KISSsoft数据管理艺术:高效组织和检索设计数据的秘诀
发布时间: 2024-12-02 21:33:33 阅读量: 16 订阅数: 26 
参考资源链接:[KISSsoft 2013全实例中文教程详解:齿轮计算与应用](https://wenku.csdn.net/doc/6x83e0misy?spm=1055.2635.3001.10343)
# 1. KISSsoft数据管理概述
KISSsoft是一款专业的齿轮计算和设计软件,广泛应用于机械工程领域。在这一章节中,我们将对KISSsoft数据管理的核心理念和重要性进行概述,同时也会介绍一些基本的操作流程和使用技巧,帮助用户快速上手。
在数据管理领域,"KISS"原则(Keep It Simple, Stupid)是至关重要的。KISS原则强调的是将复杂问题简化,使之更容易理解和操作。在KISSsoft中,这一原则得到了充分的体现。通过简洁直观的用户界面和强大的数据处理能力,KISSsoft大大降低了用户在进行齿轮设计和计算时的难度。
为了充分利用KISSsoft的强大功能,用户需要熟悉其数据管理模块。该模块负责数据的导入、存储、检索、分析和导出。理解并熟练掌握这些功能,将有助于用户提高工作效率,减少重复工作,从而在激烈的行业竞争中占据优势。在接下来的章节中,我们将深入探讨数据管理的各个方面,包括数据组织策略、数据检索与分析的优化以及实战应用。让我们开始吧!
# 2. 高效的数据组织策略
### 2.1 设计数据的分类与命名
#### 2.1.1 设计数据分类的重要性
在大型IT系统中,数据分类是管理和检索数据的基础。良好的分类策略能够降低数据冗余,提高数据检索效率,并且对于确保数据安全性和符合法规遵从性也至关重要。数据分类可依据业务逻辑、数据用途或数据敏感度等多种维度来进行。例如,财务数据、客户信息和个人隐私数据应该被严格分类管理。
#### 2.1.2 合理命名规则的制定
数据命名规则是数据分类的自然延伸。良好的命名规则有助于快速识别数据集的用途和类型。命名应该简洁明了,避免使用可能引起歧义的缩写或专有名词。例如,命名中包含日期或版本号可以帮助区分不同时间点的数据副本,确保数据追踪的连贯性。
### 2.2 数据存储结构设计
#### 2.2.1 选择合适的数据存储方案
数据存储结构的设计需要综合考虑数据的规模、复杂性以及访问频率等因素。常见的存储方案包括关系型数据库、NoSQL数据库和分布式文件系统。例如,对于需要复杂查询和事务支持的场景,关系型数据库如MySQL或PostgreSQL可能是更好的选择。而对于高并发读写和大数据分析的场景,NoSQL数据库如MongoDB或Cassandra则更加适合。
#### 2.2.2 数据库索引与查询优化
数据库索引对于提高查询效率至关重要。有效的索引可以将查询时间从几秒减少到几毫秒。在设计索引时需要考虑查询模式和数据分布,索引不仅要涵盖经常查询的字段,也要避免过度索引带来的性能负担。此外,查询优化涉及对查询语句的调优,如使用合适的连接类型和过滤条件,以最小的计算成本获取结果。
### 2.3 数据版本控制与同步
#### 2.3.1 版本控制的基本原理
版本控制是保证数据一致性和历史追踪的关键技术。在数据管理中,版本控制类似于软件开发中的Git,需要实现对数据的变更记录和历史回滚。每个版本都应包含创建时间、变更摘要和变更人等信息。版本控制还可以帮助团队成员协调工作,避免并行工作导致的数据冲突。
#### 2.3.2 实现数据同步的策略与工具
数据同步是指将数据从一个位置复制到另一个位置,以确保数据的一致性和可恢复性。实现数据同步的策略包括定期同步、实时同步和差异同步等。相应的工具比如rsync、BitTorrent Sync或专门的数据库同步软件。在选择同步工具时,需要考虑网络带宽、同步频率和冲突解决机制等因素。
```mermaid
graph LR
A[开始] --> B[设计数据分类]
B --> C[制定命名规则]
C --> D[选择存储方案]
D --> E[数据库索引设计]
E --> F[查询优化]
F --> G[版本控制策略]
G --> H[数据同步工具选择]
H --> I[结束]
```
```sql
-- 一个示例SQL语句用于创建索引
CREATE INDEX idx_column_name
ON table_name (column_name);
```
通过以上章节的分析,我们可以看到数据管理不仅仅是存储和检索信息的简单过程,而是需要经过深思熟虑的策略设计和工具选择。从数据分类到命名规则,从存储方案到版本控制,每一项决策都对数据的可维护性、可访问性和安全性产生深远的影响。随着数据量的激增和业务需求的多样化,掌握这些高效的数据组织策略,对于任何IT专业人士而言都是必不可少的技能。
# 3. 数据检索与分析的优化
在当今的数据驱动时代,数据检索与分析是至关重要的环节,它们不仅影响着决策的速度和质量,还直接关联到整个企业的运营效率。本章节将深入探讨如何优化数据检索和分析,以提升数据的价值实现和业务洞察力。
## 3.1 高级检索技术
### 3.1.1 检索算法的选择与应用
现代数据检索需要应对大数据量和复杂查询的需求,因此,选择合适且高效的检索算法至关重要。全文检索是处理大量文本数据的常用方法,其核心是通过倒排索引来实现快速的关键词匹配和检索。
**示例代码:**
```python
import whoosh.index as index
from whoosh.fields import *
from whoosh.qparser import QueryParser
# 定义文档结构
schema = Schema(title=TEXT(stored=True), content=TEXT)
# 创建索引
ix = index.create_in("indexdir", schema)
# 添加文档到索引
writer = ix.writer()
writer.add_document(title=u"Document 1", content=u"This is the content of document 1")
writer.commit()
# 搜索文档
with ix.searcher() as searcher:
query = QueryParser("content", ix.schema).parse("content:document")
results = searcher.search(query)
for result in results:
print(result['title'])
```
在此代码块中,我们创建了一个简单的全文检索系统。首先定义了文档的结构,创建了索引目录,然后添加了示例文档,并演示了如何进行基于内容的查询。这种检索方法大

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 KISSsoft 全实例中文教程专栏,您的齿轮设计终极指南。本专栏汇集了全面的文章,涵盖从入门到精通的各个方面,包括:
* 高级技巧和案例研究,揭秘 KISSsoft 的强大功能。
* 参数秘籍和强度分析教程,为您提供精确控制和评估齿轮设计所需的知识。
* 材料科学和设计流程优化,帮助您选择最佳材料并打造高效的工作流程。
* 与 CAD 的无缝集成和齿轮加工知识库,实现设计到制造的顺畅转换。
* 啮合精度提升课程和模块化设计威力,解决复杂设计难题并简化流程。
* 风电、汽车和工业机器人设计教程,提供专业视角和实践技巧。
* 参数化设计革命和专业认证指南,提升您的技能并成为认证工程师。
* 与 CAE 工具的整合术,实现跨平台设计协同。
通过本专栏,您将掌握 KISSsoft 的方方面面,成为一名齿轮设计大师。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
三菱NZ81GP21-SX型接口板安装与配置:CC-Link IE技术基础完全攻略

# 摘要
CC-Link IE技术作为一种工业以太网解决方案,已被广泛应用于自动化控制领域。本文首先概述了CC-Link IE技术的基本概念及其重要性。随后,重点介绍了三菱NZ81GP21-SX型接口板的硬件结构及功能,并详细阐述了其安装步骤,包括物理安装和固件更新。接着,本文深入探讨了CC-Link I
【Pinpoint性能监控深度解析】:架构原理、数据存储及故障诊断全攻略
# 摘要
Pinpoint性能监控系统作为一款分布式服务追踪工具,通过其独特的架构设计与数据流处理机制,在性能监控领域展现出了卓越的性能。本文首先概述了Pinpoint的基本概念及其性能监控的应用场景。随后深入探讨了Pinpoint的架构原理,包括各组件的工作机制、数据收集与传输流程以及分布式追踪系统的内部原理。第三章分析了Pinpoint在数据存储与管理方面的技术选型、存储模型优化及数据保留策略。在第四章中,本文详细描述了Pinpoint的故障诊断技术,包括故障分类、实时故障检测及诊断实例。第五章探讨了Pinpoint的高级应用与优化策略,以及其未来发展趋势。最后一章通过多个实践案例,分享了
软件工程中的FMEA实战:从理论到实践的完整攻略
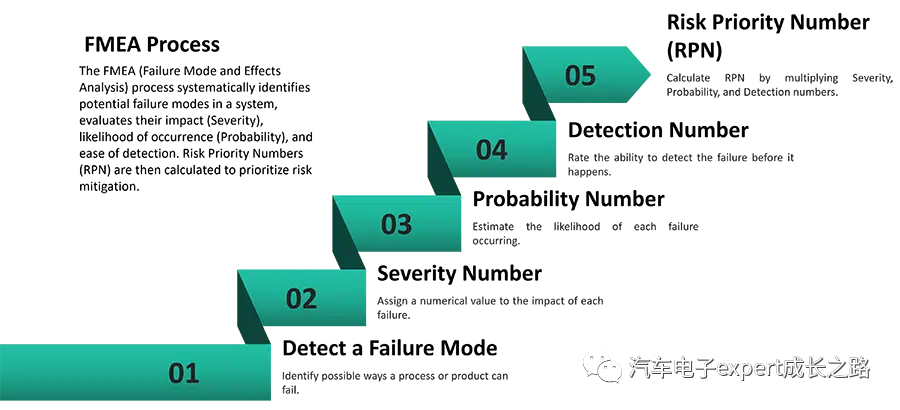
# 摘要
FMEA(故障模式与影响分析)是软件工程中用于提高产品可靠性和安全性的重要质量工具。本文详细解析了FMEA的基本概念、理论基础和方法论,并探讨了其在软件工程中的分类与应用。文章进一步阐述了FMEA实践应用的流程,包括准备工作、执行分析和报告编写等关键步骤。同时,本文还提供了FMEA在敏捷开发环境中的应用技巧,并通过案例研究分享了成功的行
CITICs_KC接口数据处理:从JSON到XML的高效转换策略
![CITICs_KC股票交易接口[1]](https://bytwork.com/sites/default/files/styles/webp_dummy/public/2021-07/%D0%A7%D1%82%D0%BE%20%D1%82%D0%B0%D0%BA%D0%BE%D0%B5%20%D0%9B%D0%B8%D0%BC%D0%B8%D1%82%D0%BD%D1%8B%D0%B9%20%D0%BE%D1%80%D0%B4%D0%B5%D1%80.jpg?itok=nu0IUp1C)
# 摘要
随着信息技术的发展,CITICs_KC接口在数据处理中的重要性日益凸显。本文首先概述了C
光学信号处理揭秘:Goodman版理论与实践,光学成像系统深入探讨

# 摘要
本文系统地介绍了光学信号处理的基础理论、Goodman理论及其深入解析,并探讨了光学成像系统的实践应用。从光学信号处理的基本概念到成像系统设计原理,再到光学信号处理技术的最新进展和未来方向,本文对光学技术领域的核心内容进行了全面的梳理和分析。特别是对Goodman理论在光学成像中的应用、数字信号处理技术、光学计算成像技术进行了深入探讨。同时,本文展望了量子光学信号处理、人工智能在光
队列的C语言实现:从基础到循环队列的进阶应用
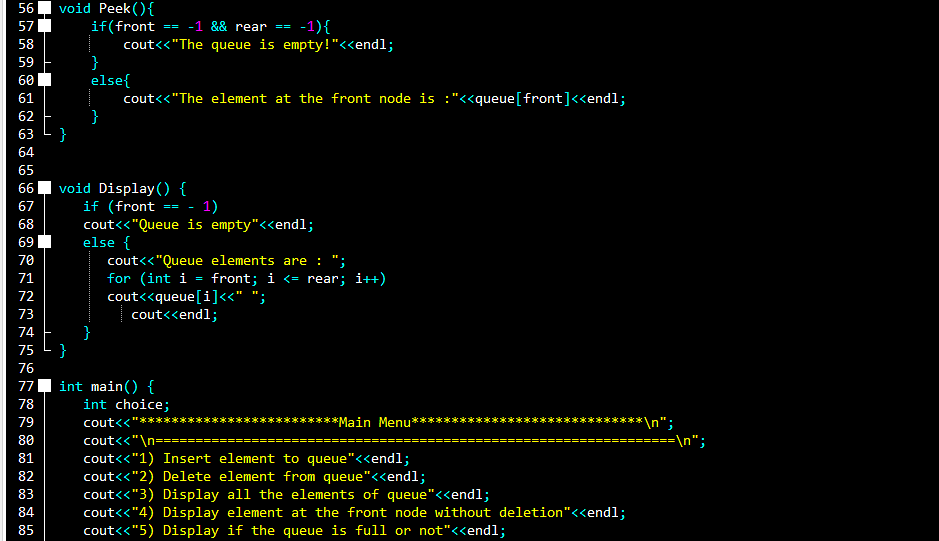
# 摘要
本论文旨在系统地介绍队列这一基础数据结构,并通过C语言具体实现线性队列和循环队列。首先,本文详细解释了队列的概念、特点及其在数据结构中的地位。随后,深入探讨了线性队列和循环队列的实现细节,包括顺序存储结构设计、入队与出队操作,以及针对常见问题的解决方案。进一步,本文探讨了队列在
【CAXA图层管理:设计组织的艺术】:图层管理的10大技巧让你的设计井井有条
# 摘要
图层管理是确保设计组织中信息清晰、高效协同的关键技术。本文首先介绍了图层管理的基本概念及其在设计组织中的重要性,随后详细探讨了图层的创建、命名、属性设置以及管理的理论基础。文章进一步深入到实践技巧,包括图层结构的组织、视觉管理和修改优化,以及CAXA环境中图层与视图的交互和自动化管理。此外,还分析了图层管理中常见的疑难问题及其解决策略,并对图层管理技术的未来发展趋势进行了展望,提出了一系列面向未来的管理策略。
# 关键字
图层管理;CAXA;属性设置;实践技巧;自动化;协同工作;未来趋势
参考资源链接:[CAXA电子图板2009教程:绘制箭头详解](https://wenku.c
NET.VB_TCPIP协议栈深度解析:从入门到精通的10大必学技巧

# 摘要
本文全面探讨了TCP/IP协议栈的基础理论、实战技巧以及高级应用,旨在为网络工程师和技术人员提供深入理解和高效应用TCP/IP协议的指南。文章首先介绍了TCP/IP协议栈的基本概念和网络通信的基础理论,包括数据包的封装与解封装、传输层协议TCP和UDP的原理,以及网络层和网络接口层的关键功能。接着,通过实战技巧章节,探讨了在特定编程环境下如VB进行
MCP41010数字电位计初始化与配置:从零到英雄
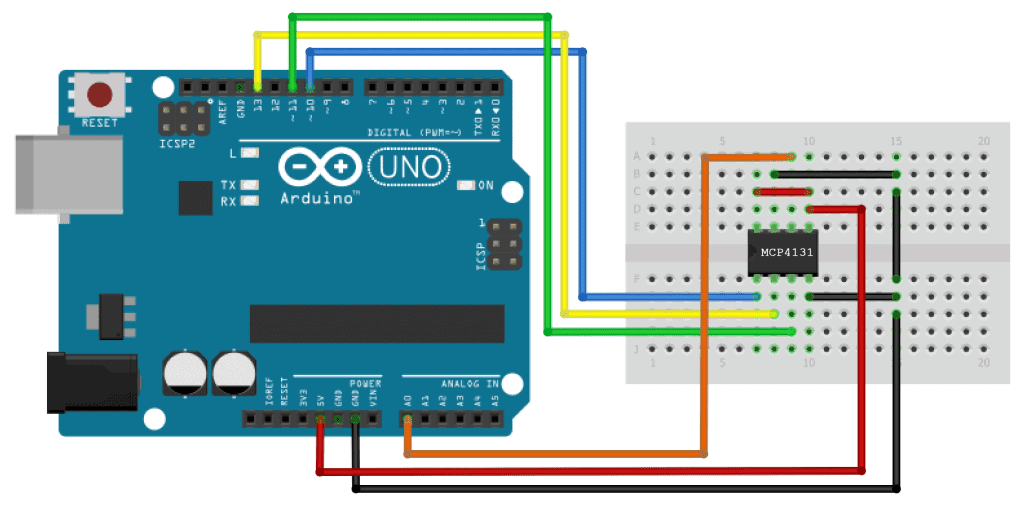
# 摘要
本文全面介绍MCP41010数字电位计的功能、初始化、配置以及高级编程技巧。通过深入探讨其工作原理、硬件接口、性能优化以及故障诊断方法,本文为读者提供了一个实用的技术指导。案例研究详细分析了MCP41010在电路调节、用户交互和系统控制中的应用,以
【Intouch界面初探】:5分钟掌握Intouch建模模块入门精髓

# 摘要
本文系统性地介绍了Intouch界面的基本操作、建模模块的核心概念、实践应用,以及高级建模技术。首先,文章概述了Intouch界面的简介与基础设置,为读者提供了界面操作的起点。随后,深入分析了建模模块的关键组成,包括数据驱动、对象管理、界面布局和图形对象操作。在实践应用部分,文章详细讨论了数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )