Python Web缓存策略:提升应用性能的5大实战技巧
发布时间: 2024-10-15 13:43:20 阅读量: 46 订阅数: 36 

免费的防止锁屏小软件,可用于域统一管控下的锁屏机制
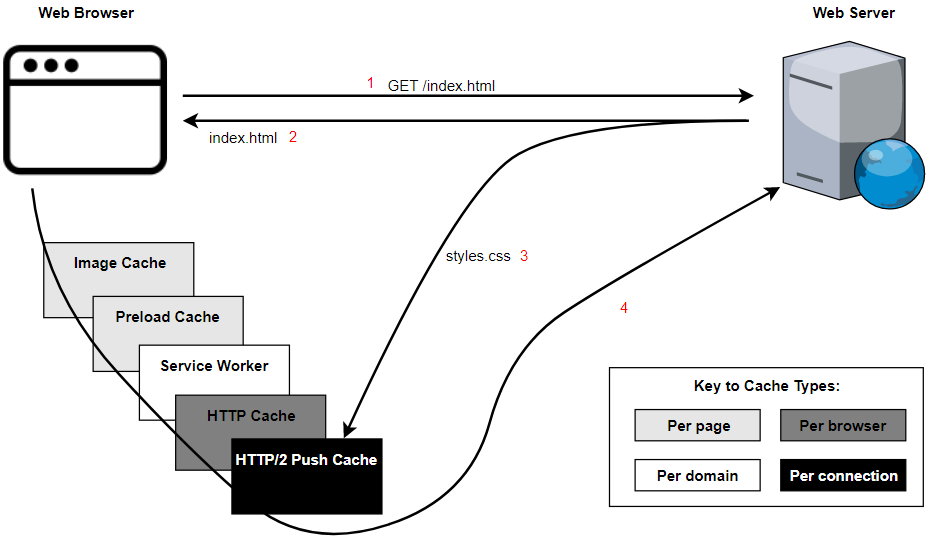
# 1. Python Web缓存概述
## 1.1 什么是缓存
在计算机科学中,缓存(Cache)是一种快速的存储层,位于数据使用者和较慢的数据源之间。在Web开发中,缓存能够显著提高应用程序的性能,减少对后端数据库的访问次数,以及降低系统的负载。通过存储最近使用或频繁访问的数据,缓存允许应用程序快速响应用户的请求,而不是每次都进行完整的数据处理和检索。
## 1.2 缓存的重要性
缓存对于现代Web应用程序来说至关重要,因为它可以:
- 减少响应时间:缓存数据可以直接从内存中快速读取,避免了从数据库加载的延迟。
- 降低服务器负载:减少数据库查询次数,减轻服务器压力,提高系统的稳定性和可靠性。
- 提高用户体验:快速的页面加载时间和流畅的用户体验能够提升用户满意度。
在Python Web开发中,合理地使用缓存机制不仅可以提高应用程序的性能,还能改善资源的利用率。接下来的章节将深入探讨缓存策略的理论基础,以及如何在实践中应用和优化这些策略。
# 2. 缓存策略的基础理论
## 2.1 缓存的基本概念和作用
### 2.1.1 什么是缓存
缓存(Cache)是一种存储临时数据的技术,用于加快数据检索速度,减少对后端存储系统的访问次数。在计算机科学中,缓存是一种高速数据存储层,位于数据使用者(如CPU)和数据存储层(如硬盘)之间。它存储了频繁访问的数据副本,当数据被请求时,系统首先检查缓存中是否有请求的数据,如果有,则直接从缓存中读取,这样可以大大提高数据访问速度。
### 2.1.2 缓存的重要性
缓存对于提升系统性能至关重要。它通过减少对缓慢的数据存储系统的依赖来降低访问延迟。例如,在Web应用中,缓存可以存储数据库查询结果,减少对数据库的直接访问次数,从而提升响应速度和处理能力。此外,缓存还可以减轻后端服务器的压力,提高并发处理能力,对于负载均衡和高可用性架构设计有着重要作用。
## 2.2 缓存策略的分类
### 2.2.1 常见的缓存策略
常见的缓存策略包括:
- **最近最少使用(LRU)**:淘汰最长时间未被访问的数据项。
- **最不常用(LFU)**:淘汰访问次数最少的数据项。
- **先进先出(FIFO)**:淘汰最早进入缓存的数据项。
- **随机淘汰(Random Replacement)**:随机淘汰数据项。
- **时间戳**:记录每个数据项的最后访问时间,淘汰最早被访问的数据项。
### 2.2.2 各种策略的比较和选择
每种缓存策略都有其适用场景。例如,LRU策略适用于访问模式随时间变化的数据集,因为它淘汰最长时间未被访问的数据项。LFU策略适合于访问模式较为稳定的数据集,因为它基于访问频率进行淘汰。
在选择缓存策略时,需要考虑数据访问模式、数据大小、缓存容量以及性能需求等因素。例如,如果数据集较小且访问模式稳定,LFU可能是更好的选择。对于大型数据集,LRU可能更加高效。
## 2.3 缓存的失效机制
### 2.3.1 缓存失效的类型
缓存失效(Cache Invalidation)指的是缓存中的数据由于某些原因不再有效,需要从缓存中移除或更新。常见的失效类型包括:
- **强制失效(Hard Invalidation)**:缓存数据因为某些操作而直接变为无效,必须从源头重新获取。
- **时间失效(Time-based Invalidation)**:缓存数据在一定时间后自动失效。
- **容量失效(Capacity-based Invalidation)**:当缓存达到最大容量时,根据策略淘汰部分数据。
### 2.3.2 缓存失效的影响和处理方法
缓存失效会导致性能下降,因为系统需要从源头(如数据库)重新获取数据。为了减少失效的影响,可以采取以下措施:
- **缓存预取(Cache Prefetching)**:在数据即将失效前预先更新缓存。
- **多级缓存(Multi-level Caching)**:使用多个缓存层级,比如本地缓存和分布式缓存结合使用。
- **缓存穿透保护(Cache Penetration Protection)**:设置缓存失效后的保护策略,避免大量请求直接打到后端系统。
在本章节中,我们介绍了缓存的基本概念、作用、策略分类以及失效机制。这些基础理论是理解和实践缓存技术的关键。接下来,我们将深入探讨Python Web缓存的实践应用。
# 3. Python Web缓存的实践应用
## 3.1 基于本地内存的缓存实践
在本章节中,我们将深入探讨如何在Python Web应用中实践本地内存缓存,包括使用内置的缓存模块以及如何实现本地缓存的优化。
### 3.1.1 使用内置的缓存模块
Python提供了多种内置的缓存模块,例如`cachetools`和`functools.lru_cache`,它们可以帮助开发者轻松地在本地内存中实现缓存机制。
#### 使用`cachetools`模块
`cachetools`是一个灵活的缓存工具库,它可以支持多种缓存策略。以下是一个使用`cachetools`实现本地缓存的简单示例:
```python
from cachetools import cached, TTLCache
# 创建一个缓存对象,设置最大缓存条目数为100,生存时间(TTL)为60秒
cache = TTLCache(maxsize=100, ttl=60)
@cached(cache)
def get_data(key):
# 这里是数据获取逻辑,例如从数据库或远程API获取
return fetch_data_from_source(key)
# 使用缓存函数
data = get_data(some_key)
```
在上述代码中,`get_data`函数被`@cached`装饰器装饰,这意味着每次调用该函数时,都会首先检查缓存中是否存在相应数据,如果存在,则直接从缓存中获取,否则会执行函数内部的逻辑以获取数据,并将其存入缓存。
#### 使用`functools.lru_cache`
`lru_cache`是Python标准库中的一个装饰器,它实现了一个简单的最近最少使用(LRU)缓存算法。
```python
from functools import lru_cache
@lru_cache(maxsize=128)
def fib(n):
if n < 2:
return n
return fib(n-1) + fib(n-2)
# 调用缓存函数
print(fib(10))
```
在上述代码中,`fib`函数计算斐波那契数列,通过`@lru_cache`装饰器,其计算结果会被缓存起来,当再次调用`fib`函数计算相同参数时,可以直接从缓存中获取结果,提高效率。
### 3.1.2 实现本地缓存的优化
本地缓存虽然简单高效,但也有一些局限性,例如缓存数据量受到内存大小的限制,且无法在多个进程或服务器之间共享。因此,了解如何优化本地缓存是至关重要的。
#### 缓存容量优化
为了避免缓存容量过大导致内存溢出,可以设置合理的缓存最大大小。此外,还可以定期清理过期或不常用的缓存条目。
```python
# 设置缓存最大大小为100条
cache = TTLCache(maxsize=100, ttl=60)
# 定期清理缓存
if len(cache) > 100:
oldest = min(cache.keys(), key=lambda k: cache[k]['time'])
del cache[oldest]
```
#### 缓存数据结构优化
根据缓存数据的特点选择合适的数据结构,可以提高缓存的查询效率。例如,如果缓存的数据是键值对,可以使用字典;如果需要根据多个条件查询,可以考虑使用更复杂的数据结构。
#### 缓存算法优化
除了LRU算法外,还可以根据应用场景选择更合适的缓存算法,如最近最常使用(MRU)或最少使用(LFU)等。
```python
# 使用MRU缓存算法
from collections import OrderedDict
cache = OrderedDict()
def mru_cache(maxsize):
def decorating_function(user_function):
cache = OrderedDict()
@wraps(user_function)
def wrapper(*args, **kwargs):
# 检查缓存
if args in cache:
cache.move_to_end(args)
return cache[args]
result = user_function(*args, **kwargs)
if len(cache) >= maxsize:
cache.popitem(last=False)
cache[args] = result
return result
return wrapper
return decorating_function
```
在本章节介绍中,我们展示了如何在Python中使用内置的缓存模块来实现本地内存缓存,并讨论了几种优化本地缓存的策略。通过这些实践,开发者可以更有效地在本地内存中缓存数据,提高Web应用的性能。
## 3.2 基于数据库的缓存实践
数据库缓存是另一种常见的缓存实践方式,它将数据存储在数据库中,而不是本地内存。这种方式通常用于分布式系统中,因为它支持缓存数据在多个进程或服务器之间的共享。
### 3.2.1 数据库缓存的策略和实现
数据库缓存的策略通常包括直接缓存、查询缓存和对象缓存。直接缓存是将整个查询结果存储在缓存中;查询缓存是存储预编译的SQL语句;对象缓存则是存储ORM对象或其属性。
#### 直接缓存策略
直接缓存是最简单的数据库缓存策略。以下是一个示例,展示如何使用`SQLAlchemy`和`Flask-Caching`实现直接缓存:
```python
from flask import Flask
from flask_caching import Cache
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
app.config['CACHE_TYPE'] = 'redis'
cache = Cache(app)
db = SQLAlchemy(app)
class User(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(50))
email = db.Column(db.String(120))
# 使用Flask-Caching装饰器缓存查询结果
@cache.cached(timeout=50, key_prefix='all_users')
def get_all_users():
return User.query.all()
@app.route('/')
def index():
users = get_all_users()
return render_template('ind
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供全面的 Python Web 开发指南,涵盖从入门到精通的必备技能。它深入探讨了 Flask 和 Django 等流行框架,并提供了高级项目管理和性能优化技巧。专栏还揭示了 Web 安全最佳实践,并通过实战案例研究和代码实现展示了 Web 项目开发的各个方面。此外,它还介绍了 Web 自动化测试、Web 爬虫、Web 服务监控、Web 微服务架构、Web 日志分析、异步 Web 开发、Web 动态渲染、Web API 设计、Web 数据库集成、Web 缓存策略、Web 性能调优、Web 中间件开发、Web 国际化和本地化、Web 信号和事件驱动以及 Web 单元测试等主题。本专栏旨在帮助开发者构建高效、安全且可扩展的 Web 应用程序。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
破解3GPP TS 36.413:深入挖掘协议核心概念
%20(GSM)%20GSM_EDGE%20Layer%201%20General%20Requirements%20(3GPP%20TS%2044.004%20
高可用性策略详解:华为双活数据中心的稳定性保证

# 摘要
本文综述了高可用性策略在现代数据中心架构中的应用,特别以华为双活数据中心架构为例,深入解析了其基本概念、关键技术、网络设计,以及实施步骤和维护优化措施。文章详细介绍了双活数据中心的工作原理,数据同步与一致性保障机制,故障检测与自动切换机制,以及网络冗余与负载均衡策略。通过对规划、设计、实施、测试和维护等各阶段的详细分析,本文提供了一套完
【力控点表导入性能升级】:2倍速数据处理的优化秘诀

# 摘要
力控点表数据处理是工业控制系统中的核心环节,其效率直接影响整个系统的性能。本文首先概述了力控点表数据处理的基本概念,随后详细探讨了数据导入的理论基础,包括数据导入流程、数据结构理解及性能优化的准备工作。接着,文章着重介绍了提升力控点表导入速度的实践技巧,涵盖硬件加速、软件层性能优化以及系统级改进措施。通过案例分析,本文展示了如何在实际中应用这些技术和方法论,并讨论了持续改进与自动化
【Cortex-A中断管理实战】:实现高效中断处理的黄金法则
# 摘要
Cortex-A系列处理器广泛应用于高性能计算领域,其中中断管理是保障系统稳定运行的关键技术之一。本文首先概述了Cortex-A中断管理的基本概念和硬件中断机制,随后深入探讨了中断服务例程的编写、中断屏蔽和优先级配置以及实战中优化中断响应时间的策略。进一步地,本文提出了中断管理的高级技巧,包括中断嵌套、线程
Matlab图形用户界面(GUI)设计:从零开始到高级应用的快速通道
# 摘要
本文系统地介绍了Matlab图形用户界面(GUI)的设计与实现。第一章概览了Matlab GUI的基本概念与重要性。第二章详细介绍了GUI设计的基础知识,包括界面元素、事件处理、布局技术和编程技巧。第三章关注于数据处理,解释了如何在GUI中有效地输入、验证、可视化以及管理数据。第四章阐述了高级功能的实现,包括
【NSGA-II实战演练】:从理论到实际问题的求解过程,专家亲授
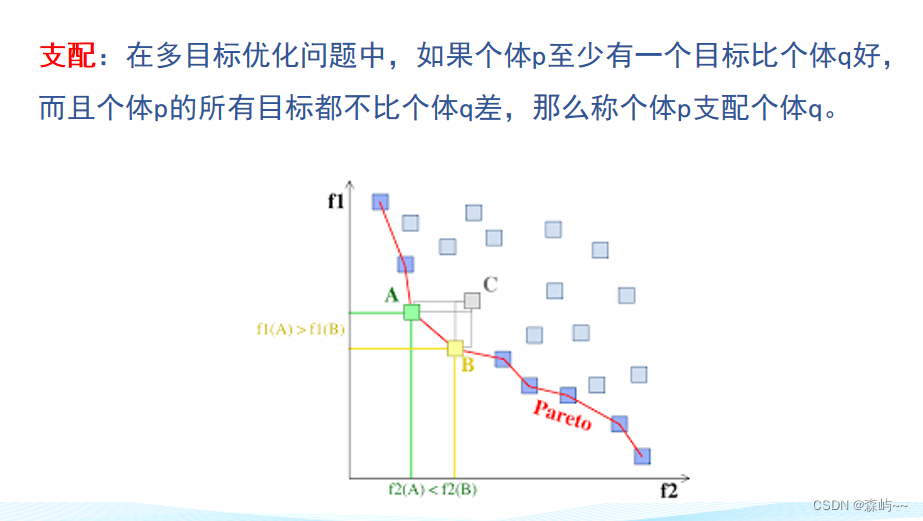
# 摘要
NSGA-II算法作为一种高效的多目标遗传优化算法,在处理具有多个冲突目标的优化问题上显示出了显著的性能优势。本文首先介绍了NSGA-II算法的基础概念和理论,涵盖其起源、数学模型以及核心机制,如快速非支配排序、密度估计和拥挤距离。随后,本文提供了NSGA-II算法的实践操作指南,涉及参数设置、编码初始化以及结果分析与可视化。通过详细的案例分析,本文展示了NSGA-II算法在工程优
一步成专家:MSP430F5529硬件设计与接口秘籍

# 摘要
本文全面介绍德州仪器(TI)的MSP430F5529微控制器,从开发环境的搭建到核心特性、硬件接口基础,以及高级功能和实际项目应用的深入分析。首先概述了MSP430F5529的基本信息和开发环境配置,随后深入探讨了其核心特性和内存与存储配置,以及丰富的I/O端口和外设接口。第三章讲述了硬件接口的基础知识,包括数字与模拟信号处理,以及通信
【COM Express行业解决方案】:5个案例分析,揭秘模块化嵌入式计算的力量

# 摘要
本文介绍了COM Express标准的概述、模块选择与兼容性、以及在工业自动化、车载信息系统和医疗设备中嵌入式计算的应用案例。通过对COM Express模块化嵌入式计算硬件基
【Ubuntu Mini.iso安装攻略】:新手到专家的10大步骤指南
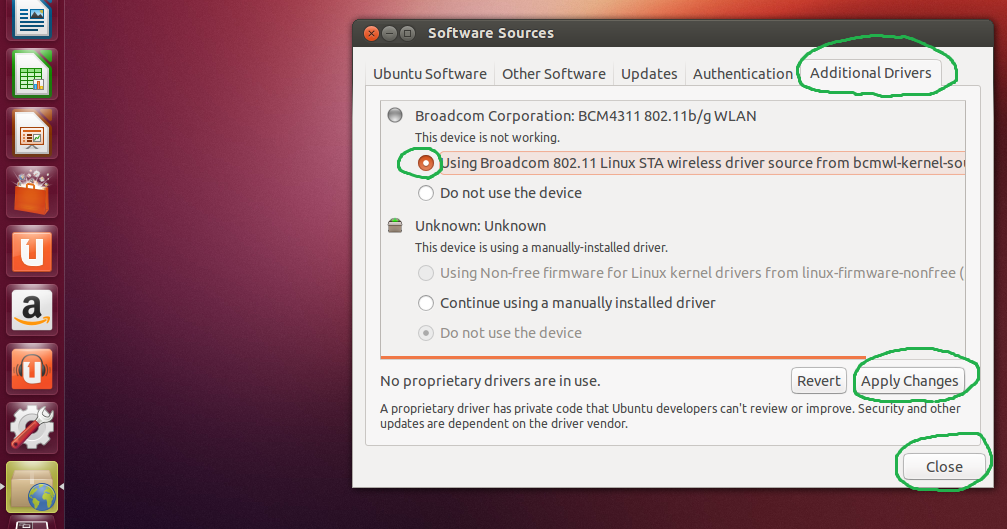
# 摘要
本文旨在为希望了解和使用Ubuntu Mini.iso的用户提供全面的指导。首先,文章介绍了Ubuntu Mini.iso的基本概念和准备工作,包括系统要求、下载、安装介质的制作以及硬件兼容性的检查。接下来,详细讲解了基础安装流程,涵盖了从启动到分区、格式化再到完成安装的每一步。此外,本文还探讨了高级安装选项,如自定义安装、系统安全设置以及安装额外驱动和软件。为了帮助用户在遇到问题时快速诊断和解决,还提供了故障排除与
Matrix Maker 自定义脚本编写:中文版编程手册的精粹

# 摘要
Matrix Maker是一款功能强大的自定义脚本工具,提供了丰富的脚本语言基础和语法解析功能,支持面向对象编程,并包含高级功能如错误处理、模块化和性能优化等。本文详细介绍了Matrix Ma
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )