并发爬虫的设计与实现:使用异步框架提高效率
发布时间: 2024-03-06 02:19:05 阅读量: 28 订阅数: 27 
# 1. 并发爬虫简介
## 1.1 爬虫技术概述
爬虫技术是一种通过程序自动化获取互联网信息的技术。它可以模拟人的行为,访问网页并提取所需的数据,常用于搜索引擎、数据分析和个性化推荐等领域。
## 1.2 并发爬虫的重要性
随着互联网规模的不断增大和网站架构的不断变化,单线程爬虫已经不能满足快速、高效地获取大量数据的需求。并发爬虫可以同时处理多个请求,提高爬取效率,缩短数据获取时间。
## 1.3 异步框架在爬虫中的应用
传统的爬虫常常使用同步IO模式,即每个请求都需等待响应返回后才能进行下一个请求,效率较低。而异步框架则可以利用非阻塞IO,实现并发处理多个请求,提高爬取效率。在爬虫中应用异步框架可以充分利用系统资源,并降低爬取过程中的等待时间。
# 2. 并发爬虫的基本原理
在这一章中,我们将深入探讨并发爬虫的基本原理,包括传统爬虫的工作流程、并发爬虫的工作原理以及异步框架在并发爬虫中的优势。
### 2.1 传统爬虫的工作流程
传统爬虫通常采用单线程顺序处理的方式,依次请求网页、解析内容,然后再请求下一个页面。这种方式效率较低,尤其在需爬取大量页面时,耗时较长。例如,以下是一个简单的传统爬虫工作流程示例:
```python
import requests
from bs4 import BeautifulSoup
def simple_crawler(url):
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# 解析页面内容并提取信息
print(soup.title.text)
else:
print("Failed to fetch page")
urls = ["https://example.com/page1", "https://example.com/page2", "https://example.com/page3"]
for url in urls:
simple_crawler(url)
```
### 2.2 并发爬虫的工作原理
与传统爬虫不同,进发爬虫利用多线程、多进程或异步编程等方式,在同一时间点处理多个页面的请求和解析,以提高爬取效率。通过并发的方式,爬虫可以同时请求多个页面,而不是等待一个页面的请求处理完毕后再处理下一个页面。以下是一个简单的并发爬虫示例:
```python
import asyncio
import aiohttp
from bs4 import BeautifulSoup
async def async_crawler(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
if response.status == 200:
html = await response.text()
soup = BeautifulSoup(html, "html.parser")
# 解析页面内容并提取信息
print(soup.title.text)
else:
print(f"Failed to fetch {url}")
urls = ["https://example.com/page1", "https://example.com/page2", "https://example.com/page3"]
loop = asyncio.get_event_loop()
tasks = [async_crawler(url) for url in urls]
loop.run_until_complete(asyncio.wait(tasks))
```
### 2.3 异步框架在并发爬虫中的优势
异步框架如`Asyncio`、`Twisted`等在并发爬虫中发挥重要作用。通过异步编程,爬虫可

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【驱动系统深度诊断】:发那科机器人故障解决与预防策略

参考资源链接:[发那科机器人SRVO-037(IMSTP)与PROF-017(从机断开)故障处理办法.docx](https://wenku.csdn.net/doc/6412b7a1be7fbd1778d4afd1?spm=1055.2635.3001.10343)
# 1. 发那科机器人的工作原理与架构
## 发那科机器人的历史与发展
发那科(
【GL USB3 Hub ISP工具负载均衡技巧】:分散处理,效率倍增
参考资源链接:[创惟科技GL3523 USB3 Hub ISP烧写工具用户指南](https://wenku.csdn.net/doc/42mhvnfqnn?spm=1055.2635.3001.10343)
# 1. GL USB3 Hub ISP工具概述
## 1.1 GL USB3 Hub ISP工具简介
GL USB3 Hub ISP工具是一款专为US
【东方通TongHttpServer虚拟主机配置秘籍】:多站点管理与隔离的高效方法

参考资源链接:[东方通 TongHttpServer:国产化替代nginx的利器](https://wenku.csdn.net/doc/6kvz6aiyc2?spm=1055.2635.3001.10343)
# 1. TongHttpServer虚拟主机概述
## 1.1 虚拟主机概念介绍
在现代IT架构中,
SystemVerilog习题专家篇:掌握验证关键概念的系统化路径

参考资源链接:[SystemVerilog验证:绿皮书第三版课后习题解答](https://wenku.csdn.net/doc/644b7ea5ea0840391e5597b3?spm=1055.2635.3001.10343)
# 1. SystemVerilog基础知识回顾
## 1.1 SystemVerilog简介
SystemVerilog是一种强大的硬件描述语言(HDL),它在传统的Ver
【PN532开发环境搭建全攻略】:软件工具与库配置,轻松上手

参考资源链接:[PN532固件V1.6详细教程:集成NFC通信模块指南](https://wenku.csdn.net/doc/6412b4cabe7fbd1778d40d3d?spm=1055.2635.3001.10343)
# 1. PN532开发环境概览
## 1.1 开发环境的组
【视频接口在广播领域的应用】:BT656与BT1120在电视直播中的比较分析
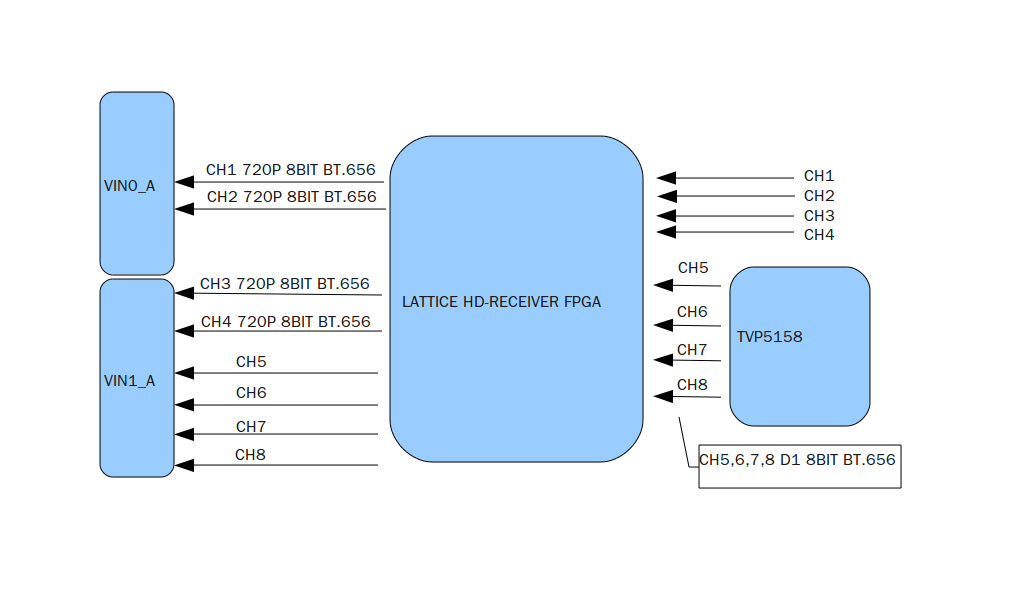
参考资源链接:[视频接口BT656和BT1120的区别](https://wenku.csdn.net/doc/646d7b21d12cbe7ec3ea32af?spm=1055.2635.3001.10343)
# 1. 视频接口技术概述
视频接口技术是连接视频设备、实现视频信
降低ADF4002干扰的电磁兼容设计:策略与案例研究

参考资源链接:[ADF4002鉴相器芯片:PLL应用与中文手册详解](https://wenku.csdn.net/doc/124z016hpa?spm=1055.2635.3001.10343)
# 1. 电磁兼容性概述及重要性
在现代电子系统中,电磁兼容性(EMC)是一个至关重要的考虑因素。它涉
台达PLC编程技巧大揭秘:效率飞升与规范实践
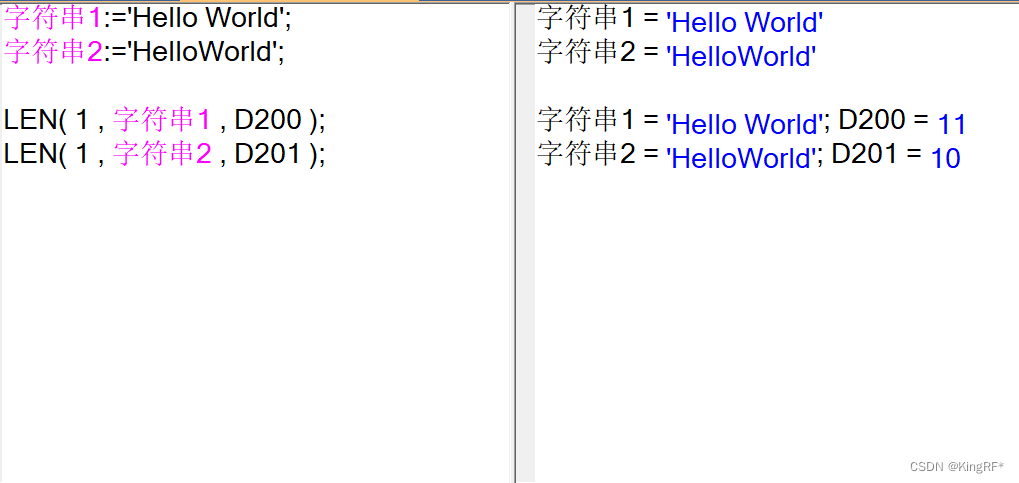
参考资源链接:[台达PLC ST编程语言详解:从入门到精通](https://wenku.csdn.net/doc/6401ad1acce7214c316ee4d4?spm=1055.2635.3001.10343)
# 1. 台达PLC编程基础
## 1.1 台达PLC简介
台达PLC(Programmable Logic Controller,可编程逻辑控制器)是工业自动化领域常用的一类控制设备。台达PL
【GBFF文件高级分析】:揭秘编码规则与数据压缩机制

参考资源链接:[解读GBFF:GenBank数据的核心指南](https://wenku.csdn.net/doc/3cym1yyhqv?spm=1055.2635.3001.10343)
# 1. GBFF文件格式概述
## 文件格式的定义与重要性
GBFF(General Binary File Format)文件格式是一种广泛应用于软件开发和数据分析的二进
【物联网项目中的DHT11】:构建连接智能世界的实践策略

参考资源链接:[DHT11:高精度数字温湿度传感器,广泛应用于各种严苛环境](https://wenku.csdn.net/doc/645f26ae543f8444888a9f2b?spm=1055.2635.3001.10343)
# 1. DHT11传感器概述与项目导入
## 1.1 DHT11传感器简介
DHT11是一款含有已校准数字信号输出的温湿度复合传感
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )