,负责运行容器。
### 3.1.2 Pods, Services和Deployments基础
Pods是Kubernetes中的最小部署单元,它代表集群中运行的一个或多个容器的组合。Pods内的容器共享存储和网络。
#### Pods
Pods的设计是为了支持同质或异质容器的紧密耦合运行。Pod内的所有容器共享一个网络命名空间和IPC命名空间,这意味着它们可以使用`localhost`进行通信。
#### Services
Services提供了一种将一组Pods暴露给外部网络的方式,它定义了一组Pod的访问策略。通过标签选择器将Services与Pods关联起来。
```yaml
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
```
#### Deployments
Deployments为Pods和ReplicaSets(

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供全面的 Python Web 开发指南,涵盖从入门到精通的必备技能。它深入探讨了 Flask 和 Django 等流行框架,并提供了高级项目管理和性能优化技巧。专栏还揭示了 Web 安全最佳实践,并通过实战案例研究和代码实现展示了 Web 项目开发的各个方面。此外,它还介绍了 Web 自动化测试、Web 爬虫、Web 服务监控、Web 微服务架构、Web 日志分析、异步 Web 开发、Web 动态渲染、Web API 设计、Web 数据库集成、Web 缓存策略、Web 性能调优、Web 中间件开发、Web 国际化和本地化、Web 信号和事件驱动以及 Web 单元测试等主题。本专栏旨在帮助开发者构建高效、安全且可扩展的 Web 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
安全代码编写:开发人员必须知道的漏洞预防策略

# 摘要
在快速发展的软件开发领域,编写安全代码成为了确保软件质量和用户数据安全的核心环节。本文系统地探讨了安全代码编写的基础概念、漏洞预防理论、安全编码标准、漏洞预防实践技巧以及常见编程语言的安全编码实践。通过对漏洞分类、根本原因分析、输入验证、输出编码、错误处理、安全日志管理等多个方面进行详细讨论,本文旨在提供一套全面的理论与实践指南,以便于开发者构建更加安全的软件产品。文章还介绍了代码审查流程、工具选择以
MATLAB光学仿真:5大进阶技巧助你提升模拟效率与精确度
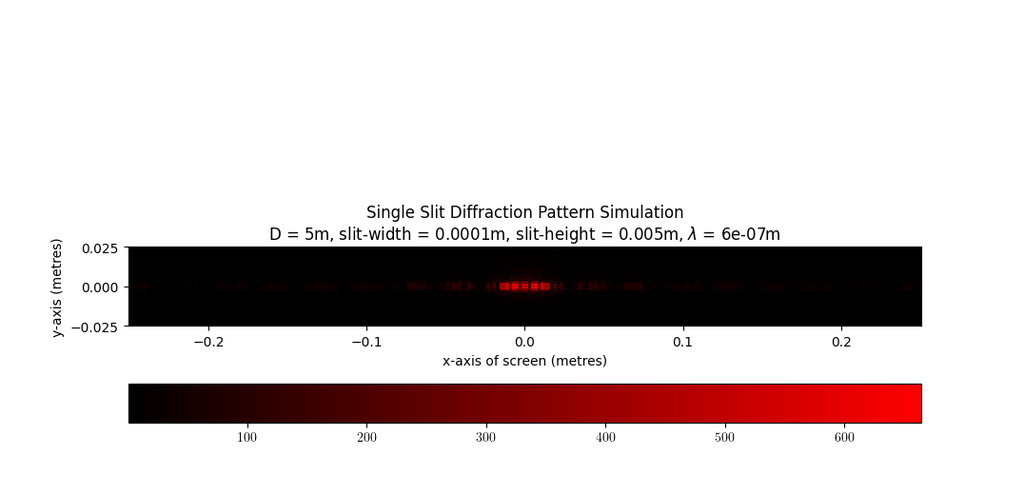
# 摘要
MATLAB光学仿真技术是光学工程和研究领域的关键技术之一,通过提供全面的光学仿真方法和分析工具,极大地推动了光学设计和性能评估的进步。本文首先介绍MATLAB光学仿真基础,包括必要的数学基础和MATLAB内置工具箱的应用。随后,文章深入探讨了波前工程、光束质量评估、多物理场耦合以及并行计算与优化等进阶仿真技巧,强调了波前分析、波前控制、光束参数计算和多物理场效应的重要性。最后
【Exynos 4412电源管理深度探讨】:优化策略与最佳实践
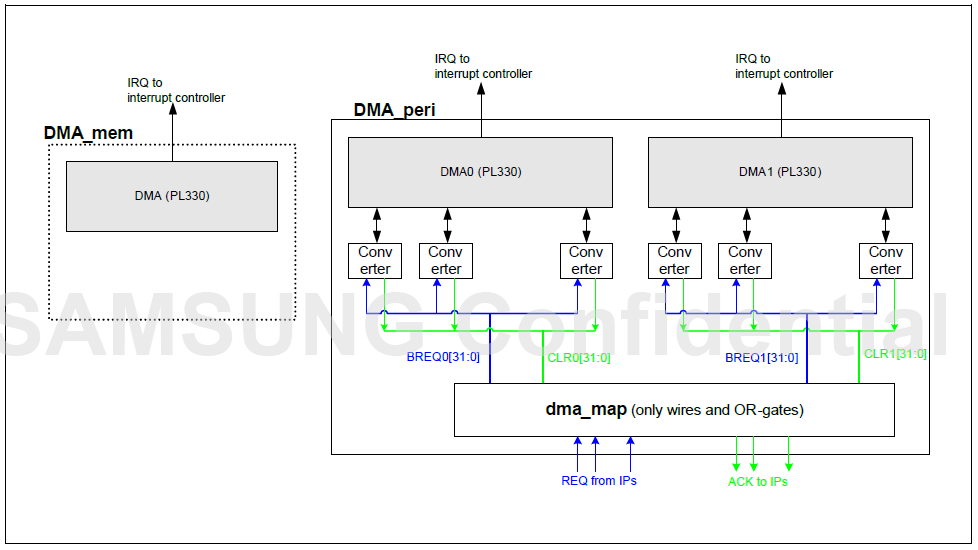
# 摘要
本文全面探讨了Exynos 4412处理器的电源管理机制。首先概述了电源管理的基本理论,包括核心概念和不同层面的管理策略。接着,深入分析了Exynos 4412的电源管理架构,特别是动态电源管理策略中的时钟门控技术和电压调节。文章还详细介绍了优化技术,包括优化目标、实验设计以及实践应用,并通过案例研究展示了优化前后的效果对比。在最佳实践方面,提出了硬件设计、软件开发和系统集成中的具体策略。最
【传感器与Arduino交互】:实现传感器数据准确读取的3大策略
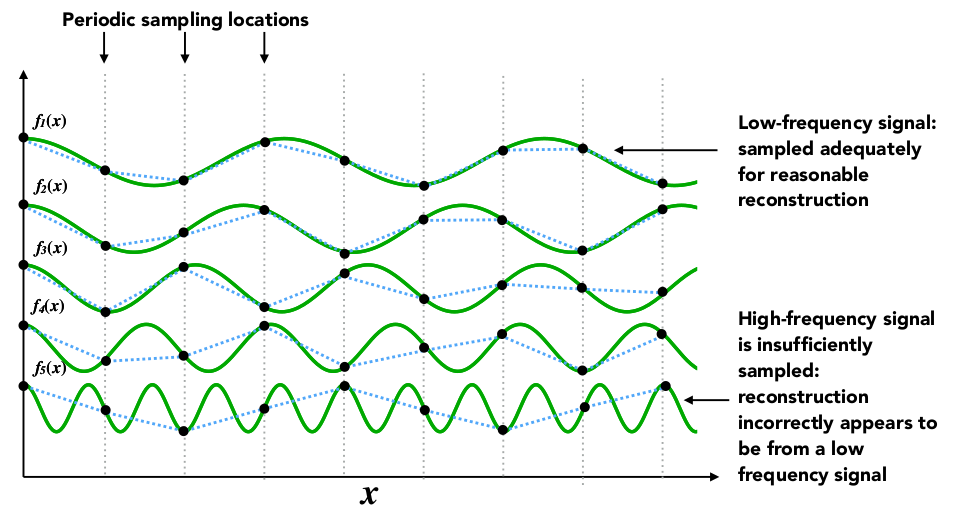
# 摘要
本文全面介绍了传感器与Arduino技术的基础知识、数据读取策略、编程实践以及综合应用案例。首先,阐述了传感器信号类型及其在Arduino平台上的准确读取方法,包括模拟和数字信号处理。接着,介绍了Arduino编程环境设置和传感器编程实现,以及通过串口和显示屏进行数据处理与显示的技术。在此基础上,文章分析了多个综合应用案例,如气候监测、智能家居控制和无人机飞
PDMS高级建模秘密:专家如何提升设计效率30%
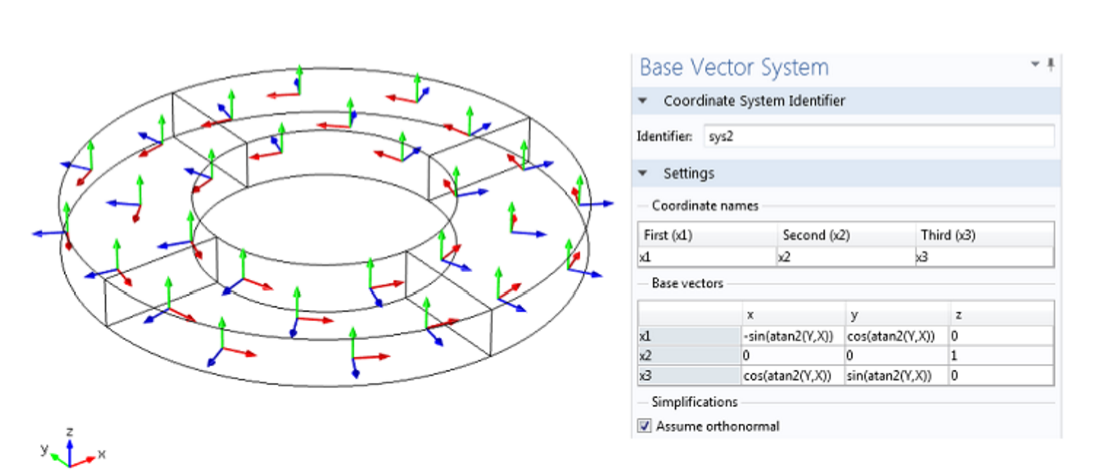
# 摘要
本文全面介绍了PDMS高级建模技术,首先概述了PDMS建模的重要性和理论基础,阐述了其基本概念、标准流程和理论框架。随后,文章深入探讨了提升PDMS建模效率的策略,包括优化建模工具和环境、实施高效的工作流程以及应用高级技术和技巧。文章还通过工业设计项目案例分析,展示PDMS建模技术在实践中的应用及效果。最后,展望了PDMS建模的未来趋势和挑战,特别是在人工智能、机器学习和云技术等方面的影响,并强调了持续学习和
【16串电池监测AFE信号处理进阶】:提升监测精度的高级技术

# 摘要
本文全面介绍了电池监测基础知识和模拟前端(AFE)信号处理技术。首先概述了AFE信号处理的基本概念、定义和作用,以及电池监测中涉及的信号类型。接着,深入探讨了AFE信号预处理技术和数字化处理技术,包括信号滤波、放大、转换、ADC应用以及数字滤波与信号重建。文章进一步阐述了提升监测精度的技术,涵盖高精度模拟信号处理、误差分析与校正方法、实时监测与数据分析技术。通过
版本控制基础:IT专业人员精通Subversion
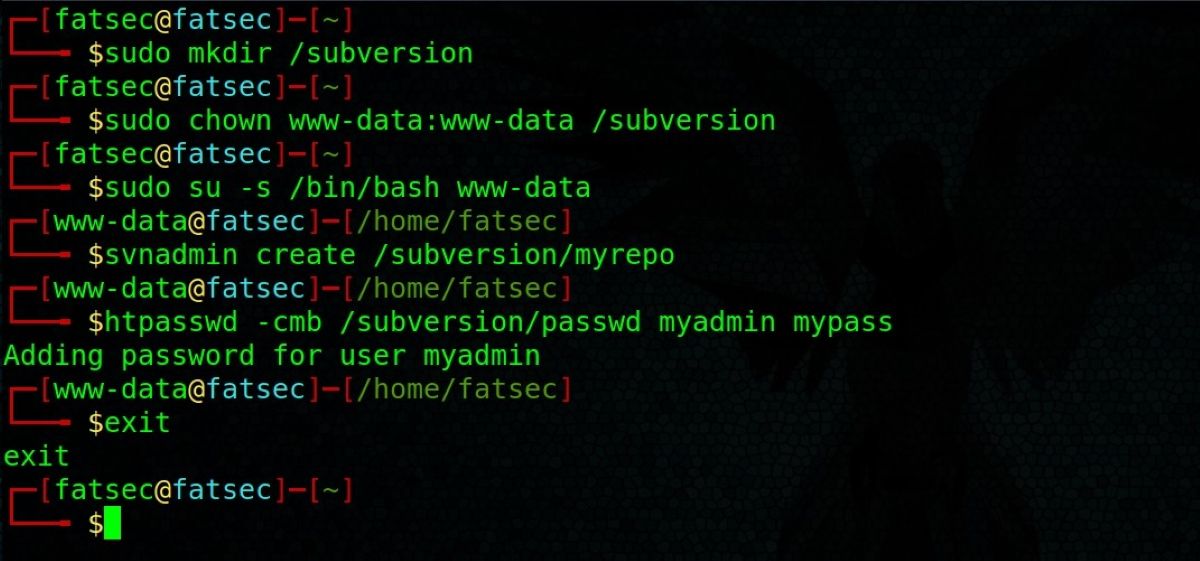
# 摘要
版本控制作为软件开发中不可或缺的工具,能够追踪和管理代码的变更历史,确保项目的协作开发和稳定迭代。本文首先概述了版本控制的基本概念和重要性,随后深入讲解了Subversion(SVN)这一广泛使用的版本控制系统的基本概念、结构、安装配置以及日常使用操作。文章还探讨了Subvers
电子工程师实战手册:从datasheet到产品选型的转换艺术
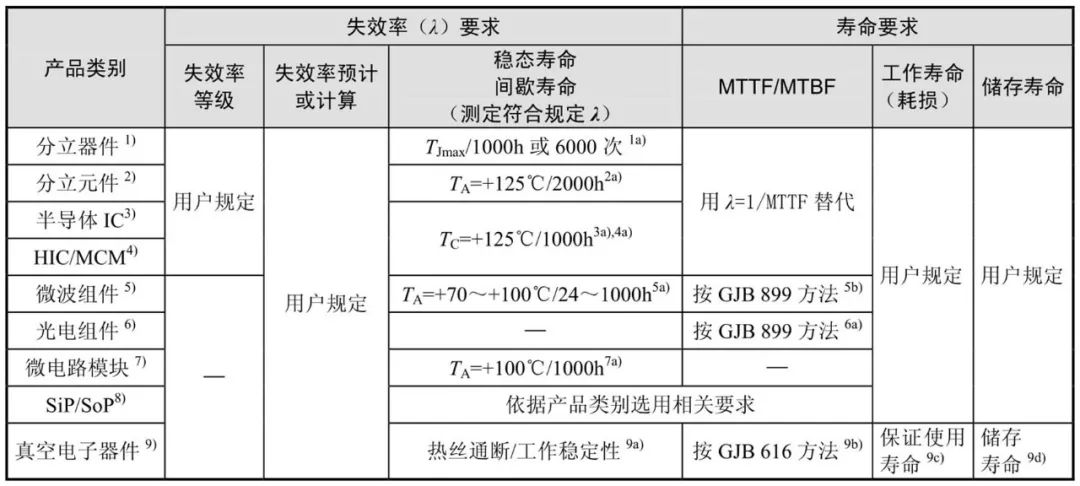
# 摘要
本文旨在全面解读datasheet的基础知识与结构,并深入分析电子元件的关键参数。通过探讨各类电气参数、环境和机械参数、性能和可靠性参数,本文提供了产品选型的实战技巧,包括如何根据设计需求、成本效益以及供应链因素进行元件选择。同时,文中通过多个应用案例分析了datasheet在电路设计中的具体应用。此外,本文指出了datasheet解读中的常见误区并提出相应对策,并探讨了未来技术趋势对产品选型可能产生的影响,如物联
VASPKIT可视化工具应用:直观理解计算结果的3大方法

# 摘要
VASPKIT是一个强大的可视化工具,专为材料科学和电子结构计算领域设计。本文概述了VASPKIT的基本功能和高级特性,着重介绍了其工作流程、可视化原理、用户界面设计以及如何应用于材料科学的具体实例。通过分析VASPKIT如何帮助用户分析晶体结构、研究电子与光学性质,本文还探讨了其在跨学科研究中的应用前景,包括与其他计算模拟工具
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )