Node.js中的数据库操作
发布时间: 2023-12-08 14:13:32 阅读量: 36 订阅数: 39 

数据库的操作
一、介绍
1.1 什么是Node.js和数据库
Node.js是一个基于Chrome V8引擎的JavaScript运行环境,具有异步、轻量级和高性能的特点。它广泛应用于服务器端的开发,可以处理高并发的请求。
数据库是用于存储和管理数据的软件应用程序。在Web应用程序中,数据库起着至关重要的作用,可以持久化存储数据并提供高效的数据访问。
1.2 Node.js的特点和优势
- 异步非阻塞:Node.js采用异步非阻塞的IO模型,能够处理大量并发请求,提高系统的吞吐量和响应速度。
- 单线程:Node.js利用单线程的优势,避免了传统多线程模型中线程切换的开销,使得服务器可以支持更多的并发连接。
- JavaScript语言:Node.js使用JavaScript语言编写,开发者可以利用JavaScript的灵活性和高效性进行开发。
- 生态系统丰富:Node.js拥有庞大的NPM包管理器和开源社区,提供了大量的模块和库,可以快速构建复杂的应用程序。
1.3 数据库在Node.js中的重要性和作用
数据库在Node.js中起着至关重要的作用,主要体现在以下几个方面:
- 数据持久化存储:数据库作为数据的存储介质,可以将数据持久化保存,保证数据在系统重启后不会被丢失。
- 高效的数据访问:数据库提供了高效的数据检索和操作方法,可以通过SQL语句或其他查询方式获取所需的数据。
- 并发处理支持:数据库具备处理并发访问的能力,可以同时处理多个请求,保证系统的稳定性和性能。
- 数据安全和权限管理:数据库可以对数据进行加密、备份和访问权限控制,保证数据的安全性和可靠性。
二、连接数据库
2.1 安装和配置数据库驱动
在Node.js中连接数据库需要使用相应的数据库驱动,如MySQL、MongoDB等。首先需要安装对应的数据库驱动,可以通过NPM包管理器进行安装。
以MySQL为例,可以使用以下命令进行安装:
```
npm install mysql
```
2.2 建立数据库连接
在Node.js中连接数据库需要使用数据库驱动的提供的API,通过数据库驱动提供的连接函数进行连接。以MySQL为例,可以使用以下代码建立数据库连接:
```javascript
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: '123456',
database: 'test'
});
connection.connect((err) => {
if (err) {
console.error('error connecting: ' + err.stack);
return;
}
console.log('connected as id ' + connection.threadId);
});
```
2.3 处理连接错误和异常
在建立数据库连接的过程中,可能会发生连接错误或异常。为了避免程序崩溃,需要处理这些错误和异常。
```javascript
connection.connect((err) => {
if (err) {
console.error('error connecting: ' + err.stack);
return;
}
console.log('connected as id ' + connection.threadId);
});
connection.on('error', (err) => {
console.error('database error: ' + err.stack);
});
```
### 章节三:执行基本操作
在Node.js中,对数据库的操作通常包括创建和插入数据、查询和读取数据、更新和修改数据以及删除和清除数据。在这一章节中,我们将详细介绍如何在Node.js中执行这些基本的数据库操作。
#### 3.1 创建和插入数据
在Node.js中,可以使用数据库驱动提供的API来创建表格结构,并将数据插入到数据库中。下面是一个示例,演示了如何使用Node.js连接到数据库并插入数据:
```javascript
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'password',
database: 'mydb'
});
connection.connect((err) => {
if (err) throw err;
console.log('Connected to the database');
const sql = 'INSERT INTO customers (name, email) VALUES ("John Doe", "john@example.com")';
connection.query(sql, (err, result) => {
if (err) throw err;
console.log('1 record inserted');
});
});
```
**代码说明:**
- 首先,我们使用`require`语句引入`mysql`模块。
- 然后,我们创建了与数据库的连接,并执行插入操作。
- 在`INSERT`语句中,我们指定了表格名称以及要插入的数据。
- 最后,使用`connection.query`方法执行SQL语句,并处理插入操作的结果。
#### 3.2 查询和读取数据
在Node.js中,可以使用数据库驱动提供的API来执行查询操作,并读取数据库中的数据。下面是一个示例,演示了如何使用Node.js连接到数据库并查询数据:
```javascript
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'password',
database: 'mydb'
});
connection.connect((err) => {
if (err) throw err;
console.log('Connected to the database');
connection.query('SELECT * FROM customers', (err, result, fields) => {
if (err) throw err;
console.log(result);
});
});
```
**代码说明:**
- 首先,我们使用`require`语句引入`mysql`模块。
- 然后,我们创建了与数据库的连接,并执行查询操作。
- 在`SELECT`语句中,我们指定了要查询的字段和表格名称。
- 最后,使用`connection.query`方法执行SQL语句,并处理查询操作的结果。
#### 3.3 更新和修改数据
在Node.js中,可以使用数据库驱动提供的API来执行更新操作,并修改数据库中的数据。下面是一个示例,演示了如何使用Node.js连接到数据库并更新数据:
```javascript
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'password',
database: 'mydb'
});
connection.connect((err) => {
if (err) throw err;
console.log('Connected to the database');
const sql = 'UPDATE customers SET name = "Mary Smith" WHERE name = "John Doe"';
connection.query(sql, (err, result) => {
if (err) throw err;
console.log(result.affectedRows + ' record(s) updated');
});
});
```
**代码说明:**
- 首先,我们使用`require`语句引入`mysql`模块。
- 然后,我们创建了与数据库的连接,并执行更新操作。
- 在`UPDATE`语句中,我们指定了要更新的表格以及更新的条件。
- 最后,使用`connection.query`方法执行SQL语句,并处理更新操作的结果。
#### 3.4 删除和清除数据
在Node.js中,可以使用数据库驱动提供的API来执行删除操作,并清除数据库中的数据。下面是一个示例,演示了如何使用Node.js连接到数据库并删除数据:
```javascript
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'password',
database: 'mydb'
});
connection.connect((err) => {
if (err) throw err;
console.log('Connected to the database');
const sql = 'DELETE FROM customers WHERE name = "Mary Smith"';
connection.query(sql, (err, result) => {
if (err) throw err;
console.log(result.affectedRows + ' record(s) deleted');
});
});
```
**代码说明:**
- 首先,我们使用`require`语句引入`mysql`模块。
- 然后,我们创建了与数据库的连接,并执行删除操作。
- 在`DELETE`语句中,我们指定了要删除的表格以及删除的条件。
- 最后,使用`connection.query`方法执行SQL语句,并处理删除操作的结果。
### 章节四:处理事务
在数据库操作中,事务是一组作为单个逻辑单元执行的SQL操作,这些操作要么全部成功,要么全部失败回滚。在Node.js中,处理事务可以确保数据库操作的一致性和完整性,特别是在涉及多个表的复杂操作时非常重要。
#### 4.1 事务的概念和作用
**事务**是指数据库管理系统执行的一组操作,这些操作被视为一个逻辑单元,要么全部成功,要么全部失败。事务具有ACID属性,即原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。事务能够确保数据库从一个一致的状态转移到另一个一致的状态,同时保护数据的完整性。
#### 4.2 Node.js中的事务管理库和工具
在Node.js中,可以使用一些第三方库来管理数据库事务,例如`sequelize`、`knex.js`等。这些库提供了简单而强大的方式来执行和管理数据库事务,从而简化了代码编写和维护的复杂性。
#### 4.3 实现数据库事务操作的步骤和技巧
实现数据库事务操作的步骤包括:
1. **开启事务**:通过数据库连接对象的方法来开启一个新的事务。
2. **执行事务操作**:在事务中执行需要进行的数据库操作,包括插入、更新、删除等。
3. **提交或回滚**:根据操作的执行结果,决定是提交事务(提交到数据库保存)还是回滚事务(撤销之前的操作)。
在实际编码中,可以通过try-catch块来捕获错误,并在发生异常时回滚事务,以确保数据的一致性和完整性。
### 章节五:安全性和性能优化
在Node.js中进行数据库操作时,除了实现基本的增删改查功能外,还需要考虑数据库操作的安全性和性能优化。本章将介绍如何管理数据库访问权限、使用数据库连接池以及优化性能的相关技巧和方法。
#### 5.1 数据库访问权限的管理
在实际应用中,为了保障数据的安全,我们需要对数据库的访问权限进行合理的管理和设置。以下是一些常见的数据库访问权限管理方法:
- 创建专门的数据库访问账号,并限制其对数据库的访问权限,例如只允许进行特定的操作。
- 使用数据库身份验证机制,比如用户名和密码的验证,确保只有合法的用户才能访问数据库。
- 定期审计数据库访问日志,及时发现异常访问行为并进行处理。
#### 5.2 数据库连接池的使用
为了提高数据库操作的性能和效率,可以使用数据库连接池技术。数据库连接池可以在应用启动时创建一定数量的数据库连接,并在需要时分配这些连接给请求,使用完毕后再归还到连接池中。这样就可以避免频繁地创建和销毁数据库连接,提高了数据库操作的性能。
以下是使用MySQL数据库连接池的示例代码(使用Node.js和MySQL数据库):
```javascript
const mysql = require('mysql');
const pool = mysql.createPool({
connectionLimit : 10,
host : 'examplehost',
user : 'exampleuser',
password : 'examplepassword',
database : 'exampledatabase'
});
pool.getConnection(function(err, connection) {
if (err) throw err; // not connected!
// Use the connection
connection.query('SELECT something FROM sometable', function (error, results, fields) {
// Handle the result
console.log(results);
// When done with the connection, release it
connection.release();
// Don't use the connection here, it has been returned to the pool.
});
});
```
#### 5.3 压缩和缓存数据以优化性能
在大型应用中,为了提高数据库操作的性能,可以考虑对经常使用的数据进行压缩和缓存。数据压缩可以减小数据在传输过程中占用的带宽,加快数据传输速度;数据缓存可以减少对数据库的频繁访问,加快数据读取速度。
常见的数据缓存方案包括:使用内存数据库(如Redis)进行数据缓存、在应用层进行数据缓存(如使用Memcached)等。
## 章节六:常见问题和解决方案
在进行 Node.js 中的数据库操作时,经常会遇到一些常见的问题,比如数据库连接丢失、查询速度慢、大量数据的导入导出等。本章将为您介绍这些常见问题的解决方案。
### 6.1 数据库连接丢失或超时的处理方法
在 Node.js 中,数据库连接丢失或超时是比较常见的问题,可以通过以下方法进行处理:
```javascript
// 示例代码 - 数据库连接超时处理
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'password',
database: 'mydb'
});
connection.connect((err) => {
if (err) {
console.error('Error connecting: ' + err.stack);
return;
}
console.log('Connected as id ' + connection.threadId);
});
connection.on('error', (err) => {
console.error('Database error: ' + err);
if (err.code === 'PROTOCOL_CONNECTION_LOST') {
// 如果连接丢失,则尝试重新连接
connection.connect();
} else {
throw err;
}
});
```
**代码总结:**
- 使用 `connection.on('error', ...)` 监听数据库连接错误
- 当连接丢失时,尝试重新连接数据库
**结果说明:**
通过以上代码处理方式,能够在数据库连接丢失或超时时进行重新连接,保证数据库操作的稳定性。
### 6.2 数据库查询速度慢的优化技巧
对于 Node.js 中数据库查询速度慢的情况,可以通过以下方式进行优化:
```javascript
// 示例代码 - 数据库查询速度慢优化
const mysql = require('mysql');
const connection = mysql.createConnection({
host: 'localhost',
user: 'root',
password: 'password',
database: 'mydb'
});
connection.query('SELECT * FROM table_name', (error, results, fields) => {
if (error) throw error;
// 处理查询结果
});
// 使用索引来优化查询速度
// ALTER TABLE table_name ADD INDEX index_name (column_name);
```
**代码总结:**
- 使用索引来优化查询速度
- 在 SQL 语句中适当添加索引可以有效提升查询速度
**结果说明:**
通过添加索引等方式优化数据库查询,可以显著提升查询速度,改善系统性能。
### 6.3 如何处理大量数据的导入和导出操作
处理大量数据的导入和导出操作是常见的需求,可以通过以下代码来实现:
```javascript
// 示例代码 - 大量数据的导入和导出操作
const fs = require('fs');
const fastCsv = require('fast-csv');
const mysql = require('mysql');
// 从 CSV 文件中导入数据到数据库
fs.createReadStream('data.csv')
.pipe(fastCsv.parse({ headers: true }))
.on('data', (row) => {
connection.query('INSERT INTO table_name SET ?', row, (error, results, fields) => {
if (error) throw error;
// 插入成功
});
});
// 从数据库导出数据到 CSV 文件
connection.query('SELECT * FROM table_name', (error, results, fields) => {
if (error) throw error;
const csvData = results.map((result) => {
return {
column1: result.column1,
column2: result.column2,
// 其他列
};
});
const csvStream = fastCsv.format({ headers: true });
csvData.forEach((data) => {
csvStream.write(data);
});
csvStream.pipe(fs.createWriteStream('exported_data.csv'));
});
```
**代码总结:**
- 使用 `fast-csv` 模块处理 CSV 文件
- 通过流式处理大量数据的导入和导出操作
**结果说明:**
通过以上方式,可以高效地处理大量数据的导入和导出操作,提升数据处理效率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
这个专栏全面介绍了Node.js的安装和环境配置,以及其基础知识和常用的模块与包管理。同时,还深入探讨了Node.js中的重要概念与技术,如回调函数、异步编程、事件循环、文件操作、网络编程和Web开发入门。此外,专栏还介绍了Express框架的使用、数据库操作、错误处理与调试、性能优化和安全性考虑等方面内容。同时,还涉及到了日志管理、测试与质量保证、跨域问题解决、认证与授权、缓存策略以及消息队列等实际问题。通过阅读本专栏,读者可以全面了解Node.js的使用和开发技巧,帮助他们更好地应用Node.js进行项目开发和优化工作。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
永磁同步电机控制策略仿真:MATLAB_Simulink实现
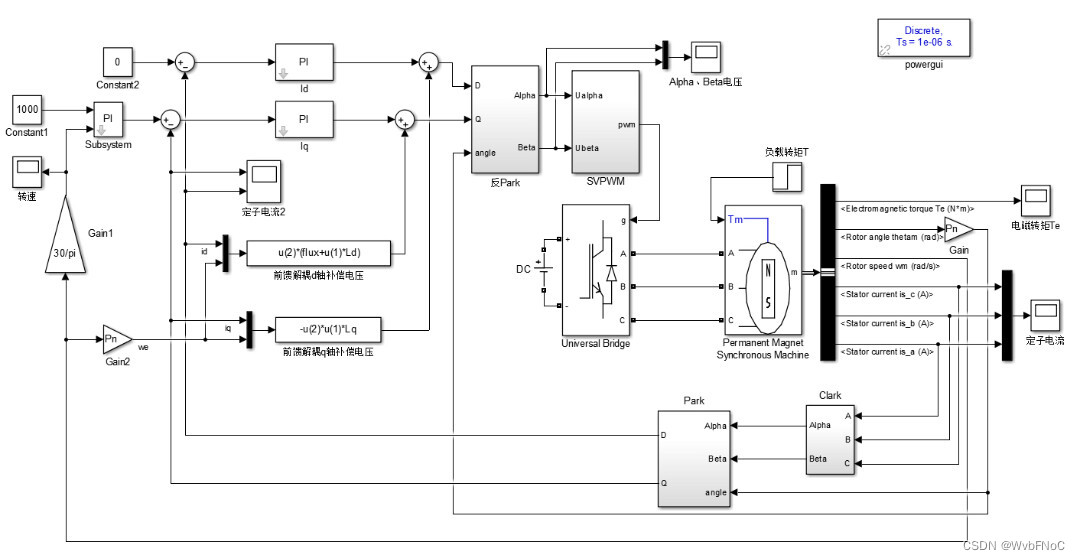
# 摘要
本文概述了永磁同步电机(PMSM)的控制策略,首先介绍了MATLAB和Simulink在构建电机数学模型和搭建仿真环境中的基础应用。随后,本文详细分析了基本控制策略,如矢量控制和直接转矩控制,并通过仿真结果进行了性能对比。在高级控制策略部分,我们探讨了模糊控制和人工智能控制策略在电机仿真中的应用,并对控制策略进行了优化。最后,通过实际应用案例,验证了仿真模型的有效性,并
【编译器性能提升指南】:优化技术的关键步骤揭秘
# 摘要
编译器性能优化对于提高软件执行效率和质量至关重要。本文详细探讨了编译器前端和后端的优化技术,包括前端的词法与语法分析优化、静态代码分析和改进以及编译时优化策略,和后端的中间表示(IR)优化、指令调度与并行化技术、寄存器分配与管理。同时,本文还分析了链接器和运行时优化对性能的影响,涵盖了链接时代码优化、运行时环境的性能提升和调试工具的应用。最后,通过编译器优化案例分析与展望,本文对比了不同编译器的优化效果,并探索了机器学习技术在编译优化中的应用,为未来的优化工作指明了方向。
# 关键字
编译器优化;前端优化;后端优化;静态分析;指令调度;寄存器分配
参考资源链接:[编译原理第二版:
Catia打印进阶:掌握高级技巧,打造完美工程图输出
# 摘要
本文全面探讨了Catia软件中打印功能的应用和优化,从基本打印设置到高级打印技巧,为用户提供了系统的打印解决方案。首先概述了Catia打印功能的基本概念和工程图打印设置的基础知识,包括工程图与打印预览的使用技巧以及打印参数和布局配置。随后,文章深入介绍了高级打印技巧,包括定制打印参数、批量打印、自动化工作流以及解决打印过程中的常见问题。通过案例分析,本文探讨了工程图打印在项目管理中的实际应用,并分享了提升打印效果
快速排序:C语言中的高效稳定实现与性能测试
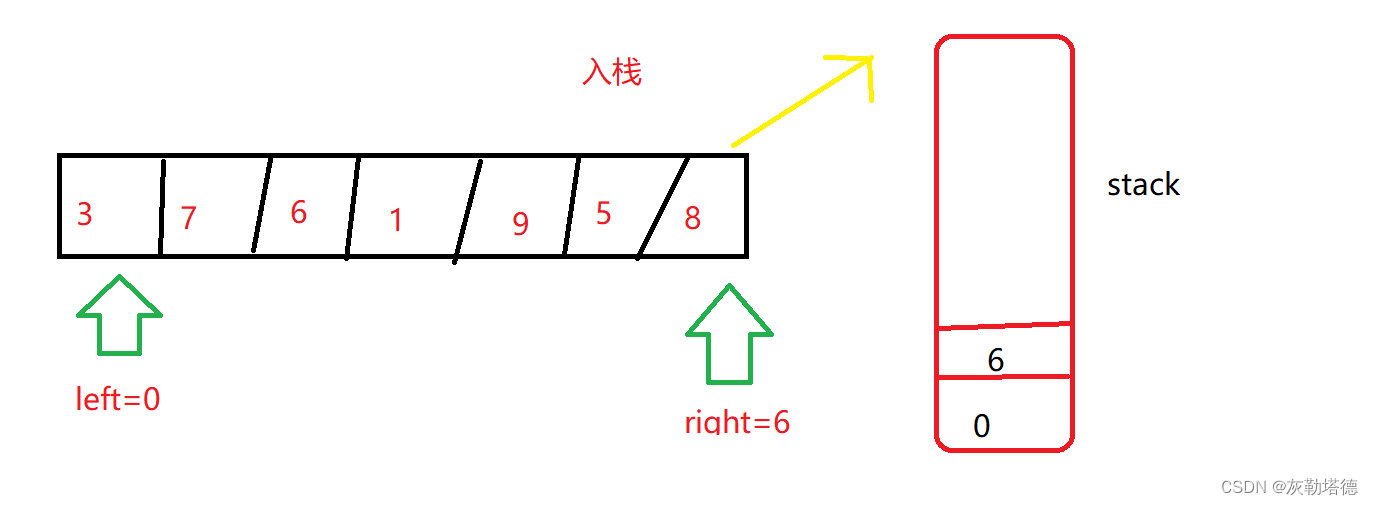
# 摘要
快速排序是一种广泛使用的高效排序算法,以其平均情况下的优秀性能著称。本文首先介绍了快速排序的基本概念、原理和在C语言中的基础实现,详细分析了其分区函数设计和递归调用机制。然后,本文探讨了快速排序的多种优化策略,如三数取中法、尾递归优化和迭代替代递归等,以提高算法效率。进一步地,本文研究了快速排序的高级特性,包括稳定版本的实现方法和非递归实现的技术细节,并与其他排序算法进行了比较。文章最后对快速排序的C语言代码实现进行了分析,并通过性能测
CPHY布局全解析:实战技巧与高速信号完整性分析
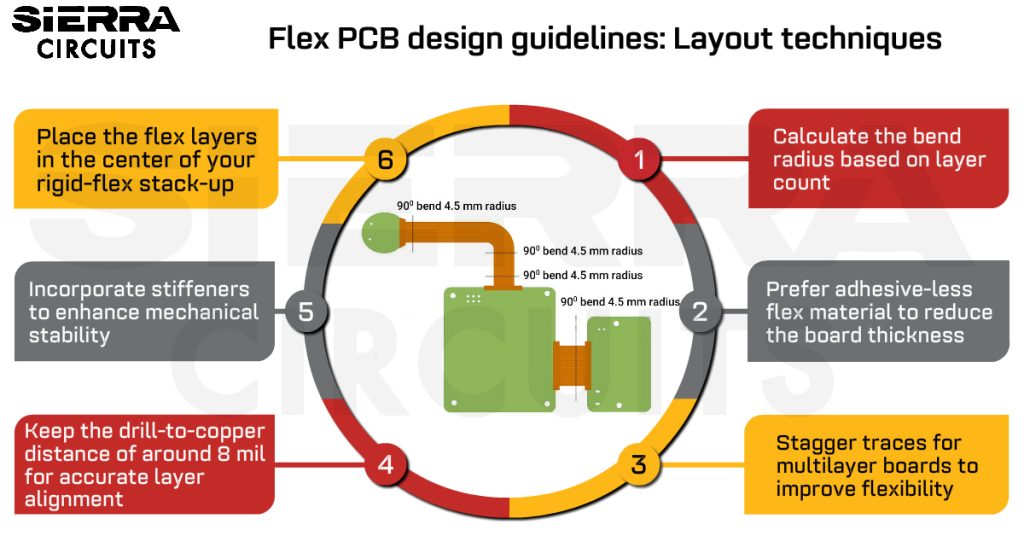
# 摘要
CPHY布局技术是支持高数据速率和高分辨率显示的关键技术。本文首先概述了CPHY布局的基本原理和技术要点,接着深入探讨了高速信号完整性的重要性,并介绍了分析信号完整性的工具与方法。在实战技巧方面,本文提供了CPHY布局要求、走线与去耦策略,以及电磁兼容(EMC)设计的详细说明。此外,本文通过案
四元数与复数的交融:图像处理创新技术的深度解析

# 摘要
本论文深入探讨了图像处理与数学基础之间的联系,重点分析了四元数和复数在图像处理领域内的理论基础和应用实践。首先,介绍了四元数的基本概念、数学运算以及其在图像处理中的应用,包括旋转、平滑处理、特征提取和图像合成等。其次,阐述了复数在二维和三维图像处理中的角色,涵盖傅里叶变换、频域分析、数据压缩、模型渲染和光线追踪。此外,本文探讨了四元数与复数结合的理论和应用,包括傅里叶变
【性能优化专家】:提升Illustrator插件运行效率的5大策略

# 摘要
随着数字内容创作需求的增加,对Illustrator插件性能的要求也越来越高。本文旨在概述Illustrator插件性能优化的有效方法
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )