Solr5文档处理:提取、转换与加载
发布时间: 2023-12-18 21:46:21 阅读量: 33 订阅数: 34 
# 1. Solr5 简介
## 1.1 Solr5 的概述与特性
Apache Solr是一个开源的搜索平台,用于构建强大的搜索应用程序。Solr5是Solr的一个重要版本,引入了许多新特性和改进。它提供了分布式搜索、大规模数据处理、多种数据格式支持等功能,使得用户可以轻松地构建复杂的搜索引擎和文档处理系统。
Solr5的主要特性包括:
- 分布式搜索:Solr5支持分布式搜索,可以水平扩展以处理大规模数据。
- 多种数据格式支持:Solr5支持处理多种数据格式,包括JSON、XML、CSV等。
- 多语言支持:Solr5提供了全文搜索和分析多种语言的能力。
- 高可用性:Solr5具有高可用性和容错性,可以保证系统的稳定性和可靠性。
## 1.2 Solr5 的文档处理功能介绍
Solr5不仅可以用于搜索,还提供了丰富的文档处理功能,包括文档提取、转换和加载。这些功能使得Solr5成为一个强大的文档处理平台,能够处理各种类型的文档数据,并提供丰富的数据处理和分析功能。在接下来的章节中,我们将分别介绍Solr5的文档提取、转换和加载功能,并对每个功能进行详细的讲解和实际应用案例分析。
# 2. 文档提取
在 Solr5 中,文档提取是指从各种数据源中提取文档并将其加载到 Solr 索引中的过程。文档提取是搜索引擎实现全文检索的基础,Solr5 提供了多种方法来进行文档提取,下面将介绍其中的一些方法。
### 2.1 使用Solr5 提取文档的方法
Solr5 提供了多种方式来提取文档,包括使用 DataImportHandler 从关系数据库中提取数据、利用 ExtractingRequestHandler 提取文档中的结构化内容、使用 Apache Tika 来解析各种格式的文档等。其中,DataImportHandler 是 Solr 中用于提取结构化数据的重要组件,它能够轻松地从关系数据库中提取数据,并对数据进行转换后加载到 Solr 索引中。
#### 使用 DataImportHandler 提取数据
```java
// 在 Solr 配置文件中配置 DataImportHandler
<dataConfig>
<dataSource type="JdbcDataSource"
driver="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost/dbname"
user="username"
password="password"/>
<document>
<entity name="item"
query="SELECT id, name, price, description FROM items"
transformer="RegexTransformer">
<field column="id" name="id" />
<field column="name" name="name" />
<field column="price" name="price" />
<field column="description" name="description" />
</entity>
</document>
</dataConfig>
```
上面是一个简单的 DataImportHandler 配置示例,通过配置 DataImportHandler,即可从 MySQL 数据库中提取数据并加载到 Solr 索引中。
### 2.2 文档提取的实际应用案例分析
除了上述的方式,Solr5 还可以通过 ExtractingRequestHandler 提取文档中的结构化内容。这在处理文本文档和各种格式的文件时非常有用,比如 PDF、Word、HTML 等格式的文档。
```java
// 使用 ExtractingRequestHandler 提取文档
SolrInputDocument doc = new SolrInputDocument();
doc.addField("id", "doc1");
doc.addField("content", new File("example.docx"));
solrClient.add(doc);
solrClient.commit();
```
上面的代码演示了如何使用 ExtractingRequestHandler 从 word 文档中提取内容,并将其加载到 Solr 索引中。
文档提取在企业应用中具有重要作用,例如在搜索引擎、文档管理系统等方面的应用。通过合理利用 Solr5 的文档提取功能,可以提升企业信息处理的效率与速度。
以上是 Solr5 文档提取的简要介绍与实际应用案例分析,下一节将会介绍文档转换的功能与应用。
# 3. 文档转换
在 Solr5 中,文档转换是一个非常重要的功能,它可以帮助我们将文档从一种格式转换为另一种格式,或者对文档进行一些特定的处理,以便更好地适应搜索引擎的需求。本章将介绍 Solr5 中文档转换的功能与用途,以及文档转换常见技术与实践经验分享。
#### 3.1 Solr5 中文档转换的功能与用途
Solr5 中的文档转换功能主要包括以下几个方面:
- **格式转换:** 将文档从一种格式转换为另一种格式,比如从 PDF 转换为 HTML、从 Word 转换为纯文本等,以便更好地适应搜索引擎的索引和检索需求。
- **内容处理:** 对文档内容进行处理,比如去除特定格式的标记、提取关键信息、进行语言翻译等,以便提高搜索结果的质量和准确性。
- **数据清洗:** 对文档数据进行清洗和规范化,比如去除重复数据、统一数据格式、修复数据错误等,以便提高搜索引擎对文档数据的理解和利用能力。
在实际应用中,文档转换功能可以帮助用户更好地管理和利用各种文档数据,提高搜索引擎的效率和效果,同时也可以为企业的信息管理和知识发现提供重要支持。
#### 3.2 文档转换常见技术与实践经验分享
在 Solr5 中,文档转换常见的技术和实践经验包括:
- **使用 Tika 进行文档解析:** Apache Tika 是一个强大的文档解析工具,可以帮助我们从各种文件格式中提取文本内容,包括 PDF、Word、HTML、XML 等,可以作为 Solr5 文档转换的重要工具之一。
- **编写自定义的文档转换插件:** 根据实际需求,我们可以借助 Solr5 提供的插件机制,编写自定义的文档转换插件,实现特定格式的文档转换、内容处理和数据清洗功能。
- **结合外部系统进行文档转换:** 在企业环境中,文档转换往往需要结合外部系统,比如将文档上传至云存储平台进行转换,再将转换后的文档加载到 Solr5 中,这样可以更好地利用各类资源和服务。
通过合理的技术选择和实践经验分享,我们可以更好地利用 Solr5 的文档转换功能,提高搜索引擎的效率和准确性,为用户提供更好的搜索体验。
以上是Solr5中文档转换的功能与用途,以及文档转换常见技术与实践经验分享,希望对您有所帮助。
# 4. 文档加载
在 Solr5 中,文档加载是指将数据源中的文档加载到 Solr 索引中的过程。它通常包括数据的获取、转换与存储三个步骤。下面我们将详细介绍 Solr5 文档加载的流程与原理,并且给出文档加载在企业应用中的实际应用案例。
#### 4.1 Solr5 文档加载的流程与原理
Solr5 文档加载的流程可以分为以下几个步骤:
1. 数据源选择:首先需要选择适当的数据源,如数据库、文件系统、Web API等。根据数据源的类型和特点,选择合适的数据获取方式。
2. 数据获取:根据所选择的数据源,使用相应的技术和工具来获取数据。例如,如果数据存储在关系型数据库中,可以使用 JDBC 来连接数据库并执行 SQL 查询获取数据;如果数据存储在文件系统中,可以使用 Java 的文件操作 API 来读取文件内容。
3. 数据转换:获取到的原始数据一般不是直接适用于 Solr 的文档模式的,需要进行数据转换。数据转换可以包括数据清洗、数据格式转换、数据字段映射等操作,以便使数据能够符合 Solr 的索引模式要求。
4. 文档处理:在数据转换之后,将转换后的文档发送给 Solr,Solr 将根据配置信息将文档存储到相应的索引中。这个过程通常采用 Solr 的 API 接口来实现,可以选择使用 SolrJ、SolrClient 等客户端库来与 Solr 交互。
5. 索引更新:当文档加载完成后,Solr 索引会自动更新,最新的文档可以被搜索到。在索引更新的过程中,Solr 会对文档进行分词、建立索引、生成倒排索引等操作,以提供高效的全文搜索能力。
#### 4.2 文档加载在企业应用中的实际应用
文档加载在企业应用中有广泛的应用场景,下面以一个电商网站为例进行说明。
假设电商网站的产品数据存储在关系型数据库中,需要将这些产品信息加载到 Solr 索引中以供快速搜索。首先,我们选择 JDBC 技术连接到数据库并执行 SQL 查询获取产品数据。然后,对产品数据进行清洗和转换,如去除不需要的字段、统一日期格式等。接下来,使用 SolrJ 客户端库将转换后的产品文档发送给 Solr,Solr 会将产品文档存储到相应的索引中。这样,用户就可以通过 Solr 快速搜索到电商网站的产品信息。
文档加载在企业应用中还有其他的应用场景,如日志数据的加载、用户行为数据的加载等。通过合理设计文档加载的流程,可以高效地将企业应用中各种类型的数据加载到 Solr 索引中,为用户提供更好的搜索体验和数据分析能力。
**代码示例:**
```java
// 使用 JDBC 连接数据库并执行 SQL 查询
import java.sql.*;
public class JdbcExample {
public static void main(String[] args) throws SQLException {
String jdbcUrl = "jdbc:mysql://localhost:3306/dbname";
String username = "username";
String password = "password";
String sql = "SELECT * FROM products";
Connection connection = null;
Statement statement = null;
ResultSet resultSet = null;
try {
connection = DriverManager.getConnection(jdbcUrl, username, password);
statement = connection.createStatement();
resultSet = statement.executeQuery(sql);
while (resultSet.next()) {
String productName = resultSet.getString("name");
double productPrice = resultSet.getDouble("price");
// 处理产品数据并发送给 Solr
// ...
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
if (resultSet != null) {
resultSet.close();
}
if (statement != null) {
statement.close();
}
if (connection != null) {
connection.close();
}
}
}
}
```
在上面的示例中,我们使用 JDBC 连接到数据库并执行 SQL 查询获取产品数据,然后可以根据实际需求对产品数据进行处理和转换,并将转换后的产品文档发送给 Solr。
以上就是 Solr5 文档加载的流程与原理介绍以及在企业应用中的实际应用案例。通过合理的文档加载设计与实现,可以高效地将各种类型的数据加载到 Solr 索引中,提供快速、准确的搜索与分析能力。
# 5. Solr5 与其他系统集成
在本章中,我们将介绍 Solr5 与其他系统的集成,包括大数据平台和企业信息系统的集成,并分享一些实际的应用案例。
#### 5.1 Solr5 与大数据平台的集成
Solr5 作为一款强大的搜索引擎,可以与大数据平台进行集成,实现海量数据的快速检索和分析。其中,与 Hadoop 和 Spark 的集成是比较常见的方式。通过与 Hadoop 的集成,可以实现对 HDFS 中的数据进行索引和搜索,而与 Spark 的集成则可以实现实时数据分析和检索。
下面是一个简单的示例,演示了如何在 Solr5 中利用 Spark 对数据进行索引:
```java
// 使用 Java API 将 Spark DataFrame 中的数据索引到 Solr
import org.apache.spark.sql.DataFrame;
import org.apache.solr.client.solrj.impl.CloudSolrClient;
import org.apache.solr.client.solrj.impl.ConcurrentUpdateSolrClient;
public class SolrSparkIntegration {
public static void indexDataFrameToSolr(DataFrame dataFrame, String solrZkHost, String collection) {
CloudSolrClient solrClient = new CloudSolrClient.Builder(Collections.singletonList(solrZkHost), Optional.empty())
.withSocketTimeout(10000).withConnectionTimeout(10000).build();
ConcurrentUpdateSolrClient updateSolrClient = new ConcurrentUpdateSolrClient.Builder().withZkHost(solrZkHost).build();
solrClient.setDefaultCollection(collection);
// 将 DataFrame 中的数据索引到 Solr
dataFrame.write().format("solr").option("zkhost", solrZkHost + "/" + collection).save();
solrClient.close();
updateSolrClient.close();
}
}
```
上述代码演示了如何使用 Java API 将 Spark DataFrame 中的数据索引到 Solr,通过 CloudSolrClient 实现与 Solr 的连接,并利用 ConcurrentUpdateSolrClient 实现数据的并发索引操作。这样就实现了 Solr 与 Spark 的集成,使得数据可以被快速索引和检索。
#### 5.2 Solr5 与企业信息系统的集成与应用案例
除了与大数据平台的集成外,Solr5 也可以与企业信息系统进行集成,实现企业内部数据的全文检索和分析。例如,可以将 Solr 与企业的 CRM 系统、ERP 系统等进行集成,实现对客户信息、产品信息等数据的快速检索和分析,提升企业运营效率和决策能力。
下面是一个使用 Python 实现 Solr 与企业 CRM 系统集成的简单示例:
```python
import requests
# 使用 requests 库调用 Solr 的查询 API 实现对 CRM 客户信息的检索
def search_customer_info_from_solr(keyword):
solr_url = "http://localhost:8983/solr/crm_core/select?q=" + keyword
response = requests.get(solr_url)
result = response.json()
return result
```
上述代码展示了如何使用 Python 的 requests 库调用 Solr 的查询 API,实现对 CRM 客户信息的检索。通过将 Solr 与 CRM 系统集成,可以快速检索客户信息,为客户服务、销售等工作提供支持。
通过以上示例,我们可以看到 Solr5 与其他系统的集成是非常灵活和强大的,可以满足企业在搜索与分析方面的各种需求。
希望这些信息能够帮助您更好地理解 Solr5 与其他系统的集成。
# 6. Solr5 文档处理的最佳实践
### 6.1 结合实际案例分析 Solr5 文档处理的最佳实践
在实际的应用中,我们可以通过一些最佳实践来优化 Solr5 的文档处理功能。下面将结合一个实际案例,来介绍一些常用的最佳实践方法。
#### 6.1.1 优化文档提取
文档提取是 Solr5 文档处理功能的重要环节,通过优化文档提取可以提升整体的处理效率。以下是一些常用的文档提取最佳实践:
##### 细化提取规则
在实际应用中,我们可以根据文档的特点,设计出更加细致的提取规则。比如,对于结构化的文档,可以使用基于模板的提取方式;对于非结构化的文档,可以使用基于规则的提取方式。通过细化提取规则,可以更精准地提取文档中的信息。
##### 利用正则表达式
正则表达式是一种强大的文本处理工具,可以用于灵活地匹配文本中的内容。在文档提取过程中,我们可以使用正则表达式来匹配需要提取的信息。同时,合理地使用正则表达式的预编译功能,可以提高匹配的效率。
#### 6.1.2 优化文档转换
文档转换是 Solr5 文档处理功能中的重要环节,通过优化文档转换,可以提升整体的处理效率。以下是一些常用的文档转换最佳实践:
##### 选择合适的转换技术
在实际应用中,我们可以根据具体的转换需求,选择合适的转换技术。比如,对于大规模的文档转换需求,可以选择分布式处理技术;对于复杂的文档转换需求,可以选择基于规则引擎的转换技术。通过选择合适的转换技术,可以提高转换的效率和准确性。
##### 合理使用缓存
在文档转换过程中,有些转换操作可能会比较耗时。为了提高转换的效率,我们可以采用缓存机制,将已经转换的结果缓存起来,下次再遇到相同的输入时,可以直接从缓存中获取结果,避免重复转换。
### 6.2 如何优化 Solr5 文档处理的性能与效果
除了以上提到的最佳实践方法,还有一些其他的方法可以帮助我们优化 Solr5 文档处理的性能和效果。
#### 6.2.1 配置合适的硬件资源
Solr5 在进行文档处理时,需要消耗一定的硬件资源。为了提高处理的性能,我们可以配置合适的硬件资源,比如增加内存和CPU的数量,提高存储设备的性能等。
#### 6.2.2 使用分布式处理
如果处理的文档量较大,单节点的处理能力可能会有限。此时,可以考虑使用分布式处理技术,将文档的处理任务分散到多个节点上,以提高整体的处理能力。
#### 6.2.3 定期优化索引
Solr5 的文档处理功能是基于索引的,而索引的性能和效果与索引的质量密切相关。因此,定期优化索引是提高文档处理性能和效果的重要手段。我们可以通过合理地选择优化策略,合并小索引块,删除过期的索引等方式来优化索引。
总结:通过以上的最佳实践方法,可以帮助我们优化 Solr5 的文档处理功能,在提高处理效率和准确性的同时,提升整体的性能和效果。
希望这些最佳实践对您有所帮助。如果您有其他问题或需要进一步的解释,请随时提问。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Solr5搜索引擎教程》专栏详细介绍了Solr5搜索引擎的各个方面,旨在帮助读者全面了解和掌握Solr5的使用技巧与优化方法。专栏由一系列文章组成,从初识Solr5的安装与配置开始,逐步深入探究Solr5的核心配置文件、索引文档的添加、更新和删除等操作。同时,还剖析了Solr5的搜索请求处理流程、搜索组件的深入应用、查询解析器的原理与应用,以及过滤器和查询时间分析器的介绍。此外,专栏还涵盖了Solr5文档处理、高级搜索功能实践、排序和分页策略等内容。专栏还探讨了Solr5复杂查询构建指南、搜索结果高亮与摘要显示、Facet在搜索中的应用、数据聚合与分析等主题。此外,还包含了Solr5中文分词器的配置与优化、索引优化与性能调优实践、多核心管理与集群部署、数据备份与恢复策略,以及Solr5与数据库集成技术的详细解析。通过阅读本专栏,读者能够系统地学习和掌握Solr5搜索引擎的应用和优化技巧,为提升搜索功能和性能提供了重要的参考。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【生物信息学基因数据处理】:Kronecker积的应用探索
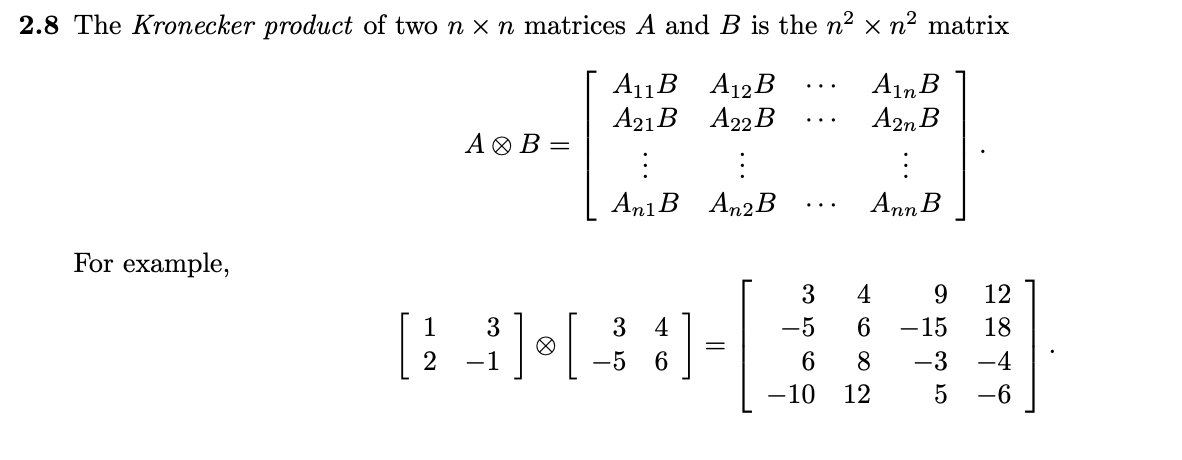
参考资源链接:[矩阵运算:Kronecker积的概念、性质与应用](https://wenku.csdn.net/doc/gja3cts6ed?spm=1055.2635.3001.10343)
# 1. 生物信息学中的Kronecker积概念介绍
## 1.1 Kronecker积的定义
在生物信息学中,Kronecker积(也称为直积)是一种矩阵
频谱资源管理优化:HackRF+One在频谱分配中的关键作用

参考资源链接:[HackRF One全方位指南:从入门到精通](https://wenku.csdn.net/doc/6401ace3cce7214c316ed839?spm=1055.2635.3001.10343)
# 1. 频谱资源管理概述
频谱资源是现代通信技术不可或缺的一部分
3-matic 9.0案例集锦】:从实践经验中学习三维建模的顶级技巧
参考资源链接:[3-matic9.0中文操作手册:从输入到分析设计的全面指南](https://wenku.csdn.net/doc/2b3t01myrv?spm=1055.2635.3001.10343)
# 1. 3-matic 9.0软件概览
## 1.1 软件介绍
3-matic 9.0是一款先进的三维模型软件,广泛应用于工业设计、游戏开发、电影制作等领域。它提供了一系列的建模和优化工具,可以有效地处理复杂的三维模型,提高模型的质量和精度。
## 1.2 功能特点
该软件的主要功能包括基础建模、网格优化、拓扑优化以及与其他软件的协同工作等。3-matic 9.0的用户界面直观易用,
Paraview数据处理与分析流程:中文版完全指南

参考资源链接:[ParaView中文使用手册:从入门到进阶](https://wenku.csdn.net/doc/7okceubkfw?spm=1055.2635.3001.10343)
# 1. Paraview简介与安装配置
## 1.1 Paraview的基本概念
Paraview是一个开源的、跨平台的数据分析和可视化应用程序,广泛应用于科学研究和工程领域。它能够处理各种类型的数据,包括标量、向量、张量等
系统稳定性与内存安全:确保高可用性系统的内存管理策略

参考资源链接:[Net 内存溢出(System.OutOfMemoryException)的常见情况和处理方式总结](https://wenku.csdn.net/doc/6412b784be7fbd1778d4a95f?spm=1055.2635.3001.10343)
# 1. 内存管理基础与系统稳定性概述
内存管理是操作系统中的一个核心功能,它涉及到内存的分配、使用和回收等多个方面。良好的内存管
【HLW8110物联网桥梁】:构建万物互联的HLW8110应用案例

参考资源链接:[hlw8110.pdf](https://wenku.csdn.net/doc/645d8bd295996c03ac43432a?spm=1055.2635.3001.10343)
# 1. HLW8110物联网桥梁概述
## 1.1 物联网桥梁简介
HL
车载网络安全测试:CANoe软件防御与渗透实战指南
参考资源链接:[CANoe软件安装与驱动配置指南](https://wenku.csdn.net/doc/43g24n97ne?spm=1055.2635.3001.10343)
# 1. 车载网络安全概述
## 1.1 车联网安全的重要性
随着互联网技术与汽车行业融合的不断深入,车辆从独立的机械实体逐渐演变成互联的智能系统。车载网络安全关系到车辆数据的完整性、机密性和可用性,是防止未授权访问和网络攻击的关键。确保车载系统的安全性,可以防止数据泄露、控制系统被恶意操控,以及保护用户隐私。因此,车载网络安全对于现代汽车制造商和用户来说至关重要。
## 1.2 安全风险的多维挑战
车辆的网络连
开发者必看!Codesys功能块加密:应对最大挑战的策略

参考资源链接:[Codesys平台之功能块加密与权限设置](https://wenku.csdn.net/doc/644b7c16ea0840391e559736?spm=1055.2635.3001.10343)
# 1. 功能块加密的基础知识
在现代IT和工业自动化领域,功能块加密已经成为保护知识产权和防止非法复制的重要手段。功能块(Fun
【跨平台协作技巧】:在不同EDA工具间实现D触发器设计的有效协作
参考资源链接:[Multisim数电仿真:D触发器的功能与应用解析](https://wenku.csdn.net/doc/5wh647dd6h?spm=1055.2635.3001.10343)
# 1. 跨平台EDA工具协作概述
随着集成电路设计复杂性的增加,跨平台电子设计自动化(EDA)工具的协作变得日益重要。本章将概述EDA工具协作的基本概念,以及在现代设计环境中它们如何共同工作。我们将探讨跨平台
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )