【多变量时间序列分析】:多元数据分析的新视角 —— tseries包的前沿应用
发布时间: 2024-11-10 19:55:43 阅读量: 129 订阅数: 39 

chapter10 codes&data_金融时间序列分析代码_

# 1. 多变量时间序列分析简介
## 1.1 时间序列分析的定义与重要性
时间序列分析是研究按时间顺序排列的数据点的统计方法,重点在于观测值随时间的变化规律。它广泛应用于经济学、金融学、生态学、工程学以及社会学等多个领域,用于预测、趋势分析、信号处理等。
## 1.2 多变量时间序列的复杂性
与单一变量的时间序列相比,多变量时间序列涉及两个或更多的变量相互之间的关系,这样的数据结构更加复杂。它不仅要求我们理解每个变量自身的动态特征,还要掌握这些变量之间的互动模式。
## 1.3 多变量时间序列分析的应用场景
在实际应用中,多变量时间序列分析可以帮助我们对多维数据进行综合判断和决策。例如,它能够分析多个股票指数之间的相关性,或者预测不同经济体指标之间的相互影响。
```mermaid
graph LR
A[定义与重要性] --> B[多变量时间序列的复杂性]
B --> C[应用场景]
```
本章的概述旨在为读者提供一个多变量时间序列分析的入门视角,为进一步深入学习其他章节打下基础。在接下来的章节中,我们会深入探讨多元数据分析的理论基础以及如何在R语言环境中进行具体操作。
# 2. 多元数据分析的理论基础
### 2.1 多变量时间序列的概念和特征
#### 2.1.1 时间序列的基本概念
时间序列是指按时间顺序排列的一系列数据点,通常由一定时间间隔内的观测值组成,用于展示某一变量随时间变化的模式。在金融、经济、社会学、生物学等多个领域,时间序列分析是理解和预测未来行为的关键工具。
例如,股票价格、季度销售数据、每天的温度记录都是时间序列数据。要分析这些数据,通常需要考虑时间依赖性和季节性变化。时间序列分析的一个主要目标是识别数据中的模式,并据此预测未来值。
#### 2.1.2 多变量时间序列的特点
多变量时间序列是时间序列分析的一个扩展,它涉及到两个或更多个相互关联的时间序列。这些序列可能共同受到外部因素的影响,或者它们之间存在内在的因果关系。
多变量时间序列分析的复杂性在于它需要同时考虑多个变量之间的动态关系。例如,在宏观经济分析中,失业率、通货膨胀率和国内生产总值(GDP)等指标往往相互关联,需要通过多变量时间序列方法来全面理解其动态变化。
### 2.2 时间序列分析的数学模型
#### 2.2.1 向量自回归模型(VAR)
向量自回归(VAR)模型是分析多变量时间序列数据的一种常用工具,特别是在变量之间存在相互关系时。VAR模型将每个变量表示为所有变量滞后值的线性组合,加上一个随机扰动项。
假设我们有两个变量,Y和X,那么一个简单的VAR(1)模型可以表示为:
```
Y_t = a_10 + a_11 * Y_(t-1) + a_12 * X_(t-1) + ε_1t
X_t = a_20 + a_21 * Y_(t-1) + a_22 * X_(t-1) + ε_2t
```
其中,Y_t和X_t分别代表在时间t的Y和X的观测值;a_10和a_20是常数项;a_11, a_12, a_21和a_22是模型参数;ε_1t和ε_2t是误差项。
#### 2.2.2 协整与误差修正模型
协整是指两个或多个非平稳时间序列的线性组合是平稳的。换言之,尽管单独的序列是非平稳的,但它们之间存在着长期稳定的关系。协整的概念允许我们在不平稳的序列上进行有效的统计推断。
误差修正模型(ECM)通常用于分析具有协整关系的时间序列。ECM模型将短期波动与长期均衡关系相结合,其中误差修正项反映了偏离长期均衡的调整速度。
#### 2.2.3 状态空间模型和卡尔曼滤波
状态空间模型提供了一个强大的框架来描述线性动态系统。该模型由两部分组成:状态方程和观测方程。状态方程描述了系统内部状态的演变,而观测方程将状态与可观测的数据联系起来。
卡尔曼滤波是一种高效的递归算法,用于估计线性动态系统的状态,它在存在噪声的情况下进行状态估计。卡尔曼滤波特别适用于处理时间序列数据,因为它的计算效率和灵活性。
### 2.3 多变量时间序列的统计检验
#### 2.3.1 平稳性检验
时间序列数据的平稳性是指数据的统计特性(如均值、方差)不随时间变化。在构建时间序列模型之前,检验数据的平稳性是必要的步骤。不平稳的时间序列可能导致误导性的模型估计和预测。
平稳性检验常用的统计方法包括单位根检验(ADF检验、PP检验等)。ADF检验的原假设是序列中存在单位根,即序列是非平稳的。如果检验统计量小于某个临界值,或者p值小于显著性水平,我们拒绝原假设,认为序列是平稳的。
#### 2.3.2 协整检验
在多个时间序列之间检验是否存在协整关系是重要的一步,尤其是在VAR模型或误差修正模型(ECM)的应用中。Engle-Granger两步法和Johansen检验是两种常用的协整检验方法。
Engle-Granger检验首先对每一对时间序列建立回归模型,然后对残差序列进行单位根检验。如果残差序列是平稳的,那么可以认为原始序列是协整的。
#### 2.3.3 格兰杰因果检验
格兰杰因果检验用于分析一个时间序列是否对另一个时间序列具有预测能力。如果变量X有助于预测变量Y,我们可以说X格兰杰导致Y。
格兰杰因果检验是在VAR模型的框架内进行的,检验一个序列的历史值是否对预测另一个序列的历史值有统计上的显著性。虽然它提供了关于变量间关系的见解,但并不意味着因果关系,因为它不能排除遗漏变量或者反向因果的可能性。
以上介绍了多元数据分析的理论基础,为后续章节中的实践操作和案例分析提供了扎实的理论支撑。接下来,我们将探索如何使用R语言和特定的包,如tseries,来实现这些理论模型的实际应用。
# 3. R语言和tseries包概述
## 3.1 R语言在时间序列分析中的应用
### 3.1.1 R语言简介
R语言自1993年诞生以来,已发展成为一种在全球范围内广泛使用的统计编程语言。它在数据科学、统计分析、图形表示和时间序列分析等领域中特别受欢迎。R语言以其开源性、强大的社区支持和丰富的统计包而著称。它能够处理各种复杂的数据问题,并提供了灵活的数据处理能力和高效的计算性能。这使得R语言成为了研究人员和数据分析师处理时间序列数据时的首选工具之一。
R语言的另一个显著优势是其包管理系统。CRAN(Comprehensive R Archive Network)是R的一个官方包仓库,它包含超过万种的包,覆盖了从基础数据分析到高级机器学习算法的各个方面。在时间序列分析领域,R语言同样拥有丰富包,比如我们本章的重点tseries包,为用户提供了强大的工具集,简化了时间序列分析的过程。
### 3.1.2 R语言中的时间序列对象
在R语言中,时间序列数据可以通过`ts`函数创建为时间序列对象。此函数提供了一种简单的方式,允许用户指定时间序列的频率(如每年、每季度、每月或每日等)、起始时间点以及其他参数。时间序列对象是进行后续分析的基础,比如绘制时间序列图、分解时间序列、进行预测等。
创建时间序列对象后,可以使用一系列函数和方法来处理这些数据。这些函数和方法包括但不限于:`plot`函数用于绘制时间序列图,`decompose`函数用于分解时间序列数据以查看其趋势、季节性和随机成分,`forecast`函数用于建立预测模型等。这仅仅是一个开端,R语言对时间序列数据的处理能力远远不止于此。
## 3.2 tseries包功能介绍
### 3.2.1 tseries包的核心功能
tseries包是R语言中处理时间序列分析的一个重要包,它提供了多种与时间序列相关的统计和金融工具。该包的核心功能包括:
- 时间序列数据的创建与处理。
- 绘制时间序列图和Acf图(自相关图)。
- 执行平稳性检验,如ADF检验(Aug

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
S7-1500 PLC编程实战手册:图形化编程技巧深度揭秘
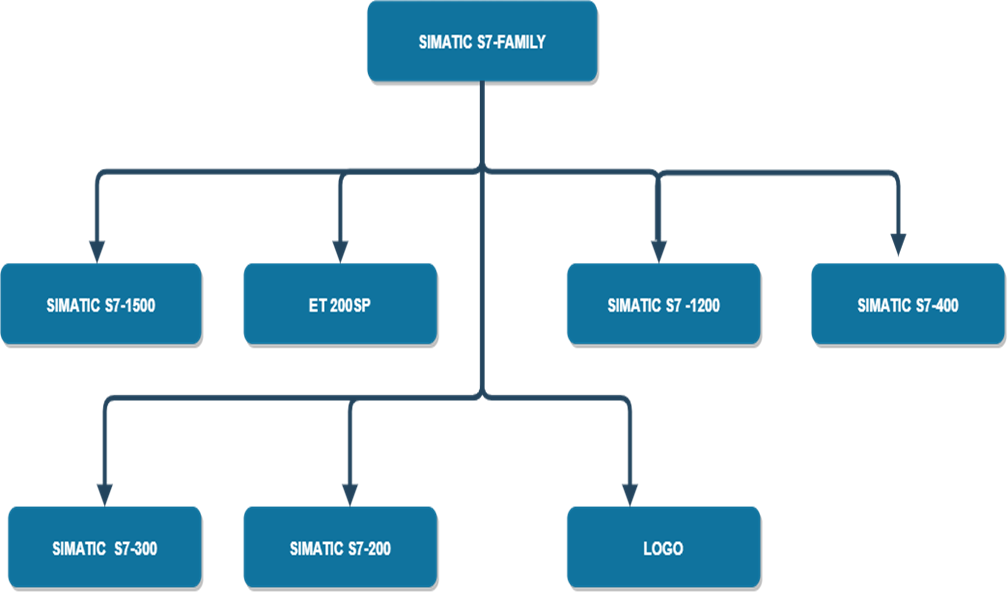
# 摘要
随着自动化和智能制造的快速发展,S7-1500 PLC编程技术的应用变得日益广泛。本文首先介绍了S7-1500 PLC的基本编程概念及其在TIA Portal环境下的图形化编程基础,随后探讨了编程中的高级技巧,如数据类型处理、功能块应用以及异常处理和优化。接着,文中分析了图形化编程在实践中的应用案例,从自动化项目的需求分析到高级控制策略的实现。在问题诊断与解决章节,讨论了编程错误的识别、性能分析以
Halcon函数应用全解读

# 摘要
本文全面介绍了Halcon软件在图像处理与机器视觉领域的应用。首先概述了Halcon的基础知识和软件特性,然后详细阐述了Halcon函数在图像预处理、特征提取、图像分割和目标识别中的具体应用。接着,文章通过实战案例,深入探讨了相机标定、三维重建、表面检测和运动目标跟踪等关键技术。此外,本文还提供了Halcon函数的高级开发技巧,包括图像分析算法的实现、自定义工具
PELCO-D协议全面解读:数据传输与优化策略

# 摘要
本文对PELCO-D协议进行了全面的介绍和分析,包括协议的基本理论、实践应用、高级功能以及未来的发展趋势。PELCO-D是一种广泛应用于监控系统中的通信协议,用于控制和管理相机等设备。文章首先概述了PELCO-D协议的基本概念,然后深入探讨了其数据格式、控制命令和通信机制。在实践应用方面,本文讨论了PELCO-D在监控系统中的集成步骤、数据加密和安全机制,以及性能优化的实践策略。高级功能与案例分析章节进一步探讨了扩展命
解决Tecplot标注难题:希腊字母和数学符号的精确操控秘籍

# 摘要
Tecplot软件广泛应用于技术绘图和数据可视化领域,其强大的标注功能对于提升图形和报告的专业性至关重要。本文详细介绍了希腊字母及数学符号在Tecplot中的精确应用方法,包括标准与非标准希腊字母的输入技巧、自定义方法以及数学符号的分类、功能和输入技巧。此外,本文还探讨了Tecplot标注功能的深度定制,强调了用户自定义标注功能的重要性,并提供了脚本基础和高级应用的指导。文章
手机射频技术实战指南:WIFI_BT_GPS性能优化与信号强度提升技巧
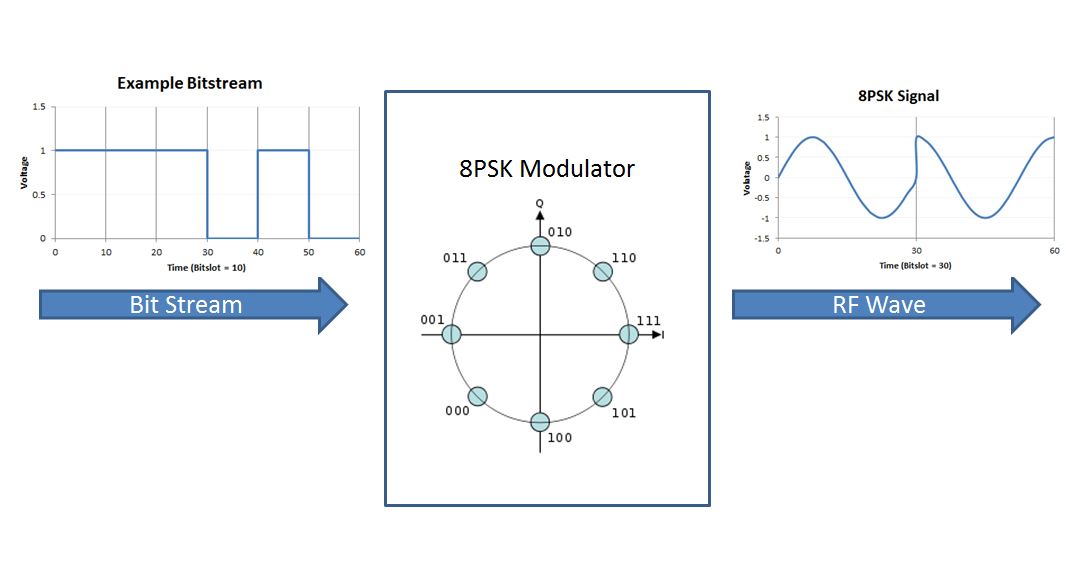
# 摘要
本文综述了手机射频技术的现状与挑战,首先介绍了射频技术的基本原理和性能指标,探讨了灵敏度、功率、信噪比等关键性能指标的定义及影响。然后,针对WIFI性能优化,深入分析了MIMO、波束成形技术以及信道选择和功率控制策略。对于蓝牙技术,探讨了BLE技术特点和优化信号覆盖范围的方法。最后,本文研究了GPS信号捕获、定位精度改进和辅
雷达信号处理的关键:MATLAB中的回波模拟与消除技巧

# 摘要
雷达信号处理是现代雷达系统中至关重要的环节,涉及信号的数学建模、去噪、仿真实现和高级处理技术。本文首先概述雷达信号处理的基本概念,随后深入介绍MATLAB在雷达信号处理中的应用,包括编程基础、工具箱的利用及信号仿真。文章重点探讨了雷达回波信号的数学描述、噪声分析、去噪技术以及回波消除方法,并讨论了自适应信号处理技术、空间和频率域处理方法以及MUSIC算法。最后,通过案例分析展示了MATLAB在
【CAD数据在ANSYS中完美预处理】:专业清理与准备指南
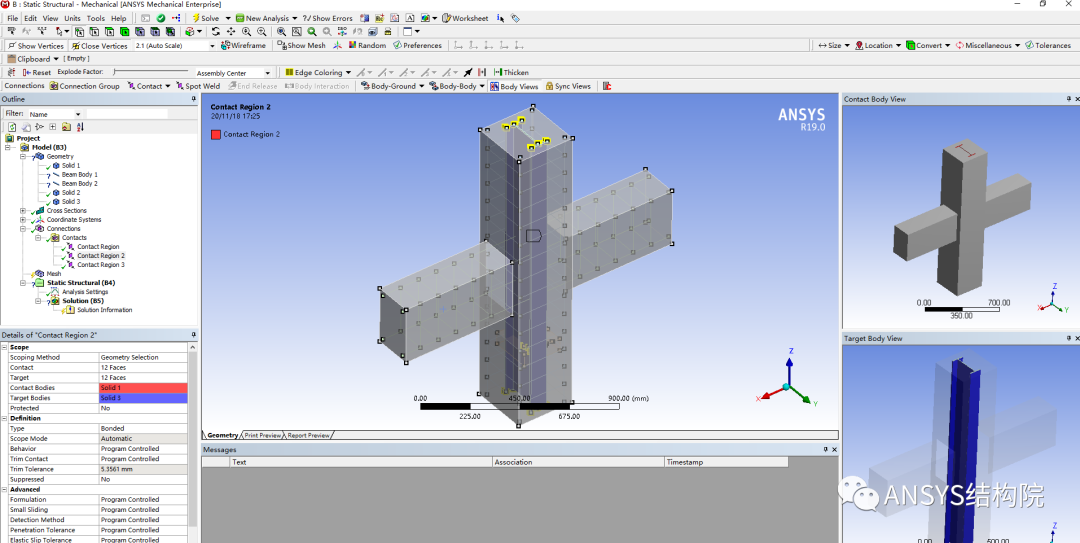
# 摘要
随着工程设计复杂性的增加,CAD数据的处理和ANSYS预处理成为了确保仿真分析准确性的重要步骤。本文详细探讨了从CAD数据导入、组织管理到几何处理的完整流程,强调了数据清理、简化与重构的技巧,以及网格划分的重要性。此外,文章还讨论了如何在ANSYS中准确地定义材料属性和载荷,以及为动态分析做准备。最后,本文展望了预处理流程自动化和优化的可能性,并分析了工程师在预处
【GNU-ld-V2.30链接脚本秘籍】:从入门到实践的快速指南

# 摘要
GNU ld链接器作为重要的工具,它在程序构建过程中扮演着至关重要的角色。本文深入解析了GNU ld链接器的基础知识、链接脚本的核心概念,并探讨了链接脚本的高级功能和组织结构。通过对实战演练的分析,本文提供了基本与高级链接脚本技术应用的实例,并详细讨论了脚本的调试
银河麒麟桌面系统V10 2303版本特性全解析:专家点评与优化建议
# 摘要
本文综合分析了银河麒麟桌面系统V10 2303版本的核心更新、用户体验改进、性能测试结果、行业应用前景以及优化建议。重点介绍了系统架构优化、用户界面定制、新增功能及应用生态的丰富性。通过基准测试和稳定性分析,评估了系统的性能和安全特性。针对不同行业解决方案和开源生态合作进行了前景探讨,同时提出了面临的市场挑战和对策。文章最后提出了系统优化方向和长期发展愿景,探讨了技术创新和对国产操作系统生态的潜在贡献。
# 关键字
银河麒麟桌面系统;系统架构;用户体验;性能评测;行业应用;优化建议;技术创新
参考资源链接:[银河麒麟V10桌面系统专用arm64架构mysql离线安装包](http
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )