【从Stream到Collectors】:掌握Guava的集合转换之美
发布时间: 2024-09-26 11:44:06 阅读量: 76 订阅数: 27 

java8-guava-comparation:Guava 和 Java 8 Stream API 的比较

# 1. Guava集合处理框架概述
## 1.1 Guava的起源与重要性
Guava是由Google开发的一款开源的Java库,它提供了丰富的集合处理工具,能够简化常见的Java编程任务,从而提高开发效率。在处理集合数据时,Guava提供了一系列便捷的方法和抽象,使开发者可以以更简洁的方式完成复杂的集合操作。
## 1.2 Guava集合框架的特点
Guava集合框架的核心特点是简化了集合操作,提供了包括但不限于集合的创建、转换和过滤等多种实用工具。它还包括了对并发集合的支持,提供了一套强大的不可变集合API,极大地降低了在多线程环境下对集合操作的复杂性。
## 1.3 Guava在现代Java开发中的应用
随着Java版本的迭代,Guava库补充了标准库中尚未实现的一些功能,比如Guava的Optional类用于更好的处理空值问题,以及Multimap、Table等集合类型提供了多数据源管理的便利。在实际的项目开发中,Guava的这些特性可以帮助开发者构建出更健壮、可维护性更强的应用程序。
# 2. Stream的基本理论与实践
## 2.1 Stream的核心概念和构建
### 2.1.1 Stream的定义和特性
Stream 是 Java 8 引入的一个新的抽象层,用于处理数据集合。它可以对集合进行声明式的操作,使用函数式编程风格,从而让代码更简洁、更易于阅读。Stream 不是集合,它没有存储数据的结构,而是对数据的处理和计算,可以看作是一个高级的迭代器。
Stream 的主要特性包括:
- **不可变性**:一旦创建了 Stream,就无法修改其内部状态。
- **延迟执行**:大多数 Stream 操作都是延迟执行的,这意味着它们会在实际需要结果时才执行。
- **函数式编程**:Stream 支持函数式编程范式,允许以声明式方式操作数据,而不需要编写复杂的循环和条件语句。
- **管道化**:多个操作可以链接起来形成一个流水线,每个操作都会返回一个新的 Stream,使得多个操作可以连接起来。
### 2.1.2 创建Stream的方法
创建 Stream 可以使用多种方式,最常见的是通过集合、数组或者特定的 Stream 类方法。下面是一些创建 Stream 的常用方法:
- **集合的 stream 方法**:通过调用集合类(如 List 或 Set)的 `stream()` 方法来创建流。
```java
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> stream = list.stream();
```
- **数组的 Stream.of 方法**:使用 `Stream.of()` 方法从数组创建一个流。
```java
String[] array = {"a", "b", "c"};
Stream<String> stream = Stream.of(array);
```
- **静态的 Stream.generate 和 Stream.iterate 方法**:这两个方法可以创建一个无限流,`generate` 方法接受一个供应函数来不断产生新的元素,而 `iterate` 方法从一个初始值开始,应用一个函数来产生新的值。
```java
Stream<Double> randomStream = Stream.generate(Math::random);
Stream<Integer> evenStream = Stream.iterate(0, n -> n + 2);
```
- **IntStream、LongStream、DoubleStream 的范围和数值流**:这些特定类型的流用于表示原始数据类型流,并提供了额外的专门方法。
```java
IntStream range = IntStream.range(1, 10);
LongStream longStream = LongStream.rangeClosed(1, 10);
```
## 2.2 Stream的操作类型和使用
### 2.2.1 中间操作:filter、map、flatMap
中间操作是 Stream API 中用于转换和过滤数据流的方法,它们总是返回一个新的 Stream,可以链接起来形成一个流水线。常见的中间操作包括 `filter`、`map` 和 `flatMap`。
- **filter**:根据给定的谓词(一个返回布尔值的函数)筛选流中的元素。
```java
Stream<String> filtered = stream.filter(s -> s.startsWith("a"));
```
- **map**:将流中的每个元素映射到对应的值,它会应用一个函数并返回应用后的结果。
```java
Stream<Integer> mapped = stream.map(String::length);
```
- **flatMap**:将流中的每个元素转换成另一个流,然后将所有流连接到一个流中。
```java
Stream<List<String>> streamOfLists = Arrays.asList(someLists);
Stream<String> flatStream = streamOfLists.flatMap(List::stream);
```
### 2.2.2 终端操作:reduce、collect、forEach
终端操作是 Stream API 中用于处理流并产生结果的方法。这些方法执行实际的数据处理,例如聚合、收集到容器中或执行某个操作。常见的终端操作有 `reduce`、`collect` 和 `forEach`。
- **reduce**:对流中的元素进行累积操作,可以是求和、求最大值等。
```java
Optional<Integer> sum = stream.reduce((a, b) -> a + b);
```
- **collect**:将流中的元素收集到一个集合中,可以使用 Collector 提供的收集器(如 toList、toSet、groupingBy 等)。
```java
List<String> collected = stream.collect(Collectors.toList());
```
- **forEach**:对流中的每个元素执行给定的操作。
```java
stream.forEach(System.out::println);
```
### 2.2.3 短路操作:anyMatch、allMatch、noneMatch
短路操作是指,一旦结果可以确定,就不会继续处理流中剩余的元素。这样可以提高处理效率。常见的短路操作有 `anyMatch`、`allMatch` 和 `noneMatch`。
- **anyMatch**:检查至少有一个元素满足特定条件。
```java
boolean anyMatch = stream.anyMatch(s -> s.contains("a"));
```
- **allMatch**:检查所有元素都满足特定条件。
```java
boolean allMatch = stream.allMatch(String::isEmpty);
```
- **noneMatch**:检查没有任何元素满足特定条件。
```java
boolean noneMatch = stream.noneMatch(s -> s.contains("z"));
```
## 2.3 Stream的性能优化
### 2.3.1 惰性求值与即时求值
Stream 的操作有两种主要的求值方式:惰性求值和即时求值。了解这两种求值方式对于优化 Stream 性能至关重要。
- **惰性求值**:只有在实际需要结果时才进行计算。中间操作通常是惰性求值的,只有在终端操作调用时,中间操作才会执行。
- **即时求值**:一旦数据源可用,就开始执行操作并产生结果。`forEach` 和 `reduce` 等终端操作就是即时求值的。
```java
Stream<String> stream = list.stream();
stream.filter(s -> {
System.out.println(" Filtering " + s);
return s.startsWith("a");
}).map(s -> {
System.out.println(" Mapping " + s);
return s.toUpperCase();
}).forEach(s -> System.out.println(" ForEach " + s));
```
在上面的例子中,中间操作 filter 和 map 都是惰性求值的,只有当执行了 forEach 这个终端操作时,所有操作才会实际执行。
### 2.3.2 并行流的创建与注意事项
并行流可以利用多核处理器的性能,通过并行化操作来加速处理。在创建并行流时,可以使用 `parallelStream()` 方法,或者在常规流上调用 `.parallel()` 方法。
```java
Stream<String> parallelStream = list.parallelStream();
```
或者
```java
Stream<String> stream = list.stream();
Stream<String> parallelStream = stream.parallel();
```
然而,并行流并不总是最优选择。并行处理会带来上下文切换和线程管理的开销,特别是在处理小数据集或简单操作时,可能比串行流更慢。在使用并行流时需要注意以下几点:
- 尽量使用无副作用的函数:避免在流操作中使用共享状态,这可以防止并发问题。
- 尽量避免不必要的对象创建:每次对象创建都会带来垃圾回收的压力。
- 考虑数据的分割和合并开销:并行流需要将数据分割到不同的线程上,然后合并结果,这个过程是有成本的。
- 使用合适的线程数:Java 的默认线程数可能不适合所有场景,有时候自定义线程池可以提高性能。
```java
// 使用并行流进行数据处理,同时自定义线程池
ExecutorService executorService = Executors.newFixedThreadPool(4);
Stream<String> stream = list.parallelStream();
Stream<String> processedStream = stream.parallel().unordered().map(...);
List<String> result = processedStream.collect(Collectors.toList());
```
在上述示例中,通过 `unordered()` 方法提升并行处理的性能,然后通过自定义的线程池来控制并行流的执行。需要注意,对于具体的业务场景和硬件环境,最佳实践可能有所不同,因此在实施并行流时应进行充分的性能测试。
# 3. 深入Collectors的原理和应用
## 3.1 Collectors的分类和功能
### 3.1.1 分类概述:归约、分组、分区
Collectors是Java 8引入的一个强大的工具类,它提供了许多便捷的方法来进行数据收集,主要可以分为三大类:归约、分组、分区。
**归约(Reduction)** 操作可以将流中的元素组合起来,生成一个单一的结果。例如,我们可以使用归约来获取流中的最小值、最大值、总和或平均值。
**分组(Grouping)** 是按照某些标准将元素分到不同的组中。这种操作非常适合分类任务,例如按部门或按性别分组。
**分区(Partitioning)** 类似于分组,但是它只使用一个条件来判断元素属于两个分区中的哪一个,分区通常返回一个Map,其键为Boolean类型,表示条件是否满足,值为对应的分组。
### 3.1.2 常用Collectors的介绍
为了更深入地理解Collectors,我们可以看看几个常用的静态方法:
- `Collectors.toList()`:将流中的元素收集到一个List中。
- `Collectors.toSet()`:将流中的元素收集到一个Set中,帮助去除重复项。
- `Collectors.toMap()`:创建一个映射,以键为一个函数,以值为另一个函数的结果。
- `Collectors.counting()`:计算流中的元素数量。
- `Collectors.summingInt()`、`Collectors.summingLong()`、`Collectors.summingDouble()`:计算流中的元素对应整数、长整数或双精度浮点数的总和。
- `Collectors.averagingInt()`、`Collectors.averagingLong()`、`Collectors.averagingDouble()`:计算流中的元素对应类型数值的平均值。
这些收集器可以相互结合使用,以实现更复杂的数据收集任务。下面章节将深入探讨如何实现自定义Collectors,并分享一些高级收集技巧。
## 3.2 实现自定义Collectors
### 3.2.1 自定义收集器的设计步骤
自定义Collectors需要遵循一定的设计模式。通常,这涉及到实现`java.util.stream.Collector`接口。接口中的关键方法如下:
```java
public interface Collector<T, A, R> {
Supplier<A> supplier();
BiConsumer<A, T> accumulator();
BinaryOperator<A> combiner();
Function<A, R> finisher();
Set<Characteristics> characteristics();
// ...
}
```
- **Supplier<A> supplier()**:创建一个新的结果容器,比如用于收集数据的List或Map。
- **BiConsumer<A, T> accumulator()**:在结果容器中添加单个元素,例如将元素添加到List或Map中。
- **BinaryOperator<A> combiner()**:在并行处理时合并两个结果容器。
- **Function<A, R> finisher()**:转换结果容器为最终结果类型,例如将List转换为Set。
- **Set<Characteristics> characteristics()**:提供关于收集器特性的一些附加信息,如是否并行处理、是否无序等。
### 3.2.2 实践案例分析
假设我们需要实现一个收集器来计算一个字符串列表中每个单词的出现频率。下面是一个简单的实现示例:
```java
import java.util.*;
import java.util.function.BiConsumer;
import java.util.function.BinaryOperator;
import java.util.function.Function;
import java.util.function.Supplier;
import java.util.stream.Collector;
public class FrequencyCollector implements Collector<String, Map<String, Long>, Map<String, Long>> {
@Override
public Supplier<Map<String, Long>> supplier() {
return HashMap::new;
}
@Override
public BiConsumer<Map<String, Long>, String> accumulator() {
return (map, word) -> map.merge(word, 1L, Long::sum);
}
@Override
public BinaryOperator<Map<String, Long>> combiner() {
return (map1, map2) -> {
map1.putAll(map2);
return map1;
};
}
@Override
public Function<Map<String, Long>, Map<String, Long>> finisher() {
return Function.identity();
}
@Override
public Set<Characteristics> characteristics() {
return Collections.unmodifiableSet(EnumSet.of(Characteristics.IDENTITY_FINISH));
}
public static void main(String[] args) {
List<String> words = Arrays.asList("apple", "banana", "apple", "orange", "banana", "apple");
Map<String, Long> wordCounts = words.stream()
.collect(new FrequencyCollector());
System.out.println(wordCounts);
}
}
```
在上面的代码中,`FrequencyCollector`通过实现Collector接口的方法定义了如何将字符串流中的单词收集到Map中,并且计算它们的频率。
## 3.3 高级收集技巧
### 3.3.1 与Stream API的结合使用
当我们在处理复杂的数据结构时,往往需要将Collectors与Stream API的其他部分结合起来使用。例如,我们可以使用`map`和`collect`结合

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面介绍了 Google Guava 库中强大的 com.google.common.collect 库,它提供了丰富的集合处理工具,旨在简化 Java 开发人员的日常任务。从基础概念到高级技巧,本专栏涵盖了广泛的主题,包括集合构建、操作优化、并发编程、流转换、性能优化、数据分组和收集、过滤和映射,以及实战案例。此外,还对 Guava 库与 Java 集合框架进行了深入比较,突出了其作为集合处理首选的优势。通过深入的解释、代码示例和实际应用,本专栏旨在帮助读者掌握 Guava com.google.common.collect 库,并将其应用于他们的项目中,以提高效率、简化代码并提升性能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【开发者必看】:PJSIP常见问题解决大全与调试技巧

# 摘要
PJSIP是一个功能强大的开源通信协议栈,广泛应用于IP多媒体子系统(IMS)和VoIP应用程序中。本文全面介绍了PJSIP的基础架构、配置、通信协议、调试与问题排查、实际应用案例分析以及进阶开发与性能调优。通过对PJSIP的详细解析,本论文旨在帮助开发者快速搭建和优化通信平台,并确保应用的安全性和性能。文章强调了理解SIP协议基础及其在PJSIP中的扩展对于实现高效可靠的通信至关重要。此
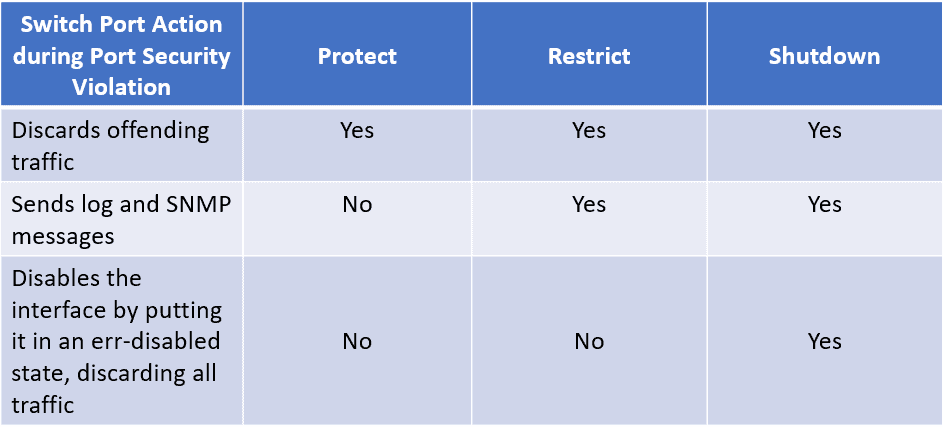
【网络安全守护】:掌握交换机端口安全设置,确保网络无懈可击
# 摘要
随着网络技术的快速发展和网络设备的日益普及,网络安全问题日益突出,其中交换机端口安全成为保障网络稳定运行的关键因素。本文首先概述了网络安全的基本概念和交换机端口安全的基础知识,深入分析了端口安全的重要性和其在防御网络攻击中的作用。接着,本文详细介绍了交换机端口安全策略的配置原则和技术手段,包括MAC地址过滤、DHCP Snooping和Dynamic ARP Inspection等。同
【模拟电路性能升级】:数字电位器在电路中的神奇应用
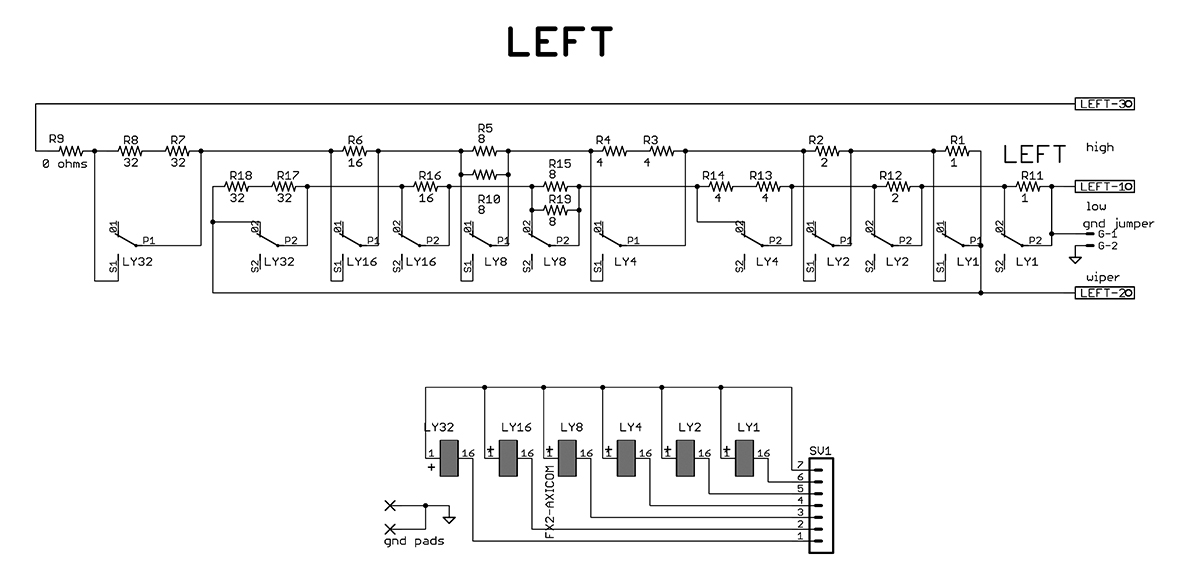
# 摘要
随着电子技术的发展,模拟电路性能的升级已成为推动现代电子系统性能提升的关键因素。数字电位器作为提升模拟电路性能的关键元件,其工作原理、特性及应用越来越受到重视。本文首先介绍了数字电位器的基础知识,包括其基本结构、工作原理以及与模拟电位器的比较分析。接着,深入探讨了数字电位器在信号调整、电源管理和滤波器设计中
【质量监控与优化】:IT系统在花键加工中的关键作用
# 摘要
本文探讨了花键加工与IT系统关联性,重点分析质量
【CAN2.0协议在物联网中的应用】:技术细节与应用潜力深度剖析

# 摘要
CAN2.0协议作为经典的现场总线协议,广泛应用于汽车、工业自动化等多个领域。本文首先对CAN2.0协议的基础知识进行了概述,然后深入分析了其技术细节,包括物理层与数据链路层的主要特性、帧结构、传输机制,以及消息处理、错误处理和网络管理等关键技术。接着,本文探讨了CAN2.0在物联网不同领域中的应用案例,如智能家居、工业自动化和汽车电子通信等。最后,本文展望
【机翻与人译的完美结合】:GMW14241翻译案例分析与技巧分享
# 摘要
翻译行业在数字化转型的浪潮中面临诸多挑战和机遇。本论文首先概述了翻译行业的发展现状和挑战,进而深入分析了机器翻译与专业人工翻译的优势,并探讨了二者的结合对于提升翻译效率与质量的重要性。通过GMW14241翻译案例的分析,本研究揭示了项目管理、团队协作、质量控制等要素对于翻译项目成功的重要性。此外,文中还探讨了提高翻译准确度的技巧、文化转化与表达的方法,以及翻译质量评估与改进的策略。最终,论文展望了翻译技术的未来趋势,并强调了翻译人员终身学习与成长的重要性。
# 关键字
翻译行业;机器翻译;人工翻译;翻译效率;质量控制;文化差异;AI翻译;神经网络;翻译辅助工具;终身学习
参考资源
实时性优化:S7-200 Smart与KEPWARE连接的性能分析与提升

# 摘要
本文综合分析了S7-200 Smart PLC与KEPWARE连接技术的实时性问题及其性能提升策略。文章首先概述了S7-200 Smart PLC的基础知识和KEPWARE的连接技术,然后深入探讨了实时性问题的识别与影响因素。针对这些挑战,本文提出了硬件优化、软件配置调整和网络优化措施,旨在通过实操案例展示如何提升S7-200 Smart PLC的实时性,并评估性
VISA函数高级应用:回调与事件处理的专家解读
# 摘要
本文对VISA(Virtual Instrument Software Architecture)函数及其在现代测试与测量应用中的重要性进行了全面介绍。文章首先介绍了VISA函数的基本概念和环境搭建,随后深入探讨了其回调机制、事件处理、高级应用实践以及跨平台应用策略。通过具体案例分析,本文详细说明了VISA在各种设备交互和复杂应用中的实际应用。文章最
Cyclone CI_CD自动化实践:构建高效流水线,快速迭代部署

# 摘要
本文系统地介绍了Cyclone,这是一个基于容器的CI/CD平台,着重阐述了其基本概念、环境搭建、核心组件解析以及与Kubernetes的集成。文章通过深入实践部分,探讨了自动化测试流水线配置、部署流水线优化策略以及代码版本控制整合,旨在提高软件交付的效率和质量。此外,本文还分析了Cyclone在不同场景的应用,包括微服务架构、多环境部署和大型项目的
文档自动构建与部署流程:工具与实践并重

# 摘要
文档自动构建与部署是提高软件开发效率和文档质量的重要技术实践。本文首先介绍了文档自动构建与部署的基本概念,随后深入探讨了构建和部署工具的理论与实践,并分析了各种工具的选择标准及实际应用效果。在此基础上,本文探讨了版本控制与协作机制,以及如何建立高效的文档版本控制和协作流程。进一步,本文详细阐述了自动化部署流程的设计、实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )