FENSAP-ICE数据分析与解读方法:揭秘结果背后的真相
发布时间: 2024-12-15 00:51:31 阅读量: 6 订阅数: 8 

参考资源链接:[FENSAP-ICE教程详解:二维三维结冰模型与飞行器性能计算](https://wenku.csdn.net/doc/5z6q9s20x3?spm=1055.2635.3001.10343)
# 1. FENSAP-ICE数据分析概述
## 1.1 FENSAP-ICE简介
FENSAP-ICE,即“全面流场数值模拟与冰霜-粒子-湿气环境的交互分析”是一个高度综合的计算流体力学软件解决方案,专门用于分析航空器表面的冰霜、湿气、污染物等的累积过程和效应。该软件集成了航空器表面结冰、发动机进气道结冰、防冰系统性能评估等模块,是航空研究和工程领域的重要工具。
## 1.2 数据分析在FENSAP-ICE中的作用
数据分析在FENSAP-ICE软件的应用中扮演着核心角色。通过对飞行数据、环境条件、冰霜形成过程等多源数据进行分析,FENSAP-ICE能够预测冰霜对航空器性能的影响,为设计改进和飞行安全评估提供科学依据。因此,深入理解数据分析在FENSAP-ICE中的应用对于提高分析精度和效率至关重要。
## 1.3 本章内容概览
本章将为您介绍FENSAP-ICE数据分析的基本概念、流程以及在航空领域的重要作用。我们将深入探讨如何准备数据集,如何进行有效的数据预处理和清洗,以及如何利用先进的数据分析技术和工具对数据进行解读和可视化。此外,本章还将讨论数据分析在具体案例中的实际应用,以及面临的挑战和未来发展趋势。
# 2. 数据预处理与清洗技巧
### 2.1 数据集的导入与检查
#### 2.1.1 数据格式的识别与转换
在开始数据处理之前,了解数据格式是至关重要的一步。不同来源的数据可能以各种格式存在,如CSV、JSON、Excel等。识别数据格式是导入数据集的前提,而转换数据格式则是为了将数据统一到适合处理的格式。
以Python为例,使用`pandas`库可以灵活地处理各种格式的数据。以下是一个识别与转换数据格式的代码示例:
```python
import pandas as pd
# 加载CSV文件
df_csv = pd.read_csv('data.csv')
# 加载Excel文件
df_excel = pd.read_excel('data.xlsx')
# 转换数据格式,例如从CSV转换为Excel
df_csv.to_excel('data_converted.xlsx', index=False)
```
在上面的代码中,`pandas`库提供了`read_csv`和`read_excel`方法用于加载不同格式的数据文件。通过`to_excel`方法可以将`DataFrame`对象保存为Excel文件,`index=False`参数用于指定是否保存DataFrame的索引。
#### 2.1.2 缺失值与异常值处理
在数据分析过程中,经常遇到含有缺失值或异常值的数据集。这可能会影响分析结果的准确性和可靠性。因此,需要采取措施来处理这些问题。
处理缺失值的一个常用方法是使用均值、中位数或众数来填充它们。而异常值则可能需要根据具体情况采用不同的处理方式,如删除或替换。
在Python中,可以使用以下代码来处理缺失值和异常值:
```python
import numpy as np
# 处理缺失值,使用均值填充
df_csv.fillna(df_csv.mean(), inplace=True)
# 检测并处理异常值,例如使用3倍标准差原则
z_scores = np.abs(stats.zscore(df_csv.select_dtypes(include=[np.number])))
df_clean = df_csv[(z_scores < 3).all(axis=1)]
```
在这里,`fillna`方法用于填充缺失值,`stats.zscore`方法计算了DataFrame中数值类型列的Z分数,`z_scores < 3`将保留绝对Z分数小于3的行,以此识别并过滤异常值。
### 2.2 数据清洗方法
#### 2.2.1 数据归一化与标准化
数据归一化和标准化是数据分析中的常见预处理步骤,目的是将特征缩放到统一的量级。归一化常用于将数据缩放到0和1之间,而标准化则根据均值和标准差将数据调整为标准正态分布。
Python中的`sklearn.preprocessing`提供了便捷的归一化和标准化工具:
```python
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# 归一化处理
scaler_normalize = MinMaxScaler()
df_normalized = pd.DataFrame(scaler_normalize.fit_transform(df_clean.select_dtypes(include=[np.number])))
# 标准化处理
scaler_standardize = StandardScaler()
df_standardized = pd.DataFrame(scaler_standardize.fit_transform(df_clean.select_dtypes(include=[np.number])))
```
在这个例子中,`MinMaxScaler`用于归一化,而`StandardScaler`用于标准化。归一化后的数据在0和1之间,标准化后的数据则具有零均值和单位方差。
#### 2.2.2 噪声数据的过滤技术
噪声数据是指那些不符合数据整体分布规律的数据点。这类数据可能是由于测量误差或其他外部因素造成的。在数据分析中,噪声数据会导致模型训练的困难和结果的偏差。
在处理噪声数据时,可以使用特定的算法,比如局部异常因子(Local Outlier Factor, LOF),它用于识别那些与周围数据点显著不同的点。
```python
from sklearn.neighbors import LocalOutlierFactor
# 初始化LOF模型
lof = LocalOutlierFactor()
# 使用LOF检测异常点
scores = lof.fit_predict(df_standardized)
```
上述代码中,`LocalOutlierFactor`可以预测每个数据点的异常分数,从而识别噪声数据。
#### 2.2.3 数据集的重构与分割
数据集的重构通常涉及特征工程,即从原始数据中创建新的特征。分割数据集则是将数据集分为训练集和测试集,以便进行模型训练和验证。
下面是一个简单的例子来演示如何重构数据和分割数据集:
```python
from sklearn.model_selection import train_test_split
# 创建新特征
df_new_features = df_standar
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 FENSAP-ICE 中文教程专栏!本专栏旨在提供全面的指南,帮助您从基础到精通地掌握 FENSAP-ICE 软件。我们涵盖了广泛的主题,包括:
* 基础操作界面解析
* 模拟仿真基础与实践
* 数据分析与解读方法
* 结果验证和网格划分策略
* 高级后处理技术应用
* 优化设计和粒子追踪
* 仿真流程自动化和与 CFD 软件集成
* 边界条件设置和多相流仿真实战
无论您是 FENSAP-ICE 的新手还是经验丰富的用户,本专栏都能提供宝贵的见解和实用技巧,帮助您充分利用这款强大的仿真软件。跟随我们的教程,您将掌握 FENSAP-ICE 的各个方面,并提升您的仿真技能,从而为您的项目取得成功奠定基础。
专栏目录

文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
精通LTspice:电路设计专家的10大快捷操作技巧
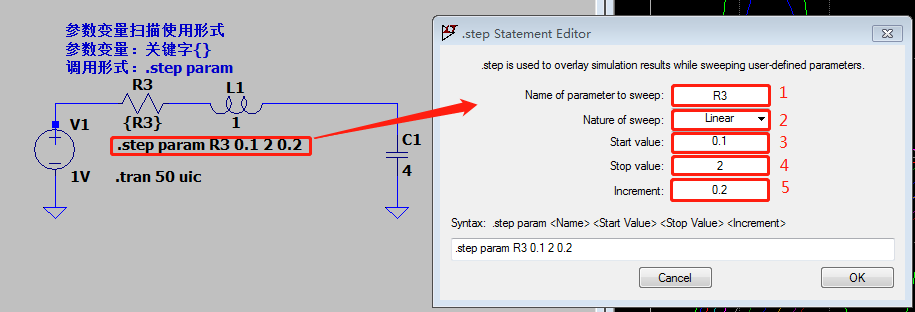
参考资源链接:[LTspice Windows版快捷键全览与新手入门指南](https://wenku.csdn.net/doc/6401acf9cce7214c316edd44?spm=1055.2635.3001.10343)
# 1. LTspice简介与安装
LTspice是一个广泛使用的SPICE模拟器,由Linear Technology公司开发,用于进行快速的电路模拟。它对个人用户是完全
深入解析CCS工程中的LIB文件:库文件作用、生成原理及依赖管理

参考资源链接:[CCS创建LIB文件及引用教程:详述步骤与问题解决](https://wenku.csdn.net/doc/646ef5da543f844488dc93bd?spm=1055.2635.3001.10343)
# 1. CCS工程中LIB文件概述
## 1.1 LIB文件在嵌入式开发中的地位
在嵌入式系统开发中,LIB文件是代码组织和模块化的重要载
【EDE数据包优化】:ARINC664协议性能提升策略与案例分析

参考资源链接:[ARINC664协议详解:AFDX与EDE在航空电子中的关键作用](https://wenku.csdn.net/doc/1xv9wmbdwm?spm=1055.2635.3001.10343)
# 1. EDE数据包优化概述
在信息技术飞速发展的今天,数据包优化在保障网络通信质量方面发挥着至关重要的作用。EDE(Efficient D
【RoCEv2 vs. InfiniBand】:性能对决与最佳应用场景
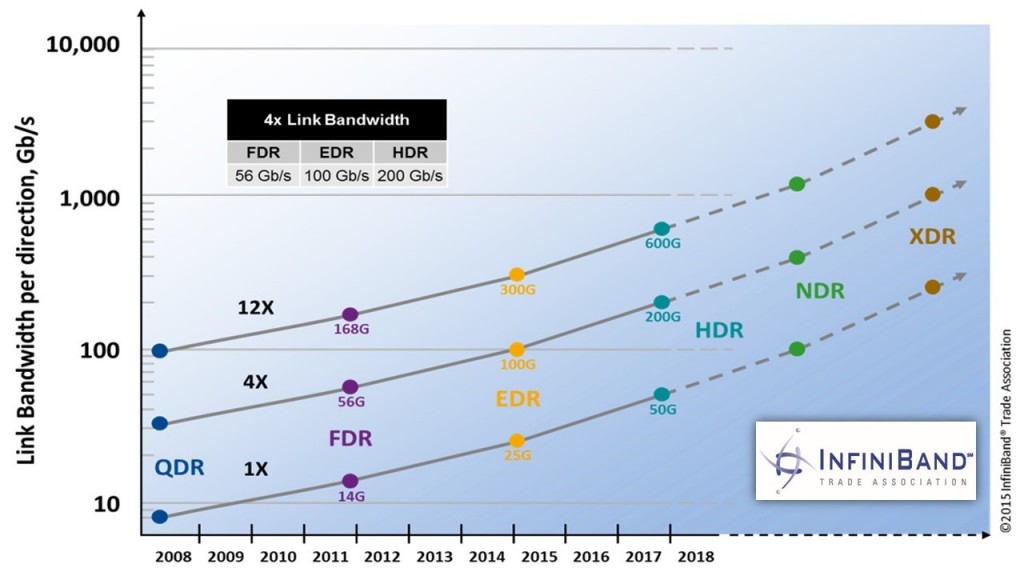
参考资源链接:[InfiniBand Architecture 1.2.1: RoCEv2 IPRoutable Protocol Extension](https://wenku.csdn.net/doc/645f20cb543f8444888a9c3d?spm=1055.2635.3001.10343)
# 1. RoCEv2与InfiniBand技术
【Dev C++使用技巧】:五步法避免Id returned 1 exit status
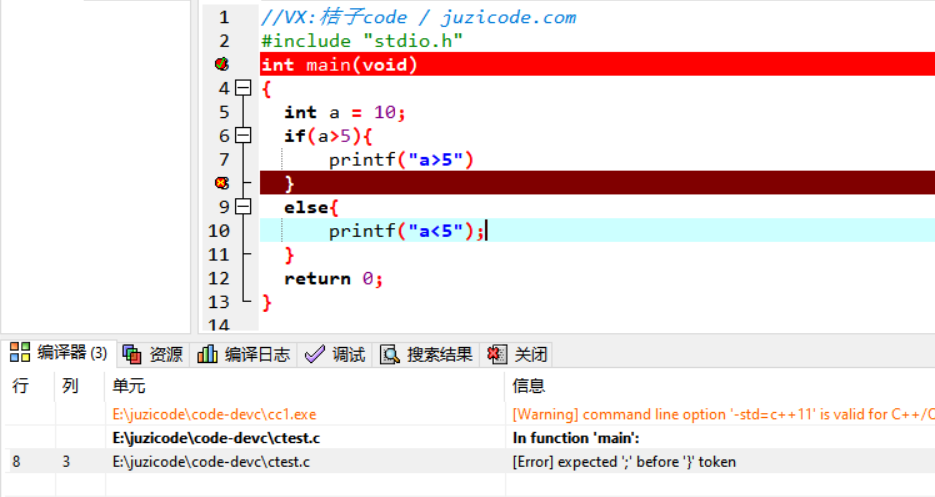
参考资源链接:[解决Dev C++编译错误:Id returned 1 exit status](https://wenku.csdn.net/doc/6412b470be7fbd1778d3f976?spm=1055.2635.3001.10343)
# 1. Dev C++简介与基础设置
Dev C++是C++语言的集成开发环境,它集成了代码编辑、编译、调试等功能
【SAP评估类型在财务报表中的作用】:核心逻辑与精确匹配

参考资源链接:[SAP物料评估与移动类型深度解析](https://wenku.csdn.net/doc/6487e1d8619bb054bf57ad44?spm=1055.2635.3001.10343)
# 1. 财务报表基础知识概览
## 简介
在深入了解SAP评估类型之前,掌握财务报表的基础知识至关重要。财务报表是企业财务状况、经营成果和现金流量的标准
TC397 MCAL UART故障排除:常见问题及解决方案指南(价值型+实用型+急迫性)

参考资源链接:[EB Tresos TC397 UART集成与配置指南](https://wenku.csdn.net/doc/3o310ipz1p?spm=1055.2635.3001.10343)
# 1. TC397 MCAL UART基础
在这一章节中,我们将介绍TC397 MCAL(Microcontroller Abstraction L
【dSPACE RTI 中断响应精讲】:调试专家的快速故障定位与优化手册

参考资源链接:[DSpace RTI CAN Multi Message开发配置教程](https://wenku.csdn.net/doc/33wfcned3q?spm=1055.2635.3001.10343)
# 1. dSPACE RTI简介与工作原理
dSPACE 实时接口(RTI)是工业界中广泛应用的一种实时
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
文章持续更新中,敬请期待~
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )