R语言环境搭建全攻略:打造专属你的高效数据分析工作站
发布时间: 2024-11-11 07:30:12 阅读量: 53 订阅数: 38 

R语言数据导入与导出:高效处理数据的实用指南

# 1. R语言概述及其重要性
## 1.1 R语言简介
R语言是一种用于统计分析、图形表示和报告的语言和环境,它成立于1993年,并在随后的年份里迅速发展。R语言的语法简洁明了,具有极强的扩展能力,它支持各种常见的统计模型,包括线性模型、广义线性模型、非参数模型和混合效应模型等。
## 1.2 R语言的重要性
在数据科学领域,R语言因其强大的数据处理能力和丰富的图形功能而变得至关重要。它不仅支持数据的输入输出、数据处理、计算和图形展示,而且是众多机器学习方法的实现平台。其开源特性、活跃的社区和持续更新的包库,使得R语言成为IT行业尤其是数据分析师和统计学家不可或缺的工具。
## 1.3 R语言的行业应用
R语言广泛应用于金融、医疗保健、零售和社交媒体等多个行业。在金融领域,R语言可以用于风险分析和资产配置;在生物信息学中,它可以处理和分析大量的基因组数据;而在零售行业,R语言常用于市场细分和消费趋势分析。由于其灵活性和有效性,R语言在数据分析和科学计算领域正变得越来越流行。
# 2. R语言环境安装与配置
### 2.1 选择合适的操作系统
在开始安装R语言之前,首先需要选择一个合适的操作系统。R语言支持多种操作系统,包括Windows、macOS以及各种Linux发行版。选择操作系统时,应考虑个人习惯、工作环境需求以及特定软件包的兼容性。
#### 2.1.1 Windows平台的R语言环境搭建
Windows是最广泛使用的个人计算机操作系统之一,对R语言有着良好的支持。以下是Windows平台上安装R语言环境的步骤:
1. 访问R语言官方网站下载页面(***)。
2. 选择与您的操作系统相对应的最新版本。
3. 下载Windows版本的安装文件。
4. 双击下载的安装文件,并按照安装向导的提示进行操作。
安装向导会指引您完成所有必要的配置步骤。特别注意,在安装过程中选择将R添加到系统路径,这样可以在任何命令行窗口中直接使用R命令。
```mermaid
graph TD;
A[访问R官网] --> B[选择下载Windows版本]
B --> C[下载安装文件]
C --> D[双击运行安装文件]
D --> E[按向导完成安装]
E --> F[选择添加R到系统路径]
F --> G[完成安装]
```
#### 2.1.2 macOS平台的R语言环境搭建
macOS用户可以使用多种方法来安装R语言,包括官方的安装包或者使用包管理器如Homebrew。以下是使用官方安装包在macOS上安装R语言的步骤:
1. 访问R语言官方网站下载页面。
2. 选择macOS版本的安装包。
3. 下载安装包后,双击打开并运行安装程序。
4. 根据安装向导完成安装。
5. 安装完成后,您可能需要手动将R添加到环境变量路径。
使用Homebrew的用户则可以通过以下命令快速安装R语言:
```sh
brew install r
```
#### 2.1.3 Linux平台的R语言环境搭建
Linux用户可以利用系统的包管理器来安装R语言,这在大多数Linux发行版中都是直接可用的。以Ubuntu为例,安装步骤如下:
1. 打开终端。
2. 更新包索引:
```sh
sudo apt-get update
```
3. 安装R语言:
```sh
sudo apt-get install r-base
```
安装完成后,您可以通过在终端输入`R`命令来启动R语言。
### 2.2 安装R语言基础软件包
#### 2.2.1 安装R语言
安装R语言本身非常直接,以下是跨平台通用的安装步骤:
- 访问CRAN(Comprehensive R Archive Network)并下载对应操作系统的安装文件。
- 运行安装程序并遵循安装向导的提示。
在Windows系统中,安装程序会自动处理环境变量的配置。在macOS和Linux中,您可能需要手动将R语言的安装路径添加到环境变量中,以确保在任何目录下都能通过命令行调用R。
#### 2.2.2 配置R语言环境变量
环境变量是操作系统用来指定操作系统运行环境的一些参数,例如可执行文件的路径等。配置R语言环境变量确保您可以从命令行窗口运行R语言。以下是跨平台的环境变量配置方法:
- 在Windows中,环境变量可以在安装过程中设置,或者在"系统属性" -> "高级" -> "环境变量"中手动添加。
- 在macOS和Linux中,可以修改`.bashrc`或`.zshrc`文件来永久设置环境变量。
```sh
# 以bash shell为例,打开终端输入以下命令:
export PATH=$PATH:/path/to/R/bin
```
### 2.3 配置集成开发环境(IDE)
#### 2.3.1 RStudio介绍与安装
RStudio是R语言的一个流行的集成开发环境,提供代码编辑、图形界面、包管理等强大功能。以下是安装RStudio的步骤:
1. 访问RStudio官方网站下载页面(***)。
2. 选择适合您操作系统的RStudio版本。
3. 下载相应的安装包。
4. 运行安装包并按照提示完成安装。
#### 2.3.2 配置RStudio以提高工作效率
安装完RStudio后,可以通过以下步骤来进一步配置:
- 安装和配置R语言包管理器,如Packrat或renv,以便管理项目依赖。
- 配置代码片段、快捷键和工作区布局,以适应个人编程习惯。
- 集成版本控制工具,如Git,以便进行版本控制和代码协作。
通过这些步骤的配置,RStudio将变得更加适合您的工作流程,从而提高编码和分析的效率。
# 3. R语言包管理与使用
## 3.1 R语言包的基本概念
### 3.1.1 包的安装与更新
R语言的核心优势之一在于其丰富的包资源,这些包包含了特定领域的函数和数据集,极大的扩展了R语言的实用性。安装R包十分简单,使用`install.packages("package_name")`函数即可完成安装。为了更新已安装的包,可以使用`update.packages()`函数。
```r
# 安装一个包
install.packages("ggplot2")
# 更新所有已安装的包
update.packages()
```
安装过程中,R会自动选择CRAN镜像服务器,但用户也可以手动指定使用其他镜像。更新包时,R会检查每个包的版本,并下载更新版本替换旧版本。这个过程保证了用户始终能使用到最新的功能和修复。
### 3.1.2 包的管理与卸载
包的管理是日常使用R语言中不可避免的环节。可以使用`library()`或`require()`函数来加载已经安装的包,或者使用`detach()`函数来卸载包。卸载时需要注意,某些包可能依赖于其他包,因此可能需要一并卸载。
```r
# 加载一个包
library(ggplot2)
# 卸载一个包
detach("package:ggplot2", unload=TRUE)
# 一次性卸载多个包
remove.packages(c("dplyr", "tidyr"))
```
卸载包时,应确保没有正在使用的对象或代码依赖于该包,否则会导致错误。为了管理包,RStudio提供了一个图形界面,可以更加直观地安装、更新和卸载包。
## 3.2 掌握CRAN与Bioconductor
### 3.2.1 从CRAN安装包
CRAN是R的官方包仓库,提供了成千上万个由社区贡献的包。使用`install.packages()`函数默认从CRAN安装包。在安装前,可以通过`available.packages()`函数查看CRAN上所有的包及其版本信息。
```r
# 查看所有可用的包及其版本信息
available.packages()
```
在安装包时,由于包的版本更新可能会引入不兼容的变化,建议根据项目需求选择合适的版本进行安装。为了避免在数据分析过程中产生意外的不兼容问题,稳定的包版本管理策略是非常重要的。
### 3.2.2 从Bioconductor安装包
Bioconductor是一个专门针对生物信息学领域的R包集合。它提供了安装工具`biocLite()`来安装Bioconductor包。为了安装`biocLite()`,可以先执行以下代码:
```r
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install()
```
一旦有了`BiocManager`,安装Bioconductor包的过程就变得简单了:
```r
# 安装Bioconductor包
BiocManager::install("GenomicRanges")
```
## 3.3 高级包管理技巧
### 3.3.1 源码安装R包
在某些情况下,出于对最新功能或特定功能的需求,用户可能需要从源代码安装R包。这通常发生在官方CRAN或Bioconductor仓库尚未更新的包的情况下。源码安装通常需要系统上安装了编译工具链,如在Windows上需要安装Rtools。
```r
# 从源码安装一个包
install.packages("path/to/package.tar.gz", repos = NULL, type = "source")
```
源码安装可以确保用户获得最新版本的包,但也可能因为系统依赖问题或编译错误而导致安装失败。建议在源码安装时,仔细阅读包的说明文档,并确保所有必要的依赖项都已经安装。
### 3.3.2 包的依赖管理
依赖管理是R包管理中的一个复杂话题。R包可能会依赖于其他包,而这些依赖包本身又可能有其他的依赖,这可能导致版本冲突。为了避免这种情况,可以使用`sessionInfo()`函数查看当前R会话的包依赖树。
```r
# 查看当前R会话的包依赖信息
sessionInfo()
```
为了管理依赖,可以考虑使用`packrat`或`renv`等R包,这些包允许创建项目的私有包库,从而确保项目依赖的一致性和隔离性。此外,在RStudio中,包管理器界面也提供了依赖检查的功能,可以直观地管理包的依赖关系。
以上是第三章关于R语言包管理与使用的详细内容。这一章节深入探讨了包的安装、更新、管理以及高级技巧,旨在为读者提供全面的R语言包使用和管理知识。通过这些内容的学习,读者将能够有效地管理R环境中的各种包,为数据分析工作提供坚实的基础。
# 4. R语言环境的进阶配置
## 4.1 配置高性能计算环境
### 4.1.1 多核处理与并行计算
R语言通过多种包提供了并行计算的能力,这对于处理大规模数据集和计算密集型任务至关重要。并行计算可以显著减少运行时间,特别是当面对统计建模、大规模模拟或复杂的机器学习算法时。为了实现这一目标,我们可以采用几种策略:
1. **基础并行包(parallel)** - R自带的parallel包提供了基础的并行功能,包括多线程处理和集群并行。你可以使用`mclapply`(基于多核处理)或`clusterApply`(基于集群)等函数来实现并行计算。
2. **高性能计算包(doParallel/doMPI)** - 这些包为并行计算提供了额外的支持,并且能够与foreach循环结合使用,以达到并行执行的目的。
下面是一个使用doParallel包进行多核并行计算的示例代码:
```r
# 安装并加载并行计算所需的包
if (!require(doParallel)) install.packages("doParallel")
library(doParallel)
# 设置并行核的数量
cl <- makeCluster(detectCores() - 1) # 使用所有CPU核心,减去1避免占用太多系统资源
# 注册为集群
registerDoParallel(cl)
# 并行计算示例:计算1到10的平方和
result <- foreach(i = 1:10) %dopar% {
i^2
}
# 关闭集群
stopCluster(cl)
# 输出结果
print(result)
```
在上述代码中,我们首先检测可用的核心数,并创建一个集群对象,随后注册该集群为并行环境,并使用`foreach`循环并行执行计算任务。最后,关闭集群释放资源。请确保在生产环境中适当管理并行集群的生命周期,以避免资源耗尽。
### 4.1.2 GPU加速在R环境中的应用
虽然R语言天生不是为GPU加速设计的,但通过特定的包和工具,可以利用GPU强大的并行处理能力加速计算。`gputools`包是一个流行的GPU加速工具,它允许用户在R中使用CUDA驱动的GPU进行矩阵运算和统计分析。
```r
# 安装并加载gputools包
if (!require(gputools)) install.packages("gputools")
library(gputools)
# 示例:使用GPU进行矩阵乘法
A <- matrix(rnorm(1e5), nrow = 1000)
B <- matrix(rnorm(1e5), nrow = 1000)
# 将矩阵上传至GPU
A_gpu <- gpuMatrix(A, type = "float")
B_gpu <- gpuMatrix(B, type = "float")
# 在GPU上执行矩阵乘法
C_gpu <- A_gpu %*% B_gpu
# 将结果从GPU下载回R环境
C <- as.array(C_gpu)
# 输出结果
print(C)
```
使用GPU进行计算时,重要的是要注意数据传输和内存管理。GPU计算适合于内存需求大和计算密集型的任务。然而,由于GPU计算涉及数据在CPU和GPU之间的传输,所以需要合理安排数据处理流程,以避免I/O瓶颈。
## 4.2 自定义工作空间与版本控制
### 4.2.1 工作空间管理与配置文件
为了维护一个高效和可重复的研究工作环境,管理好R的工作空间和配置文件至关重要。R提供了一些工具来帮助用户自定义和优化工作环境。
1. **.Rprofile** - 这是一个R启动时自动执行的脚本文件,可以放在用户的主目录或项目目录下。通过`.Rprofile`文件,可以自定义R的启动环境,加载常用的库,设置选项等。
2. **.Renviron** - 这个文件用来定义环境变量。R运行时会读取这些变量,可以用来存储API密钥、数据库连接字符串等敏感信息。
3. **RStudio项目(.Rproj)** - 如果使用RStudio,创建项目文件(.Rproj)可以帮助你为每个项目设置一个独立的工作环境,便于管理项目依赖和配置。
### 4.2.2 版本控制在R开发中的应用
版本控制是软件开发中的标准实践,对于R语言项目同样适用。使用Git进行版本控制可以让你跟踪代码变更、协作并行开发和回溯历史版本。
1. **使用RStudio集成Git** - RStudio为Git提供了一个友好的用户界面。你可以直接在RStudio中初始化Git仓库、提交更改、创建分支和合并等。
2. **编写README和License** - 在项目根目录下包含一个README文件,它可以提供项目信息、安装和使用指南。同样地,创建一个License文件来明确代码的版权和使用条件。
3. **使用远程仓库托管服务** - 例如GitHub、GitLab或Bitbucket,这些服务可以用来备份你的代码,与他人协作和共享代码。
## 4.3 调整与优化R环境
### 4.3.1 内存管理与性能监控
随着数据集的增大,R环境的内存管理变得越来越重要。R中有一些工具和策略可以帮助优化内存使用:
1. **Rprof** - 这是R的一个性能分析工具,可以用来监控R代码的性能,并识别出内存使用和计算瓶颈。
2. **object.size** - 通过这个函数可以查看单个对象的内存大小。
3. **内存清理** - 使用`rm`函数和`gc`(垃圾回收)函数可以清理不再使用的对象,释放内存。
```r
# 查看对象大小示例
size_of_data <- object.size(mtcars) # mtcars是R内置数据集
print(size_of_data)
# 内存清理示例
rm(list = ls()) # 删除所有对象
gc() # 运行垃圾回收
```
### 4.3.2 调整垃圾回收机制
垃圾回收(garbage collection)是R语言自动进行的内存管理过程。随着内存使用量的增加,自动垃圾回收会变得频繁,可能会影响性能。通过调整R的垃圾回收参数,可以优化内存管理。
1. **调整R的选项** - R的内存管理可以通过多种选项进行微调。例如,`options()`函数可以用来设置`gcinterval`(垃圾回收间隔)和其他相关选项。
2. **使用底层内存管理函数** - R提供了一些底层内存管理函数,如`memCompress()`和`memDecompress()`,这些可以用来在不触发垃圾回收的情况下,手动压缩和解压数据。
```r
# 设置垃圾回收间隔示例
options(gctorture = TRUE) # 激活垃圾回收压力测试模式,用于内存密集型任务
# 手动压缩内存
compressed_data <- memCompress(rawToChar(as.raw(mtcars)), "gzip")
```
在实际应用中,需要根据具体的内存需求和任务特性来调整垃圾回收的设置,以达到最佳性能。调整时建议进行严格的性能测试,以确保所做的更改能够有效提高性能。
通过以上进阶配置,R语言的用户可以提升R环境的性能,实现更高效的数据处理和分析工作。在实际应用中,每个设置都需要根据项目需求和计算资源进行个性化的调整,以达到最优的工作环境。
# 5. R语言的实践应用案例
在这一章节中,我们将通过具体的应用案例深入探讨R语言如何在数据分析、机器学习以及特定领域应用中发挥作用。R语言不仅仅是一门编程语言,它还是一个功能强大的工具,能够帮助数据科学家、统计学家以及分析师解决各种复杂问题。我们从数据分析与可视化案例开始,进一步探索机器学习应用,最后聚焦于R语言在特定领域,如生物信息学和金融数据分析中的独特应用。
## 5.1 数据分析与可视化案例
数据分析是R语言的核心应用领域之一。在这个子章节中,我们将通过案例学习如何导入和预处理数据,以及如何利用R语言的强大可视化工具来展示数据分析结果。
### 5.1.1 数据导入与预处理
R语言具有多种方法来导入和预处理数据。从简单的CSV文件到复杂的数据库系统,R语言都能提供相应的方法进行数据读取。以CSV文件为例,我们可以使用`read.csv`函数来导入数据:
```R
# 导入CSV文件数据
data <- read.csv("data.csv")
```
在导入数据后,我们通常需要进行一系列预处理步骤。这包括数据清洗、数据类型转换、缺失值处理和数据变换等。R语言的`dplyr`包提供了简洁的数据操作语法,可以帮助我们高效地完成数据预处理任务。
```R
# 使用dplyr包进行数据预处理
library(dplyr)
data <- data %>%
mutate(column1 = as.factor(column1)) %>%
filter(column2 > 0) %>%
na.omit() %>%
select(-column3)
```
预处理后的数据将更适合用于后续的分析和可视化。
### 5.1.2 数据可视化技巧与实践
R语言的可视化能力非常强大,通过使用`ggplot2`包,我们可以制作出高质量且美观的图表。下面的代码展示了如何使用`ggplot2`来创建一个散点图,并通过分面(facet)展示数据的不同方面。
```R
# 加载ggplot2包并创建散点图
library(ggplot2)
ggplot(data, aes(x=column1, y=column2)) +
geom_point() +
facet_wrap(~column3) +
theme_minimal()
```
在本案例中,我们创建了一个以`column1`为X轴,`column2`为Y轴的散点图。通过`facet_wrap`函数,我们按照`column3`的不同类别将数据分面展示,这有助于我们更清晰地观察到不同类别下数据的分布情况。
## 5.2 机器学习应用
机器学习是R语言的另一个重要应用领域。通过R语言中的包,比如`caret`和`randomForest`,我们可以轻松实现各种机器学习算法,并对模型进行评估和调优。
### 5.2.1 机器学习算法应用示例
下面代码演示了如何使用`randomForest`包建立一个随机森林模型,并使用训练数据集进行模型训练。
```R
# 加载randomForest包并训练模型
library(randomForest)
model <- randomForest(y ~ ., data = train_data)
```
在这个例子中,`train_data`是已经被划分好的训练数据集,其中`y`是目标变量,`~ .`表示使用所有的其他特征作为模型输入。
### 5.2.2 模型评估与调优策略
训练模型后,我们需评估模型的性能。通过创建混淆矩阵和计算准确率,我们可以对模型进行初步评估:
```R
# 预测测试数据集并创建混淆矩阵
predictions <- predict(model, test_data)
confusion_matrix <- table(predictions, test_data$y)
# 计算准确率
accuracy <- sum(diag(confusion_matrix)) / sum(confusion_matrix)
```
模型调优是机器学习中的重要步骤。通过网格搜索(Grid Search)可以尝试不同的参数组合,以找到最优模型配置。
```R
# 使用caret包进行模型调优
library(caret)
train_control <- trainControl(method="cv", number=10)
tune_grid <- expand.grid(.mtry=c(2, 3, 4))
model_tuned <- train(y ~ ., data = train_data, method="rf", trControl=train_control, tuneGrid=tune_grid)
print(model_tuned)
```
在这个调优示例中,我们使用了交叉验证(`cv`)方法,并尝试了不同的`mtry`参数值。
## 5.3 R语言在特定领域的应用
R语言在特定领域也有着广泛的应用。本节将探讨R语言在生物信息学和金融数据分析中的应用案例。
### 5.3.1 生物信息学中的应用
在生物信息学中,R语言被广泛用于基因表达数据分析。通过使用`Bioconductor`,我们可以访问专门针对生物信息学设计的R包和工具。
```R
# 安装Bioconductor
if (!requireNamespace("BiocManager", quietly = TRUE))
install.packages("BiocManager")
BiocManager::install()
```
一旦安装了`Bioconductor`,就可以安装专门的包,比如`limma`,用于处理微阵列数据的差异表达分析。
### 5.3.2 金融数据分析中的应用
在金融数据分析中,R语言可用于构建和回测投资策略,预测市场趋势。`xts`和`zoo`包可以帮助我们处理时间序列数据,`quantmod`包可以用于获取金融市场数据。
```R
# 安装金融分析相关包
install.packages(c("xts", "zoo", "quantmod"))
library(xts)
library(zoo)
library(quantmod)
# 使用quantmod获取股票价格数据
getSymbols("AAPL")
apple_prices <- Cl(AAPL)
```
在这个例子中,我们使用`quantmod`包获取了苹果公司的股票收盘价,并将其存储在`apple_prices`变量中。
## 总结
在本章中,我们深入探讨了R语言在实践中的具体应用案例,涵盖了数据分析与可视化、机器学习以及特定领域应用。通过实际案例的展示,我们了解了R语言如何在各种场合下提供强大的数据处理和分析能力。在下一章中,我们将探索R语言社区资源以及如何成为R语言的贡献者。
# 6. R语言社区与资源
## 6.1 探索R语言社区资源
R语言之所以能够在数据科学领域拥有强大的影响力,很大程度上得益于其活跃的社区和丰富的资源。无论是初学者还是经验丰富的开发者,都可以从这些社区和资源中获益。
### 6.1.1 加入R语言论坛与社群
加入R语言的论坛和社群是一个学习和交流的好途径。在这里,你可以提出问题,分享自己的项目,或者参与到其他人的讨论中。一些值得推荐的社区资源包括:
- R-Project官方网站:官方社区论坛,提供最新资讯和问答平台。
- Stack Overflow:一个庞大的编程问答社区,以标签形式组织问题。
- R Bloggers:这个平台汇聚了大量R语言的博客文章,适合阅读和学习。
- GitHub:在这里可以找到大量的R语言项目和贡献者。
### 6.1.2 书籍、课程和研讨会资源
通过阅读书籍、参加在线课程和研讨会,可以系统地学习R语言。
- 书籍:如《R语言实战》、《高级R》等,为不同水平的读者提供了深入学习的资料。
- 在线课程:Coursera、edX、DataCamp等平台提供了多种R语言课程。
- 研讨会:比如rstudio::conf,是R语言开发者的重要交流平台。
## 6.2 维护与升级R语言环境
为了保持R语言环境的最佳性能和安全性,定期进行维护和升级是必要的步骤。
### 6.2.1 定期更新R语言与包
R语言和其包的更新往往包含性能提升和安全修复。因此,保持最新状态是重要的。可以通过以下命令实现:
```r
# 更新R语言
updateR()
# 更新所有已安装的包
update.packages(ask = FALSE, checkBuilt = TRUE)
```
### 6.2.2 保障R环境的安全性与稳定性
R社区非常重视代码的安全性与稳定性。以下是几个保障环境安全稳定的建议:
- 使用RStudio或其他IDE来管理R环境,它们通常提供了更安全的编码环境。
- 定期备份工作目录和重要项目。
- 使用版本控制系统如git来跟踪代码的变更。
## 6.3 成为R语言的贡献者
R语言的成功也建立在其开源精神上,任何有志于贡献的人都可以参与到这个过程中。
### 6.3.1 贡献代码与包到CRAN
如果你编写了R语言包并希望贡献到CRAN,需要确保你的代码符合CRAN的发布标准。CRAN有严格的审查流程,确保每个提交的包都具有高质量。这需要:
- 确保代码的正确性和文档的完整性。
- 代码需要通过一系列CRAN的检查,包括代码风格和性能测试。
### 6.3.2 参与R社区的开源项目
即使不直接贡献代码,你也可以通过参与开源项目来支持R社区:
- 贡献文档、翻译、教程等非代码内容。
- 测试他人开发的包并提供反馈。
- 参与或组织R语言相关的本地用户组或meetup。
通过参与R社区,不仅能帮助他人,也能加深自己对R语言的理解,从而在数据科学领域取得更多的进步。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏提供有关 R 语言 RCurl 数据包的全面指南。从安装和管理到高级技巧,您将掌握如何使用 RCurl 处理复杂网络请求、清洗非结构化数据、与 Web API 交互、构建图形界面,以及在数据处理、统计建模、文本分析、时间序列分析、并行计算和高级数据处理等领域应用 RCurl。通过深入的教程和实战演练,您将提升 R 语言技能,并解锁 RCurl 在数据处理生态系统中的强大功能。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【MATLAB中MSK调制的艺术】:差分编码技术的优化与应用

# 摘要
MSK调制技术作为现代通信系统中的一种关键调制方式,与差分编码相结合能够提升信号传输的效率和抗干扰能力。本文首先介绍了MSK调制技术和差分编码的基础理论,然后详细探讨了差分编码在MSK调制中的应用,包括MSK调制器设计与差分编码
从零开始学习RLE-8:一文读懂BMP图像解码的技术细节

# 摘要
本文从编码基础与图像格式出发,深入探讨了RLE-8编码技术在图像处理领域的应用。首先介绍了RLE-8编码机制及其在BMP图像格式中的应用,然后详细阐述了RLE-8的编码原理、解码算法,包括其基本概念、规则、算法实现及性能优化策略。接着,本文提供了BMP图像的解码实践指南,解析了文件结构,并指导了RLE-8解码器的开发流程。文章进一步分析了RLE-8在图像压缩中的优势和适用场景,以及其在高级图像处
Linux系统管理新手入门:0基础快速掌握RoseMirrorHA部署
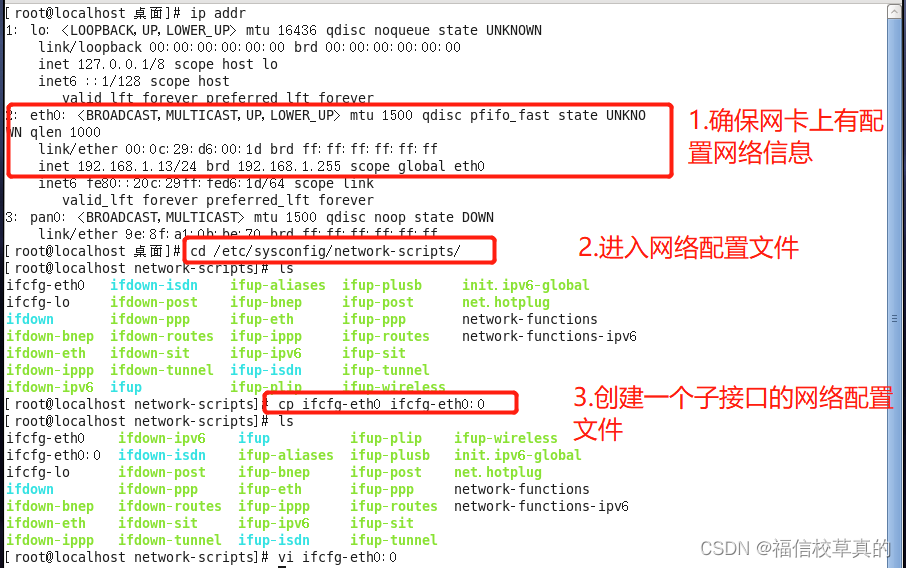
# 摘要
本文首先介绍了Linux系统管理的基础知识,随后详细阐述了RoseMirrorHA的理论基础及其关键功能。通过逐步讲解Linux环境下RoseMirrorHA的部署流程,包括系统要求、安装、配置和启动,本文为系统管理员提供了一套完整的实施指南。此外,本文还探讨了监控、日常管理和故障排查等关键维护任务,以及高可用场景下的实践和性能优化策略。最后,文章展望了Linux系统管理和R
用户体验:华为以用户为中心的设计思考方式与实践
# 摘要
用户体验在当今产品的设计和开发中占据核心地位,对产品成功有着决定性影响。本文首先探讨了用户体验的重要性及其基本理念,强调以用户为中心的设计流程,涵盖用户研究、设计原则、原型设计与用户测试。接着,通过华为的设计实践案例分析,揭示了用户研究的实施、用户体验的改进措施以及界面设计创新的重要性。此外,本文还探讨了在组织内部如何通过
【虚拟化技术】:smartRack资源利用效率提升秘籍
# 摘要
本文全面介绍了虚拟化技术,特别是smartRack平台在资源管理方面的关键特性和实施技巧。从基础的资源调度理论到存储和网络资源的优化,再到资源利用效率的实践技巧,本文系统阐述了如何在smartRack环境下实现高效的资源分配和管理。此外,本文还探讨了高级资源管理技巧,如资源隔离、服务质量(QoS)保障以及性能分析与瓶颈诊
【聚类算法选型指南】:K-means与ISODATA对比分析
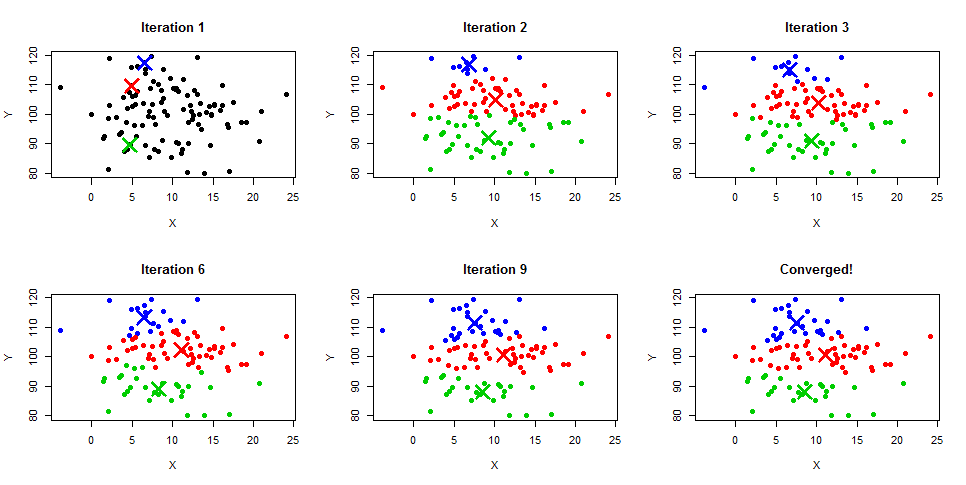
# 摘要
本文系统地介绍了聚类算法的基础知识,着重分析了K-means算法和ISODATA算法的原理、实现过程以及各自的优缺点。通过对两种算法的对比分析,本文详细探讨了它们在聚类效率、稳定性和适用场景方面的差异,并展示了它们在市场细分和图像分割中的实际应用案例。最后,本文展望了聚类算法的未来发展方向,包括高维数据聚类、与机器学习技术的结合以及在新兴领域的应用前景。
# 关
小米mini路由器序列号恢复:专家教你解决常见问题

# 摘要
本文对小米mini路由器序列号恢复问题进行了全面概述。首先介绍了小米mini路由器的硬件基础,包括CPU、内存、存储设备及网络接口,并探讨了固件的作用和与硬件的交互。随后,文章转向序列号恢复的理论基础,阐述了序列号的重要性及恢复过程中的可行途径。实践中,文章详细描述了通过Web界面和命令行工具进行序列号恢复的方法。此外,本文还涉及了小米mini路由器的常见问题解决,包括
深入探讨自然辩证法与软件工程的15种实践策略

# 摘要
自然辩证法作为哲学原理,为软件工程提供了深刻的洞见和指导原则。本文探讨了自然辩证法的基本原理及其在软件开发、设计、测试和管理中的应用。通过辩证法的视角,文章分析了对立统一规律、质量互变规律和否定之否定原则在软件生命周期、迭代优化及软件架构设计中的体现。此外,还讨论了如何将自然辩证法应用于面向对象设计、设计模式选择以及测试策略的制定。本文强调了自然辩证法在促进软
【自动化控制】:PRODAVE在系统中的关键角色分析

# 摘要
本文对自动化控制与PRODAVE进行了全面的介绍和分析,阐述了PRODAVE的基础理论、应用架构以及在自动化系统中的实现。文章首先概述了PRODAVE的通信协议和数据交换模型,随后深入探讨了其在生产线自动化、能源管理和质量控制中的具体应用。通过对智能工厂、智能交通系统和智慧楼宇等实际案例的分析,本文进一步揭示了PR
【VoIP中的ITU-T G.704应用】:语音传输最佳实践的深度剖析

# 摘要
本文系统地分析了ITU-T G.704协议及其在VoIP技术中的应用。文章首先概述了G.704协议的基础知识,重点阐述了其关键特性,如帧结构、时间槽、信道编码和信号传输。随后,探讨了G.704在保证语音质量方面的作用,包括误差检测控制机制及其对延迟和抖动的管理。此外,文章还分析了G.704
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )