Amazon Aurora的跨地域读重复实践
发布时间: 2023-12-26 03:01:43 阅读量: 27 订阅数: 31 
# 章节一:理解Amazon Aurora跨地域读重复的概念
## 1.1 什么是Amazon Aurora?
Amazon Aurora 是亚马逊推出的一种关系型数据库引擎,兼容MySQL和PostgreSQL,具有高性能、可扩展性和高可用性的特点。它提供了多个实例部署、自动容错处理、存储容量自动扩展等功能,适用于各种规模的应用程序。
## 1.2 跨地域读重复的概念和作用
跨地域读重复是指在Amazon Aurora数据库的不同地理区域之间进行读取数据的操作。通过在不同地域部署的数据库实例之间进行读取,可以实现数据的灾备备份、跨地域负载均衡、降低用户访问延迟等作用。
## 1.3 Amazon Aurora 跨地域读重复的优势
Amazon Aurora 跨地域读重复具有以下优势:
- 可用性提升:跨地域读重复可以在不同地域之间实现故障切换,提高系统的可用性和容错能力。
- 负载均衡:可以根据用户地理位置将读请求分发到就近的数据库实例,实现负载均衡,降低访问延迟。
- 灾备备份:在发生灾难性故障时,可以快速切换到备用地域的数据库实例,保障数据的安全性和可靠性。
## 2. 章节二:配置Amazon Aurora跨地域读重复
Amazon Aurora的跨地域读重复功能能够帮助用户在全球范围内实现低延迟、高可用的读取操作。本章节将详细介绍如何配置Amazon Aurora的跨地域读重复功能,包括启用跨地域读重复的步骤、最佳实践和常见问题解答。
### 2.1 如何在Amazon Aurora上启用跨地域读重复?
在Amazon Aurora数据库实例的配置中启用跨地域读重复非常简单。您只需按照以下步骤进行配置:
```python
# Python代码示例
import boto3
# 创建RDS客户端
client = boto3.client('rds')
# 启用跨地域读重复
response = client.modify_db_cluster(
DBClusterIdentifier='your-db-cluster-identifier',
EnableGlobalWriteForwarding=True
)
print(response)
```
上述Python代码通过AWS SDK for Python(Boto3)调用了RDS的API,在指定的DBClusterIdentifier下启用了跨地域读重复。在实际应用中,您需要替换`your-db-cluster-identifier`为您的数据库集群标识符。
### 2.2 配置跨地域读重复的最佳实践
在配置跨地域读重复时,以下是一些最佳实践建议:
- 选择最近的地理位置:为了获得最佳的性能和延迟,建议选择离主实例地理位置较近的读取实例。
- 定期监控读取实例的健康状态:定期监控读取实例的运行状态和性能,确保跨地域读重复的可用性。
### 2.3 常见问题解答:配置Amazon Aurora跨地域读重复时可能遇到的问题和解决方法
Q: 如何区分主实例和读取实例的地理位置?
A: 您可以通过AWS Management Console或AWS CLI来查看数据库实例的地理位置信息,或者通过describe-db-instances API来获取实例的地理位置属性。
Q: 在启用跨地域读重复后,读取延迟依然较高,该如何优化?
A: 您可以考虑增加读

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
Amazon Aurora是由亚马逊公司提供的一种高性能、可扩展和高可用的关系型数据库服务。这个专栏深入介绍了Amazon Aurora的基本概念、架构和性能优化策略,以及与传统数据库和其他AWS服务的对比分析。此外,专栏还涵盖了Amazon Aurora的故障恢复、读写分离、备份与恢复机制、多可用区部署、敏感数据加密与管理等关键功能和最佳实践。通过结合实际案例和具体的迁移指南,读者可以了解如何迁移和升级数据库,以及如何实现跨地域读的重复。此外,本专栏还介绍了与Securosys的HSM集成和全球数据库配置的实践。总之,专栏提供了详尽的资料和实用的建议,旨在帮助用户充分利用Amazon Aurora的强大功能,实现高性能、高可用性和可扩展性的数据库解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电动汽车充电效率提升:SAE J1772标准实施难点的解决方案

参考资源链接:[SAE J1772-2017.pdf](https://wenku.csdn.net/doc/6412b74abe7fbd1778d
PFC5.0数据备份与恢复策略:保障数据完整性和可用性的高级方案

参考资源链接:[PFC5.0用户手册:入门与教程](https://wenku.csdn.net/doc/557hjg39sn?spm=1055.2635.3001.10343)
# 1. 数据备份与恢复的必要性
## 数据的脆弱性与备份的重要性
在当今数字化时代,数据是企业资产的核心。任何数据的丢失或损坏都可能导致灾难性的后果,包括但不限于运营中断、财务损失以及客户信任的丧失。因此,数据备份与恢复已成为
【高级控制算法】:提高FANUC 0i-MF系统精度的算法优化,技术解析
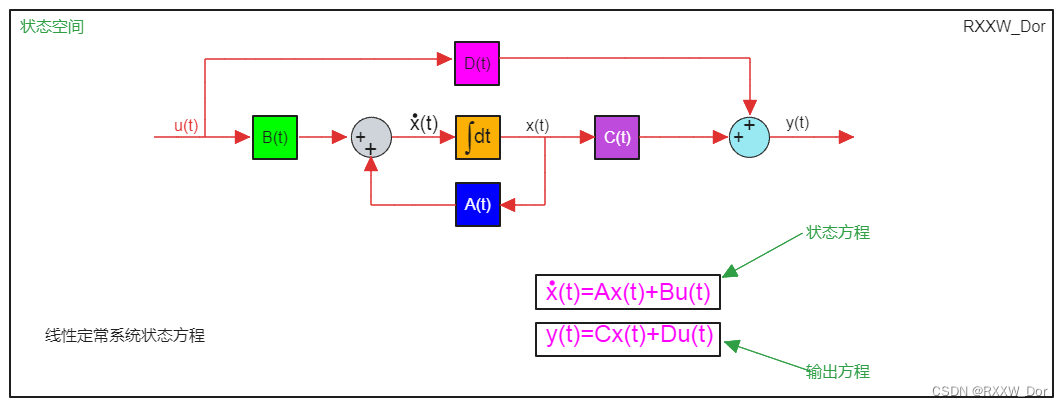
参考资源链接:[FANUC 0i-MF 加工中心系统操作与安全指南](https://wenku.csdn.net/doc/6401ac08cce7214c316ea60a?spm=1055.2635.3001.10343)
# 1. ```
# 第一章:FANUC 0i-MF系统与控制算法概述
FANUC 0i-MF系统作为现代工业自动化领域的重要组成部分,以其卓越的控制性能和可靠性在数控机床等领域得到广泛应用。本章将从系统架构、控制算法类型
【ASP.NET Core Web API设计】:构建RESTful服务的最佳实践

参考资源链接:[ASP.NET实用开发:课后习题详解与答案](https://wenku.csdn.net/doc/649e3a1550e8173efdb59dbe?spm=1055.2635.3001.10343)
# 1. ASP.NET
iSecure Center审计功能:合规性监控与审计报告完全解析

参考资源链接:[iSecure Center 安装指南:综合安防管理平台部署步骤](https://wenku.csdn.net/doc/2f6bn25sjv?spm=1055.2635.3001.10343)
# 1. iSecure Center审计功能概述
## 1.1 了解iSecure Center
iSecure Center是一个高效的审计和合规性
从原理图到实物:STM32F103VET6 PCB设计全程指南
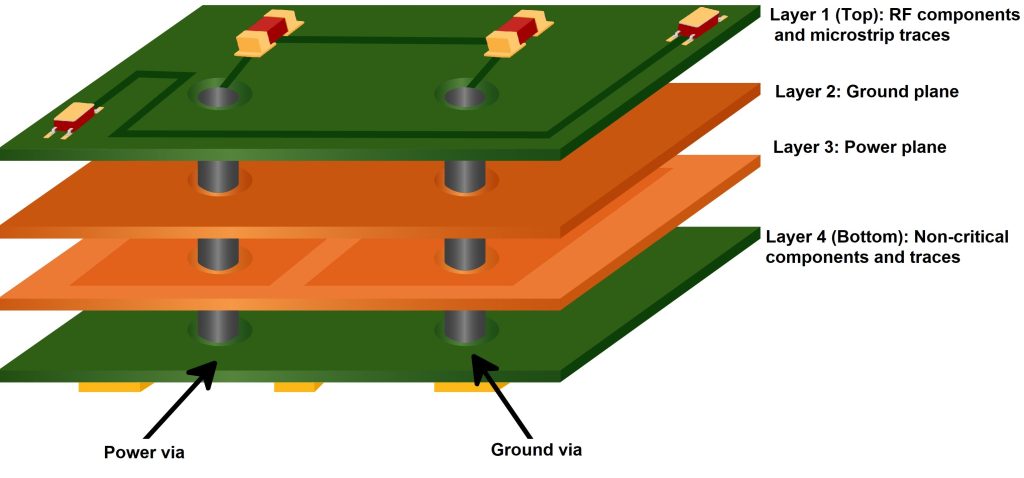
参考资源链接:[STM32F103VET6 PCB原理详解:最小系统板与电路布局](https://wenku.csdn.net/doc/6412b795be7fbd1778d4ad36?spm=1055.2635.3001.10343)
# 1. STM32F103VET6微控制器概述
微控制器领域中,STM32F103VET6是广
WINCC与操作系统版本兼容性:专家分析与实用指南
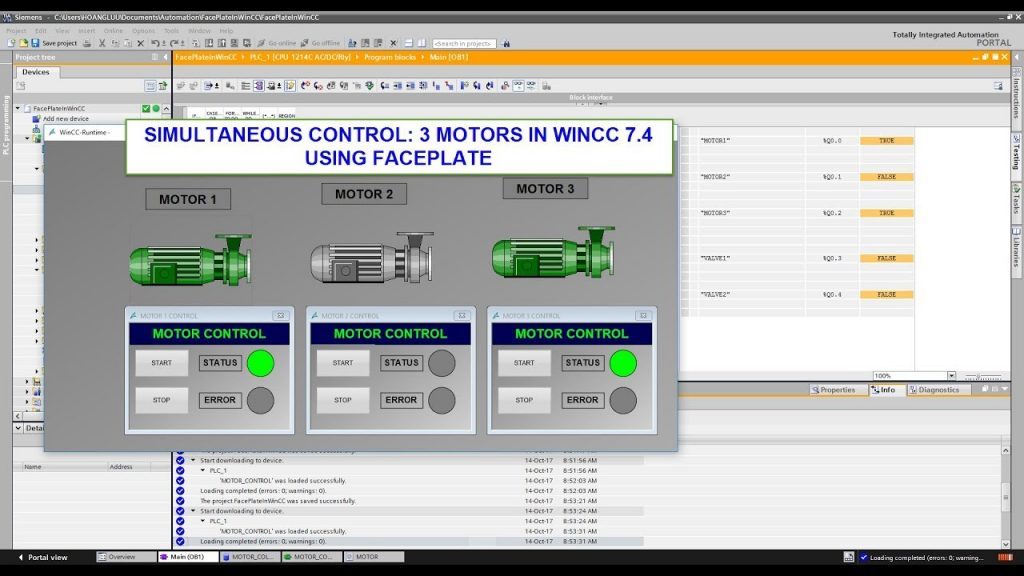
参考资源链接:[Windows XP下安装WINCC V6.0/V6.2错误解决方案](https://wenku.csdn.net/doc/6412b6dcbe7fbd1778d483df?spm=1055.2635.3001.10343)
# 1. WinCC与操作系统兼容性的基础了解
## 1.1 软件与操作系统兼容性的重要性
在工业自动化领域,Win
硬盘SMART数据分析:区分正常老化与潜在故障的方法

参考资源链接:[硬盘SMART错误警告解决办法与诊断技巧](https://wenku.csdn.net/doc/7cskgjiy20?spm=1055.2635.3001.10343)
# 1. 硬盘SMART技术概述
硬盘作为计算机中存储数据的重要设备,其稳定性和性能直接关系到整个系统的运行效率。SMART技术,全称是Self-Monitoring, Analysis, and Reporting Technology
避免IDEA编译卡顿:打开自动编译的正确方式
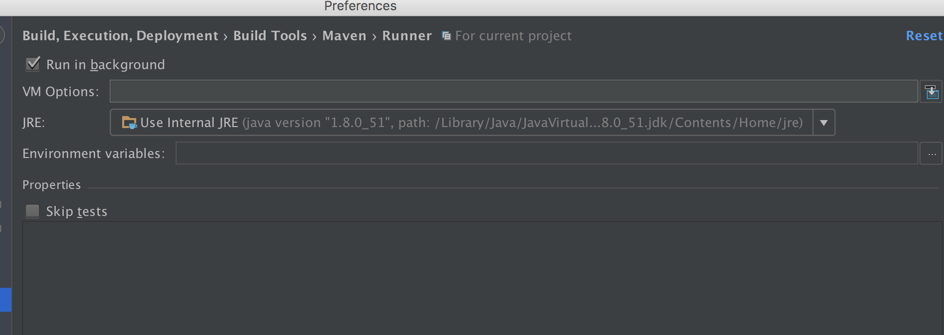
参考资源链接:[IDEA 开启自动编译设置步骤](https://wenku.csdn.net/doc/646ec8d7d12cbe7ec3f0b643?spm=1055.2635.3001.10343)
# 1. 自动编译在IDEA中的重要性
自动编译功能是现代集成开发环境(IDE)中不可或缺的一部分,特别是在Java开发中,IntelliJ
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )