Solr5核心配置文件详解
发布时间: 2023-12-18 21:31:49 阅读量: 35 订阅数: 36 

solr所需配置文件
# 第一章:Solr5概述
1.1 Solr5 简介
1.2 Solr5 核心功能
## 第二章:Solr5 核心配置文件概述
Solr5核心配置文件是Solr搜索引擎的重要组成部分,通过配置文件可以对搜索引擎的行为进行详细控制。本章将介绍Solr5核心配置文件的概述,包括文件结构和主要参数的作用。让我们一起深入了解Solr5核心配置文件的重要性和基本概念。
### 2.1 Solr5 核心配置文件结构
Solr5核心配置文件主要包括solrconfig.xml和schema.xml两个文件。solrconfig.xml文件用于配置Solr实例的行为,而schema.xml文件用于定义索引中的字段和字段类型。这两个文件共同构成了Solr的核心配置,对搜索行为和索引结构起着至关重要的作用。
#### solrconfig.xml 结构示例:
```xml
<?xml version="1.0" encoding="UTF-8" ?>
<config>
<!-- 全局配置 -->
<luceneMatchVersion>6.0.0</luceneMatchVersion>
<dataDir>${solr.data.dir:}</dataDir>
<!-- 请求处理器配置 -->
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="defType">dismax</str>
<str name="qf">title^2.0 body^1.0</str>
</lst>
</requestHandler>
<!-- 请求日志配置 -->
<requestLogger name="requestLogger" class="solr.RequestLogComponent" />
<!-- ... 其他配置 ... -->
</config>
```
#### schema.xml 结构示例:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<schema name="example" version="1.5">
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="title" type="text_general" indexed="true" stored="true" />
<field name="body" type="text_general" indexed="true" stored="true" />
<!-- ... 其他字段定义 ... -->
<uniqueKey>id</uniqueKey>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<!-- ... 词法分析器配置 ... -->
</analyzer>
<analyzer type="query">
<!-- ... 词法分析器配置 ... -->
</analyzer>
</fieldType>
</schema>
```
### 2.2 核心配置文件中的主要参数
在Solr5核心配置文件中,有许多重要的参数需要进行配置,主要包括请求处理器、请求日志、字段定义、词法分析器等。这些参数直接影响着搜索的行为和性能表现,需要根据实际需求进行详细的配置和调优。
在solrconfig.xml文件中,可以配置请求处理器的默认参数,设置请求日志的记录方式,定义搜索组件等。而在schema.xml文件中,可以定义索引中的字段类型、字段属性、唯一键等信息,还可以配置词法分析器对文本进行分词和处理。
在接下来的章节中,我们将对Solr5核心配置文件中的各项参数进行详细的解析和示例,帮助读者更好地理解这些配置参数的作用和使用方法。
以上是Solr5核心配置文件概述的内容,下一步我们将深入分析solrconfig.xml和schema.xml文件的具体配置细节。
### 第三章:Solr5 核心配置文件详解
在Solr5中,核心配置文件起着至关重要的作用。其中,solrconfig.xml和schema.xml是两个最为重要的配置文件。它们定义了Solr的行为,包括索引、查询、分析等方方面面。下面我们将详细解析这两个配置文件。
#### 3.1 solrconfig.xml详解
solrconfig.xml文件定义了Solr的全局配置,包括请求处理、缓存、更新流程、插件等。在solrconfig.xml中,我们可以配置各种请求处理器和搜索组件,以及设置请求处理链的执行顺序。
```xml
<!-- 示例代码:定义请求处理器 -->
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="qf">title^5.0 text^1.0</str>
</lst>
</requestHandler>
```
*注释:上面的示例代码定义了一个名为`/select`的请求处理器,使用了solr.SearchHandler类。其中`<lst name="defaults">`用于设置默认参数,这里设置了查询字段权重。*
#### 3.2 schema.xml详解
schema.xml文件定义了Solr的索引结构,包括字段类型、字段属性、动态字段等。在schema.xml中,我们可以定义索引中的字段,并配置字段的属性、分词器等。
```xml
<!-- 示例代码:定义字段类型 -->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" words="stopwords.txt" ignoreCase="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
```
*注释:上面的示例代码定义了一个名为`text_general`的字段类型,使用了solr.TextField类。在该字段类型中指定了分词器为StandardTokenizerFactory,并使用了StopFilterFactory进行停用词过滤。*
通过对solrconfig.xml和schema.xml的详细解析,我们可以更深入地理解Solr的核心配置文件,进而灵活地配置和定制Solr的行为。
### 第四章:Solr5 核心配置文件高级配置
#### 4.1 Query Parser 配置
在Solr中,Query Parser用于解析查询语句并将其转换为可执行的查询。在Solr5的核心配置文件中,可以通过配置Query Parser来实现高级的查询功能,例如布尔查询、短语查询、通配符查询等。以下是一个基本的Query Parser配置示例:
```xml
<!-- solrconfig.xml -->
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="defaults">
<str name="defType">edismax</str>
<str name="qf">title^5.0 text^1.0</str>
<str name="pf">title^10.0 text^3.0</str>
</lst>
</requestHandler>
```
在上面的示例中,我们配置了名为"select"的请求处理程序,其Query Parser的类型为"edismax",并且设置了"qf"参数和"pf"参数来定义查询时的权重。在实际应用中,我们可以根据具体的需求进行更复杂的配置,包括布尔逻辑、模糊查询、短语查询等高级查询功能。
#### 4.2 过滤器配置
过滤器在Solr中承担着非常重要的作用,它们用于对检索结果进行过滤,并且可以实现很多高级的功能,如数据清洗、数据转换、数据格式化等。在Solr5的核心配置文件中,可以通过配置过滤器来实现对检索结果的精细化控制。以下是一个常见的过滤器配置示例:
```xml
<!-- solrconfig.xml -->
<requestHandler name="/select" class="solr.SearchHandler">
<lst name="invariants">
<str name="facet.date">timestamp</str>
<str name="facet.date.start">NOW/YEAR-10YEARS</str>
<str name="facet.date.end">NOW</str>
<str name="facet.date.gap">+1YEAR</str>
</lst>
</requestHandler>
```
在上面的示例中,我们配置了名为"select"的请求处理程序,设置了一个日期过滤器,用于按照时间范围对检索结果进行过滤。通过这样的配置,我们可以灵活地实现按照时间进行聚合统计、分析或者可视化展示等功能。
#### 4.3 词法分析器配置
词法分析器在Solr中起着至关重要的作用,它决定了文本在检索和索引时如何被分析和处理。通过配置词法分析器,我们可以实现对检索文本的分词、同义词处理、大小写转换等功能。以下是一个简单的词法分析器配置示例:
```xml
<!-- schema.xml -->
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
</analyzer>
</fieldType>
```
在上面的示例中,我们配置了一个名为"text_general"的字段类型,定义了在索引和查询时使用的词法分析器链。通过这样的配置,我们实现了对文本的分词、转换和同义词处理,从而提高了检索的准确性和效率。
## 第五章:Solr5 核心配置文件调优
在使用Solr5进行全文搜索时,为了提高查询性能和索引性能,我们需要对核心配置文件进行一定的调优。本章节将介绍如何进行Solr5核心配置文件的调优,以实现更高效的全文检索服务。
### 5.1 查询性能优化
对于查询性能的优化,需要考虑以下几个方面:
#### 5.1.1 查询缓存设置
在solrconfig.xml中,可以通过配置queryResultCache和documentCache来控制查询结果和文档的缓存。通过合理设置缓存大小和过期时间,可以有效提高查询性能。
```xml
<query>
<filterCache class="solr.LRUCache"
size="40960"
initialSize="20480"
autowarmCount="4096"/>
<queryResultCache class="solr.LRUCache"
size="163840"
initialSize="81920"
autowarmCount="16384"/>
<documentCache class="solr.LRUCache"
size="40960"
initialSize="20480"
autowarmCount="4096"/>
</query>
```
#### 5.1.2 搜索组件配置
根据实际需求,可以在solrconfig.xml中配置搜索组件,比如按字段进行检索、拼写检查等,以提高查询的准确性和效率。
```xml
<searchComponent name="my_component" class="solr.SpellCheckComponent">
<str name="queryAnalyzerFieldType">text_general</str>
<lst name="spellchecker">
<str name="name">default</str>
<str name="field">name</str>
<str name="spellcheckIndexDir">./spellchecker</str>
</lst>
</searchComponent>
```
### 5.2 索引性能优化
针对索引性能的优化,可以考虑以下几点:
#### 5.2.1 索引缓存设置
在solrconfig.xml中可以通过配置indexConfig来设置索引缓存的大小和策略,以加快索引操作的速度。
```xml
<indexConfig>
<ramBufferSizeMB>64</ramBufferSizeMB>
<mergeFactor>10</mergeFactor>
<maxBufferedDocs>10000</maxBufferedDocs>
</indexConfig>
```
#### 5.2.2 自动优化策略
通过配置autoCommit和autoSoftCommit,可以实现自动提交和软提交索引的策略,从而提高索引性能。
```xml
<autoCommit>
<maxTime>15000</maxTime>
<openSearcher>false</openSearcher>
</autoCommit>
<autoSoftCommit>
<maxTime>3000</maxTime>
</autoSoftCommit>
```
经过以上调优措施,可显著提升Solr5的查询性能和索引性能,使其更适应大规模数据处理及高并发查询的需求。
## 第六章:Solr5 核心配置文件实例分析
在本章中,我们将通过两个具体的实例来分析Solr5核心配置文件的应用。我们将介绍如何搭建全文搜索引擎和将Solr应用于电商网站的商品搜索。
### 6.1 实例一:搭建全文搜索引擎
#### 场景描述
假设我们需要搭建一个全文搜索引擎,可以对网站的文章内容进行搜索。我们将使用Solr5作为搜索引擎的后台,通过配置核心配置文件来实现相关功能。
#### 实现步骤
1. 创建一个名为"fulltext"的Core。
2. 在solrconfig.xml中配置请求处理程序,定义搜索请求处理流程。
3. 设计schema.xml,定义数据的索引结构。
#### 代码和配置
```xml
<!-- solrconfig.xml -->
<requestHandler name="/search" class="solr.SearchHandler">
<lst name="defaults">
<str name="df">text</str>
<str name="q.alt">*:*</str>
<str name="fl">*,score</str>
</lst>
</requestHandler>
```
```xml
<!-- schema.xml -->
<field name="id" type="string" indexed="true" stored="true" required="true"/>
<field name="text" type="text_general" indexed="true" stored="false"/>
<fieldType name="text_general" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/>
<filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
```
#### 代码总结
在这个例子中,我们创建了一个名为“fulltext”的Core,并配置了请求处理程序和索引字段的分词器。请求处理程序定义了默认搜索字段和返回字段,并且在schema.xml中定义了文本字段的索引结构,包括分词器的设置。
#### 结果说明
通过以上配置,我们成功搭建了一个全文搜索引擎,并且定义了文本字段的索引结构和搜索请求处理流程。
### 6.2 实例二:应用于电商网站的商品搜索
#### 场景描述
假设我们需要将Solr应用于电商网站的商品搜索,可以对商品名称、描述等进行搜索。我们将使用Solr5作为商品搜索的后台,并通过配置核心配置文件来实现相关功能。
#### 实现步骤
1. 创建一个名为"products"的Core。
2. 在solrconfig.xml中配置请求处理程序,定义商品搜索请求处理流程。
3. 设计schema.xml,定义商品数据的索引结构。
#### 代码和配置
```xml
<!-- solrconfig.xml -->
<requestHandler name="/productSearch" class="solr.SearchHandler">
<lst name="defaults">
<str name="df">productName</str>
<str name="q.alt">*:*</str>
<str name="fl">productName,price,category,score</str>
</lst>
</requestHandler>
```
```xml
<!-- schema.xml -->
<field name="id" type="string" indexed="true" stored="true" required="true"/>
<field name="productName" type="text_general" indexed="true" stored="true"/>
<field name="description" type="text_general" indexed="true" stored="true"/>
<field name="price" type="double" indexed="true" stored="true"/>
<field name="category" type="string" indexed="true" stored="true"/>
```
#### 代码总结
在这个例子中,我们创建了一个名为“products”的Core,并配置了商品搜索请求处理程序和商品数据的索引字段。请求处理程序定义了默认搜索字段和返回字段,并且在schema.xml中定义了商品数据的索引结构。
#### 结果说明
通过以上配置,我们成功将Solr应用于电商网站的商品搜索,定义了商品数据的索引结构和商品搜索请求处理流程。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Solr5搜索引擎教程》专栏详细介绍了Solr5搜索引擎的各个方面,旨在帮助读者全面了解和掌握Solr5的使用技巧与优化方法。专栏由一系列文章组成,从初识Solr5的安装与配置开始,逐步深入探究Solr5的核心配置文件、索引文档的添加、更新和删除等操作。同时,还剖析了Solr5的搜索请求处理流程、搜索组件的深入应用、查询解析器的原理与应用,以及过滤器和查询时间分析器的介绍。此外,专栏还涵盖了Solr5文档处理、高级搜索功能实践、排序和分页策略等内容。专栏还探讨了Solr5复杂查询构建指南、搜索结果高亮与摘要显示、Facet在搜索中的应用、数据聚合与分析等主题。此外,还包含了Solr5中文分词器的配置与优化、索引优化与性能调优实践、多核心管理与集群部署、数据备份与恢复策略,以及Solr5与数据库集成技术的详细解析。通过阅读本专栏,读者能够系统地学习和掌握Solr5搜索引擎的应用和优化技巧,为提升搜索功能和性能提供了重要的参考。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
数据隐私法规遵循:企业合规之路,权威指导手册
# 摘要
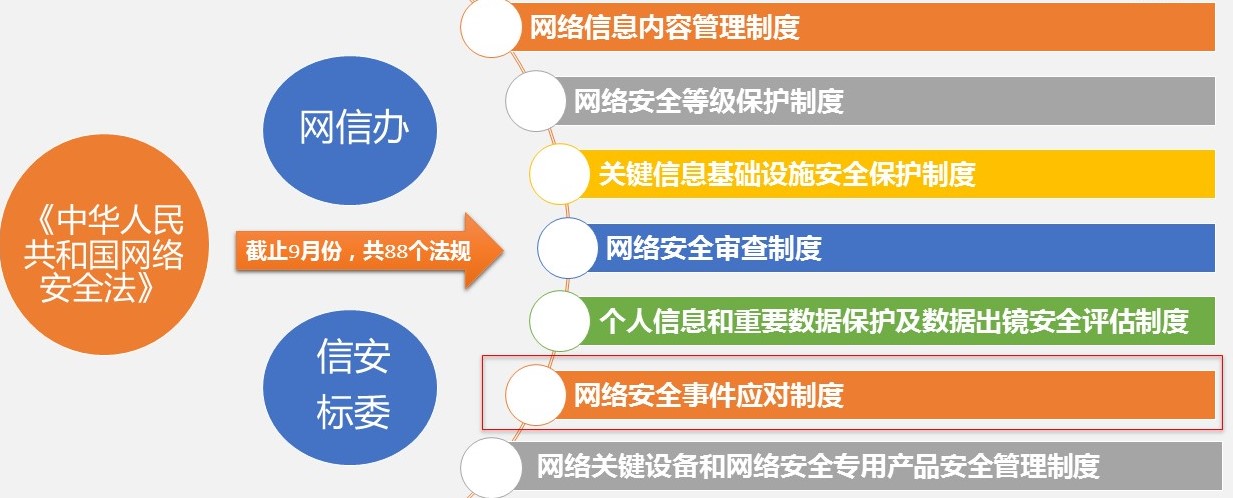
随着全球数据隐私法规的日益严格,企业面临着合规建设的重大挑战。本文首先概述了数据隐私法规的发展趋势,随后详细介绍了企业如何建设合规基础,包括解读法规、制定政策、搭建技术架构。第三章重点讨论了确保合规流程与操作实践的实施,包括数据收集、处理、用户隐私权保护以及应对数据泄露的应急响应计划。第四章探讨了合规技术与工具的应用,强调了数据加密、隐私增强技术和数据生命周期管理工具的重要性。最后,本文第五章提出了合规评估与持续改进
【CMT2300开发新手指南】:从零到专家的全面基础配置教程
# 摘要
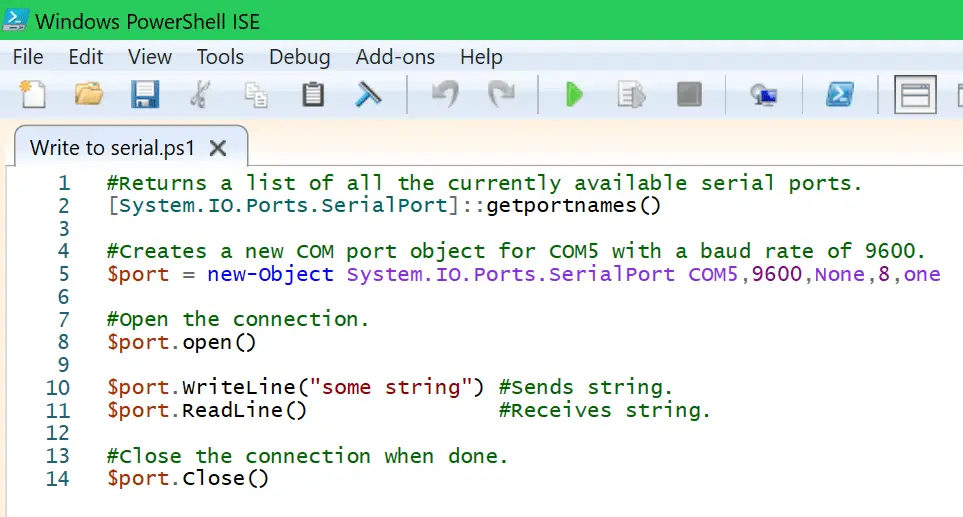
本文全面介绍了CMT2300开发环境的搭建和使用,涵盖了硬件基础配置、软件环境搭建、开发实践基础、进阶开发技巧以及项目管理与部署的各个方面。首先,对CMT2300的硬件结构进行了详细解析,并介绍了基础外设的使用和电源管理策略。其次,讨论了如何安装操作系统、配置驱动程序和开发工具链,为开发实践打下基础。接着
1stOpt 5.0 VS 传统软件:选择谁,为何选择?

# 摘要
本文旨在比较1stOpt 5.0与传统优化软件的功能差异,分析其核心技术特点,并通过实操演练展示其在解决优化问题中的实际效果。文章深入解析了1stOpt 5.0中非线性优化算法的演进,包括算法的理论基础和实际表现,同时指出了传统优化软件的局限性。通过行业案例的深度剖析,本文揭示了1stOpt在工程领域和学术研究中的应用优势和对科研创新的贡献。最后,本文展望了1stOpt 5.0的未来发展趋势,评估了其可能
【IFPUG与敏捷】:敏捷开发中功能点估算的有效融合
/filters:no_upscale()/articles/size-estimation-agile/en/resources/43.png)
# 摘要
随着软件开发方法的演进,敏捷开发已成为业界广泛采纳的实践。本文系统地介绍了敏捷开发与功能点分析(FPA)的融合,首先概述了敏捷开发的原理和IFPUG功能点计数方法论,重点分析了IFPUG的计数规则及其在实践中的应用和复杂性调整。接着,文章探讨了功能点分析在敏捷开发环境中的应用,
博途TIA PORTAL V18数据管理大师:精通数据块与变量表
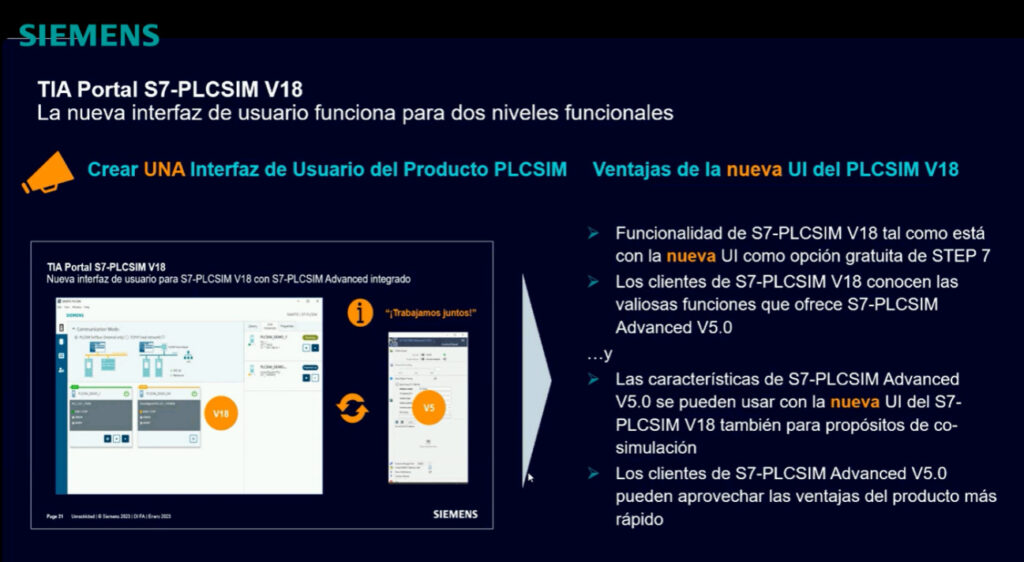
# 摘要
本文针对TIA Portal V18的数据管理进行了全面的探讨。首先介绍了数据块的种类和应用,深入分析了实例数据块(IDB)和全局数据块(GDB)的设计原则与使用场景,以及数据块的层次化组织和变量声明。接着,详细解析了变量表的作用、创建和配置方法,以及维护和优化策略。文章还分享了数据块和变量表在实际应用中的编程实践、管理实践和集成技巧,强调了数据备份与恢复机制,以及数据
【DoIP车载诊断协议全解析】:从入门到精通的6个关键步骤

# 摘要
DoIP车载诊断协议是汽车电子领域中用于车辆诊断与通信的重要协议。本文首先概述了DoIP协议的基本概念,接着详细探讨了其基础知识点,包括数据结构、通信模型和关键概念。在此基础上,通过实践操作章节,本文提供了DoIP工具与软件的搭建方法以及消息交换流程,还介绍了故障诊断的实例和策略。在高级应用章节中,
HEC-RAS模型构建指南:从入门到精通的10个实用技巧

# 摘要
HEC-RAS模型作为一款成熟的水力分析工具,在洪水风险评估、河流整治和防洪管理等领域扮演着重要角色。本文首先概述了HEC-RAS模型的基本原理和理论基础,详细探讨了其在水文模型与洪水分析中的应用,包括水文学原理、流域分析以及一维与二维模型的选择。接着,通过实践指南深入分析模型构建的各个步骤,包括前期准备、建立与配置、以及校验与验证方法。在高级应用章节,本文着
【ANSA体网格创建秘籍】:从入门到精通,快速掌握高效网格设计

# 摘要
本文系统性地介绍了ANSA体网格创建的全过程,涵盖理论基础、实践操作及进阶应用。首先概述了体网格创建的重要性及基本概念,随后深入探讨了网格生成的理论基础和实践技巧,包括模
【测控系统技术精英】:第二章原理与设计要点总结及案例分析
# 摘要
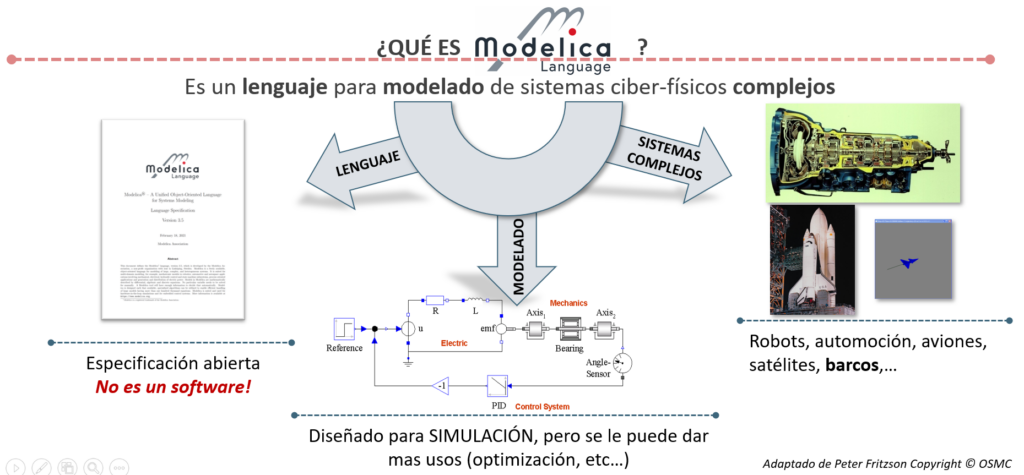
测控系统作为实现自动化控制的关键技术,其在工业、实验室和特殊环境中的应用逐渐增多。本文首先介绍了测控系统的技术概述和设计要点,包括理论基础、硬件设计、软件架构以及人机交互。通过分析工业和实验室测控系统案例,揭示了系统在不同应用环境中的实现和优化方法。进而,本文阐述了性能评估的关键指标和优化策略,最后探讨了新技术的应用和测控系统的发展趋势,同时也指出了实践中的挑战和解决方
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )