【Guava库实战案例】:项目中有效使用***mon.collect的终极指南
发布时间: 2024-09-26 11:56:40 阅读量: 79 订阅数: 24 
# 1. Guava库介绍与背景
## 1.1 Java编程的挑战与需求
Java作为一门成熟的编程语言,在处理集合、并发、函数式编程等方面提供了丰富的API。然而,随着编程需求的不断增长,Java标准库的一些局限性逐渐显现。开发者往往需要编写额外的代码来实现一些常见的操作,比如集合的不可变性、集合的转换等。
## 1.2 Guava库的诞生
为了解决这些问题,Google开发了Guava库,旨在简化Java开发,减少重复的代码编写。Guava库通过提供一系列实用工具类和核心集合的扩展,让Java开发者能够更加专注于业务逻辑的实现。
## 1.3 Guava库的特性与优势
Guava库包含了许多方便的功能,例如集合操作工具、缓存处理、并发控制、事件总线等,极大地提高了开发效率。其设计注重实用性和可扩展性,通过流畅的API设计使代码更加简洁易读。因此,Guava成为了IT行业中许多开发者项目中的必备工具库。
# 2. Guava集合框架详解
Guava集合框架为Java集合框架提供了额外的工具和实现,它们扩展了标准Java集合类的功能。这些工具让开发者能够以更加简洁和安全的方式来处理集合,减少样板代码,提高代码的可读性和可维护性。
## 2.1 集合工具类的使用
### 2.1.1 集合的创建与初始化
在Java中,创建和初始化集合通常涉及到冗长的样板代码。Guava提供了简洁的静态工厂方法来创建和初始化集合,这些方法可以大大减少初始化的代码量。例如,`ImmutableList.of()`、`ImmutableMap.of()` 和 `ImmutableSet.of()` 提供了快速创建不可变集合的方式。
```java
List<String> immutableList = ImmutableList.of("Apple", "Banana", "Cherry");
Set<String> immutableSet = ImmutableSet.of("Apple", "Banana", "Cherry");
Map<String, Integer> immutableMap = ImmutableMap.of("Apple", 1, "Banana", 2, "Cherry", 3);
```
使用这些方法,可以不必调用`new`关键字或者调用集合的添加方法。这些不可变集合被设计为线程安全,并且在初始化之后不允许修改。
### 2.1.2 集合的装饰与转换
Guava还提供了许多集合的装饰器工具类,允许开发者在不创建新集合的基础上,为现有集合添加额外的功能。例如,`Collections2.filter()` 可以创建一个视图来过滤集合中的元素,而不实际修改原始集合。
```java
Collection<String> fruits = Lists.newArrayList("Apple", "Banana", "Cherry", "Date");
Collection<String> fruitsWithoutDate = Collections2.filter(fruits, Predicates.not(Predicates.equalTo("Date")));
```
这种装饰方式可以在任何`Iterable`上应用,而不需要关心集合的具体类型,这是通过`Iterable`的泛型多态性实现的。
## 2.2 集合类型的选择与应用
### 2.2.1 不可变集合的使用场景
不可变集合在某些场景下非常有用,比如在多线程环境下共享数据时。由于不可变集合不允许进行添加、删除等修改操作,因此可以安全地在多个线程之间共享。
```java
ImmutableSet<String> emptySet = ImmutableSet.of();
ImmutableMap<String, Integer> emptyMap = ImmutableMap.of();
```
在构建公共的缓存、常量集、或是单例集合对象时,使用不可变集合可以保证对象一旦创建之后不会被改变。
### 2.2.2 多值映射与BiMap的高级用法
在某些情况下,我们可能会遇到需要将一个键映射到多个值的场景。Guava的`Multimap`提供了这样的功能。`BiMap`是`Multimap`的一个特例,它允许你使用值作为键来反向查找键,而不会有冲突。
```java
BiMap<String, String> biMap = HashBiMap.create();
biMap.put("One", "1");
biMap.put("Two", "2");
String value = biMap.inverse().get("2"); // 返回 "Two"
```
使用`BiMap`时,你可以同时从键和值访问元素,这样在处理双向关系的时候非常方便。
## 2.3 集合的遍历与操作
### 2.3.1 迭代器与遍历器
Guava通过`Iterators`和`Iterables`提供了许多便捷的遍历集合的工具。例如,`Iterators.partition()`方法可以将迭代器分割成固定大小的小块进行迭代,这在处理大数据集时非常有用。
```java
Iterator<String> iterator = Iterators.forArray("Apple", "Banana", "Cherry", "Date");
Iterable<List<String>> partitioned = Iterators.partition(iterator, 2);
for (List<String> partition : partitioned) {
System.out.println(partition);
}
```
这种方法对于分批处理数据非常方便,并且可以很容易地实现分页功能。
### 2.3.2 集合的过滤、排序和归约
集合的过滤可以使用`Collections2.filter()`方法,排序可以使用`Collections2.sort()`方法。归约操作(如将集合中的元素合并成一个单一的结果)可以通过`Collections2.transformAndConcat()`来实现。
```java
Collection<String> fruits = Lists.newArrayList("Apple", "Banana", "Cherry", "Date");
// 过滤出长度大于5的水果名称
Collection<String> longNames = Collections2.filter(fruits, new Predicate<String>() {
@Override
public boolean apply(String input) {
return input.length() > 5;
}
});
// 对水果名称按长度排序
Collections.sort(longNames, Ordering.natural().onResultOf(new Function<String, Integer>() {
@Override
public Integer apply(String input) {
return input.length();
}
}));
// 归约操作
String joined = Collections2.transformAndConcat(fruits, new Function<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String input) {
return Lists.newArrayList(input + "-suffixed");
}
}).join(" ");
```
通过这些工具,可以轻松实现复杂的集合操作,而无需编写大量的循环和条件语句。
在下一章节中,我们将深入探讨Guava的缓存框架及其应用,探索如何使用Guava来优化数据访问性能。
# 3. Guava缓存实践
## 3.1 缓存的基本概念与优势
### 3.1.1 为什么需要缓存
在现代的软件应用中,数据访问往往是一切操作的瓶颈。服务器需要花费大量时间去数据库查询数据,网络服务需要从远程API获取信息,这些操作消耗的时间远超过CPU和内存处理的开销。引入缓存机制可以明显提高数据访问的效率,减少因重复计算和数据检索所导致的延迟。
缓存可以存储那些经常被访问且不经常发生变化的数据,当后续相同的请求发生时,可以直接从缓存中获取数据,而不是每次都进行耗时的数据处理或者数据检索。此外,缓存还能减轻数据库的压力,提高系统的吞吐量和响应速度,这对于高并发的场景尤其重要。
### 3.1.2 缓存的工作原理
缓存的基本工作原理是:当数据第一次被读取时,它会被存储到缓存中;当相同的读取请求再次发生时,系统将直接从缓存中获取数据,而不是重新从数据库或其他数据源读取。这个过程可以被概括为以下几个步骤:
1. **查找(Lookup)**:首先尝试从缓存中查找数据。
2. **命中(Hit)/未命中(Miss)**:如果在缓存中找到了数据,称为“命中”;如果没有找到,则为“未命中”。
3. **填充(Population)**:在缓存未命中时,需要将数据从原始数据源加载到缓存中。
4. **更新(Update)**:缓存中的数据在使用过程中可能会过时,需要适时进行更新。
5. **驱逐(Eviction)**:当缓存达到容量上限时,需要根据某些策略移除一些数据,为新数据腾出空间。
缓存机制通常遵循CAP原理中的一致性(Consistency)和可用性(Availability)之间的权衡,因为缓存无法保证总是和数据源保持绝对一致,但可以提供快速响应。
## 3.2 缓存的构建与使用
### 3.2.1 Guava Cache的基本使用方法
Guava Cache是一种内存存储机制,能够缓存计算成本高昂的结果,使得基于某些输入的函数调用能够快速返回结果。Guava Cache提供了丰富的功能,比如自动加载、过期策略、容量控制等。以下是如何使用Guava Cache的一个基本示例:
```java
LoadingCache<Key, Graph> graphs = CacheBuilder.newBuilder()
.maximumSize(1000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.removalListener(notification -> System.out.println(notification.getKey() + " was removed, cause: " + notification.getCause()))
.build(new CacheLoader<Key, Graph>() {
public Graph load(Key key) throws AnyException {
return createExpensiveGraph(key);
}
});
```
在这个示例中,我们创建了一个`LoadingCache`,它会根据`Key`来加载`Graph`对象。缓存的大小被限制为1000个条目,并且条目在写入后10分钟未被访问会自动过期。
### 3.2.2 高级缓存特性与配置
Guava Cache还提供了许多高级特性,可以让你更细致地控制缓存的行为。例如,你可以通过`refreshAfterWrite`方法设置缓存项在多久之后自动刷新,这允许缓存的值在过期之前自动重新生成,而不需要等待访问它们。
```java
graphs.refr
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 Google Guava 库中强大的 com.google.common.collect 库,它提供了丰富的集合处理工具,旨在简化 Java 开发人员的日常任务。从基础概念到高级技巧,本专栏涵盖了广泛的主题,包括集合构建、操作优化、并发编程、流转换、性能优化、数据分组和收集、过滤和映射,以及实战案例。此外,还对 Guava 库与 Java 集合框架进行了深入比较,突出了其作为集合处理首选的优势。通过深入的解释、代码示例和实际应用,本专栏旨在帮助读者掌握 Guava com.google.common.collect 库,并将其应用于他们的项目中,以提高效率、简化代码并提升性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB时域分析:动态系统建模与分析,从基础到高级的完全指南
# 1. MATLAB时域分析概述
MATLAB作为一种强大的数值计算与仿真软件,在工程和科学领域得到了广泛的应用。特别是对于时域分析,MATLAB提供的丰富工具和函数库极大地简化了动态系统的建模、分析和优化过程。在开始深入探索MATLAB在时域分析中的应用之前,本章将为读者提供一个基础概述,包括时域分析的定义、重要性以及MATLAB在其中扮演的角色。
时域
【JavaScript人脸识别的用户体验设计】:界面与交互的优化

# 1. JavaScript人脸识别技术概述
## 1.1 人脸识别技术简介
人脸识别技术是一种通过计算机图像处理和识别技术,让机器能够识别人类面部特征的技术。近年来,随着人工智能技术的发展和硬件计算能力的提升,JavaScript人脸识别技术得到了迅速的发展和应用。
## 1.2 JavaScript在人脸识别中的应用
JavaScript作为一种强
【NLP新范式】:CBAM在自然语言处理中的应用实例与前景展望

# 1. NLP与深度学习的融合
在当今的IT行业,自然语言处理(NLP)和深度学习技术的融合已经产生了巨大影响,它们共同推动了智能语音助手、自动翻译、情感分析等应用的发展。NLP指的是利用计算机技术理解和处理人类语言的方式,而深度学习作为机器学习的一个子集,通过多层神经网络模型来模拟人脑处理数据和创建模式
数据一致性保证:MySQL PXC集群工作原理与同步机制

# 1. MySQL PXC集群概述
MySQL PXC(Percona XtraDB Cluster)是一个开源的高性能集群解决方案,它基于Galera库实现了同步多主复制,为MySQL数据库提供了真正的高可用性和可扩展性。PXC集群特别适合于需要确保数据一致性和系统高可用性的应用环境,如金融、电商和云服务等领域。
## MySQL PXC集群的核心价值
PXC的核心价值在于其提供的是一个高
故障恢复计划:机械运动的最佳实践制定与执行

# 1. 故障恢复计划概述
故障恢复计划是确保企业或组织在面临系统故障、灾难或其他意外事件时能够迅速恢复业务运作的重要组成部分。本章将介绍故障恢复计划的基本概念、目标以及其在现代IT管理中的重要性。我们将讨论如何通过合理的风险评估与管理,选择合适的恢复策略,并形成文档化的流程以达到标准化。
## 1.1 故障恢复计划的目的
故障恢复计划的主要目的是最小化突发事件对业务的
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
【深度学习在卫星数据对比中的应用】:HY-2与Jason-2数据处理的未来展望

# 1. 深度学习与卫星数据对比概述
## 深度学习技术的兴起
随着人工智能领域的快速发展,深度学习技术以其强大的特征学习能力,在各个领域中展现出了革命性的应用前景。在卫星数据处理领域,深度学习不仅可以自动
拷贝构造函数的陷阱:防止错误的浅拷贝
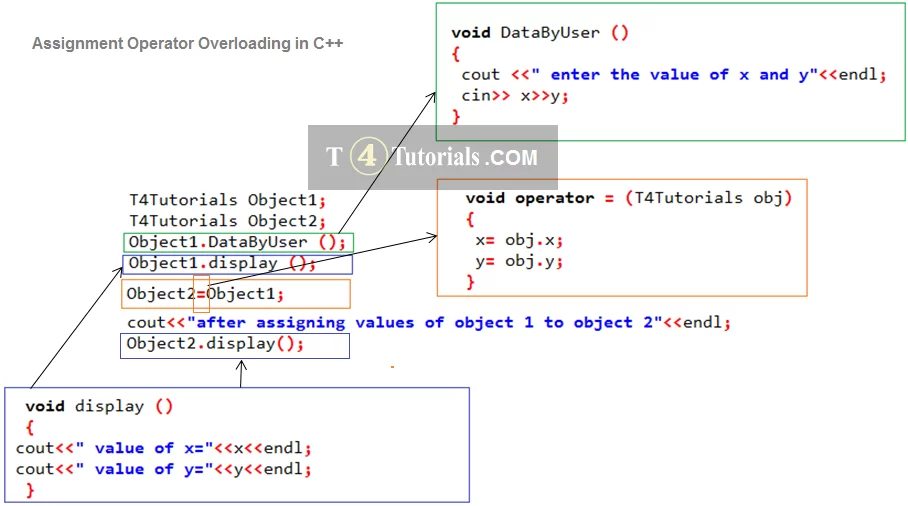
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
消息队列在SSM论坛的应用:深度实践与案例分析

# 1. 消息队列技术概述
消息队列技术是现代软件架构中广泛使用的组件,它允许应用程序的不同部分以异步方式通信,从而提高系统的可扩展性和弹性。本章节将对消息队列的基本概念进行介绍,并探讨其核心工作原理。此外,我们会概述消息队列的不同类型和它们的主要特性,以及它们在不同业务场景中的应用。最后,将简要提及消息队列
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )