揭秘YOLO数据集加载的陷阱:常见问题及解决方案
发布时间: 2024-08-16 06:22:55 阅读量: 113 订阅数: 22 

yolo数据集8:1:1分类
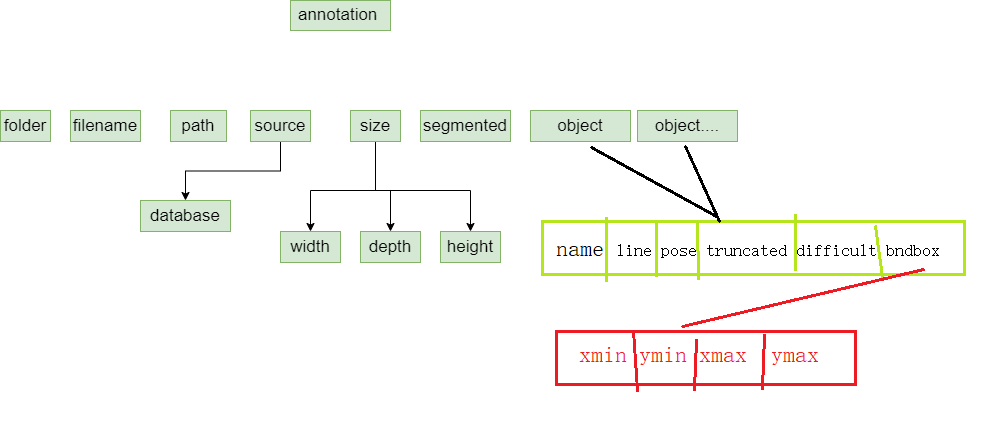
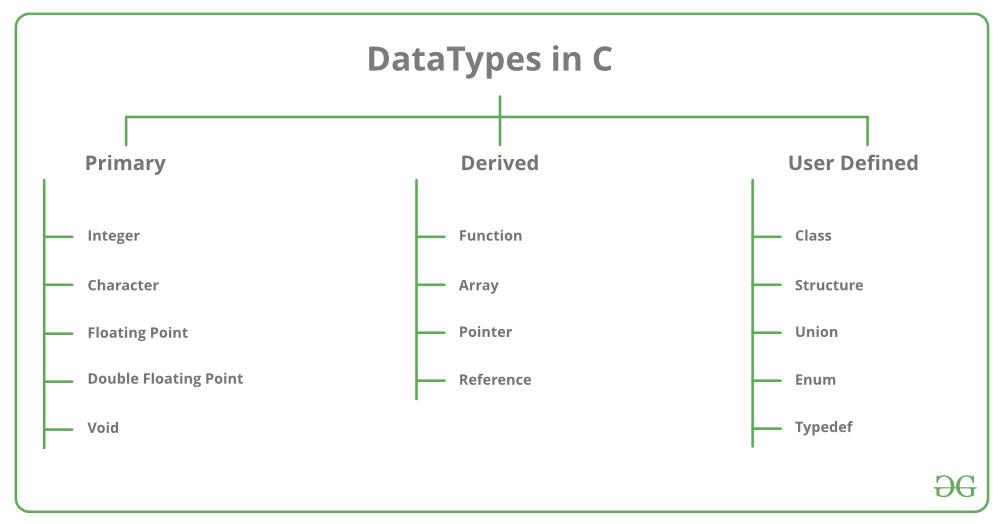
# 1. YOLO数据集简介
YOLO(You Only Look Once)数据集是专为目标检测任务设计的图像数据集。它包含大量带注释的图像,其中每个图像都包含一个或多个目标对象。YOLO数据集的独特之处在于其速度和准确性,使其成为训练和评估目标检测模型的理想选择。
YOLO数据集由多个版本组成,每个版本都包含不同数量的图像和注释。最流行的版本是YOLOv3和YOLOv4,它们分别包含80个和80个以上的目标类别。YOLO数据集中的图像通常是高分辨率的,并且以JPEG或PNG格式存储。每个图像都包含一个相应的XML文件,其中包含目标对象的边界框和类别标签。
# 2. YOLO数据集加载理论基础
### 2.1 YOLO数据集的结构和格式
YOLO数据集通常采用PASCAL VOC格式,该格式包含以下信息:
- **图像文件:**JPEG或PNG格式的图像文件,存储训练和测试图像。
- **标注文件:**XML格式的文件,存储每个图像中目标的边界框和类别信息。
**XML标注文件示例:**
```xml
<annotation>
<folder>VOC2007</folder>
<filename>000001.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
<flickrid>322409915</flickrid>
</source>
<owner>
<flickrid>null</flickrid>
<name>null</name>
</owner>
<size>
<width>500</width>
<height>375</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>dog</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>188</xmin>
<ymin>183</ymin>
<xmax>363</xmax>
<ymax>368</ymax>
</bndbox>
</object>
</annotation>
```
### 2.2 数据集加载的原理和流程
数据集加载涉及以下步骤:
1. **读取图像文件:**使用图像处理库(如OpenCV)读取图像文件并将其转换为Numpy数组。
2. **解析标注文件:**使用XML解析库(如xmltodict)解析XML标注文件并提取边界框和类别信息。
3. **数据预处理:**对图像和标注进行预处理,如调整大小、归一化、增强等。
4. **数据加载:**将预处理后的数据加载到内存或磁盘中,以便训练和评估模型。
**数据集加载流程图:**
```mermaid
graph LR
subgraph 数据集加载
A[读取图像文件] --> B[解析标注文件] --> C[数据预处理] --> D[数据加载]
end
```
**代码示例:**
```python
import cv2
import xmltodict
def load_yolo_dataset(image_dir, annotation_dir):
"""加载YOLO数据集
Args:
image_dir (str): 图像目录
annotation_dir (str): 标注目录
Returns:
list: 图像和标注列表
"""
images = []
annotations = []
for image_file in os.listdir(image_dir):
image = cv2.imread(os.path.join(image_dir, image_file))
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
images.append(image)
for annotation_file in os.listdir(annotation_dir):
with open(os.path.join(annotation_dir, annotation_file), "r") as f:
annotation = xmltodict.parse(f.read())
annotations.append(annotation)
return images, annotations
```
# 3. YOLO数据集加载实践技巧
### 3.1 数据集预处理和增强
#### 数据集预处理
数据集预处理是加载数据集之前的重要步骤,它可以提高模型的训练效果和效率。常见的预处理操作包括:
- **数据清洗:**删除损坏或不完整的数据,以及异常值。
- **数据归一化:**将数据值缩放到特定范围内,例如 [0, 1] 或 [-1, 1]。
- **数据标准化:**将数据值减去其均值并除以其标准差,使数据分布更接近正态分布。
#### 数据增强
数据增强是一种通过对原始数据进行变换来创建新数据样本的技术,它可以增加数据集的规模和多样性,从而提高模型的泛化能力。常见的增强操作包括:
- **翻转:**水平或垂直翻转图像。
- **旋转:**以一定角度旋转图像。
- **裁剪:**从图像中随机裁剪出不同大小和宽高比的区域。
- **颜色抖动:**随机改变图像的亮度、对比度和饱和度。
### 3.2 数据集加载的优化和加速
#### 多线程加载
多线程加载可以充分利用多核 CPU 的优势,并行加载数据。在 Python 中,可以使用 `multiprocessing` 模块创建多个进程来加载数据。
#### 内存映射
内存映射是一种将文件映射到内存中的技术,它允许直接访问文件内容,而无需每次读取数据时都从磁盘中读取。在 Python 中,可以使用 `mmap` 模块进行内存映射。
#### 预取加载
预取加载是一种预先将数据加载到内存中的技术,它可以减少后续加载数据的延迟。在 Python 中,可以使用 `numpy.load` 函数进行预取加载。
#### 代码示例:
```python
import multiprocessing
import numpy as np
import mmap
# 多线程加载
def load_data(filename):
with open(filename, "rb") as f:
data = f.read()
return data
def main():
filenames = ["file1.txt", "file2.txt", "file3.txt"]
pool = multiprocessing.Pool(processes=4)
data = pool.map(load_data, filenames)
# 内存映射
with open("file.txt", "rb") as f:
data = mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ)
# 预取加载
data = np.load("file.npy")
```
### 逻辑分析:
- **多线程加载:**使用 `multiprocessing` 模块创建多个进程,并行加载数据。
- **内存映射:**使用 `mmap` 模块将文件映射到内存中,直接访问文件内容。
- **预取加载:**使用 `numpy.load` 函数将数据预先加载到内存中。
# 4. YOLO 数据集加载常见问题及解决方案
### 4.1 数据集加载失败或不完整
#### 问题描述
在加载 YOLO 数据集时,可能会遇到数据集加载失败或不完整的问题。这可能是由于以下原因造成的:
- **文件损坏或不完整:**数据集文件在下载或传输过程中可能损坏或不完整。
- **文件路径错误:**加载脚本中指定的 YOLO 数据集文件路径不正确。
- **文件格式不兼容:**YOLO 数据集文件格式与加载脚本不兼容。
- **内存不足:**加载数据集所需的内存不足,导致加载过程失败。
#### 解决方案
- **检查文件完整性:**重新下载或传输 YOLO 数据集文件,确保其完整无损。
- **验证文件路径:**仔细检查加载脚本中指定的数据集文件路径,确保其准确无误。
- **检查文件格式:**确认 YOLO 数据集文件格式与加载脚本兼容。
- **增加内存:**如果内存不足,可以增加计算机的可用内存或使用更小的数据集。
### 4.2 数据集加载速度慢或内存占用高
#### 问题描述
加载 YOLO 数据集时,可能会遇到数据集加载速度慢或内存占用高的现象。这可能是由于以下原因造成的:
- **数据集过大:**YOLO 数据集包含大量图像和标注,加载大型数据集会耗费大量时间和内存。
- **加载过程低效:**加载脚本中使用的加载算法效率低下,导致加载速度慢。
- **内存管理不当:**加载脚本中没有正确管理内存,导致内存占用高。
#### 解决方案
- **使用较小数据集:**如果可能,使用较小的 YOLO 数据集,以减少加载时间和内存占用。
- **优化加载算法:**使用高效的加载算法,例如多线程加载或并行加载。
- **优化内存管理:**使用内存管理技术,例如缓存和内存池,以减少内存占用。
### 代码示例
以下代码示例展示了如何使用多线程加载 YOLO 数据集,以提高加载速度:
```python
import threading
import cv2
class YOLODatasetLoader(threading.Thread):
def __init__(self, dataset_path, batch_size):
super().__init__()
self.dataset_path = dataset_path
self.batch_size = batch_size
self.images = []
self.labels = []
def run(self):
with open(self.dataset_path, 'r') as f:
for line in f:
image_path, label_path = line.strip().split(' ')
image = cv2.imread(image_path)
label = cv2.imread(label_path)
self.images.append(image)
self.labels.append(label)
while True:
batch_images = []
batch_labels = []
for i in range(self.batch_size):
index = np.random.randint(len(self.images))
batch_images.append(self.images[index])
batch_labels.append(self.labels[index])
yield batch_images, batch_labels
# 创建多线程加载器
num_threads = 4
loaders = [YOLODatasetLoader(dataset_path, batch_size) for i in range(num_threads)]
# 启动加载器
for loader in loaders:
loader.start()
# 从加载器中获取批次数据
for batch_images, batch_labels in zip(*loaders):
# 处理批次数据
pass
```
### 参数说明
- `dataset_path`:YOLO 数据集文件路径。
- `batch_size`:每个批次加载的图像数量。
- `images`:加载的图像列表。
- `labels`:加载的标注列表。
- `num_threads`:加载器线程数量。
### 代码逻辑分析
该代码使用多线程加载 YOLO 数据集,以提高加载速度。它创建了多个加载器线程,每个线程负责加载一部分数据集。加载器线程从数据集文件中读取图像和标注,并将其存储在 `images` 和 `labels` 列表中。
主线程从加载器线程中获取批次数据,并对批次数据进行处理。这种多线程加载方式可以并行加载数据集,从而提高加载速度。
# 5. YOLO数据集加载的最佳实践和注意事项
### 5.1 数据集加载的性能评估
为了评估数据集加载的性能,可以考虑以下指标:
- **加载时间:**从开始加载到数据集完全加载到内存中所需的时间。
- **内存占用:**数据集加载后占用的内存量。
- **吞吐量:**每秒加载的数据量。
### 5.2 数据集加载的最佳实践和注意事项
为了优化数据集加载的性能,并避免常见问题,请遵循以下最佳实践和注意事项:
- **使用高效的数据加载器:**选择专为快速和高效的数据加载而设计的库或框架。
- **预处理和增强数据:**在加载数据之前,预处理和增强数据可以提高模型的性能。这可能包括调整图像大小、归一化像素值或应用数据增强技术。
- **并行加载:**如果可能,并行加载数据以提高吞吐量。这可以通过使用多线程或多进程来实现。
- **缓存数据:**如果数据集频繁加载,请考虑将其缓存到内存中以提高后续加载的速度。
- **使用内存映射:**内存映射允许直接访问文件中的数据,而无需将其加载到内存中。这可以减少内存占用并提高加载速度。
- **监视加载性能:**定期监视数据集加载的性能以识别瓶颈并进行优化。
- **避免加载不必要的数据:**仅加载模型训练或推理所需的必要数据。
- **使用适当的数据类型:**选择适当的数据类型以优化内存占用和处理速度。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 YOLO 自定义数据集构建指南!本专栏将带你踏上从头开始构建 YOLO 训练集的旅程。我们将揭开 YOLO 数据集加载过程中的常见陷阱,并提供解决方案。了解如何优化数据集策略以提高训练效率。我们还将比较不同的 YOLO 数据集标注工具,帮助你选择最适合你的助手。
深入了解 YOLO 数据集增强技术,提升模型泛化能力。探索 YOLO 数据集评估指标,掌握衡量模型性能的权威标准。获取 YOLO 数据集管理秘诀,优化训练过程。掌握 YOLO 数据集版本管理,保持数据一致性和可追溯性。保护敏感数据的 YOLO 数据集安全指南必不可少。
促进团队合作的 YOLO 数据集共享和协作策略将帮助你充分利用数据集。挖掘数据中的宝藏,通过数据分析和模式识别获得洞察力。直观呈现 YOLO 数据集,通过数据分布可视化发现模式。识别并处理异常数据,确保数据集的质量。消除训练数据偏见,提高模型的公平性和准确性。
通过数据集合成生成更多训练数据,增强模型性能。掌握 YOLO 数据集转换技巧,轻松转换格式。从外部来源扩展 YOLO 数据集,丰富数据多样性。合并数据集以增强多样性,执行 YOLO 数据集聚合。最后,通过 YOLO 数据集清理大扫除,去除冗余和不相关的数据,确保数据集的干净和有效。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
空间统计学新手必看:Geoda与Moran'I指数的绝配应用
# 摘要
本论文深入探讨了空间统计学在地理数据分析中的应用,特别是运用Geoda软件进行空间数据分析的入门指导和Moran'I指数的理论与实践操作。通过详细阐述Geoda界面布局、数据操作、空间权重矩阵构建以及Moran'I指数的计算和应用,本文旨在为读者提供一个系统的学习路径和实操指南。此外,本文还探讨了如何利用Moran'I指数进行有效的空间数据分析和可视化,包括城市热岛效应的空间分析案例研究。最终,论文展望了空间统计学的未来
【Python数据处理秘籍】:专家教你如何高效清洗和预处理数据

# 摘要
随着数据科学的快速发展,Python作为一门强大的编程语言,在数据处理领域显示出了其独特的便捷性和高效性。本文首先概述了Python在数据处理中的应用,随后深入探讨了数据清洗的理论基础和实践,包括数据质量问题的认识、数据清洗的目标与策略,以及缺失值、异常值和噪声数据的处理方法。接着,文章介绍了Pandas和NumPy等常用Python数据处理库,并具体演示了这些库在实际数
【多物理场仿真:BH曲线的新角色】:探索其在多物理场中的应用
# 摘要
本文系统介绍了多物理场仿真的理论基础,并深入探讨了BH曲线的定义、特性及其在多种材料中的表现。文章详细阐述了BH曲线的数学模型、测量技术以及在电磁场和热力学仿真中的应用。通过对BH曲线在电机、变压器和磁性存储器设计中的应用实例分析,本文揭示了其在工程实践中的重要性。最后,文章展望了BH曲线研究的未来方向,包括多物理场仿真中BH曲线的局限性
【CAM350 Gerber文件导入秘籍】:彻底告别文件不兼容问题
# 摘要
本文全面介绍了CAM350软件中Gerber文件的导入、校验、编辑和集成过程。首先概述了CAM350与Gerber文件导入的基本概念和软件环境设置,随后深入探讨了Gerber文件格式的结构、扩展格式以及版本差异。文章详细阐述了在CAM350中导入Gerber文件的步骤,包括前期
【秒杀时间转换难题】:掌握INT、S5Time、Time转换的终极技巧
# 摘要
时间表示与转换在软件开发、系统工程和日志分析等多个领域中起着至关重要的作用。本文系统地梳理了时间表示的概念框架,深入探讨了INT、S5Time和Time数据类型及其转换方法。通过分析这些数据类型的基本知识、特点、以及它们在不同应用场景中的表现,本文揭示了时间转换在跨系统时间同步、日志分析等实际问题中的应用,并提供了优化时间转换效率的策略和最
【传感器网络搭建实战】:51单片机协同多个MLX90614的挑战

# 摘要
本论文首先介绍了传感器网络的基础知识以及MLX90614红外温度传感器的特点。接着,详细分析了51单片机与MLX90614之间的通信原理,包括51单片机的工作原理、编程环境的搭建,以及传感器的数据输出格式和I2C通信协议。在传感器网络的搭建与编程章节中,探讨了网络架构设计、硬件连接、控制程序编写以及软件实现和调试技巧。进一步
Python 3.9新特性深度解析:2023年必知的编程更新
# 摘要
随着编程语言的不断进化,Python 3.9作为最新版本,引入了多项新特性和改进,旨在提升编程效率和代码的可读性。本文首先概述了Python 3.
金蝶K3凭证接口安全机制详解:保障数据传输安全无忧
# 摘要
金蝶K3凭证接口作为企业资源规划系统中数据交换的关键组件,其安全性能直接影响到整个系统的数据安全和业务连续性。本文系统阐述了金蝶K3凭证接口的安全理论基础,包括安全需求分析、加密技术原理及其在金蝶K3中的应用。通过实战配置和安全验证的实践介绍,本文进一步阐释了接口安全配置的步骤、用户身份验证和审计日志的实施方法。案例分析突出了在安全加固中的具体威胁识别和解决策略,以及安全优化对业务性能的影响。最后
【C++ Builder 6.0 多线程编程】:性能提升的黄金法则
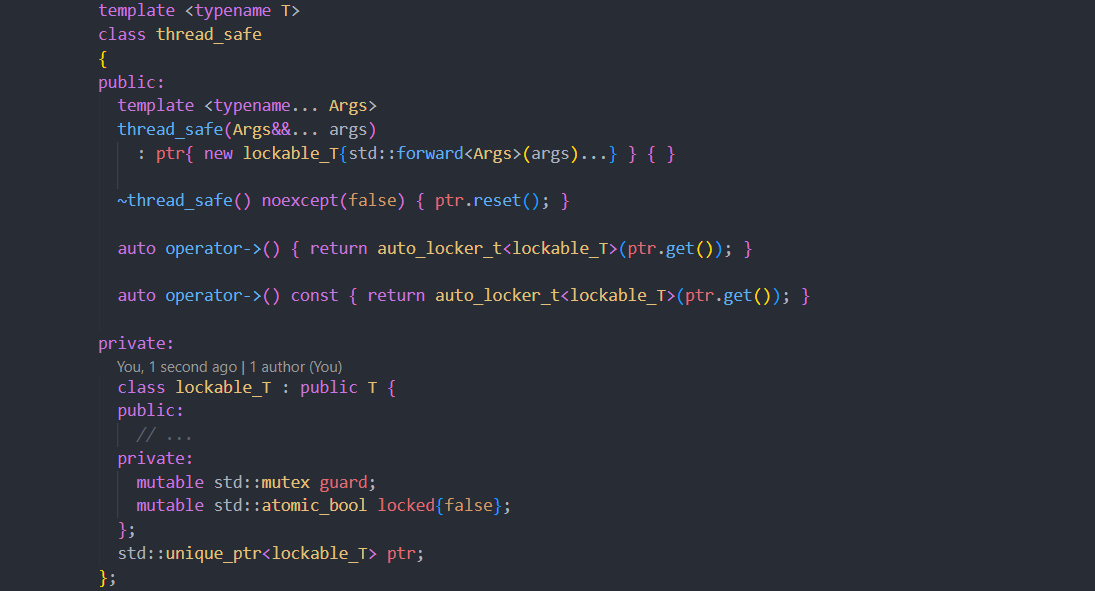
# 摘要
随着计算机技术的进步,多线程编程已成为软件开发中的重要组成部分,尤其是在提高应用程序性能和响应能力方面。C++ Builder 6.0作为开发工具,提供了丰富的多线程编程支持。本文首先概述了多线程编程的基础知识以及C++ Builder 6.0的相关特性,然后深入探讨了该环境下线程的创建、管理、同步机制和异常处理。接着,文章提供了多线程实战技巧,包括数据共享
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )