【机器学习模型优化】:Anaconda环境下的开发实践
发布时间: 2024-12-07 14:40:27 阅读量: 7 订阅数: 13 

svm_机器学习、Python、anaconda_
# 1. 机器学习模型优化概论
在机器学习领域,模型优化是提升算法性能的核心环节。它涉及到模型的准确性、效率、鲁棒性和可解释性等多个维度。优化的目的在于找到最佳的模型参数和结构,使得模型在未见数据上表现良好,达到实际应用的要求。这一过程包含对模型进行细致的调整,比如选择合适的算法、调整学习率和正则化等参数,以及采用先进的优化技术,如梯度下降变种算法、自适应学习率方法等。本章将介绍机器学习模型优化的基本概念,以及优化在模型开发过程中的重要性。
# 2. Anaconda环境搭建与配置
## 2.1 Anaconda环境概述
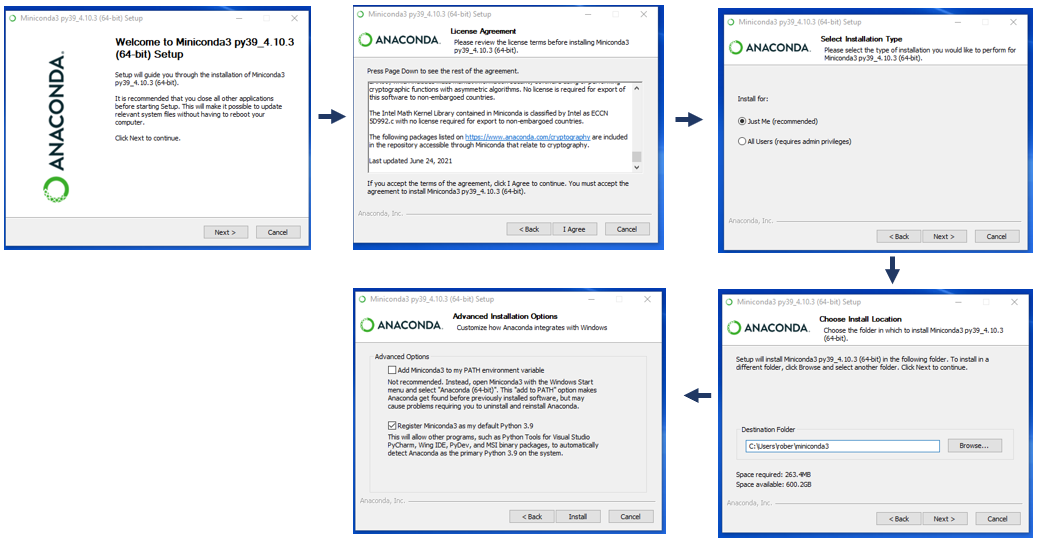
### 2.1.1 Anaconda的安装与初识
Anaconda是一个用于科学计算的Python发行版,它包含了众多流行的科学计算库,如NumPy、SciPy、pandas、scikit-learn等。Anaconda通过其包管理和环境管理功能,使得用户能够方便地安装、管理、更新各种软件包,并且创建、管理和隔离不同的虚拟环境。
安装Anaconda的过程简单直接,用户只需下载适合自己的操作系统的安装包,然后按照安装向导进行安装。安装完成后,Anaconda会自动配置环境变量,用户可以直接在终端或命令提示符中使用Anaconda的相关命令。
```bash
# 在终端执行以下命令检查Anaconda是否安装成功
conda --version
```
### 2.1.2 Anaconda环境和包管理器Conda的使用
Conda是一个开源的软件包管理系统和环境管理系统,它可以快速安装、运行和升级包和依赖关系。Conda可以在Windows、MacOS和Linux上运行,并且可以在同一台机器上安装多个版本的Python。
使用Conda创建一个新环境,并安装一个包的基本步骤如下:
```bash
# 创建一个名为'myenv'的新环境,指定Python版本为3.8
conda create -n myenv python=3.8
# 激活'myenv'环境
conda activate myenv
# 在当前环境中安装一个包,例如scikit-learn
conda install scikit-learn
```
## 2.2 定制化环境配置
### 2.2.1 创建虚拟环境的策略和最佳实践
创建虚拟环境的目的是为了隔离项目依赖,避免不同项目之间的库版本冲突。以下是创建虚拟环境的最佳实践:
- **为每个项目创建独立环境**:这样可以确保项目依赖的包版本不会和其他项目冲突。
- **使用环境文件管理依赖**:创建一个`environment.yml`文件,列出所有依赖包及其版本号,便于环境的复制和重构。
- **定期更新环境**:随着时间的推移,库可能会有更新和安全补丁,定期更新环境可以保证项目的安全性。
### 2.2.2 环境依赖和包的管理技巧
管理依赖和包可以使用以下技巧:
- **使用Conda或pip安装包**:根据包的来源,选择合适的方式安装。
- **管理包的版本**:在`environment.yml`文件中明确指定每个包的版本号,以保证环境的一致性。
- **利用Conda的解决冲突功能**:当存在包版本冲突时,Conda可以尝试解决冲突,而不是简单地拒绝安装。
```yaml
# environment.yml示例
name: myenv
dependencies:
- python=3.8
- numpy
- pandas
- scikit-learn=0.22.1
```
## 2.3 集成开发环境(IDE)的选择与配置
### 2.3.1 常见IDE的比较和选择
选择合适的集成开发环境(IDE)对于提高开发效率和体验非常关键。以下是几种流行的Python开发IDE及其特点:
- **PyCharm**:专业版功能丰富,社区版免费。提供代码自动完成、调试、测试等强大的功能。
- **Visual Studio Code**:轻量级,插件丰富,适用于各种编程语言和项目类型。
- **Jupyter Notebook**:适合数据分析和机器学习项目的开发,支持交互式编程。
### 2.3.2 环境与IDE的集成配置
环境与IDE集成配置的步骤取决于选择的IDE。以PyCharm为例,用户可以按照以下步骤进行配置:
- 打开PyCharm,选择"Preferences"(或"File" -> "Settings")。
- 在"Project: YourProjectName" -> "Project Interpreter"中,点击齿轮图标。
- 选择"Add",然后选择"Conda Environment"。
- 选择现有的环境或者创建一个新的环境。
- 选择环境所在的目录,并确认配置。
通过以上步骤,PyCharm会配置相应的环境,并在编写代码时使用这个环境。
# 3. 特征工程与数据预处理
在数据科学项目中,特征工程与数据预处理是模型训练前的准备阶段,它们对最终模型的性能和准确性有着决定性的影响。这一章节将深入探讨数据预处理技术和特征工程的方法,以及如何有效地将这些策略应用于现实世界的问题。
### 3.1 数据预处理技术
数据预处理是任何机器学习项目中的第一步,也是至关重要的一步。它涉及多个步骤,包括数据清洗、处理缺失值、异常值以及数据标准化和归一化。
#### 3.1.1 数据清洗和缺失值处理
在获取到原始数据后,第一个要处理的问题通常是数据质量问题。数据清洗是一个识别、纠正或删除数据中不完整、不准确或不一致部分的过程。
```python
import pandas as pd
from sklearn.impute import SimpleImputer
# 创建一个示例DataFrame
data = pd.DataFrame({
'feature1': [1, 2, None, 4, 5],
'feature2': [None, 3, 3, 4, None],
'target': [1, 1, 0, 1, 0]
})
# 缺失值处理策略:使用列的中位数填充
imputer = SimpleImputer(strategy='median')
data_filled = pd.DataFrame(imputer.fit_transform(data), columns=data.columns)
```
在上述代码中,我们使用了`SimpleImputer`类来处理缺失值,该类属于`sklearn`库,它提供了一种简单的方式来填充缺失值。`strategy='median'`参数指明我们用中位数来替代缺失值。
#### 3.1.2 数据标准化和归一化方法
数据标准化和归一化是将数据特征的缩放调整到特定的范围或分布,这样可

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Anaconda在数据科学中的应用》专栏深入探讨了Anaconda在数据科学领域的广泛应用。文章涵盖了Anaconda的入门指南、环境构建、高级配置、并行计算加速、协作分析、版本控制、云部署、框架整合、数据可视化、机器学习模型优化、大数据处理和自动化数据分析等主题。通过这些文章,读者可以全面了解Anaconda在数据科学工作流程中的作用,并掌握如何利用Anaconda提高数据分析效率和协作能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【UHD 620核显驱动与虚拟机兼容性详解】:VMware和VirtualBox中的最佳实践
参考资源链接:[Win7 64位下UHD 620/630核显驱动发布(8代处理器适用)](https://wenku.csdn.net/doc/273in28khy?spm=1055.2635.3001.10343)
# 1. UHD 620核显驱动概述
## 1.1 UHD
【BODAS编程实践】:6个高效编码秘诀,让你成为控制应用代码高手
参考资源链接:[BODAS控制器编程指南:从安装到下载的详细步骤](https://wenku.csdn.net/doc/6ygi1w6m14?spm=1055.2635.3001.10343)
# 1. BODAS编程实践概览
在当今这个以数据为中心的世界里,BODAS编程语言因其独特的架构和强大的性能,受到了越来越多开发者的青睐。它不仅仅是一种工具,更是一种设计理念,它在处理大规模数据和实时计算方面展现了出色的能力。本章将为读者提供一
【LabVIEW错误代码应用秘籍】:提升效率的10个技巧
参考资源链接:[LabVIEW错误代码大全:快速查错与定位](https://wenku.csdn.net/doc/7am571f3vk?spm=1055.2635.3001.10343)
# 1. LabVIEW错误代码的基础知识
在LabVIEW的编程实践中,错误代码是程序运行时不可或缺的一部分,它们帮助开发者理解程序执行过程中可能遇到的问题。理解错误代码对于提升L
Fluent UDF并行计算优化秘籍:提升大规模仿真效率的终极指南
参考资源链接:[Fluent UDF中文教程:自定义函数详解与实战应用](https://wenku.csdn.net/doc/1z9ke82ga9?spm=1055.2635.3001.10343)
# 1. Fluent UDF并行计算基础
Fluent是流体仿真领域广泛使用的计算流体动力学(CFD)软件,其用户定义函数(UDF)是扩展软件功能的强大工具。本章节将探
内存乒乓缓存机制:C语言最佳实践
参考资源链接:[C代码实现内存乒乓缓存与消息分发,提升内存响应](https://wenku.csdn.net/doc/64817668d12cbe7ec369e795?spm=1055.2635.3001.10343)
# 1. 内存乒乓缓存机制概述
## 内存乒乓缓存简介
内存乒乓缓存机制是一种高效的内存管理策略,它通过使用两组内存缓冲区交替处理数据流,以减少缓存失效和提高系统性能。这种机制特别适用于数据流连续且具有
宏命令性能优化策略:提升执行效率的5大技巧
参考资源链接:[魔兽世界(WOW)宏命令完全指南](https://wenku.csdn.net/doc/6wv6oyaoy6?spm=1055.2635.3001.10343)
# 1. 宏命令性能优化概述
在现代IT行业中,宏命令作为一种常见的自动化指令集,广泛应用于多种场景,如自动化测试、系统配置等。性能优化,尤其是对宏命令的优化,对于提高工作效率、保障系统稳定性以及实现资源高效利用具有重要意义。本章将
【HBM ESD测试自动化】:结合JESD22-A114-B标准的新技术应用

参考资源链接:[JESD22-A114-B(EDS-HBM).pdf](https://wenku.csdn.net/doc/6401abadcce7214c316e91b7?spm=1055.2635.3001.10343)
# 1. HBM ESD测试概述
在现代电子制造领域中,随着集成电路密度的不断提高和尺寸的不断缩小,电路对静电放电(ESD)的敏感性也随之增加,这成为了电子行
【CAD许可问题急救手册】:迅速诊断并解决“许可管理器不起作用或未正确安装”
参考资源链接:[CAD提示“许可管理器不起作用或未正确安装。现在将关闭AutoCAD”的解决办法.pdf](https://wenku.csdn.net/doc/644b8a65ea0840391e559a08?spm=1055.2635.3001.10343)
# 1. CAD许可问题概述
CAD软件作为工程设计领域不可或缺的工具,其许可问题一直备受关注。本章将为读者提供一个关于CAD许
深入解析STC89C52单片机:掌握内部结构的5大核心要点
参考资源链接:[STC89C52单片机中文手册:概览与关键特性](https://wenku.csdn.net/doc/70t0hhwt48?spm=1055.2635.3001.10343)
# 1. STC89C52单片机概述
STC89C52单片机作为一款经典的8位微控制器,它在工业控制、家用电器和嵌入式系统设计等领域广泛应用于各种控制任务。它由STC公司生产,是基于Intel 8051内核的单片机产品系列之一。该单片机因其高可靠性和高性价比而被广泛采用,其性能在对资源要求不是极高的场合完全能够满足。
核心硬件组成方面,STC89C52拥有4KB的内部程序存储器(ROM)、128字节
【计算机网络与体系结构融合】:整合技术与系统整合的五大方法

参考资源链接:[王志英版计算机体系结构课后答案详解:层次结构、虚拟机与透明性](https://wenku.csdn.net/doc
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )