【Maven在大数据项目中的应用】:Hadoop与Maven集成实践
发布时间: 2024-10-20 19:04:19 阅读量: 28 订阅数: 43 

# 1. Maven简介与大数据项目概述
## 1.1 Maven简介
Apache Maven是一个流行的Java项目管理工具,它使用一个名为Project Object Model (POM)的文件来管理项目的构建,报告和文档。Maven提供了丰富的插件系统,这使得它能够执行广泛的项目任务,从编译和运行单元测试到创建JAR文件。
## 1.2 大数据项目概述
大数据项目通常涉及处理和分析大量数据,以发现隐藏的模式、未知的相关性、市场趋势、客户偏好等有价值的信息。这些项目往往依赖于强大的数据处理框架,如Hadoop和Spark。Maven在这些项目中扮演了重要角色,因为它可以自动化构建流程,管理项目依赖,并且能够集成复杂的构建和部署任务。
## 1.3 Maven在大数据项目中的作用
在大数据项目中,Maven可以带来一致的构建体验,通过POM文件可以清晰地定义项目依赖,避免了手动管理的复杂性。它还支持通过插件和自定义脚本集成各种大数据工具和框架,为项目提供了一种通用的构建方式。
这些章节的编写方式会依照整个文章的逻辑顺序进行深入,从Maven的基本概念开始,逐渐涉及它在大数据项目中的应用和优势,以及更高级的特性。在后续章节中,我们将详细探讨如何在具体的大数据项目中应用和优化Maven,以达到提高开发效率和项目管理质量的目的。
# 2. Maven核心概念和大数据项目构建
## 2.1 Maven的基本原理和生命周期
### 2.1.1 Maven的构建和依赖管理
Maven是Java平台上的项目管理和自动化构建工具。它将项目构建成一个标准化的项目结构,通过使用预定义的生命周期和插件,Maven能够处理项目的编译、测试、打包、部署等构建环节。
#### 构建生命周期
Maven的生命周期是指从初始化项目到构建完成的各个阶段,包括清理(clean)、编译(compile)、测试(test)、打包(package)、安装(install)和部署(deploy)。生命周期是可插拔的,每个阶段都有具体的插件行为与之对应,用户可以自定义生命周期的每个阶段来完成不同的任务。
**示例代码:**
```bash
mvn clean compile test package
```
**代码分析:**
- `clean` 清理项目输出的文件。
- `compile` 编译项目源代码。
- `test` 执行测试用例。
- `package` 打包生成JAR或WAR文件。
#### 依赖管理
依赖管理是Maven最核心的功能之一,它允许用户在项目中声明所依赖的库,Maven会自动下载这些库及其依赖到本地仓库中。
**POM依赖声明:**
```xml
<dependencies>
<dependency>
<groupId>org.example</groupId>
<artifactId>library</artifactId>
<version>1.0.0</version>
</dependency>
</dependencies>
```
**依赖范围:**
```xml
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>5.3.1</version>
<scope>compile</scope>
</dependency>
```
- `compile` 编译时需要。
- `test` 测试时需要。
- `provided` 编译时需要,但运行时由JDK或容器提供。
- `runtime` 运行时需要。
### 2.1.2 Maven的插件系统和扩展机制
Maven的插件系统允许用户自定义和扩展构建过程。每个插件通常包含了一个或多个目标(goal),这些目标可以绑定到生命周期的不同阶段。
#### 插件目标
一个典型的插件目标可以执行代码生成、打包、部署等任务。
**示例代码:**
```bash
mvn compiler:compile
```
这里使用`compiler`插件的`compile`目标来编译Java代码。
#### 插件扩展机制
通过编写自己的插件,用户可以定义自己的生命周期阶段和任务。插件通常被打包为JAR文件,并放置到Maven的本地仓库中。
**编写插件的基本步骤:**
1. 创建一个Maven项目。
2. 在`pom.xml`中定义插件的坐标。
3. 编写插件代码,并打包成JAR。
4. 在项目中使用定义好的插件。
**插件编写示例代码:**
```java
public class MyPlugin extends AbstractMojo {
@Parameter(property = "myPlugin.param", defaultValue = "default value")
private String param;
public void execute() throws MojoExecutionException, MojoFailureException {
getLog().info("Executing my custom plugin with param: " + param);
// 插件逻辑代码
}
}
```
这个简单的插件输出了一个参数信息。
## 2.2 Maven项目对象模型(POM)
### 2.2.1 POM文件的作用和结构
POM是Maven项目的中心,所有的构建配置都定义在`pom.xml`文件中。它包括项目的基本信息、配置、依赖、构建配置、插件配置等。
**`pom.xml`结构基本示例:**
```xml
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>my-project</artifactId>
<version>1.0-SNAPSHOT</version>
<!-- 描述、开发人员、许可证等其他配置 -->
<dependencies>
<!-- 依赖列表 -->
</dependencies>
<!-- 插件配置 -->
</project>
```
### 2.2.2 配置POM以适应大数据项目需求
大数据项目通常涉及多模块构建、依赖的特殊管理、特定的插件使用等。POM文件的配置需要反映这些需求。
#### 多模块构建
```xml
<modules>
<module>module1</module>
<module>module2</module>
</modules>
```
#### 大数据框架依赖
```xml
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
</dependency>
```
#### 特定插件配置
```xml
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
```
## 2.3 大数据项目依赖管理
### 2.3.1 管理Hadoop及其他大数据框架依赖
依赖管理不仅涉及Hadoop,也涉及Spark、Hive、Flink等多个大数据框架。
**示例依赖配置:**
```xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
```
### 2.3.2 解决依赖冲突和版本控制策略
在多模块项目或涉及多个库时,依赖冲突是常见的问题。Maven通过依赖传递来解决冲突,但仍需要用户进行适当的管理。
**管理策略:**
- 使用`<dependencyManagement>`元素来统一管理依赖版本。
- 使用Maven的版本范围功能。
- 手动排除冲突的依赖。
**示例配置:**
```xml
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
<exclusions>
<exclusion>
<groupId>org.mortbay.jetty</groupId>
<artifactId>jetty</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
</dependencyManagement>
```
通过这些策略,可以确保项目依赖的一致性和稳定性,减少由于版本不一致造成的运行时问题。在大数据项目中,这一环节尤其重要,因为各个框架之间的依赖关系错综复杂。
# 3. Hadoop与Maven的集成实践
### 3.1 Maven与Hadoop的集成概述
#### 3.1.1 集成的必要性和优势
在大数据项目中,集成Maven与Hadoop带来了诸多优势。首先,Maven作为一种构建工具,提供了项目管理的一站式解决方案,包括依赖管理、构建生命周期和插件管理等。而Hadoop作为大数据处理的核心框架,涉及到复杂的项目依赖和构建过程。借助Maven,可以极大地简化项目构建和依赖的管理。此外,Maven的可扩展插件系统能够很好地支持Hadoop项目的特定需求,如MapReduce任务的构建和打包。
#### 3.1.2 环境搭建和准备工作
在进行Maven与Hadoop集成之前,我们需要准备好以下环境和工具:
- 安装Java开发工具包(JDK),因为Maven和Hadoop都是基于Java的应用程序。
- 安装Maven,并配置好`settings.xml`文件,确保能够从中央仓库下载依赖包。
- 安装Hadoop,并配置好环境变量,以便在任何目录下使用Hadoop命令。
- 确认网络连接正常,以便Maven能够下载所需的依赖和插件。
### 3.2 Maven在Hadoop项目中的应用
#### 3.2.1 创建Hadoop项目结构
在Maven中创建一个Hadoop项目结构,首先需要创建一个基本的Maven项目,然后添加Hadoop相关依赖。可以通过以下Maven命令快速生成项目骨架:
```bash
mvn archetype:generate -DgroupId=com.example -DartifactId=hadoop-maven-integration -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false
```
然后,在`pom.xml`文件中添加Hadoop的依赖:
```xml
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.2.1</version>
</dependency>
</dependencies>
```
#### 3.2.2 构建Hadoop MapReduce程序
构建Hadoop MapReduce程序通常涉及编写Map和Reduce任务代码,然后通过Maven进行编译、打包。一个简单的MapReduce示例代码如下:
```java
public class WordCount {
public s
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面解析 Java Maven 项目管理工具,从入门精讲到高级应用,涵盖项目管理、构建技巧、依赖管理、插件使用、仓库管理、生命周期优化、多环境配置、持续集成、聚合继承、模块化管理、性能调优、版本号策略、与其他构建工具比较、自定义插件开发、源码分析、安全最佳实践、自动化部署、在 Spring Boot 项目中的应用等各个方面。通过深入浅出的讲解和丰富的实战案例,帮助读者快速掌握 Maven 的核心概念和使用技巧,提升项目管理和构建效率,打造更健壮、高效的 Java 项目。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【统计分析的终极武器】:最小二乘法的全面解析与案例实战

# 摘要
最小二乘法是一种广泛应用于数据统计分析的数学优化技术,用于估计模型参数并最小化误差的平方和。本论文首先回顾了最小二乘法的理论基础和数学原理,包括线性回归分析、损失函数
西门子伺服技术精讲:掌握V90 PN伺服控制字与状态字的实战技巧
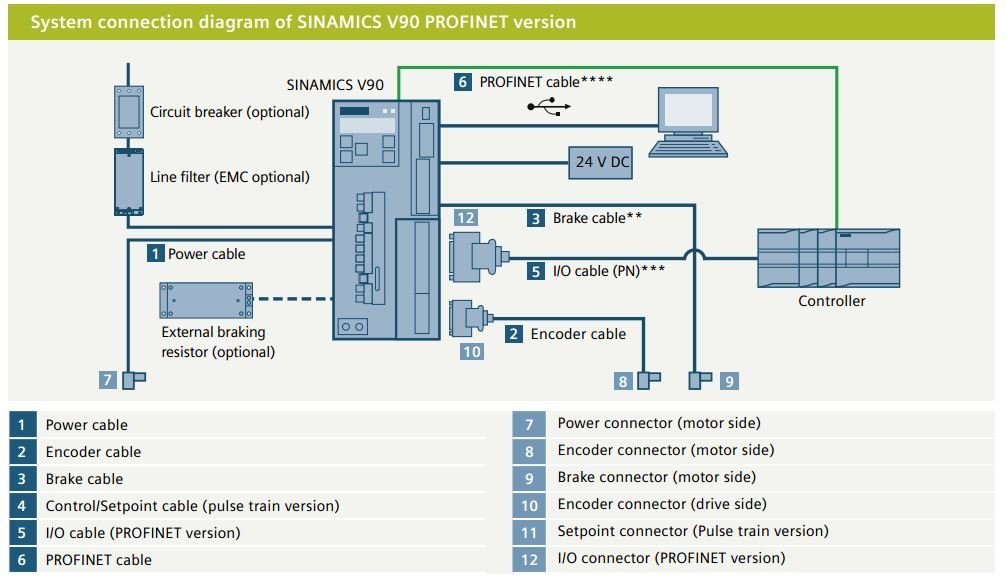
# 摘要
本文系统地介绍了西门子V90 PN伺服技术,包括控制字与状态字的深入解析、实际应用和故障处理。首先概述了伺服技术与V90 PN伺服的基本知识,随后详细阐述了控制字的理论基础和编程实践,以及状态字在故障诊断中的应用。通过实战技巧章节,本文还提供了现场调试、参数优化和问题解决的具体方法。最
【Ubuntu Mini.iso进阶技巧】:解决安装常见问题的4大秘诀
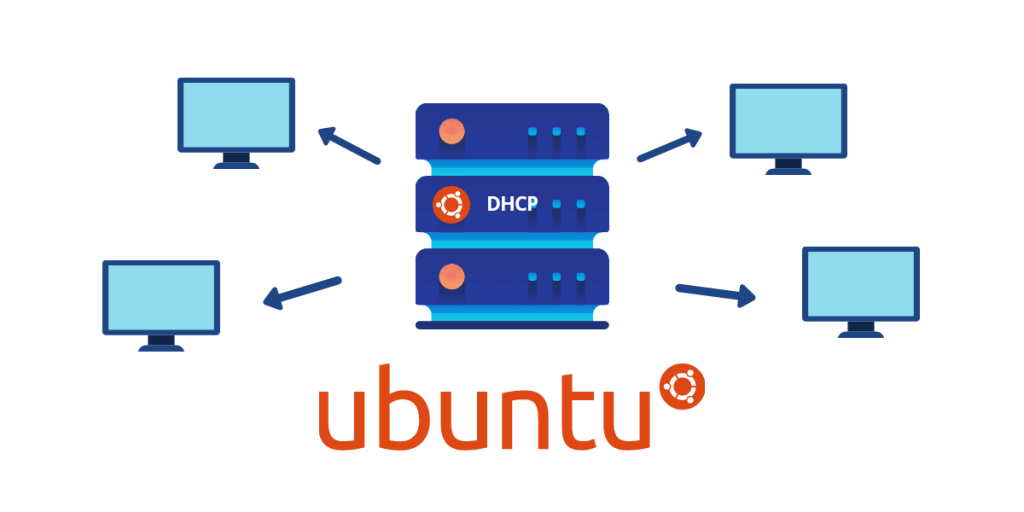
# 摘要
Ubuntu Mini.iso作为一个精简的Linux发行版镜像,为用户提供了一个轻量级的安装选项,特别适用于需要快速部署系统的场景。本文首先对Ubuntu Mini.iso的基本概念和安装基础进行了介绍,并深入分析了其文件系统结构和安装流程。随后,文章详细探讨了安装过程中可能遇到的各类问题及其理论背景,并提供了相应的解决方法。进阶技巧章节分享了如何通过脚本自动化安装、系
深度解析SRecord工具集:专家揭秘srec_cat、srec_cmp、srec_info的高级使用技巧

# 摘要
本文深入介绍SRecord工具集,包括其基础功能、高级用法和核心功能。通过探讨srec_cat的命令结构和数据转换应用,srec_cmp的对比原理和固件校验技巧,以及srec_info的用户交互和信息提取技术,本文展示了如何在嵌入式开发中高效整合使用这些工具。同时,本文提供了实战演练案例,分析了在整合应用中遇到的高级问题及解决方案,并对SRecord工具集的未来改进方向进行展望,强
MIMO与OFDM深度解析:掌握3GPP TS 36.413的关键技术

# 摘要
本文对MIMO和OFDM技术进行了全面的概述,并深入探讨了其工作原理、性能评估、关键技术以及结合应用。首先介绍了MIMO技术的基本原理、分类和性能评估方法,接着分析了O
KISTLER 5847技术秘籍:零基础也能精通的术语与应用
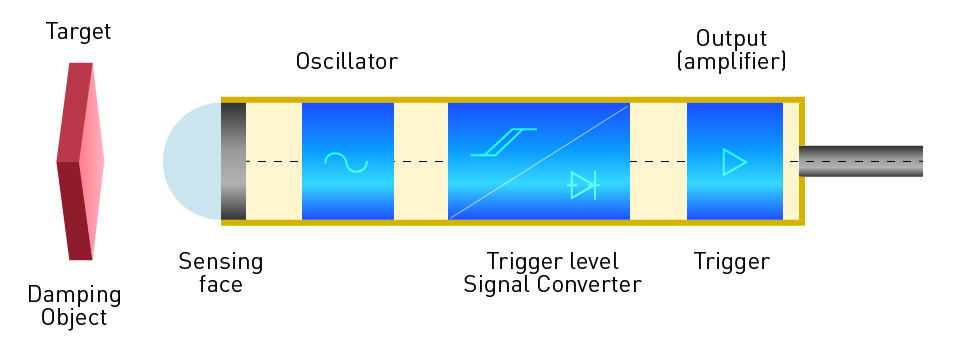
# 摘要
KISTLER 5847传感器因其在测量精度和应用范围上的优势而被广泛使用。本文首先对KISTLER 5847传感器进行概述,然后详细分析其核心原理与技术,包括压电效应的理论基础、传感器工作机制以及校准与性能优化方法。接着,探讨了该传感器在工业、科研和环境监测等不同领域的日常应用,突出其在材料测试、产品质量控制和动态过程监测中的重要性。此外,文章还提供了
【PreScan Viewer高级技能提升】:视频输出质量优化,专家级进阶教程!

# 摘要
本文系统性地介绍了PreScan Viewer在视频质量优化中的应用,重点探讨了视频输出质量的理论基础和实践操作技巧。首先,概述了视频编码技术及其效率和质量的权衡原则,接着分析了信号处理技术在视频压缩中的应用,以及视频质量评估的主观与客观标准。文章接着介绍了PreScan Viewer的界面详解、高级视频预处理技术应用和高效视频输出设置。进
MSP430F5529软件编程全攻略:C语言到汇编,效率翻倍!

# 摘要
本文旨在全面介绍MSP430F5529微控制器的基础知识、开发环境搭建以及其在嵌入式系统中的应用。首先,文章回顾了C语言编程的基础,并探讨了如何在MSP430F5529开发环境中进行工程配置和构建。接着,深入分析了MSP430F5529的寄存器架构和硬件特性,提供了外设模块的编程细节,包括定时器、ADC/DAC转换以及通信接口的高级应用。此外,文章详细阐述
【COM Express操作系统选择】:如何挑选最适合您模块的操作系统
# 摘要
本文综合分析了COM Express模块的操作系统选择问题,从理论基础、实践方法到案例分析,系统地探讨了操作系统的选择和实施过程。首先介绍了COM Express模块的基本概念和特点,然后深入讨论了操作系统选择的理论基础,包括不同操作系统的分类、硬件兼容性、系统稳定性及安全性要求。在实践方法章节,本文关注了需求分析、社区支持评
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )