深入理解Kubernetes的工作原理与基础组件
发布时间: 2024-01-21 05:29:13 阅读量: 60 订阅数: 25 

kubernetes基础知识
# 1. Kubernetes简介
## 1.1 什么是Kubernetes
Kubernetes(简称为K8s)是一个开源的容器编排平台,它可以自动化地部署、扩展和管理容器化的应用程序。Kubernetes提供了丰富的功能和强大的工具,可以简化容器化应用的管理,并提供高可用性、弹性伸缩、自动修复等特性,有效地帮助用户构建和管理现代化的云原生应用。
Kubernetes的设计理念是以容器为基础的工作负载抽象,通过对容器进行统一的编排和调度,实现高效的资源利用和弹性伸缩。它提供了丰富的API和工具集,支持多种容器运行时(如Docker、Containerd等),并且可以与通用的云平台集成,如AWS、Azure、OpenStack等。
## 1.2 Kubernetes的发展历程
Kubernetes最早是由Google开发的内部容器编排工具,它在Google的大规模容器集群环境中得到了广泛应用。随后,Google将Kubernetes开源,并将其交给了Cloud Native Computing Foundation(CNCF)作为维护和管理的项目。
自开源以来,Kubernetes得到了全球范围内的广泛关注和使用。它成为了容器编排领域的事实标准,并迅速成为了云原生应用开发和部署的首选平台。
## 1.3 Kubernetes的重要性与优势
Kubernetes在现代化应用开发和部署中扮演着非常重要的角色,具有以下优势:
- **容器编排与调度**:Kubernetes可以自动进行容器的调度和管理,确保应用在集群中的平衡和高可用性。
- **弹性伸缩**:Kubernetes支持根据负载自动进行应用的水平扩展和收缩,以及支持自动容器的故障恢复。
- **多租户与隔离**:Kubernetes可以提供多租户的环境,确保不同用户或团队的应用之间的隔离和安全性。
- **可扩展性**:Kubernetes具有良好的可扩展性,可以支持大规模集群的管理,并能够有效地管理数千个容器应用。
- **生态系统与工具支持**:Kubernetes拥有丰富的生态系统和工具支持,可以方便地进行监控、日志收集、自动化任务等操作。
总之,Kubernetes作为一个开源的容器编排平台,为用户提供了更加便捷和高效的方式来构建、部署和管理容器化应用,大大地提高了应用的可靠性和可扩展性。它已经成为了云原生应用开发和运维的重要工具,对于现代化的软件开发来说,是不可或缺的一部分。
# 2. Kubernetes的工作原理
#### 2.1 Pod与容器的概念
在Kubernetes中,最小的部署单元是Pod。Pod是一个可以包含一个或多个容器的组。每个Pod都有自己的IP地址,并且它包含的所有容器共享相同的网络命名空间、存储卷以及其他资源。这样设计的好处是便于容器之间的通信和共享资源。
```python
# 示例代码
# 创建一个简单的Pod
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx
```
在这个示例中,我们创建了一个名为`nginx-pod`的Pod,并在其中运行一个名为`nginx-container`的Nginx容器。
#### 2.2 控制器的角色与作用
控制器是用来确保系统中的某种资源处于期望状态的组件。在Kubernetes中,控制器负责管理Pod的创建、复制、更新以及删除操作。常见的控制器包括ReplicaSet、Deployment、StatefulSet等。
```java
// 示例代码
// 创建一个简单的Deployment
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: nginx
```
在这个示例中,我们创建了一个名为`nginx-deployment`的Deployment,它指定了要运行3个副本的Nginx容器。
#### 2.3 调度器的工作机制
Kubernetes的调度器负责根据预定义的调度策略,将新创建的Pod分配到集群中的某个节点上。调度器会考虑节点的资源利用率、标签选择器以及亲和性/反亲和性等因素来做出最优的调度决策。
```go
// 示例代码
// 创建一个带有节点选择器的Pod
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx
nodeSelector:
disktype: ssd
```
在这个示例中,我们定义了一个名为`nginx-pod`的Pod,并指定了该Pod只能调度到拥有`disktype: ssd`标签的节点上。
#### 2.4 服务发现与负载均衡
Kubernetes使用Service来暴露一个应用,而不是直接暴露Pod。Service定义了一组Pod的访问规则,通常与标签选择器一起使用,以确定要路由到哪些Pod。此外,Service还提供了负载均衡的功能,可以将流量分发到多个后端Pod上。
```javascript
// 示例代码
// 创建一个简单的Service
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
```
在这个示例中,我们创建了一个名为`nginx-service`的Service,它会将所有标签中包含`app: nginx`的Pod暴露在TCP端口80上。
通过以上章节内容,我们深入了解了Kubernetes的工作原理,包括Pod与容器的概念、控制器的作用、调度器的工作机制以及服务发现与负载均衡的实现原理。
# 3. Kubernetes的基础组件
Kubernetes的基础组件包括Master节点和Worker节点,它们分别担负着集群的管理和应用的运行任务。
#### 3.1 Master节点的角色与组件
在Kubernetes集群中,Master节点是整个集群的控制中心,负责调度和管理集群中的所有工作负载。Master节点包括以下组件:
##### 3.1.1 Api Server
Api Server是Kubernetes集群的中央管理端点,所有的集群控制命令都通过Api Server进行处理。它提供了RESTful API,用于集群状态的查询和集群操作的执行。
```python
# 示例代码
from kubernetes import client, config
# 加载集群配置
config.load_kube_config()
# 创建API客户端
api_instance = client.CoreV1Api()
# 查询所有的Pod
api_response = api_instance.list_pod_for_all_namespaces()
for pod in api_response.items:
print(pod.metadata.name)
```
**代码总结**:上述代码使用Python的kubernetes客户端库,通过Api Server查询集群中所有的Pod,并打印它们的名称。
**结果说明**:该代码将打印出集群中所有Pod的名称。
##### 3.1.2 Controller Manager
Controller Manager负责运行控制器,这些控制器负责维护集群的状态,例如故障恢复、滚动更新等。其中包括Replication Controller、Endpoints Controller等。
```java
// 示例代码
import io.kubernetes.client.ApiClient;
import io.kubernetes.client.ApiException;
import io.kubernetes.client.Configuration;
import io.kubernetes.client.apis.AppsV1Api;
import io.kubernetes.client.models.V1Deployment;
import io.kubernetes.client.models.V1DeploymentList;
// 设置ApiClient的配置
ApiClient client = Configuration.getDefaultApiClient();
// 创建AppsV1Api实例
AppsV1Api api = new AppsV1Api(client);
// 列出命名空间下的所有Deployment
V1DeploymentList deploymentList = api.listNamespacedDeployment("default", null, null, null, null, null, null, null, null, null);
for (V1Deployment deployment : deploymentList.getItems()) {
System.out.println(deployment.getMetadata().getName());
}
```
**代码总结**:以上Java代码使用Kubernetes Java客户端,列出指定命名空间下所有的Deployment。
**结果说明**:这段代码将打印出指定命名空间下所有Deployment的名称。
##### 3.1.3 Scheduler
Scheduler负责将新创建的Pod分配到集群中的节点,它根据一定的调度算法来选择合适的节点进行调度。
##### 3.1.4 etcd
etcd是Kubernetes集群中的分布式键值存储,用于保存集群的状态和元数据信息,是Kubernetes集群的数据存储后端。
#### 3.2 Worker节点的角色与组件
Worker节点是集群中实际运行应用工作负载的节点,它包括以下组件:
##### 3.2.1 Kubelet
Kubelet是Node节点上的主要组件,负责管理节点上运行的Pod,并与Master节点的Api Server进行通信。
```go
// 示例代码
import (
"context"
"fmt"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/rest"
)
// 创建Kubelet客户端
config, err := rest.InClusterConfig()
if err != nil {
panic(err.Error())
}
clientset, err := kubernetes.NewForConfig(config)
if err != nil {
panic(err.Error())
}
// 查询所有Node上运行的Pod
pods, err := clientset.CoreV1().Pods("").List(context.TODO(), metav1.ListOptions{})
if err != nil {
panic(err.Error())
}
for _, pod := range pods.Items {
fmt.Println(pod.Name)
}
```
**代码总结**:上述Go代码使用client-go库创建Kubelet客户端,然后查询所有Node上运行的Pod并打印它们的名称。
**结果说明**:该代码将打印出所有Node上运行的Pod的名称。
##### 3.2.2 Kube-proxy
Kube-proxy负责维护节点上的网络规则,实现了Kubernetes服务的代理和负载均衡功能。
##### 3.2.3 Container Runtime
Container Runtime负责管理容器的生命周期,包括镜像的拉取、容器的创建、启动和关闭等操作。
以上是Kubernetes的基础组件,它们共同协作构成了一个高效稳定的容器编排平台。
# 4. Kubernetes集群的部署与管理
### 4.1 Kubernetes集群的部署方式
在部署Kubernetes集群时,我们有多种方式可供选择,下面介绍两种常见的部署方式。
#### 4.1.1 基于二进制的部署
基于二进制的部署方式适用于那些希望对Kubernetes的每个组件进行更加细致的定制和控制的用户。
首先,需要下载Kubernetes的二进制文件,包括kube-apiserver、kube-controller-manager、kube-scheduler等组件。
然后,配置每个组件的选项和参数,在每个节点上启动这些组件。这些组件之间会通过Etcd进行通信和协调。
最后,确保每个节点上的kubelet和kube-proxy服务正常运行,并且节点之间的网络能够互通。
#### 4.1.2 基于容器的部署
基于容器的部署方式使用容器化技术来部署Kubernetes集群,如Docker等。
首先,创建一个包含Kubernetes所有组件的Docker镜像,包括kube-apiserver、kube-controller-manager、kube-scheduler等。
然后,使用Docker或其他容器运行时在每个节点上运行这些镜像,通过配置容器的选项和参数来启动各个组件。
最后,确保节点上的容器运行时正常工作,并且节点之间的网络能够互通。
### 4.2 组件的配置与管理
部署Kubernetes集群后,我们需要对各个组件进行配置和管理,以确保集群的正常运行。
#### 4.2.1 Master节点的配置与管理
- Api Server: 可以通过修改Api Server的配置文件来指定Api Server的监听地址、认证授权方式等。
- Controller Manager: 可以通过修改Controller Manager的配置文件来指定控制器的运行参数、日志级别等。
- Scheduler: 可以通过修改Scheduler的配置文件来指定调度策略、绑定策略等。
- etcd: 可以通过修改etcd的配置文件来指定数据存储路径、备份策略等。
#### 4.2.2 Worker节点的配置与管理
- Kubelet: 可以通过修改Kubelet的配置文件来指定该节点上的容器运行时、网络设置等。
- Kube-proxy: 可以通过修改Kube-proxy的配置文件来指定代理规则、负载均衡策略等。
- Container Runtime: 可以通过修改容器运行时的配置文件来设置容器的资源限制、环境变量等。
### 4.3 高可用性与容灾备份
为了保证Kubernetes集群的高可用性和容灾备份,我们可以采取以下措施:
- 使用多个Master节点:通过在集群中使用多个Master节点,可以实现Master节点的高可用性,防止单点故障导致整个集群不可用。
- 定期备份etcd数据:etcd是Kubernetes集群的数据存储组件,定期备份etcd数据可以保证在数据丢失或损坏的情况下可以快速恢复集群。
- 使用负载均衡器:在集群中使用负载均衡器可以将流量均匀分配给多个节点,提高集群的整体性能和可用性。
通过以上措施,我们可以确保Kubernetes集群的高可用性和容灾备份,提供稳定可靠的服务。
# 5. Kubernetes的应用案例
Kubernetes作为一个容器编排平台,具有强大的应用部署与管理能力。在本章节中,我们将详细探讨Kubernetes在实际应用中的案例和使用方法。
#### 5.1 容器化应用的部署与管理
在Kubernetes中,通过创建Pod来部署容器化的应用。Pod是Kubernetes的最小部署单元,可以包含一个或多个容器。通过定义Pod的配置文件,可以实现对应用的快速部署与管理。
```yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80
```
上述YAML配置文件定义了一个名为nginx-pod的Pod,其中包含一个基于nginx镜像的容器,该容器监听80端口。通过kubectl apply命令可以将该配置文件提交给Kubernetes集群进行部署。
#### 5.1.1 使用Pod进行应用部署
通过创建Pod来部署应用,可以实现应用容器的快速启动和管理,同时也可以灵活地对应用进行资源调度和暴露服务。
#### 5.1.2 使用Service进行服务暴露与访问
在Kubernetes中,Service是用来暴露应用提供的网络服务的资源对象。通过定义Service配置文件,可以实现对应用的访问与负载均衡。
```yaml
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx-pod
ports:
- protocol: TCP
port: 80
targetPort: 80
type: NodePort
```
上述YAML配置文件定义了一个名为nginx-service的Service,通过selector字段指定了要暴露的Pod标签,通过type字段指定了Service的类型为NodePort。通过kubectl apply命令可以将该配置文件提交给Kubernetes集群进行Service的创建与暴露。
#### 5.2 水平扩展与滚动升级
Kubernetes通过ReplicaSet资源对象实现了对应用的水平扩展和滚动升级能力。通过定义ReplicaSet配置文件,可以实现对应用实例数量的动态调整。
```yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-replicaset
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80
```
上述YAML配置文件定义了一个名为nginx-replicaset的ReplicaSet,通过spec字段的replicas属性可以指定应用的实例数量。通过kubectl apply命令可以将该配置文件提交给Kubernetes集群进行ReplicaSet的创建与管理。
#### 5.3 无状态与有状态应用的管理
Kubernetes对于无状态应用和有状态应用都有良好的支持。对于无状态应用,可以使用Deployment资源对象进行快速部署和管理;对于有状态应用,可以使用StatefulSet资源对象实现稳定的存储和网络标识。
以上就是Kubernetes在实际应用中的案例和使用方法,通过对应用的部署、扩展、升级以及无状态/有状态应用的管理,Kubernetes为用户提供了强大的应用管理能力。
# 6. Kubernetes的进阶主题
Kubernetes作为一个高级的容器编排平台,除了基本的容器编排能力之外,还提供了许多进阶的功能和主题。在本章节中,我们将深入讨论这些进阶主题,包括存储卷的管理与使用、认证与授权的管理、网络配置与管理、监控与日志收集以及自动化与持续集成/持续部署。
#### 6.1 存储卷的管理与使用
在Kubernetes中,存储卷是一种用于持久化存储数据的机制,它可以被Pod挂载并被多个容器共享。Kubernetes支持多种类型的存储卷,包括空目录、主机路径、网络存储等。存储卷的管理与使用对于运行有状态应用非常重要。
示例代码(Python):
```python
# 创建一个持久化存储卷
apiVersion: v1
kind: PersistentVolume
metadata:
name: my-pv
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: slow
local:
path: /mnt/disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- my-node
# 创建一个使用存储卷的Pod
apiVersion: v1
kind: Pod
metadata:
name: my-pod
spec:
containers:
- name: my-frontend
image: nginx
volumeMounts:
- mountPath: "/var/www/html"
name: my-persistent-storage
volumes:
- name: my-persistent-storage
persistentVolumeClaim:
claimName: my-pvc
```
代码总结:上述示例代码使用Python编写了创建一个持久化存储卷和使用存储卷的Pod的YAML配置文件。
结果说明:这段代码演示了如何在Kubernetes中创建一个持久化存储卷,并将其挂载到一个Pod中供容器使用。
#### 6.2 认证与授权的管理
在Kubernetes集群中,认证与授权是非常重要的主题,它涉及到用户、身份、权限等方面的管理。Kubernetes提供了多种认证与授权的方式,包括基于角色的访问控制(RBAC)、凭证管理、TLS证书、ServiceAccount等。
示例代码(Java):
```java
// 创建一个ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
name: my-service-account
namespace: default
// 创建一个Role,并定义其权限
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "watch", "list"]
// 创建绑定将Role与ServiceAccount绑定
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
- kind: ServiceAccount
name: my-service-account
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
```
代码总结:上述示例代码使用Java编写了创建ServiceAccount、Role和RoleBinding的YAML配置文件,实现了基于角色的访问控制。
结果说明:这段代码演示了如何在Kubernetes中创建一个ServiceAccount,并通过Role和RoleBinding实现对Pod的访问控制。
#### 6.3 网络配置与管理
Kubernetes集群中的网络配置与管理也是一个重要的主题,它涉及到Pod之间的通信、服务的暴露与发现、网络策略等方面。Kubernetes支持多种网络插件,如Calico、Flannel、Cilium等,用于实现不同的网络模型。
示例代码(Go):
```go
// 创建一个网络策略,限制对特定Pod的访问
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: test-network-policy
spec:
podSelector:
matchLabels:
run: test
policyTypes:
- Ingress
- Egress
ingress:
- from:
- ipBlock:
cidr: 192.168.1.0/24
except:
- 192.168.1.10/32
ports:
- protocol: TCP
port: 6379
egress:
- to:
- ipBlock:
cidr: 10.0.0.0/24
ports:
- protocol: TCP
port: 5978
```
代码总结:上述示例代码使用Go编写了创建一个NetworkPolicy的YAML配置文件,实现了对特定Pod的网络访问控制。
结果说明:这段代码演示了如何在Kubernetes中使用NetworkPolicy限制对特定Pod的网络访问。
#### 6.4 监控与日志收集
在Kubernetes集群中,监控与日志收集是必不可少的,它涉及到集群运行状态的监控、日志的收集与分析等。Kubernetes集群通常会使用Prometheus、Grafana、Elasticsearch等工具进行监控与日志收集。
示例代码(JavaScript):
```javascript
// 配置Prometheus的ServiceMonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: my-service-monitor
spec:
selector:
matchLabels:
app: my-app
endpoints:
- port: web
```
代码总结:上述示例代码使用JavaScript编写了创建一个ServiceMonitor的YAML配置文件,用于配置Prometheus的监控目标。
结果说明:这段代码演示了如何在Kubernetes中配置ServiceMonitor,以便Prometheus进行监控。
#### 6.5 自动化与持续集成/持续部署
自动化与持续集成/持续部署是Kubernetes中的另一个重要主题,它涉及到CI/CD流水线的构建、容器镜像的构建与发布、应用的自动化部署等。在Kubernetes集群中,通常会使用Jenkins、GitLab CI、Spinnaker等工具实现自动化与持续集成/持续部署。
示例代码(Python):
```python
# 配置Jenkins Pipeline,实现持续集成/持续部署
pipeline {
agent any
stages {
stage('Build') {
steps {
// 构建Docker镜像
sh 'docker build -t my-app:v1 .'
}
}
stage('Test') {
steps {
// 运行单元测试
sh 'pytest'
}
}
stage('Deploy') {
steps {
// 使用kubectl部署应用
sh 'kubectl apply -f deployment.yaml'
}
}
}
}
```
代码总结:上述示例代码使用Python编写了一个Jenkins Pipeline,实现了容器镜像的构建、单元测试和应用部署的持续集成/持续部署流程。
结果说明:这段代码演示了如何使用Jenkins Pipeline实现持续集成/持续部署流程,以确保应用的自动化发布与部署。
本章节通过实际的示例代码和结果说明,详细讨论了Kubernetes的进阶主题,包括存储卷的管理与使用、认证与授权的管理、网络配置与管理、监控与日志收集以及自动化与持续集成/持续部署,帮助读者深入理解Kubernetes在实际应用中的高级功能和应用场景。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏《K8s结合Prometheus监控告警系统基础与应用》涵盖了Kubernetes(K8s)以及Prometheus监控系统的各个方面。您将了解Kubernetes的基本概念、架构以及深入理解其工作原理与基础组件。同时,您还将学习如何使用Minikube搭建本地Kubernetes集群,并在K8s中安装配置Prometheus监控系统,实现灵活的指标查询与聚合。此外,专栏还介绍了如何在Kubernetes中实现服务发现与监控自动发现,以及使用Prometheus Operator简化Kubernetes集群的监控配置。您还将学习如何使用Alertmanager实现Prometheus告警管理,配置告警通知的多样化,并使用Recording Rules优化告警规则。同时,您还将深入探索Prometheus的存储与数据模型,实现自动发现目标和跨集群的监控。此外,专栏还介绍了使用Pushgateway支持短期任务监控,实现Prometheus的高可用和水平扩展,以及如何使用Prometheus和Grafana进行可视化监控。通过本专栏,您将全面了解Kubernetes与Prometheus监控告警系统的基础知识,并能应用于实际项目中。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
datasheet解读速成课:关键信息提炼技巧,提升采购效率

# 摘要
本文全面探讨了datasheet在电子组件采购过程中的作用及其重要性。通过详细介绍datasheet的结构并解析其关键信息,本文揭示了如何通过合理分析和利用datasheet来提升采购效率和产品质量。文中还探讨了如何在实际应用中通过标准采购清单、成本分析以及数据整合来有效使用datasheet信息,并通过案例分析展示了datasheet在采购决策中的具体应用。最后,本文预测了datasheet智能化处
【光电传感器应用详解】:如何用传感器引导小车精准路径

# 摘要
光电传感器在现代智能小车路径引导系统中扮演着核心角色,涉及从基础的数据采集到复杂的路径决策。本文首先介绍了光电传感器的基础知识及其工作原理,然后分析了其在小车路径引导中的理论应用,包括传感器布局、导航定位、信号处理等关键技术。接着,文章探讨了光电传感器与小车硬件的集成过程,包含硬件连接、软件编程及传感器校准。在实践部分,通过基
新手必看:ZXR10 2809交换机管理与配置实用教程
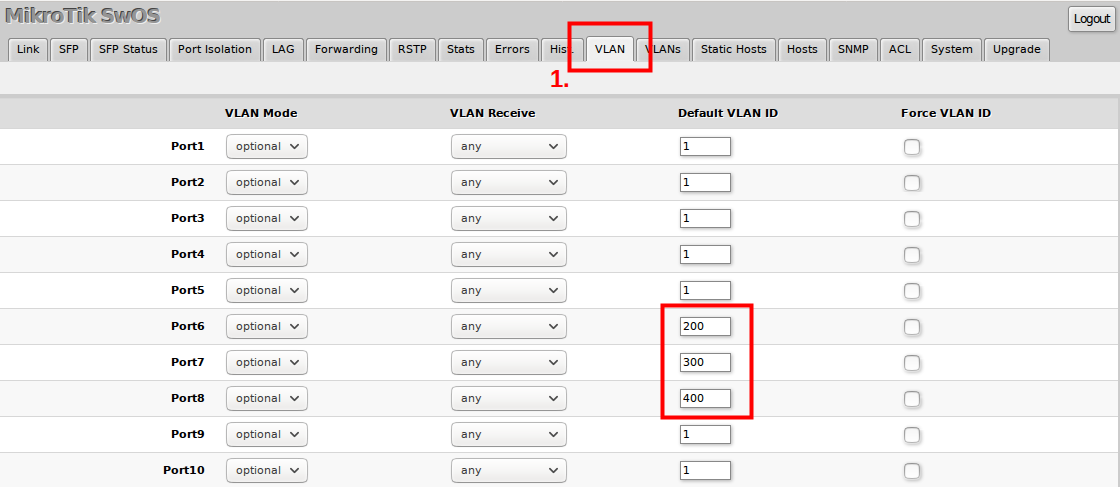
# 摘要
ZXR10 2809交换机作为网络基础设施的关键设备,其配置与管理是确保网络稳定运行的基础。本文首先对ZXR10 2809交换机进行概述,并介绍了基础管理知识。接着,详细阐述了交换机的基本配置,包括物理连接、初始化配置、登录方式以及接口的配置与管理。第三章深入探讨了网络参数的配置,VLAN的创建与应用,以及交换机的安全设置,如ACL配置和端口安全。第四章涉及高级网络功能,如路由配置、性能监控、故障排除和网络优
加密技术详解:专家级指南保护你的敏感数据
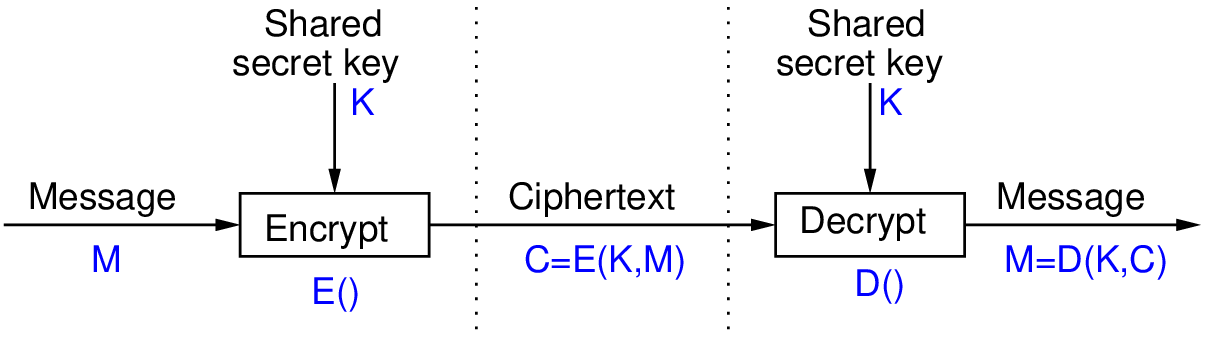
# 摘要
本文系统介绍了加密技术的基础知识,深入探讨了对称加密与非对称加密的理论和实践应用。分析了散列函数和数字签名在保证数据完整性与认证中的关键作用。进一步,本文探讨了加密技术在传输层安全协议TLS和安全套接字层SSL中的应用,以及在用户身份验证和加密策略制定中的实践。通过对企业级应用加密技术案例的分析,本文指出了实际应用中的挑战与解决方案,并讨论了相关法律和合规问题。最后,本文展望了加密技术的未来发展趋势,特别关注了量
【16串电池监测AFE选型秘籍】:关键参数一文读懂

# 摘要
本文全面介绍了电池监测AFE(模拟前端)的原理和应用,着重于其关键参数的解析和选型实践。电池监测AFE是电池管理系统中不可或缺的一部分,负责对电池的关键性能参数如电压、电流和温度进行精确测量。通过对AFE基本功能、性能指标以及电源和通信接口的分析,文章为读者提供了选择合适AFE的实用指导。在电池监测AFE的集成和应用章节中
VASPKIT全攻略:从安装到参数设置的完整流程解析

# 摘要
VASPKIT是用于材料计算的多功能软件包,它基于密度泛函理论(DFT)提供了一系列计算功能,包括能带计算、动力学性质模拟和光学性质分析等。本文系统介绍了VASPKIT的安装过程、基本功能和理论基础,同时提供了实践操作的详细指南。通过分析特定材料领域的应用案例,比如光催化、
【Exynos 4412内存管理剖析】:高速缓存策略与性能提升秘籍
# 摘要
本文对Exynos 4412处理器的内存管理进行了全面概述,深入探讨了内存管理的基础理论、高速缓存策略、内存性能优化技巧、系统级内存管理优化以及新兴内存技术的发展趋势。文章详细分析了Exynos 4412的内存架构和内存管理单元(MMU)的功能,探讨了高速缓存架构及其对性能的影响,并提供了一系列内存管理实践技巧和性能提升秘籍。此外,
慧鱼数据备份与恢复秘籍:确保业务连续性的终极策略(权威指南)
# 摘要
本文全面探讨了数据备份与恢复的基础概念,备份策略的设计与实践,以及慧鱼备份技术的应用。通过分析备份类型、存储介质选择、备份工具以及备份与恢复策略的制定,文章提供了深入的技术见解和配置指导。同时,强调了数据恢复的重要性,探讨了数据恢复流程、策略以及慧鱼数据恢复工具的应用。此
【频谱分析与Time Gen:建立波形关系的新视角】:解锁频率世界的秘密
# 摘要
本文旨在探讨频谱分析的基础理论及Time Gen工具在该领域的应用。首先介绍频谱分析的基本概念和重要性,然后详细介绍Time Gen工具的功能和应用场景。文章进一步阐述频谱分析与Time Gen工具的理论结合,分析其在信号处理和时间序列分析中的作用。通过多个实践案例,本文展示了频谱分析与Time Gen工具相结合的高效性和实用性,并探讨了其在高级应用中的潜在方向和优势。本文为相关领域的研究人员和工程师
【微控制器编程】:零基础入门到编写你的首个AT89C516RD+程序
# 摘要
本文深入探讨了微控制器编程的基础知识和AT89C516RD+微控制器的高级应用。首先介绍了微控制器的基本概念、组成架构及其应用领域。随后,文章详细阐述了AT89C516RD+微控制器的硬件特性、引脚功能、电源和时钟管理。在软件开发环境方面,本文讲述了Keil uVision开发工具的安装和配置,以及编程语言的使用。接着,文章引导读者通过实例学习编写和调试AT89C516RD+的第一个程序,并探讨了微控制器在实践应用中的接口编程和中断驱动设计。最后,本文提供了高级编程技巧,包括实时操作系统的应用、模块集成、代码优化及安全性提升方法。整篇文章旨在为读者提供一个全面的微控制器编程学习路径,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )