Webpack与Vue:打造优雅的Vue项目
发布时间: 2023-12-19 10:43:31 阅读量: 50 订阅数: 40 

webpack搭建的一个vue项目模板
# 1. 介绍
### 什么是Webpack和Vue
Webpack是一个现代的静态模块打包工具,它可以分析项目中的各个模块,将它们打包成最终的静态资源。Vue是一个用于构建用户界面的渐进式JavaScript框架,它结合了易用性和灵活性,使得开发者可以快速构建交互式的Web应用程序。
### 为什么选择Webpack和Vue来构建项目
使用Webpack和Vue来构建项目有许多好处。首先,Webpack可以帮助我们管理和优化项目中的各个模块,从而加快应用的加载速度。其次,Vue提供了一套清晰简洁的API,使得开发者可以很方便地构建组件化的应用。另外,Webpack和Vue都有庞大的社区支持,可以提供丰富的插件和工具,使得开发变得更加高效。
### 目标:打造优雅的Vue项目
本篇文章的目标是教会读者如何使用Webpack和Vue来构建优雅的Vue项目。我们将从Webpack和Vue的基础开始讲解,然后介绍它们的集成方法,最后讲解优化和部署Vue项目的技巧。通过学习本文,读者将能够熟练运用Webpack和Vue来构建高效、灵活和可维护的Vue项目。
# 2. Webpack基础
在本章中,我们将介绍Webpack的基础知识和使用方法。
### 什么是Webpack
Webpack是一个现代的静态模块打包工具,它是Web应用程序的构建工具。通过Webpack,我们能够将项目中的各种资源如JS文件、CSS文件、图片等进行打包,并且可以根据需要进行优化和压缩。
### Webpack的核心概念和工作原理
Webpack的核心概念包括入口(entry)、输出(output)、加载器(loader)和插件(plugins)。入口指定了Webpack开始构建的模块,输出指定了构建后的文件生成的位置和命名规则。加载器和插件可以对模块进行处理和优化,例如将ES6语法转换为ES5、压缩代码、提取CSS等。
Webpack的工作原理是通过依赖图来分析和构建项目的模块。在入口文件中,Webpack会递归地分析每个模块的依赖关系,然后根据配置进行加载和处理,最终生成一个或多个打包后的文件。
### 安装和配置Webpack
首先,我们需要全局安装Webpack。打开终端并执行以下命令:
```shell
npm install webpack webpack-cli -g
```
接下来,我们可以在项目目录中,使用npm初始化一个新的项目,并安装Webpack作为开发依赖:
```shell
npm init -y
npm install webpack webpack-cli --save-dev
```
安装完成后,我们可以创建一个Webpack的配置文件`webpack.config.js`,并进行基本的配置。以下是一个简单的示例:
```javascript
const path = require('path');
module.exports = {
entry: './src/index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js',
},
};
```
在配置文件中,我们指定了入口文件为`./src/index.js`,输出文件名为`bundle.js`,并将输出文件放置在`dist`目录中。
现在,我们可以通过执行`webpack`命令进行构建,Webpack会根据配置文件进行打包,并将结果文件生成在指定的输出目录中。
```shell
webpack
```
以上就是Webpack的基础介绍和配置方法。接下来,我们将继续学习Vue的基础知识。
# 3. Vue基础
Vue是一款用于构建用户界面的渐进式JavaScript框架。它的核心思想是通过数据驱动DOM的方式来构建交互式的Web应用程序。Vue具有以下核心概念和基本用法:
- #### 数据绑定
Vue使用双向数据绑定来实现数据和视图之间的自动同步。可以通过在HTML模板中使用`{{}}`语法将数据绑定到DOM,并且当数据改变时,DOM会自动更新。
```html
<div id="app">
<p>{{ message }}</p>
</div>
<script>
var app = new Vue({
el: '#app',
data: {
message: 'Hello, Vue!'
}
});
</script>
```
以上代码定义了一个`message`属性,并将其绑定到`<p>`标签中。当`message`属性的值改变时,`<p>`标签中的文本也会相应地更新。
- #### 指令
指令是Vue提供的一种声明式的语法,用于在DOM上添加交互行为或响应式效果。常用的指令有`v-model`、`v-bind`和`v-for`等。
```html
<div id="app">
<input v-model="message">
<p v-bind:title="message">{{ message }}</p>
<ul>
<li v-for="item in list">{{ item }}</li>
</ul>
</div>
<script>
var app = new Vue({
el: '#app',
data: {
message: 'Hello, Vue!',
list: ['item1', 'item2', 'item3']
}
});
</script>
```
上述代码中,`v-model`将`message`属性与`<input>`标签的值进行双向绑定,`v-bind`将`message`属性的值作为`<p>`标签的`title`属性,并且`v-for`循环遍历`list`属性生成一个列表。
- #### 组件化
Vue允许通过组件的方式来封装可复用的代码块,这样可以更好地组织和管理代码。组件可以接受参数,定义方法和样式,并且可以通过事件和属性进行交互。
```html
<div id="app">
<my-component></my-component>
</div>
<script>
Vue.component('my-component', {
template: '<div>{{ message }}</div>',
data: function() {
return {
message: 'Hello, Component!'
}
}
});
var app = new Vue({
el: '#app'
});
</script>
```
上述代码定义了一个名为`my-component`的组件,它的模板中显示了一个`message`属性的值。在`<div id="app">`中使用`<my-component>`标签来引入和使用这个组件。
以上是Vue的基本概念和用法,通过学习和实践这些知识,您可以开始构建优雅的Vue项目。
# 4. Webpack和Vue的集成
Webpack和Vue是目前前端开发中非常流行的工具和框架,它们可以很好地配合使用来构建现代化的Vue项目。在本章中,我们将学习如何将Webpack和Vue集成在一起,并搭建起Vue项目的基本目录结构。
### 在Webpack中使用Vue
首先,我们需要在Webpack中安装并配置Vue的相关Loader和插件。Vue项目通常需要使用vue-loader来解析Vue组件,并将其转换为浏览器可以识别的JavaScript代码。同时,我们还需要安装并配置Vue的相关插件,如VueRouter、VueX等,以满足项目的需要。
```javascript
// webpack.config.js
module.exports = {
// ...
module: {
rules: [
// ...
{
test: /\.vue$/,
loader: 'vue-loader'
},
// ...
]
},
resolve: {
// ...
extensions: ['.js', '.vue'],
alias: {
// ...
'vue$': 'vue/dist/vue.esm.js'
}
},
// ...
}
```
### Vue-loader和Vue插件的配置
除了安装和配置vue-loader之外,我们还需要安装和配置Vue的相关插件。例如,如果需要在项目中使用VueRouter来实现前端路由,我们需要先安装VueRouter,并在Vue实例中注册它。
```javascript
// main.js
import Vue from 'vue'
import VueRouter from 'vue-router'
import App from './App.vue'
Vue.use(VueRouter)
const router = new VueRouter({
// ...
})
new Vue({
router,
render: h => h(App)
}).$mount('#app')
```
### 搭建Vue项目的基本目录结构
在搭建Vue项目时,合理的目录结构可以帮助我们更好地管理和组织代码。常见的Vue项目目录结构如下:
```
├── src
│ ├── assets // 静态资源文件夹(图片、样式等)
│ ├── components // Vue组件文件夹
│ ├── views // 页面级别组件文件夹
│ ├── router // 路由配置文件夹
│ ├── store // 状态管理文件夹(如VueX)
│ └── main.js // 项目入口文件
└── dist // 打包后的代码输出文件夹
```
以上是一个简单的Vue项目的基本目录结构,可以根据实际项目需求进行调整和扩展。
本章内容介绍了如何在Webpack中使用Vue以及配置Vue-loader和Vue插件,同时还介绍了搭建Vue项目的基本目录结构。下一章我们将学习如何优化Vue项目的构建。
# 5. 优化Vue项目的构建
在这一章节中,我们将讨论如何优化Vue项目的构建,包括代码分割和动态导入、压缩和混淆代码、以及处理图片、字体和样式等方面的优化。另外,我们还会介绍如何管理环境变量,以便在不同的环境下进行配置。
### 代码分割和动态导入
#### 代码分割
在大型Vue项目中,为了提高页面加载速度,我们通常会将代码拆分成多个小块,然后按需加载。Webpack提供了代码分割的功能,通过`import()`动态导入模块,实现按需加载。
```javascript
// 原始代码
import Vue from 'vue';
import App from './App.vue';
// 代码分割
const Foo = () => import('./Foo.vue');
const Bar = () => import('./Bar.vue');
```
#### 动态导入
动态导入 (Dynamic Import) 是 ECMAScript 提案,通过 `import()` 函数可以异步加载模块,实现动态导入。在 Vue 项目中,我们可以利用动态导入来优化页面加载速度。
```javascript
// 动态导入组件
const Foo = () => import('./Foo.vue');
const Bar = () => import('./Bar.vue');
```
### 压缩和混淆代码
在构建Vue项目时,我们通常会对代码进行压缩和混淆,以减小文件体积并提高加载速度。
#### 使用UglifyJsPlugin压缩代码
在 webpack 的配置中,我们可以使用 UglifyJsPlugin 来压缩代码。
```javascript
const UglifyJsPlugin = require('uglifyjs-webpack-plugin');
module.exports = {
//...其他配置
plugins: [
new UglifyJsPlugin({
//...UglifyJsPlugin 配置
})
]
};
```
#### 使用babel-minify-webpack-plugin混淆代码
除了压缩代码,我们还可以使用 babel-minify-webpack-plugin 这样的工具来混淆代码,提高代码的安全性。
```javascript
const MinifyPlugin = require('babel-minify-webpack-plugin');
module.exports = {
//...其他配置
plugins: [
new MinifyPlugin({
//...MinifyPlugin 配置
})
]
};
```
### 图片、字体和样式的处理
#### 处理图片和字体
在 Vue 项目中,我们可以使用 file-loader 和 url-loader 来处理图片和字体文件,让它们能够被正确加载并且优化加载速度。
```javascript
module.exports = {
//...其他配置
module: {
rules: [
{
test: /\.(png|jpe?g|gif|svg)(\?.*)?$/,
use: {
loader: 'url-loader',
options: {
limit: 10000,
name: 'img/[name].[hash:7].[ext]'
}
},
{
test: /\.(woff2?|eot|ttf|otf)(\?.*)?$/,
use: {
loader: 'url-loader',
options: {
limit: 10000,
name: 'fonts/[name].[hash:7].[ext]'
}
}
]
}
};
```
#### 处理样式
对于样式文件,我们可以使用 css-loader 和 style-loader 来处理 CSS 文件,并使用 postcss-loader 实现自动添加浏览器前缀等功能。
```javascript
module.exports = {
//...其他配置
module: {
rules: [
{
test: /\.css$/,
use: ['style-loader', 'css-loader', 'postcss-loader']
}
]
}
};
```
### 环境变量的管理
在不同的环境中,我们可能需要配置不同的变量,例如开发环境和生产环境。Vue 项目中,我们可以通过环境文件来管理这些变量。
#### 使用.env文件管理环境变量
在 Vue 项目中,我们可以使用`.env`文件来管理环境变量。
```plaintext
# .env.development
VUE_APP_BASE_URL='/api'
# .env.production
VUE_APP_BASE_URL='https://example.com/api'
```
然后在代码中,我们可以通过`process.env.VUE_APP_BASE_URL`来访问这些环境变量。
通过以上优化技巧,我们可以更好地构建和优化 Vue 项目,提供更好的用户体验。
在本章节中,我们详细介绍了代码分割和动态导入、压缩和混淆代码、图片、字体和样式的处理,以及环境变量的管理。这些优化技巧能够帮助我们构建更高效、更优雅的 Vue 项目。
# 6. 打包和部署Vue项目
在开发和完善Vue项目之后,我们需要将其打包并部署到服务器上供用户访问。本章节将介绍如何进行线上环境的打包配置,以及如何将Vue项目部署到服务器上的步骤。同时,我们还将探讨预渲染和SSR(服务器端渲染)的实践,以提升项目的性能和用户体验。
### 6.1 线上环境打包配置
在进行线上环境打包之前,我们需要对Webpack的配置进行调整,以使项目在生产环境下运行更加高效和稳定。
- **优化打包结果**:通过使用`MiniCssExtractPlugin`插件提取CSS样式文件,使用`UglifyJsPlugin`插件进行代码的压缩和混淆,以减小打包后文件的体积,并提升页面加载速度。
- **处理静态资源**:使用`url-loader`和`file-loader`处理图片、字体等静态资源,通过设置较小的`limit`值,将较小的资源转换为DataURL,减少HTTP请求数,提升加载速度。
- **设置缓存策略**:通过给打包后的文件名称添加hash值,避免浏览器缓存旧的文件版本,确保用户能够加载到最新的资源文件。
- **配置CDN加速**:将一些长时间不会变动的第三方库资源通过配置CDN的方式加载,提升用户的访问速度和体验。
下面是一个示例的生产环境配置文件`webpack.prod.js`:
```javascript
const path = require('path');
const webpack = require('webpack');
const MiniCssExtractPlugin = require('mini-css-extract-plugin');
const UglifyJsPlugin = require('uglifyjs-webpack-plugin');
module.exports = {
mode: 'production',
devtool: 'source-map',
output: {
filename: 'bundle.[contenthash].js',
path: path.resolve(__dirname, 'dist'),
publicPath: '/'
},
optimization: {
minimizer: [new UglifyJsPlugin({
sourceMap: true,
uglifyOptions: {
compress: {
warnings: false
},
output: {
comments: false
}
}
})]
},
module: {
rules: [
{
test: /\.css$/,
use: [MiniCssExtractPlugin.loader, 'css-loader']
},
{
test: /\.(png|jpe?g|gif|svg|eot|ttf|woff|woff2)$/,
use: [{
loader: 'url-loader',
options: {
limit: 8192,
name: '[name].[contenthash].[ext]',
outputPath: 'assets/',
publicPath: '/assets/'
}
}]
}
]
},
plugins: [
new MiniCssExtractPlugin({
filename: 'styles.[contenthash].css'
}),
new webpack.DefinePlugin({
'process.env.NODE_ENV': JSON.stringify('production')
})
]
};
```
在打包之前,我们可以使用`webpack-merge`工具来合并通用配置文件和生产环境配置文件,以避免重复编写相同的配置。
### 6.2 部署到服务器的步骤
当我们完成了项目的打包配置之后,接下来就是将打包后的文件部署到服务器上,以供用户访问。
1. **上传文件到服务器**:将打包后的`dist`文件夹中的所有文件上传到服务器的指定目录中。
2. **安装所需依赖**:在服务器上安装所需的运行环境,如Node.js等。
3. **启动服务器**:通过运行Node.js的服务器程序,如Express等,来启动服务器。
4. **配置域名和端口**:根据需要,设置服务器的域名和端口号,通过访问相应的URL来访问我们部署的Vue项目。
5. **持久化运行**:将服务器程序设置为持久化运行,以确保项目能够在服务器上持续运行。
### 6.3 预渲染和SSR的实践
除了将Vue项目打包并部署到服务器上,我们还可以使用预渲染和SSR来进一步优化项目的性能和用户体验。
- **预渲染**:通过预先将部分页面在构建时生成静态HTML文件的方式,让用户在访问这些页面时能够更快地看到内容,提升页面的渲染速度。
- **SSR**:服务器端渲染将Vue组件在服务器端预先渲染成HTML字符串然后发送给浏览器,以便更快速地呈现页面内容,提升首屏加载速度和SEO优化效果。
根据项目的具体需求,我们可以选择其中一种或两种方式,来进一步优化和改进我们的Vue项目。
总结:
在本章节中,我们学习了如何配置线上环境的Webpack打包和部署Vue项目到服务器的步骤,并介绍了预渲染和SSR的实践方法。通过这些技巧,我们可以更好地优化Vue项目的构建和性能,提升用户访问体验。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏讲解了如何使用Webpack构建前端项目的脚手架。专栏首先介绍了Webpack的基础知识,并带领读者搭建了基础的Webpack配置。然后详细介绍了Webpack的加载器和插件,以提升开发效率。接着深入解析了Webpack的打包原理和优化策略,让读者更好地优化项目性能。此外,还探讨了Webpack与其他技术的结合,如与ES6模块化、React、Vue、TypeScript、CSS预处理器等的配合使用,以及与静态资源管理、代码质量管理、单元测试、自动化部署、移动端适配、服务端渲染、PWA、性能监控与调优、国际化等的应用。通过阅读本专栏,读者将掌握Webpack的高级配置技巧,并可以构建出优雅、高效、安全、性能优化的前端应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【电子打印小票的前端实现】:用Electron和Vue实现无缝打印

# 摘要
电子打印小票作为商业交易中不可或缺的一部分,其需求分析和实现对于提升用户体验和商业效率具有重要意义。本文首先介绍了电子打印小票的概念,接着深入探讨了Electron和Vue.js两种前端技术的基础知识及其优势,阐述了如何将这两者结合,以实现高效、响应
【EPLAN Fluid精通秘籍】:基础到高级技巧全覆盖,助你成为行业专家
# 摘要
EPLAN Fluid是针对工程设计的专业软件,旨在提高管道和仪表图(P&ID)的设计效率与质量。本文首先介绍了EPLAN Fluid的基本概念、安装流程以及用户界面的熟悉方法。随后,详细阐述了软件的基本操作,包括绘图工具的使用、项目结构管理以及自动化功能的应用。进一步地,本文通过实例分析,探讨了在复杂项目中如何进行规划实施、设计技巧的运用和数据的高效管理。此外,文章还涉及了高级优化技巧,包括性能调优和高级项目管理策略。最后,本文展望了EPLAN Fluid的未来版本特性及在智能制造中的应用趋势,为工业设计人员提供了全面的技术指南和未来发展方向。
# 关键字
EPLAN Fluid
小红书企业号认证优势大公开:为何认证是品牌成功的关键一步
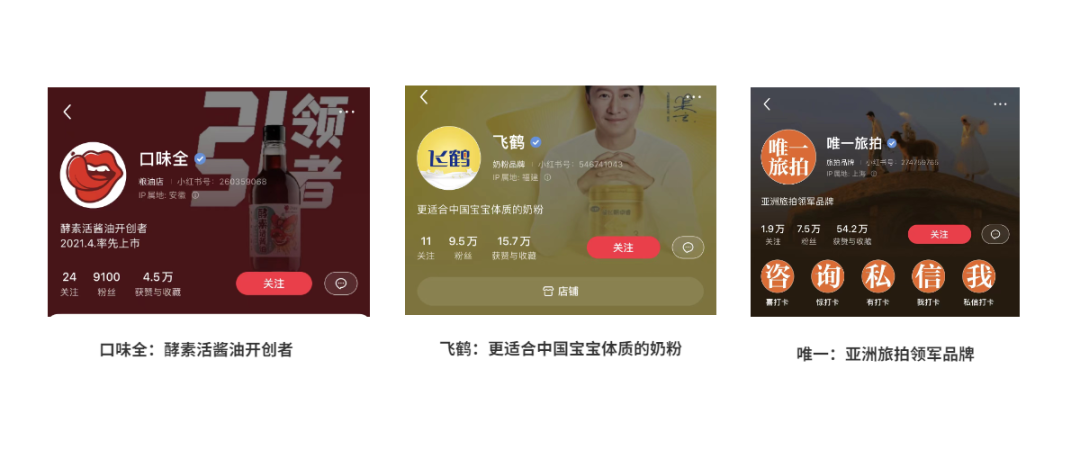
# 摘要
小红书企业号认证是品牌在小红书平台上的官方标识,代表了企业的权威性和可信度。本文概述了小红书企业号的市场地位和用户画像,分析了企业号与个人账号的区别及其市场意义,并详细解读了认证过程与要求。文章进一步探讨了企业号认证带来的优势,包括提升品牌权威性、拓展功能权限以及商业合作的机会。接着,文章提出了企业号认证后的运营策略,如内容营销、用户互动和数据分析优化。通过对成功认证案例的研究,评估
【用例图与图书馆管理系统的用户交互】:打造直观界面的关键策略
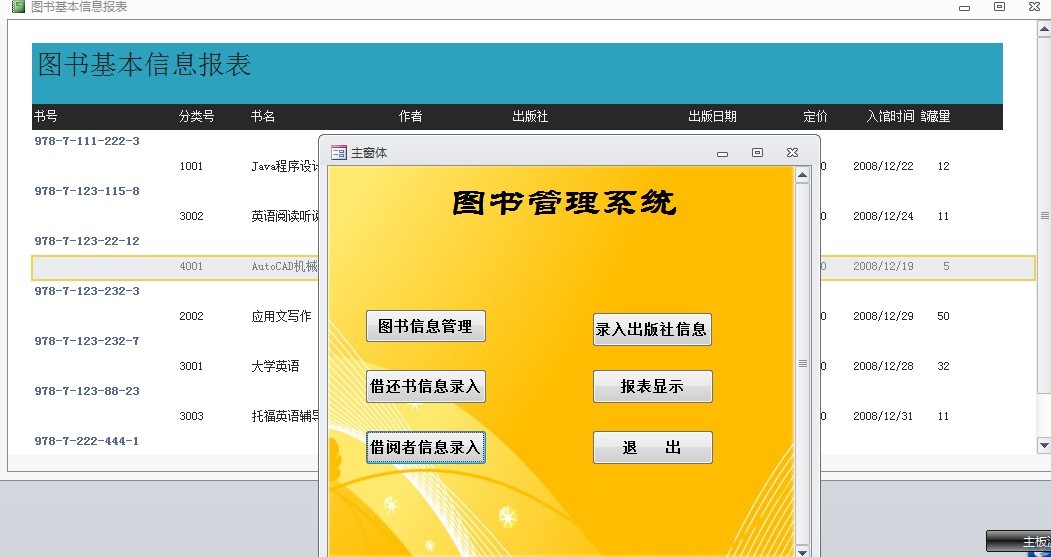
# 摘要
本文旨在探讨用例图在图书馆管理系统设计中的应用,从基础理论到实际应用进行了全面分析。第一章概述了用例图与图书馆管理系统的相关性。第二章详细介绍了用例图的理论基础、绘制方法及优化过程,强调了其在系统分析和设计中的作用。第三章则集中于用户交互设计原则和实现,包括用户界面布局、交互流程设计以及反馈机制。第四章具体阐述了用例图在功能模块划分、用户体验设计以及系统测试中的应用。
FANUC面板按键深度解析:揭秘操作效率提升的关键操作
# 摘要
FANUC面板按键作为工业控制中常见的输入设备,其功能的概述与设计原理对于提高操作效率、确保系统可靠性及用户体验至关重要。本文系统地介绍了FANUC面板按键的设计原理,包括按键布局的人机工程学应用、触觉反馈机制以及电气与机械结构设计。同时,本文也探讨了按键操作技巧、自定义功能设置以及错误处理和维护策略。在应用层面,文章分析了面板按键在教育培训、自动化集成和特殊行业中的优化策略。最后,本文展望了按键未来发展趋势,如人工智能、机器学习、可穿戴技术及远程操作的整合,以及通过案例研究和实战演练来提升实际操作效率和性能调优。
# 关键字
FANUC面板按键;人机工程学;触觉反馈;电气机械结构
华为SUN2000-(33KTL, 40KTL) MODBUS接口安全性分析与防护

# 摘要
本文深入探讨了MODBUS协议在现代工业通信中的基础及应用背景,重点关注SUN2000-(33KTL, 40KTL)设备的MODBUS接口及其安全性。文章首先介绍了MODBUS协议的基础知识和安全性理论,包括安全机制、常见安全威胁、攻击类型、加密技术和认证方法。接着,文章转入实践,分析了部署在SUN2
【高速数据传输】:PRBS的优势与5个应对策略

# 摘要
本文旨在探讨高速数据传输的背景、理论基础、常见问题及其实践策略。首先介绍了高速数据传输的基本概念和背景,然后详细分析了伪随机二进制序列(PRBS)的理论基础及其在数据传输中的优势。文中还探讨了在高速数据传输过程中可能遇到的问题,例如信号衰减、干扰、传输延迟、带宽限制和同步问题,并提供了相应的解决方案。接着,文章提出了一系列实际应用策略,包括PRBS测试、信号处理技术和高效编码技术。最后,通过案例分析,本文展示了PRBS在
【GC4663传感器应用:提升系统性能的秘诀】:案例分析与实战技巧
# 摘要
GC4663传感器是一种先进的检测设备,广泛应用于工业自动化和科研实验领域。本文首先概述了GC4663传感器的基本情况,随后详细介绍了其理论基础,包括工作原理、技术参数、数据采集机制、性能指标如精度、分辨率、响应时间和稳定性。接着,本文分析了GC4663传感器在系统性能优化中的关键作用,包括性能监控、数据处理、系统调优策略。此外,本文还探讨了GC4663传感器在硬件集成、软件接口编程、维护和故障排除方面的
NUMECA并行计算工程应用案例:揭秘性能优化的幕后英雄
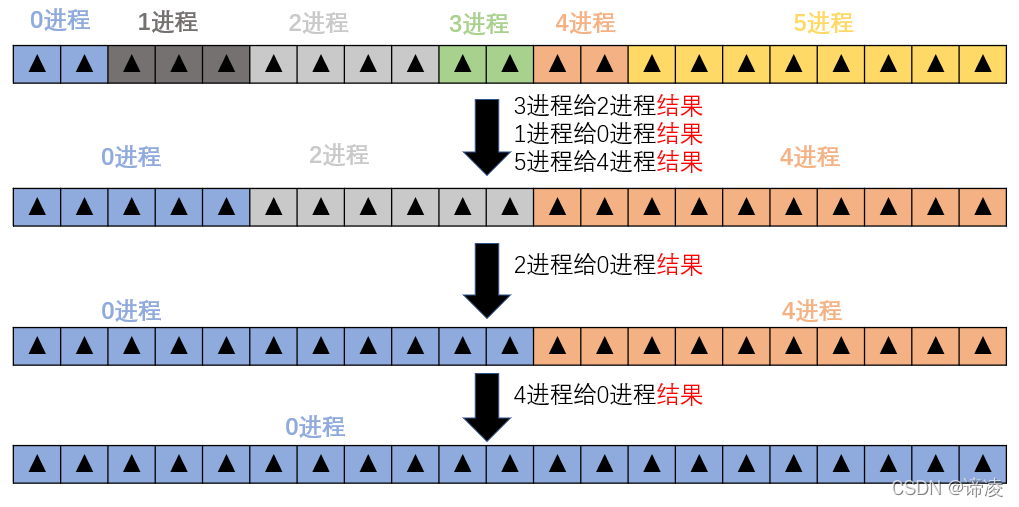
# 摘要
本文全面介绍NUMECA软件在并行计算领域的应用与实践,涵盖并行计算基础理论、软件架构、性能优化理论基础、实践操作、案例工程应用分析,以及并行计算在行业中的应用前景和知识拓展。通过探
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )