【sre_parse与数据处理】:海量数据下的sre_parse策略,高效清洗与分析
发布时间: 2024-10-13 08:11:47 阅读量: 21 订阅数: 25 

eng_sre-.rar_数据结构_C++_
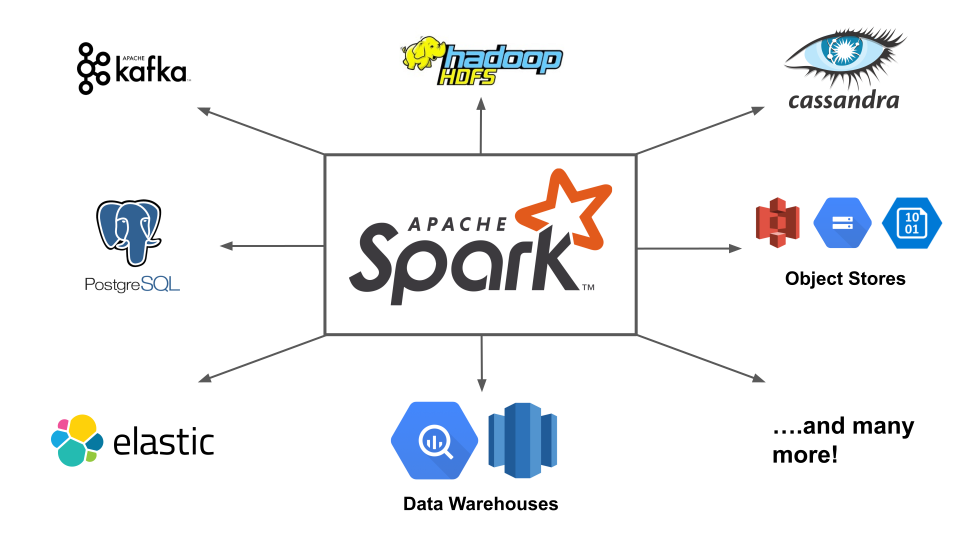
# 1. sre_parse的基本概念与应用
## 1.1 sre_parse的起源与定义
`sre_parse`是一个专门用于字符串解析和重构的工具,它的设计初衷是为了简化开发者在处理文本数据时的复杂性。它基于正则表达式和解析树的概念,能够高效地对输入的字符串进行解析和提取关键信息,然后根据预设的模板重构数据,生成结构化的输出。
## 1.2 sre_parse的应用场景
`sre_parse`在多个领域有着广泛的应用,包括但不限于日志分析、数据清洗、协议解析等。例如,在系统日志管理中,它可以帮助工程师快速定位问题,通过解析日志文件中的关键信息,生成清晰的问题报告。在数据清洗中,它能够从脏数据中提取出有用信息,提高数据质量。
## 1.3 sre_parse的工作流程
`sre_parse`的工作流程主要分为三个步骤:输入解析、数据处理和输出重构。在输入解析阶段,它利用正则表达式对原始字符串进行解析,提取出有价值的信息。在数据处理阶段,它对解析出的数据进行清洗、分析和优化。最后,在输出重构阶段,它根据用户的需求,将处理后的数据重构为所需格式的输出。
# 2. sre_parse的理论基础
## 2.1 sre_parse的工作原理
### 2.1.1 sre_parse的输入输出
在本章节中,我们将深入探讨sre_parse的工作原理,特别是它的输入输出机制。sre_parse是一个用于解析和处理数据的强大工具,它能够将复杂的输入数据转换成结构化信息,以便于进一步的分析和处理。
#### 输入机制
sre_parse的输入通常是一系列非结构化的数据,如文本文件、日志条目、数据库记录等。这些数据可能包含各种各样的信息,从简单的键值对到复杂的嵌套结构。sre_parse通过定义好的模式(pattern)来识别这些数据中的结构,从而实现数据的解析。
```python
# 示例代码块:sre_parse的输入数据示例
import sre_parse
# 假设我们有一段日志数据
log_data = "2023-01-01 12:00:00 [INFO] User logged in: 'john_doe'"
# 使用sre_parse定义模式进行解析
pattern = sre_***pile(r"(?P<timestamp>\d{4}-\d{2}-\d{2}) (?P<level>\w+)\] (?P<action>.+): '(?P<username>.+)'")
matches = pattern.matches(log_data)
# 解析后的结果
parsed_data = matches.groupdict()
print(parsed_data)
```
#### 输出机制
解析后的数据可以以多种格式输出,常见的有字典、列表或自定义的数据结构。输出格式取决于具体的应用需求和后续处理步骤。例如,在上述代码示例中,解析后的数据被转换成了一个字典,其中包含了时间戳、日志级别、动作和用户名等信息。
### 2.1.2 sre_parse的处理流程
sre_parse的处理流程主要包括以下几个步骤:
1. **模式定义**:首先需要定义一个正则表达式模式,用于匹配和解析输入数据。
2. **数据输入**:将待处理的数据输入到sre_parse中。
3. **模式匹配**:sre_parse通过定义的模式对输入数据进行匹配和分组。
4. **结构化输出**:将匹配到的数据转换成结构化的形式输出。
```mermaid
graph LR
A[开始] --> B[定义模式]
B --> C[输入数据]
C --> D[模式匹配]
D --> E[结构化输出]
E --> F[结束]
```
#### 模式定义
模式定义是sre_parse工作的核心。一个模式由多个子模式组成,每个子模式对应数据中的一个特定部分。子模式可以指定匹配类型,如字面量、字符类、重复匹配等。
#### 数据输入
输入数据可以是单个数据项,也可以是数据流。sre_parse需要能够处理不同的数据输入方式,以适应不同的应用场景。
#### 模式匹配
模式匹配是通过正则表达式引擎实现的。sre_parse使用正则表达式来匹配输入数据,并提取出所需的信息。
#### 结构化输出
最后,sre_parse将匹配到的数据转换成结构化形式输出,这使得数据更容易被后续的处理步骤所使用。
在本章节介绍的输入输出机制和处理流程的基础上,我们可以进一步探讨sre_parse的数据处理策略。
# 3. sre_parse的实践应用
#### 3.1 sre_parse在海量数据处理中的应用
##### 3.1.1 海量数据的定义和特性
在本章节中,我们将深入探讨sre_parse在海量数据处理中的应用。首先,我们需要明确什么是海量数据,以及它的特性。海量数据通常指的是数据量达到TB(Terabyte)、PB(Petabyte)级别的数据,它们的特点包括数据量大、数据类型多样、数据增长速度快、数据价值密度低等。在处理这样的数据时,传统的数据处理工具往往力不从心,因此需要更加强大和灵活的工具来应对挑战。
##### 3.1.2 sre_parse在海量数据处理中的优势
sre_parse作为一种先进的数据处理工具,它在海量数据处理方面具有明显的优势。首先,sre_parse支持高效的并行处理,能够将大规模数据集分散到多个处理节点上,从而显著提高数据处理速度。其次,sre_parse支持多种数据源和数据格式,这使得它能够处理来自不同系统和平台的复杂数据集。此外,sre_parse还具备良好的扩展性,可以通过增加处理节点来线性提升处理能力。
#### 3.2 sre_parse在数据分析中的应用
##### 3.2.1 数据分析的基本概念
在本章节中,我们将介绍数据分析的基本概念,并探讨sre_parse在数据分析中的应用。数据分析是指利用统计学和计算技术对数据进行探索、分析和解释的过程,目的是揭示数据中的模式、趋势和关联,从而为决策提供支持。数据分析通常包括数据清洗、数据探索、统计分析、预测建模和数据可视化等步骤。
##### 3.2.2 sre_parse在数据分析中的应用实例
sre_parse在数据分析中的应用非常广泛,以下是一些具体的应用实例:
1. **日志数据分析**:sre_parse可以快速处理服务器日志文件,提取有用信息,如用户访问行为、系统性能瓶颈等,从而帮助工程师优化系统性能和用户体验。
2. **市场分析**:通过sre_parse处理市场数据,可以分析消费者行为、市场趋势,为市场营销策略提供数据支持。
3. **社交网络分析**:sre_parse可以处理社交媒体数据,分析用户之间的互动模式,为社交网络平台提供产品改进的依据。
```python
# 示例代码:使用sre_parse处理日志数据
import sre_parse
# 读取日志文件
with open('server.log', 'r') as ***
***
* 使用sre_parse解析日志数据
parsed_data = [sre_parse.parse(line) for line in log_data]
# 输出解析后的数据
print(parsed_data)
```
在上述代码中,我们首先导入了sre_p

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入解析 Python 正则表达式库 sre_parse,从基础概念到高级技巧,全面提升您的正则表达式使用能力。涵盖了优化匹配效率、实战应用、错误诊断、数据处理、安全分析和数据可视化等各个方面,为您提供全方位的 sre_parse 学习指南。通过深入的讲解和丰富的案例,帮助您掌握 sre_parse 的核心用法,解决实际问题,提升文本处理和数据分析效率,并探索其在网络安全和数据可视化等领域的应用。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
紧急揭秘!防止Canvas转换中透明区域变色的5大技巧

# 摘要
Canvas作为Web图形API,广泛应用于现代网页设计与交互中。本文从Canvas转换技术的基本概念入手,深入探讨了在渲染过程中透明区域变色的理论基础和实践解决方案。文章详细解析了透明度和颜色模型,渲染流程以及浏览器渲染差异,并针对性地提供了预防透明区域变色的技巧。通过对Canvas上下文优化
超越MFCC:BFCC在声学特征提取中的崛起

# 摘要
声学特征提取是语音和音频处理领域的核心,对于提升识别准确率和系统的鲁棒性至关重要。本文首先介绍了声学特征提取的原理及应用,着重探讨
Flutter自定义验证码输入框实战:提升用户体验的开发与优化

# 摘要
本文详细介绍了在Flutter框架中实现验证码输入框的设计与开发流程。首先,文章探讨了验证码输入框在移动应用中的基本实现,随后深入到前端设计理论,强调了用户体验的重
光盘刻录软件大PK:10个最佳工具,找到你的专属刻录伙伴
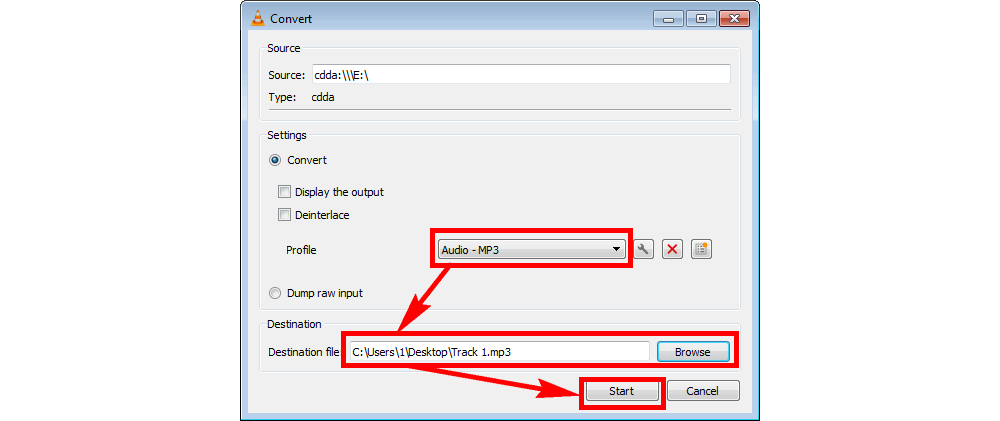
# 摘要
本文全面介绍了光盘刻录技术,从技术概述到具体软件选择标准,再到实战对比和进阶优化技巧,最终探讨了在不同应用场景下的应用以及未来发展趋势。在选择光盘刻录软件时,本文强调了功能性、用户体验、性能与稳定性的重要性。此外,本文还提供了光盘刻录的速度优化、数据安全保护及刻录后验证的方法,并探讨了在音频光盘制作、数据备份归档以及多媒体项目中的应用实例。最后,文章展望了光盘刻录技术的创
【FANUC机器人接线实战教程】:一步步教你完成Process IO接线的全过程
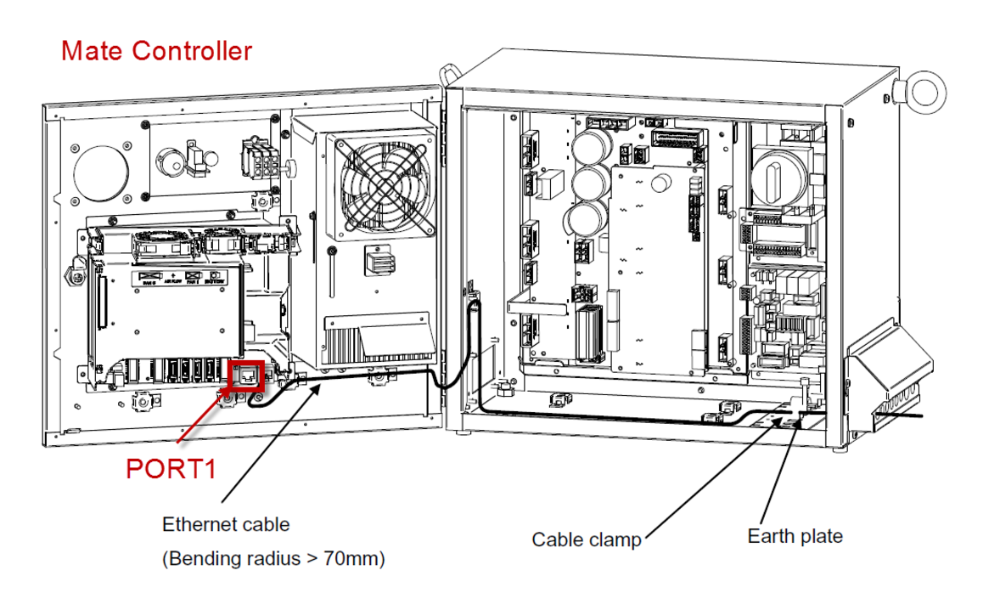
# 摘要
本文系统地介绍了FANUC机器人接线的基础知识、操作指南以及故障诊断与解决策略。首先,章节一和章节二深入讲解了Process IO接线原理,包括其优势、硬件组成、电气接线基础和信号类型。随后,在第三章中,提供了详细的接线操作指南,从准备工作到实际操作步骤,再到安全操作规程与测试,内容全面而细致。第四章则聚焦于故障诊断与解决,提供了一系列常见问题的分析、故障排查步骤与技巧,以及维护和预防措施
ENVI高光谱分析入门:3步掌握波谱识别的关键技巧

# 摘要
本文全面介绍了ENVI高光谱分析软件的基础操作和高级功能应用。第一章对ENVI软件进行了简介,第二章详细讲解了ENVI用户界面、数据导入预处理、图像显示与分析基础。第三章讨论了波谱识别的关键步骤,包括波谱特征提取、监督与非监督分类以及分类结果的评估与优化。第四章探讨了高级波谱分析技术、大数据环境下的高光谱处理以及ENVI脚本
ISA88.01批量控制核心指南:掌握制造业自动化控制的7大关键点

# 摘要
本文详细介绍了ISA88.01批量控制标准的理论基础和实际应用。首先,概述了ISA88.01标准的结构与组件,包括基本架构、核心组件如过程模块(PM)、单元模块(UM)
【均匀线阵方向图优化手册】:提升天线性能的15个实战技巧
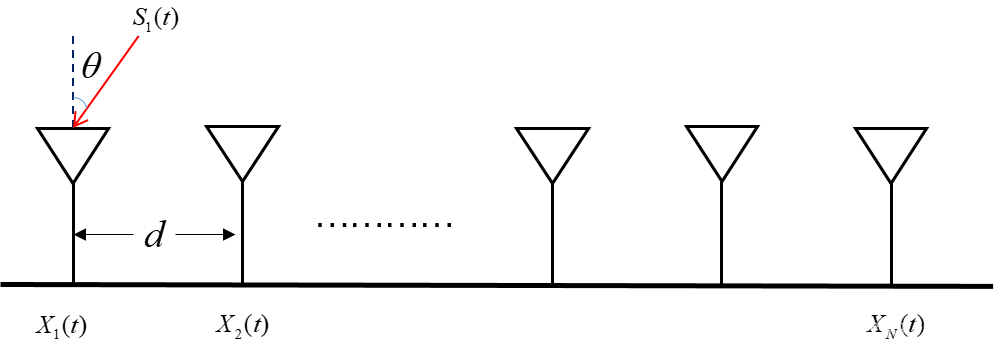
# 摘要
本文系统地介绍了均匀线阵天线的基础知识、方向图优化理论基础、优化实践技巧、系统集成与测试流程,以及创新应用。文章首先概述了均匀线阵天线的基本概念和方向图的重要性,然后
STM32F407 USB通信全解:USB设备开发与调试的捷径

# 摘要
本论文深入探讨了STM32F407微控制器在USB通信领域的应用,涵盖了从基础理论到高级应用的全方位知识体系。文章首先对USB通信协议进行了详细解析,并针对STM32F407的USB硬件接口特性进行了介绍。随后,详细阐述了USB设备固件开发流程和数据流管理,以及USB通信接口编程的具体实现。进一步地,针对USB调试技术和故障诊断、性能优化进行了系统性分析。在高级应用部分,重点介绍了USB主
车载网络诊断新趋势:SAE-J1939-73在现代汽车中的应用
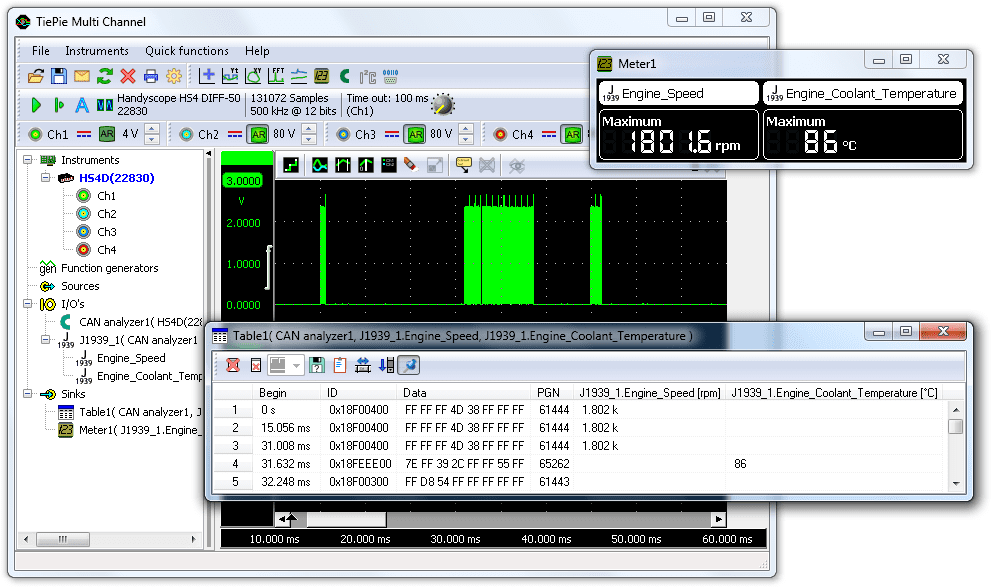
# 摘要
随着汽车电子技术的发展,车载网络诊断技术变得日益重要。本文首先概述了车载网络技术的演进和SAE-J1939标准及其子标准SAE-J1939-73的角色。接着深入探讨了SAE-J1939-73标准的理论基础,包括数据链路层扩展、数据结构、传输机制及诊断功能。文章分析了SAE-J1939-73在现代汽车诊断中的实际应用,车载网络诊断工具和设备,以
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )