使用Alertmanager实现Prometheus告警管理
发布时间: 2024-01-21 05:49:01 阅读量: 43 订阅数: 21 
# 1. 介绍Alertmanager和Prometheus
## 1.1 什么是Alertmanager?
Alertmanager是一个用于处理和路由来自Prometheus监控系统的警报的组件。它可以将警报路由到各种接收器,如电子邮件、PagerDuty、Slack等,并通过去重、分组和静默功能来确保及时且不重复地通知相关人员。
## 1.2 Prometheus与Alertmanager的关系
Prometheus是一款开源的监控和警报工具箱,它可以收集时间序列数据,并使用PromQL查询语言进行数据分析和警报规则定义。Alertmanager则是Prometheus生态系统中的一个重要组成部分,负责接收由Prometheus生成的警报,并进行处理和路由。
## 1.3 Alertmanager的优势和用途
Alertmanager通过强大的告警路由规则和灵活的通知机制,可以帮助用户及时发现系统中的问题并进行相应的处理。其优势在于灵活的配置、丰富的通知方式以及对告警进行聚合和沉默的能力,使得用户能够更加高效地响应监控系统发出的警报。
# 2. 安装和配置Alertmanager
在本章中,我们将介绍如何安装和配置Alertmanager与Prometheus的集成。Alertmanager是一个处理和发送监控告警的工具,而Prometheus则用于采集和存储监控数据。
### 2.1 下载和安装Alertmanager
Alertmanager可以从Prometheus的官方网站上下载。根据不同的操作系统,选择对应的二进制文件进行下载,并解压到指定目录。
为了方便管理,建议将Alertmanager二进制文件放置在系统的可执行程序搜索路径下,比如`/usr/local/bin`。
安装完成后,可以通过运行以下命令来验证Alertmanager的安装:
```shell
alertmanager --version
```
### 2.2 配置Alertmanager与Prometheus的集成
Alertmanager与Prometheus的集成是通过配置文件来实现的。创建一个名为`alertmanager.yml`的配置文件,并将以下内容复制到文件中:
```yaml
global:
resolve_timeout: 5m
route:
receiver: 'default-receiver'
receivers:
- name: 'default-receiver'
email_configs:
- to: 'admin@example.com'
from: 'alertmanager@example.com'
smarthost: 'smtp.example.com:587'
auth_username: 'username'
auth_password: 'password'
```
上述配置中,使用了默认的路由规则将所有的告警发送到名为`default-receiver`的接收者。在这个接收者中,我们使用了电子邮件配置来发送告警到指定的邮箱。
根据实际需求,可以使用其他不同的接收者配置,比如Slack、PagerDuty等。
### 2.3 配置告警规则和接收者
除了配置Alertmanager的集成以外,还需要在Prometheus中定义告警规则,并指定接收者。
打开Prometheus的配置文件`prometheus.yml`,在其中添加以下内容:
```yaml
rule_files:
- 'rules.yml'
alerting:
alertmanagers:
- static_configs:
- targets:
- 'localhost:9093'
```
上述配置中,我们指定了一个名为`rules.yml`的规则文件,用于定义告警规则。同时,通过`alertmanagers`配置指定了Alertmanager的地址和端口。
接下来,创建一个名为`rules.yml`的规则文件,并添加以下内容:
```yaml
groups:
- name: 'example'
rules:
- alert: 'HighCpuUsage'
expr: '100 - (avg by(instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90'
for: '5m'
labels:
severity: 'critical'
annotations:
summary: 'High CPU usage detected'
description: 'The average CPU usage is above 90% for the past 5 minutes.'
runbook: 'http://example.com/runbook/high-cpu-usage'
```
上述规则定义了一个名为`HighCpuUsage`的告警规则,当5分钟内的平均CPU使用率超过90%时触发告警,并设置了相应的标签和注释。
保存并重启Prometheus,然后访问Prometheus的表达式浏览器,可以看到`HighCpuUsage`的告警规则已经生效。
至此,Alertmanager与Prometheus的集成已经完成。在下一章节中,我们将介绍如何配置Alertmanager的告警路由与处理。
# 3. Prometheus告警规则配置
在这一章节中,我们将深入探讨如何在Prometheus中配置告警规则,以便及时捕捉系统中的异常情况并进行相应的处理。
#### 3.1 如何定义Prometheus的告警规则?
Prometheus的告警规则可以通过PromQL语言定义,PromQL是Prometheus的查询语言,同时也支持用于定义告警条件。例如,我们可以使用类似以下的表达式来定义一个告警规则:
```yaml
groups:
- name: example
rules:
- alert: HighErrorRate
expr: job:request_error_rate{job="myjob"} > 0.5
for: 5m
labels:
severity: page
annotations:
summary: "High error rate detected"
description: "The error rate for myjob is above 0.5"
```
在上述示例中,我们定义了一个名为HighErrorRate的告警规则,当名为myjob的job的请求错误率超过了0.5的阈值持续5分钟时,将触发这个告警规则。
#### 3.2 配置Prometheus以生成告警
为了使Prometheus能够根据我们定义的告警规则生成相应的告警信息,我们需要在Promethe

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏《K8s结合Prometheus监控告警系统基础与应用》涵盖了Kubernetes(K8s)以及Prometheus监控系统的各个方面。您将了解Kubernetes的基本概念、架构以及深入理解其工作原理与基础组件。同时,您还将学习如何使用Minikube搭建本地Kubernetes集群,并在K8s中安装配置Prometheus监控系统,实现灵活的指标查询与聚合。此外,专栏还介绍了如何在Kubernetes中实现服务发现与监控自动发现,以及使用Prometheus Operator简化Kubernetes集群的监控配置。您还将学习如何使用Alertmanager实现Prometheus告警管理,配置告警通知的多样化,并使用Recording Rules优化告警规则。同时,您还将深入探索Prometheus的存储与数据模型,实现自动发现目标和跨集群的监控。此外,专栏还介绍了使用Pushgateway支持短期任务监控,实现Prometheus的高可用和水平扩展,以及如何使用Prometheus和Grafana进行可视化监控。通过本专栏,您将全面了解Kubernetes与Prometheus监控告警系统的基础知识,并能应用于实际项目中。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【笔记本性能飙升】:DDR4 SODIMM vs DDR4 DIMM,内存选择不再迷茫
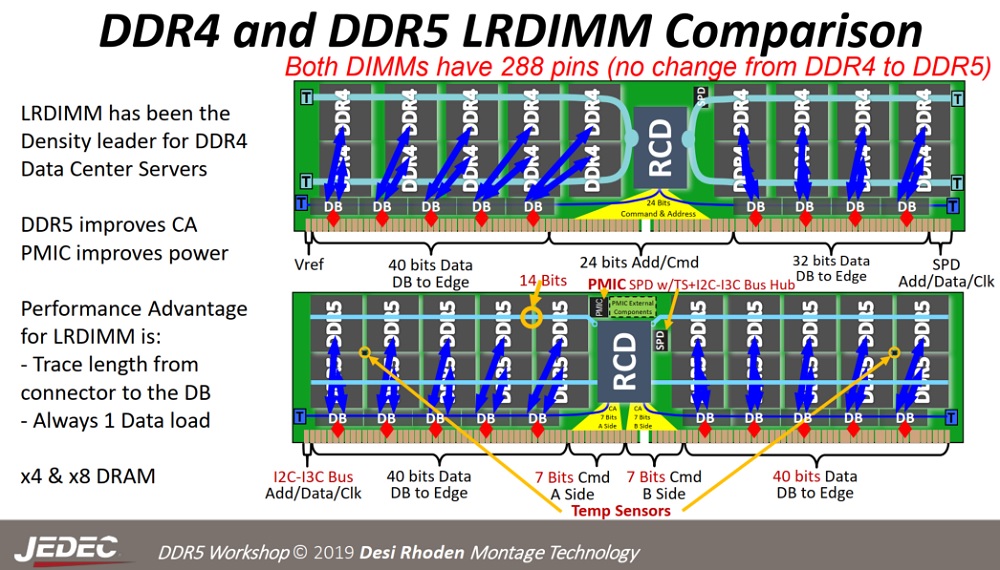
参考资源链接:[DDR4_SODIMM_SPEC.pdf](https://wenku.csdn.net/doc/6412b732be7fbd1778d496f2?spm=1055.2635.3001.10343)
# 1. 内存技术的演进与DDR4标准
## 1.1 内存技术的历史回顾
内存技术经历了从最
【防止过拟合】机器学习中的正则化技术:专家级策略揭露

参考资源链接:[《机器学习(周志华)》学习笔记.pdf](https://wenku.csdn.net/doc/6412b753be7fbd1778d49
【高级电路故障排除】:PIN_delay设置错误的诊断与修复,恢复系统稳定性
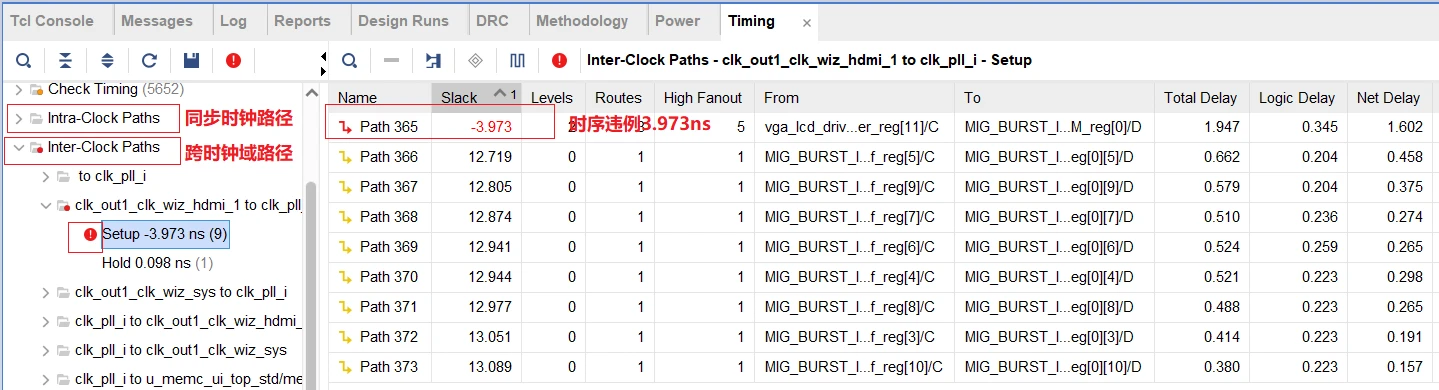
参考资源链接:[Allegro添加PIN_delay至高速信号的详细教程](https://wenku.csdn.net/doc/6412b6c8be7fbd1778d47f6b?spm=1055.2635.3001.10343)
# 1. PIN_delay设置的重要性与影响
在当今的IT和电子工程领域,PIN_delay参数的设置对于确保系统稳定性和
【GX Works3版本控制】:如何管理PLC程序的版本更新,避免混乱

参考资源链接:[三菱GX Works3编程手册:安全操作与应用指南](https://wenku.csdn.net/doc/645da0e195996c03ac442695?spm=1055.2635.3001.10343)
# 1. GX Works3版本控制概论
在PLC(可编程逻辑控制器)编程中,随着项目规模的增长和团队协作的复杂化,版本控制已经成为了一个不可或缺的工具。GX Wo
【GNSS高程数据处理坐标系统宝典】:选择与转换的专家指南

参考资源链接:[GnssLevelHight:高精度高程拟合工具](https://wenku.csdn.net/doc/6412b6bdbe7fbd1778d47cee?spm=1055.2635.3001.10343)
# 1. GNSS高程数据处理基础
在本章中,我们将探讨全球导航卫星系统(GNSS)高程数据处理的
【跨平台GBFF文件解析】:兼容性问题的终极解决方案

参考资源链接:[解读GBFF:GenBank数据的核心指南](https://wenku.csdn.net/doc/3cym1yyhqv?spm=1055.2635.3001.10343)
# 1. 跨平台文件解析的挑战与GBFF格式
跨平台应用在现代社会已经成为一种常态,这不仅仅表现在不同操作系统之间的兼容,还包括不同硬件平台以及网络环境。在文件解析这一层面,
STEP7 GSD文件安装:兼容性分析,确保不同操作系统下的正确安装
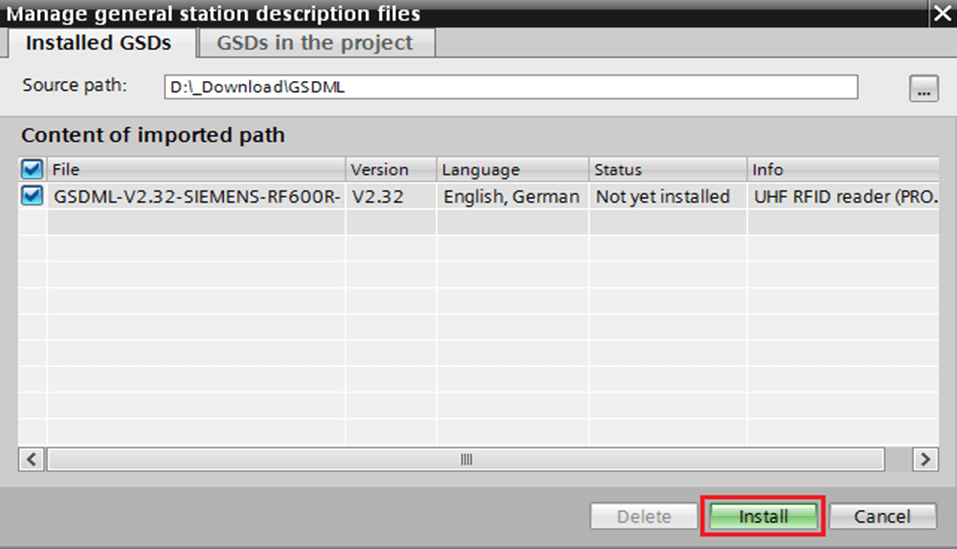
参考资源链接:[解决STEP7中GSD安装失败问题:解除引用后重装](https://wenku.csdn.net/doc/6412b5fdbe7fbd1778d451c0?spm=1055.2635.3001.10343)
# 1. STEP7 GSD文件简介
在自动化和工业控制系统领域,STEP7(也称为TIA Portal)是西门子广泛
【自定义宏故障处理】:发那科机器人灵活性与稳定性并存之道
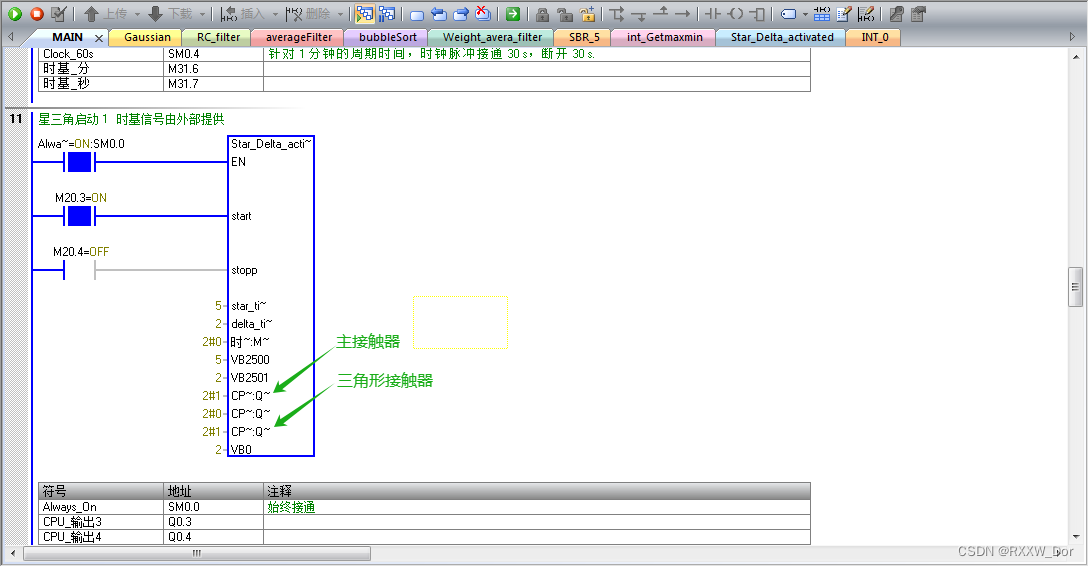
参考资源链接:[发那科机器人SRVO-037(IMSTP)与PROF-017(从机断开)故障处理办法.docx](https://wenku.csdn.net/doc/6412b7a1be7fbd1778d4afd1?spm=1055.2635.3001.10343)
# 1. 发那科机器人自定义宏概述
自定义宏是发那科机器人编程中的一个强大工具,它允许用户通过参数化编程来简化重复性任务和复杂逻辑
台达PLC编程常见错误剖析:新手到专家的防错指南
参考资源链接:[台达PLC ST编程语言详解:从入门到精通](https://wenku.csdn.net/doc/6401ad1acce7214c316ee4d4?spm=1055.2635.3001.10343)
# 1. 台达PLC编程简介
台达PLC(Programmable Logic Controller)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )