爬虫法律与道德:合法合规地使用网络爬虫
发布时间: 2024-12-06 19:23:52 阅读量: 26 订阅数: 15 

微信小程序源码云匹面粉直供微信小程序-微信端-毕业设计.zip

# 1. 网络爬虫基础概念与应用
网络爬虫是互联网数据收集的重要工具,它通过自动化的方式从网站上抓取信息。基础概念包括了解爬虫的定义、类型以及在行业中的应用范围。网络爬虫可以分为通用型爬虫和聚焦型爬虫。通用型爬虫尝试抓取所有网站数据,而聚焦型爬虫专注于特定主题或网站内容。
应用方面,爬虫技术被广泛运用于搜索引擎索引、市场数据分析、新闻聚合、学术研究等领域。它可以帮助企业自动化收集市场情报,提高工作效率,是数字营销和数据分析不可或缺的一部分。
接下来的章节将深入探讨网络爬虫的技术原理与实践,以及它们在法律、道德与伦理问题上的挑战和解决策略。我们将逐步揭开网络爬虫的神秘面纱,向读者展示这一技术在现代社会中的实际作用和未来发展的可能。
# 2. 网络爬虫的技术原理与实践
## 2.1 网络爬虫的工作流程
网络爬虫的工作流程是其技术实现的核心部分,它包括网页请求与响应处理、数据提取与解析技术以及爬虫的异常处理机制。
### 2.1.1 网页请求与响应处理
网络爬虫的第一步是发送HTTP请求到目标网站并接收响应。Python中的requests库是处理此类任务的常用工具。下面是一个简单的代码示例:
```python
import requests
from bs4 import BeautifulSoup
# 发送GET请求
response = requests.get('http://example.com')
# 检查请求是否成功
if response.status_code == 200:
# 使用BeautifulSoup解析HTML内容
soup = BeautifulSoup(response.text, 'html.parser')
# 提取网页信息
# ...
else:
print('请求失败,状态码:', response.status_code)
```
### 2.1.2 数据提取与解析技术
提取数据是爬虫工作的重点。数据提取通常使用HTML解析库如BeautifulSoup,配合CSS选择器或XPath技术。下面的代码展示如何使用BeautifulSoup提取网页中的标题:
```python
from bs4 import BeautifulSoup
# 假设我们已经有了HTTP响应response
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text # 使用find方法定位到<title>标签并提取其文本内容
print(title)
```
### 2.1.3 爬虫的异常处理机制
爬虫在工作过程中会遇到各种异常,比如网络请求失败、数据解析错误等。异常处理机制能够确保爬虫程序的健壮性和稳定性。示例如下:
```python
try:
# 尝试执行可能抛出异常的代码
response = requests.get('http://example.com')
response.raise_for_status() # 如果状态码不是200,将抛出HTTPError异常
except requests.HTTPError as http_err:
print(f'HTTP error occurred: {http_err}')
except Exception as err:
print(f'An error occurred: {err}')
else:
# 如果没有异常发生,则执行此段代码
# 处理正常情况下的响应数据
pass
```
## 2.2 网络爬虫的高级功能实现
高级功能实现是网络爬虫技术中的高级部分,包括应对反爬机制、分布式爬虫的架构设计以及爬虫的存储方案选择。
### 2.2.1 反爬机制的应对策略
网站常见的反爬措施有IP封禁、User-Agent限制、动态加载数据等。爬虫可以通过设置代理、使用随机的User-Agent、模拟浏览器行为等方式来应对反爬机制。
```python
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
# 使用session对象保持连接状态
session = requests.Session()
session.proxies.update(proxies)
try:
response = session.get('http://example.com', headers={'User-Agent': 'Mozilla/5.0'})
except requests.exceptions.ProxyError as e:
print("Proxy error:", e)
```
### 2.2.2 分布式爬虫的架构设计
随着爬取需求的增长,分布式爬虫成为了一种趋势。分布式爬虫涉及到多个爬虫节点的协同工作,一般包括任务调度、任务分发、数据存储和数据分析等模块。系统架构图如下所示:
```mermaid
graph TD
A[调度服务器] -->|任务分发| B(爬虫节点1)
A -->|任务分发| C(爬虫节点2)
A -->|任务分发| D(爬虫节点3)
B -->|数据存储| E(数据库)
C -->|数据存储| E
D -->|数据存储| E
E -->|数据分析| F(数据处理中心)
```
### 2.2.3 爬虫的存储方案选择
根据爬取数据的量级和使用场景,爬虫的存储方案有多种选择。常见的存储方案包括关系型数据库、NoSQL数据库和分布式文件系统。表格比较了不同存储方案的优势和局限性:
| 存储方案 | 优势 | 局限性 |
| :--: | :-- | :--: |
| 关系型数据库 | 成熟稳定,支持复杂的查询和事务 | 可能会遇到扩展性瓶颈 |
| NoSQL数据库 | 高性能,易扩展,灵活的数据模型 | 通常不支持复杂查询,一致性保障较弱 |
| 分布式文件系统 | 高容错性,适用于存储非结构化数据 | 查询效率相对较低,需要额外的数据处理 |
## 2.3 网络爬虫的性能优化
性能优化是提升爬虫效率的关键,包括爬取速度与效率的提升、资源消耗与负载均衡以及爬虫的并发与分布式控制。
### 2.3.1 爬取速度与效率提升
通过设置合理的延迟时间、使用缓存机制、减少重复下载相同的资源等方式可以提升爬虫的效率。代码示例中使用了`time.sleep()`实现延迟:
```python
import time
# 假设这是一个爬虫的循环体
for url in url_list:
response = requests.get(url)
# 处理响应内容
...
# 设置合理的时间间隔
time.sleep(1)
```
### 2.3.2 资源消耗与负载均衡
通过限制爬虫同时运行的线程数、使用异步IO、负载均衡算法等方式可以有效减少资源消耗。这里介绍

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以“Python网络爬虫的实用技巧”为主题,深入探讨网络爬虫的各个方面。从入门指南到实战演练,从数据清洗到异常处理,从IP代理池构建到分布式部署,专栏全面覆盖了网络爬虫开发的各个环节。此外,还涉及爬虫法律与道德、爬虫与深度学习、爬虫与验证码识别等前沿话题。通过阅读本专栏,读者将掌握Python网络爬虫的实用技巧,并了解如何设计和构建高效、稳定、合法的网络爬虫系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
平移向量高手速成:三维空间位置调整的5个技巧
参考资源链接:[原理详解_三点解算两个坐标系之间的旋转矩阵和平移向量](https://wenku.csdn.net/doc/6412b723be7fbd1778d49388?spm=1055.2635.3001.10343)
# 1. 三维空间和平移向量基础
## 1.1 理解三维空间
在三维空间中,我们可以通过三个坐标轴(x, y, z
【计价软件操作进阶】:专家级别技能提升指南

参考资源链接:[新点计价软件操作指南:量价费与子目工程量调整](https://wenku.csdn.net/doc/61bffjnss9?spm=1055.2635.3001.10343)
# 1. 计价软件操作基础知识
## 1.1 计价软件的定义与功能
计价软件是为工程项目中预算编制、成本控制、报价和决算所设计的专用工具。它集成了工程量计算、材料成本估算、人工费用计算等多种功能,可以大幅提高工作效率,减少人为错误
【Prime Time深度剖析】:全面解读功能模块,提升工作效率

参考资源链接:[Synopsys Prime Time中文教程:静态时序分析与形式验证详解](https://wenku.csdn.net/doc/6492b5a89aecc961cb2885db?spm=1055.2635.3001.10343)
# 1. 功能模块概述与重要性
## 功能模块的定义与目的
在软件
FANUC数控编程:专家揭秘提升效率的10大实战秘诀

参考资源链接:[FANUC机器人操作与安全手册:编程与维修指南](https://wenku.csdn.net/doc/645ef067543f844488899ce4?spm=1055.2635.3001.10343)
# 1. FANUC数控编程基础与应用
## 1.1 数控编程的简介
数控编程是指导FANUC数控系统如何操作机器进行加工作业的指令语言。这种语言使机械操作变
Kettle数据同步终极指南:掌握全量数据迁移的15个绝技
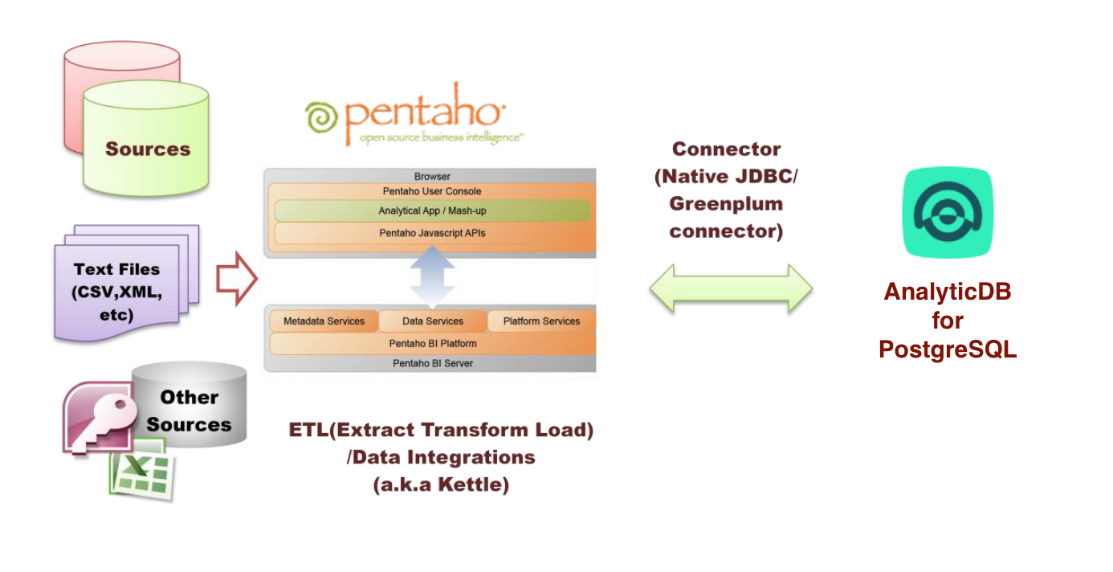
参考资源链接:[Kettle全量多表数据同步教程](https://wenku.csdn.net/doc/646eb837d12cbe7ec3f092fe?spm=1055.2635.3001.10343)
# 1. Kettle数据同步概述
## 1.1 Kettle的概念和重要性
Kettle,也被称作Pentaho Data Integration (PDI),是一个开源的ET
SMC ZK2-ZSEA-A故障诊断:快速解决常见问题指南
参考资源链接:[SMC ZK2-ZSEA-A 数字式压力开关设置与功能详解](https://wenku.csdn.net/doc/4mh9zj55a8?spm=1055.2635.3001.10343)
# 1. SMC ZK2-ZSEA-A故障诊断概述
SMC ZK2-ZSEA-A作为工业自动化领域中的关键设备,在各种复杂的生产环境中扮演着至关重要的角色。本章旨在概述故障诊断的重要性和必要性,为读者提供一个关于SMC ZK2-Z
【CST仿真边界设置秘籍】:详解边界条件设置,案例与最佳实践

参考资源链接:[CST微波工作室初学者教程:电磁仿真轻松入门](https://wenku.csdn.net/doc/6401ad40cce7214c316eed7a?spm=1055.2635.3001.10343)
# 1. CST仿真软件与边界条件概述
在现代电子工程和电磁领域设计与研究中,CST(Computer Simulation Technology)仿真软件已经成为一个不可或缺的工具,它在
如何正确理解和应用SAE J2602-1标准:深度翻译与实践指南

参考资源链接:[SAE J2602-1标准解析:汽车串行通信网络规范](https://wenku.csdn.net/doc/646ec24a543f844488dbd357?spm=1055.2635.3001.10343)
# 1. SAE J2602-1标准概述
SAE J2602-1标准,全称《车辆数据通信网络 - CAN 高级诊断协议》,是由美国汽车工程师学会(SAE)制定的一项技术标准。它旨在定义一种标准的诊断协议,以适用于具备CAN
嵌入式开发流程革新:Keil与SourceInsight协作的6大优势
参考资源链接:[Keil与SourceInsight集成调试配置教程](https://wenku.csdn.net/doc/6488
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )