边界标记技术深度解析:PM_DS18与竞品的10个关键差异
发布时间: 2024-11-30 06:02:19 阅读量: 10 订阅数: 16 

参考资源链接:[Converge仿真软件初学者教程:2.4版本操作指南](https://wenku.csdn.net/doc/sbiff4a7ma?spm=1055.2635.3001.10343)
# 1. 边界标记技术概述
## 1.1 边界标记技术的定义与作用
边界标记技术是一种用于数据处理和信息管理的高级技术,它通过在数据边界处添加特殊的标记,以增强数据的可读性和可追踪性。这种技术对于提高数据分析的准确性、加强数据安全、以及促进数据交换和集成尤为关键。
## 1.2 边界标记技术的历史与发展
边界标记技术起源于早期的数据处理需求,随着时间的推移和信息技术的进步,该技术已经经历了从简单的数据分割到智能化数据识别的演变。随着大数据和人工智能时代的到来,边界标记技术在性能和准确性上都有了显著提升,使其在多种应用场景中显得不可或缺。
通过这一章节的阅读,读者应能对边界标记技术有一个基本的理解,并认识到它在现代信息技术中的重要性。下一章将深入探讨PM_DS18技术的具体原理及其架构设计。
# 2. PM_DS18技术原理
## 2.1 标记技术的理论基础
### 2.1.1 边界标记技术的定义与作用
边界标记技术,也称作标记与探测技术,是一种通过在数据流中嵌入特定的标记(tags),进而实现对数据流状态、流量、内容等属性进行监控、追踪、管理和控制的技术。这些标记可以是简单的元数据,也可以是复杂的数据结构,其核心在于为数据赋予额外的语义信息。
在信息流动日益复杂、网络攻击愈发频繁的现代IT环境中,边界标记技术的作用不容小觑。它能帮助管理人员:
- 有效地监控网络流量,实时跟踪信息的流动路径;
- 防止数据泄露,通过标记追踪数据访问和传输过程;
- 优化数据处理流程,提高数据使用效率;
- 实现精准的网络流量管理和控制;
- 在出现安全事件时快速定位问题源头。
### 2.1.2 边界标记技术的历史与发展
边界标记技术的起源可追溯到早期的网络安全研究,其核心思想是利用标记机制来维护和控制数据流的边界。随着网络技术的发展,边界标记技术也经历了几个重要的发展阶段:
1. **标记技术的初期应用**:在早期网络中,标记技术主要用于区分服务(DiffServ)模型中不同类别的数据包。简单标记机制如IP优先级标记被用于区分网络流量的优先级。
2. **安全增强**:随着安全需求的提升,边界标记技术开始集成加密和身份验证机制,使得数据在传输过程中既被标记也能确保其安全。
3. **精细化管理**:进入云时代,边界标记技术发展成为可以支持精细化流量管理和策略控制的手段,使得网络管理者能够对复杂的流量模式做出快速响应。
4. **AI与自动化**:当下,边界标记技术与人工智能、机器学习技术的结合,使得标记可以自适应于复杂多变的网络环境,实现自动化智能控制。
## 2.2 PM_DS18的核心架构
### 2.2.1 系统架构的详细介绍
PM_DS18是一种先进的边界标记技术,其核心架构主要由以下几个部分组成:
- **标记引擎(Tagging Engine)**:负责在数据流中生成和插入标记,这是整个系统的核心功能模块。
- **标记解析器(Tag Analyzer)**:用于解析数据流中的标记,提取关键信息,为系统的决策提供依据。
- **策略管理器(Policy Manager)**:根据预设策略与标记解析结果,控制数据流的行为。
- **安全模块(Security Module)**:负责标记的安全性,防止篡改和伪造。
- **应用接口(API Layer)**:提供开发者和管理员与系统交互的接口。
### 2.2.2 核心算法与处理流程
PM_DS18的核心算法集中在其标记生成与解析过程中,涉及以下关键步骤:
1. **数据流捕获**:监控网络,捕获数据流。
2. **标记生成**:根据预设策略生成标记,嵌入到数据流中。
3. **标记传输**:数据流与标记一同在网络中传输。
4. **标记捕获与解析**:在指定的节点捕获标记,通过解析算法提取信息。
5. **策略决策与执行**:解析结果触发策略管理器决策,实现对数据流的控制。
处理流程的代码示例可能如下所示:
```python
def generate_tag(data_stream):
# 这里是一些生成标记的逻辑,可能涉及到哈希,加密等技术
tag = cryptographic_function(data_stream)
return tag
def parse_tag(tag):
# 解析标记并提取信息
info = extract_information_from_tag(tag)
return info
def policy_decision(info):
# 根据解析得到的信息做决策
decision = decision_making_process(info)
return decision
def main(data_stream):
tag = generate_tag(data_stream)
info = parse_tag(tag)
decision = policy_decision(info)
# 执行决策
execute_decision(decision)
```
这些步骤能够确保数据流在被标记、传输和解析的过程中,其完整性、机密性和可用性得到保障。
## 2.3 PM_DS18与其他标记技术的对比
### 2.3.1 对比分析的方法论
对比分析PM_DS18和其他标记技术时,需要基于一系列的定量和定性指标。这些指标可能包括:
- **性能指标**:延迟、吞吐量、处理速度等。
- **安全性指标**:抵抗攻击的能力,加密强度等。
- **功能性指标**:支持的标记类型,策略的复杂度和灵活性等。
- **兼容性**:与其他技术或系统的兼容程度。
- **可维护性**:系统升级、维护的难易程度。
### 2.3.2 基础功能的相似性与差异
在进行对比时,我们可以构建如下的表格,以展示不同标记技术间的相似性与差异。
| 功能特性 | PM_DS18 | 技术B | 技术C |
|-----------|---------|-------|-------|
| 性能 | 高吞吐量、低延迟 | 中等性能 | 较低性能 |
| 安全性 | 多层次加密,防篡改 | 基础加密 | 加密能力较弱 |
| 功能性 | 强大策略控制 | 简单控制 | 复杂策略支持 |
| 兼容性 | 良好的跨平台兼容 | 有限兼容 | 专有平台支持 |
| 可维护性 | 易于升级和维护 | 维护难度中等 | 维护难度高 |
通过表格,我们能够一

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**PM_DS18 边界标记:数据流管理的权威指南**
PM_DS18 边界标记是数据流管理领域的革命性技术。本专栏提供了一系列全面深入的文章,揭示了使用 PM_DS18 边界标记实现数据流管理成功的关键策略。从避免常见错误到优化系统性能,再到与其他技术的无缝对接,本专栏涵盖了各个方面。此外,本专栏还深入探讨了边界标记技术,分析了 PM_DS18 与竞品的差异,以及在实时系统和分布式系统中的应用案例。通过专家建议和深入分析,本专栏旨在帮助数据处理人员和工程师充分利用 PM_DS18 边界标记,构建高效、安全且可扩展的数据流管理解决方案。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
车载网络安全测试:CANoe软件防御与渗透实战指南
参考资源链接:[CANoe软件安装与驱动配置指南](https://wenku.csdn.net/doc/43g24n97ne?spm=1055.2635.3001.10343)
# 1. 车载网络安全概述
## 1.1 车联网安全的重要性
随着互联网技术与汽车行业融合的不断深入,车辆从独立的机械实体逐渐演变成互联的智能系统。车载网络安全关系到车辆数据的完整性、机密性和可用性,是防止未授权访问和网络攻击的关键。确保车载系统的安全性,可以防止数据泄露、控制系统被恶意操控,以及保护用户隐私。因此,车载网络安全对于现代汽车制造商和用户来说至关重要。
## 1.2 安全风险的多维挑战
车辆的网络连
3-matic 9.0案例集锦】:从实践经验中学习三维建模的顶级技巧
参考资源链接:[3-matic9.0中文操作手册:从输入到分析设计的全面指南](https://wenku.csdn.net/doc/2b3t01myrv?spm=1055.2635.3001.10343)
# 1. 3-matic 9.0软件概览
## 1.1 软件介绍
3-matic 9.0是一款先进的三维模型软件,广泛应用于工业设计、游戏开发、电影制作等领域。它提供了一系列的建模和优化工具,可以有效地处理复杂的三维模型,提高模型的质量和精度。
## 1.2 功能特点
该软件的主要功能包括基础建模、网格优化、拓扑优化以及与其他软件的协同工作等。3-matic 9.0的用户界面直观易用,
【生物信息学基因数据处理】:Kronecker积的应用探索
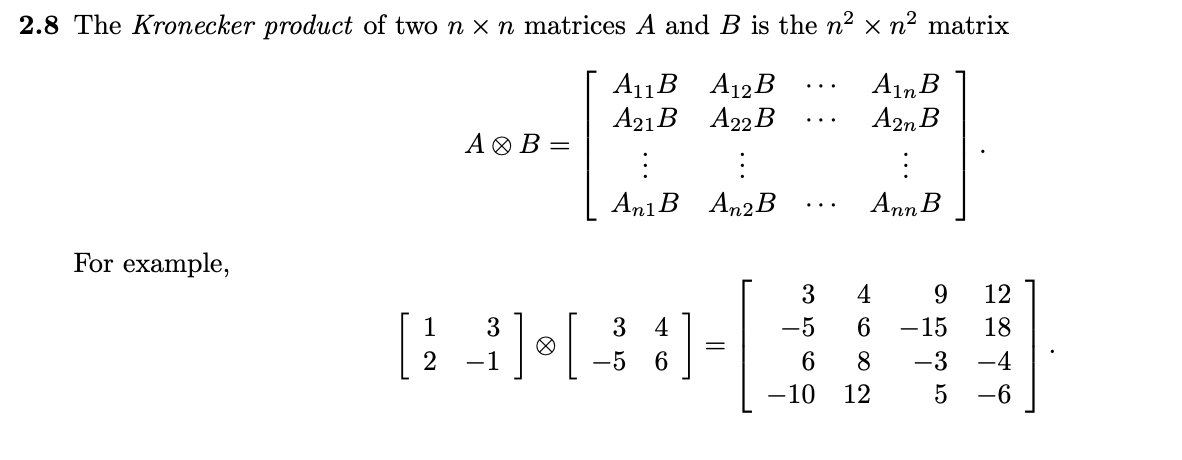
参考资源链接:[矩阵运算:Kronecker积的概念、性质与应用](https://wenku.csdn.net/doc/gja3cts6ed?spm=1055.2635.3001.10343)
# 1. 生物信息学中的Kronecker积概念介绍
## 1.1 Kronecker积的定义
在生物信息学中,Kronecker积(也称为直积)是一种矩阵
频谱资源管理优化:HackRF+One在频谱分配中的关键作用

参考资源链接:[HackRF One全方位指南:从入门到精通](https://wenku.csdn.net/doc/6401ace3cce7214c316ed839?spm=1055.2635.3001.10343)
# 1. 频谱资源管理概述
频谱资源是现代通信技术不可或缺的一部分
Paraview数据处理与分析流程:中文版完全指南

参考资源链接:[ParaView中文使用手册:从入门到进阶](https://wenku.csdn.net/doc/7okceubkfw?spm=1055.2635.3001.10343)
# 1. Paraview简介与安装配置
## 1.1 Paraview的基本概念
Paraview是一个开源的、跨平台的数据分析和可视化应用程序,广泛应用于科学研究和工程领域。它能够处理各种类型的数据,包括标量、向量、张量等
【HLW8110物联网桥梁】:构建万物互联的HLW8110应用案例

参考资源链接:[hlw8110.pdf](https://wenku.csdn.net/doc/645d8bd295996c03ac43432a?spm=1055.2635.3001.10343)
# 1. HLW8110物联网桥梁概述
## 1.1 物联网桥梁简介
HL
开发者必看!Codesys功能块加密:应对最大挑战的策略

参考资源链接:[Codesys平台之功能块加密与权限设置](https://wenku.csdn.net/doc/644b7c16ea0840391e559736?spm=1055.2635.3001.10343)
# 1. 功能块加密的基础知识
在现代IT和工业自动化领域,功能块加密已经成为保护知识产权和防止非法复制的重要手段。功能块(Fun
【跨平台协作技巧】:在不同EDA工具间实现D触发器设计的有效协作
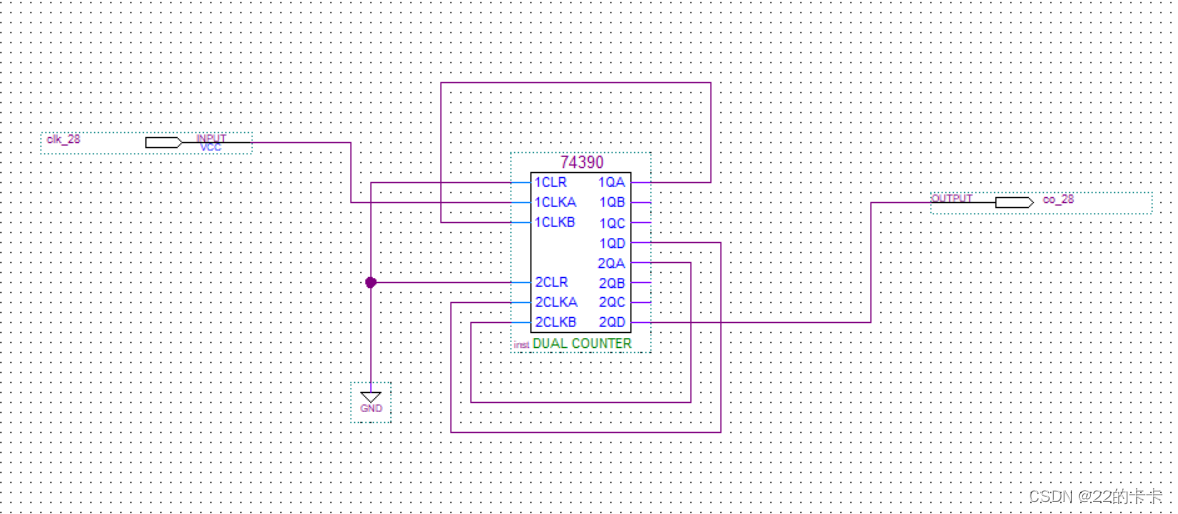
参考资源链接:[Multisim数电仿真:D触发器的功能与应用解析](https://wenku.csdn.net/doc/5wh647dd6h?spm=1055.2635.3001.10343)
# 1. 跨平台EDA工具协作概述
随着集成电路设计复杂性的增加,跨平台电子设计自动化(EDA)工具的协作变得日益重要。本章将概述EDA工具协作的基本概念,以及在现代设计环境中它们如何共同工作。我们将探讨跨平台
系统稳定性与内存安全:确保高可用性系统的内存管理策略

参考资源链接:[Net 内存溢出(System.OutOfMemoryException)的常见情况和处理方式总结](https://wenku.csdn.net/doc/6412b784be7fbd1778d4a95f?spm=1055.2635.3001.10343)
# 1. 内存管理基础与系统稳定性概述
内存管理是操作系统中的一个核心功能,它涉及到内存的分配、使用和回收等多个方面。良好的内存管
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )