Webpack与代码质量管理:集成ESLint与Prettier
发布时间: 2023-12-19 10:49:19 阅读量: 43 订阅数: 40 

eslint+prettier统一代码风格的实现方法
# 章节一:Webpack简介与概述
## 1.1 Webpack的作用与原理
Webpack是一个现代JavaScript应用程序的静态模块打包工具。它主要的作用是将前端项目中的各种资源(js、css、图片等)视作模块,然后根据模块之间的依赖关系进行静态分析,最后打包成适合浏览器环境执行的静态资源。Webpack的原理是通过入口文件,分析模块间的依赖关系,将代码转换成浏览器可以直接执行的代码。
在项目中,我们可以通过配置Webpack的入口、出口、loader、插件等信息来定制化打包过程,实现各种功能,比如代码分割、懒加载、压缩混淆等。
## 1.2 如何集成Webpack到项目中
要集成Webpack到项目中,首先需要安装Webpack及其相关的loader和plugin,然后创建一个`webpack.config.js`文件,在其中配置入口、出口、loader、plugin等信息。接着可以通过命令行工具或者配置package.json中的scripts来执行打包命令。
```javascript
// webpack.config.js
const path = require('path');
module.exports = {
entry: './src/index.js', // 入口文件
output: {
path: path.resolve(__dirname, 'dist'), // 出口目录
filename: 'bundle.js' // 出口文件名
},
module: {
rules: [
{
test: /\.js$/, // 匹配规则
exclude: /node_modules/,
use: {
loader: 'babel-loader' // 使用的loader
}
}
]
},
plugins: [
new HtmlWebpackPlugin({ // 使用的插件
template: './src/index.html'
})
]
};
```
## 1.3 Webpack与代码质量管理的关系
### 章节二:ESLint简介与配置
ESLint是一个用于识别和报告JavaScript代码中的模式的工具,其目标是保持代码的一致性和避免错误。在本章节中,我们将介绍ESLint的基本概念,并讨论如何在项目中配置和集成ESLint。
#### 2.1 什么是ESLint以及它的作用
ESLint是一个静态代码分析工具,用于识别ECMAScript/JavaScript代码中的模式。它可以帮助开发人员发现代码中的问题,并确保代码风格的一致性。ESLint具有可扩展性,因此可以根据团队的需求定义自定义的规则。
#### 2.2 如何在项目中集成ESLint
在项目中集成ESLint非常简单,可以使用npm或yarn来安装ESLint,并通过一些简单的配置来启用。
```bash
# 使用 npm 安装 ESLint
npm install eslint --save-dev
# 使用 yarn 安装 ESLint
yarn add eslint --dev
```
#### 2.3 配置ESLint规则与常见配置示例
在项目根目录下创建`.eslintrc.js`文件,用于配置ESLint的规则和选项。以下是一个常见的ESLint配置示例:
```javascript
module.exports = {
env: {
browser: true,
node: true,
es6: true
},
extends: ["eslint:recommended", "plugin:react/recommended"],
parserOptions: {
ecmaFeatures: {
jsx: true
},
ecmaVersion: 2018,
sourceType: "module"
},
plugins: ["react"],
rules: {
"react/prop-types": 0,
"no-unused-vars": 1,
"no-console": 1
}
};
```
以上示例中的配置包括定义了代码运行环境、使用了推荐的规则集合、指定了解析器选项,以及定义了一些自定义规则。
### 章节三:Prettier简介与配置
Prettier是一个流行的代码格式化工具,它可以帮助开发人员统一项目中的代码风格,减少不必要的代码格式争论,提高团队的开发效率。
#### 3.1 Prettier的作用与特点
Prettier主要有以下几个特点:
- 自动化:Prettier能够自动格式化代码,无需手动调整代码风格。
- 一致性:通过Prettier,项目中的所有代码都将保持统一的风格,避免了不同开发人员之间的个人风格差异。
- 灵活性:Prettier支持自定义配置,可以根据项目需求进行定制化设置。
#### 3.2 如何在项目中集成Prettier
在项目中集成Prettier非常简单,首先我们需要在项目中安装Prettier:
```bash
npm install --save-dev prettier
```
接下来,我们可以在项目根目录下创建一个`.prettierrc`文件来配置Prettier的规则:
```json
{
"singleQuote": true,
"semi": false,
"tabWidth": 2
}
```
以上配置示例表示使用单引号,去掉末尾的分号,以及设置缩进为2个空格。
#### 3.3 配置Prettier规则与格式化选项
Prettier支持多种格式化选项,例如缩进大小、末尾分号等,可以根据具体需求进行配置。另外,还可以通过`.prettierignore`文件来指定不需要格式化的文件或目录,以避免不必要的影响。
## 章节四:集成ESLint与Prettier到Webpack
在这一部分,我们将学习如何将ESLint和Prettier集成到Webpack中,以确保代码质量和一致的代码风格。
### 4.1 集成ESLint到Webpack的步骤
集成ESLint到Webpack需要进行一些配置和安装。以下是详细的步骤:
#### 步骤一:安装依赖
首先,我们需要在项目中安装eslint和eslint-loader:
```bash
npm install eslint eslint-loader --save-dev
```
#### 步骤二:配置Webpack
接下来,我们需要在webpack.config.js中配置eslint-loader。示例配置如下:
```javascript
// webpack.config.js
const path = require('path');
module.exports = {
entry: './src/index.js',
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'bundle.js',
},
module: {
rules: [
{
test: /\.js$/,
exclude: /node_modules/,
use: ['babel-loader', 'eslint-loader'],
},
],
},
};
```
#### 步骤三:创建ESLint配置文件
在项目根目录下创建.eslintrc文件,并定义ESLint规则。可以使用现有的规则集,也可以自定义规则。
### 4.2 集成Prettier到Webpack的步骤
集成Prettier到Webpack也需要进行类似的配置和安装。
#### 步骤一:安装依赖
首先,我们需要在项目中安装prettier和prettier-loader:
```bash
npm install prettier prettier-loader --save-dev
```
#### 步骤二:配置Webpack
在webpack.config.js中配置prettier-loader。示例配置如下:
```javascript
// webpack.config.js
module.exports = {
// ... (其他配置)
module: {
rules: [
{
test: /\.js$/,
exclude: /node_modules/,
use: ['babel-loader', 'prettier-loader'],
},
],
},
};
```
#### 步骤三:创建Prettier配置文件
在项目根目录下创建.prettierrc文件,并定义Prettier的格式化选项。
### 4.3 Webpack中ESLint与Prettier的使用示例
现在,我们已经成功将ESLint和Prettier集成到Webpack中。在实际开发中,我们可以通过这些工具来提高代码质量,并确保一致的代码风格。
### 5. 章节五:代码质量管理与团队协作
在团队协作中,代码质量管理是至关重要的一环。ESLint与Prettier的集成不仅可以帮助团队统一代码风格,提升代码质量,还可以在团队协作中发挥重要作用。
#### 5.1 通过ESLint与Prettier提升团队协作效率
ESLint与Prettier的集成,可以帮助团队成员在编写代码时自动进行代码风格检查与格式化,避免了因为个人习惯不同而导致的代码格式不一致的问题。这不仅提升了团队协作的效率,还能使团队的代码更加统一,易于阅读与维护。
#### 5.2 代码质量管理与持续集成的关联
在持续集成(CI)中,代码质量管理是一个重要的环节。通过在代码提交时进行ESLint与Prettier的检查与格式化,可以确保代码的质量与一致性。这对于CI/CD流程的顺利进行非常重要,能够减少代码质量相关的问题,提高持续集成的效率。
#### 5.3 最佳实践与团队应用指南
针对不同团队的实际情况,可以制定最佳的ESLint与Prettier配置实践,并结合团队的实际情况给出应用指南。比如,可以定义一套团队内统一的ESLint规则与Prettier格式化选项,并制定团队成员遵守的统一规范,以确保代码质量管理与团队协作的顺利进行。
## 章节六:总结与展望
在本文中,我们深入探讨了Webpack与代码质量管理工具(ESLint与Prettier)的作用、原理以及如何集成到项目中。通过对这些工具的全面了解,我们可以更好地提升项目的代码质量,同时也改善团队协作效率。
### 6.1 对Webpack与代码质量管理的总结
通过本文的学习,我们了解到Webpack作为前端项目构建工具,能够高效管理模块依赖、优化资源、提升开发效率。同时,ESLint与Prettier作为代码质量管理工具,能够帮助团队规范代码风格、发现潜在问题并保持一致的代码风格。
结合Webpack与ESLint、Prettier,可以在项目中实现统一的代码风格和质量管理,为团队开发提供良好的基础设施和保障。
### 6.2 发展方向与未来趋势展望
随着前端技术的不断发展,Webpack在模块化、构建优化等方面将会有更多的创新和改进。同时,对于代码质量工具ESLint与Prettier来说,会更加智能化、定制化,能够更好地适应不同团队的需求。
未来,我们有理由相信,Webpack与代码质量管理将成为前端开发中不可或缺的重要环节,并在持续优化和发展中发挥更大的作用。
### 6.3 结语与致谢
通过本文的学习,我们深入了解了Webpack及其与代码质量管理工具的结合应用。希望本文能够为读者在项目开发中引入Webpack和代码质量管理工具提供一些帮助。
最后,感谢您的阅读与支持!

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏讲解了如何使用Webpack构建前端项目的脚手架。专栏首先介绍了Webpack的基础知识,并带领读者搭建了基础的Webpack配置。然后详细介绍了Webpack的加载器和插件,以提升开发效率。接着深入解析了Webpack的打包原理和优化策略,让读者更好地优化项目性能。此外,还探讨了Webpack与其他技术的结合,如与ES6模块化、React、Vue、TypeScript、CSS预处理器等的配合使用,以及与静态资源管理、代码质量管理、单元测试、自动化部署、移动端适配、服务端渲染、PWA、性能监控与调优、国际化等的应用。通过阅读本专栏,读者将掌握Webpack的高级配置技巧,并可以构建出优雅、高效、安全、性能优化的前端应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
HALCON基础教程:轻松掌握23.05版本HDevelop操作符(专家级指南)

# 摘要
本文全面介绍HALCON 23.05版本HDevelop环境及其图像处理、分析和识别技术。首先概述HDevelop开发环境的特点,然后深入探讨HALCON在图像处理领域的基础操作,如图像读取、显示、基本操作、形态学处理等。第三章聚焦于图像分析与识别技术,包括边缘和轮廓检测、图像分割与区域分析、特征提取与匹配。在第四章中,本文转向三维视觉处理,介绍三维
【浪潮英信NF5460M4安装完全指南】:新手也能轻松搞定
# 摘要
本文详细介绍了浪潮英信NF5460M4服务器的安装、配置、管理和性能优化过程。首先概述了服务器的基本信息和硬件安装步骤,包括准备工作、物理安装以及初步硬件设置。接着深入讨论了操作系统的选择、安装流程以及基础系统配置和优化。此外,本文还包含了服务器管理与维护的最佳实践,如硬件监控、软件更新与补丁管理以及故障排除支持。最后,通过性能测试与优化建议章节,本文提供了测试工具介绍、性能调优实践和长期维护升级规划,旨在帮助用户最大化服务器性能并确保稳定运行。
# 关键字
服务器安装;操作系统配置;硬件监控;软件更新;性能测试;故障排除
参考资源链接:[浪潮英信NF5460M4服务器全面技术手
ACM动态规划专题:掌握5大策略与50道实战演练题
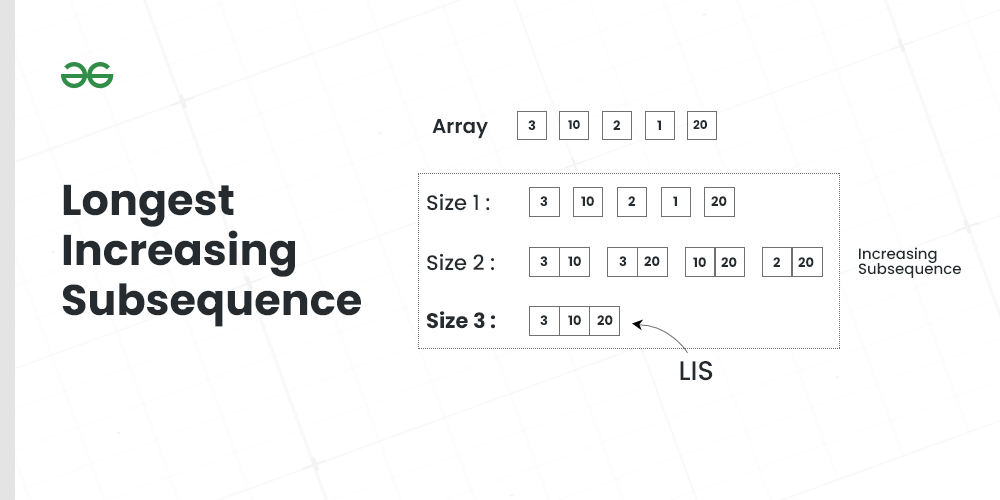
# 摘要
动态规划是解决复杂优化问题的一种重要算法思想,涵盖了基础理论、核心策略以及应用拓展的全面分析。本文首先介绍了ACM中动态规划的基础理论,并详细解读了动态规划的核心策略,包括状态定义、状态转移方程、初始条件和边界处理、优化策略以及复杂度分析。接着,通过实战演练的方式,对不同难度等级的动态规划题目进行了深入的分析与解答,涵盖了背包问题、数字三角形、石子合并、最长公共子序列等经典问题
Broyden方法与牛顿法对决:非线性方程组求解的终极选择

# 摘要
本文旨在全面探讨非线性方程组求解的多种方法及其应用。首先介绍了非线性方程组求解的基础知识和牛顿法的理论与实践,接着
【深度剖析】:掌握WindLX:完整用户界面与功能解读,打造个性化工作空间
# 摘要
本文全面介绍了WindLX用户界面的掌握方法、核心与高级功能详解、个性化工作空间的打造技巧以及深入的应用案例研究。通过对界面定制能力、应用管理、个性化设置等核心功能的详细解读,以及窗口管理、集成开发环境支持和多显示器设置等高级功能的探索,文章为用户提供了全面的WindLX使用指导。同时,本文还提供了实际工作
【数学建模竞赛速成攻略】:6个必备技巧助你一臂之力
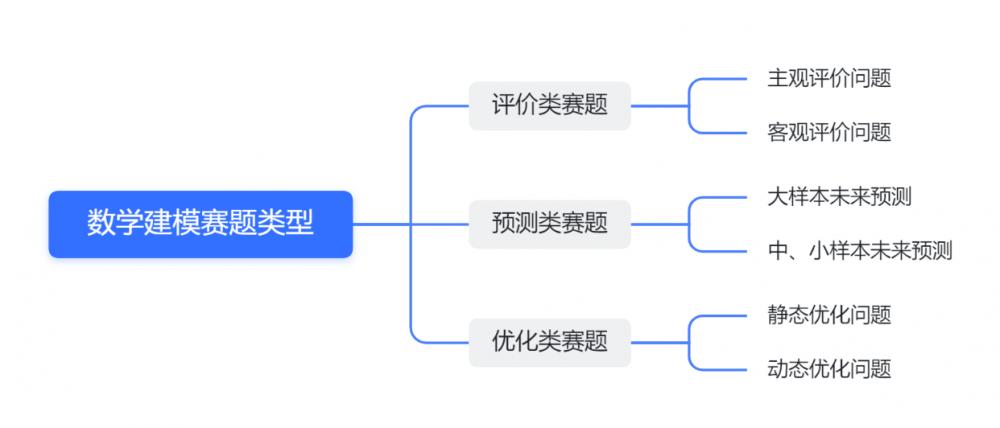
# 摘要
数学建模竞赛是一项综合性强、应用广泛的学术活动,旨在解决实际问题。本文旨在全面介绍数学建模竞赛的全过程,包括赛前准备、基本理论和方法的学习、实战演练、策略和技巧的掌握以及赛后分析与反思。文章详细阐述了竞赛规则、团队组建、文献收集、模型构建、论文撰写等关键环节,并对历届竞赛题目进行了深入分析。此外,本文还强调了时间管理、团队协作、压力管理等关键策略,以及对个人和团队成长的反思,以及对
【SEED-XDS200仿真器使用手册】:嵌入式开发新手的7日速成指南
# 摘要
SEED-XDS200仿真器作为一款专业的嵌入式开发工具,其概述、理论基础、使用技巧、实践应用以及进阶应用构成了本文的核心内容。文章首先介绍了SEED-XDS200仿真器的硬件组成及其在嵌入式系统开发中的重要性。接着,详细阐述了如何搭建开发环境,掌握基础操作以及探索高级功能。本文还通过具体项目实战,探讨了如何利用仿真器进行入门级应用开发、系统性能调优及故障排除。最后,文章深入分析了仿真器与目标系统的交互,如何扩展第三方工具支持,以及推荐了学习资源,为嵌入式开发者提供了一条持续学习与成长的职业发展路径。整体而言,本文旨在为嵌入式开发者提供一份全面的SEED-XDS200仿真器使用指南。
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )