从头搭建Linux环境下的CUDA安装
发布时间: 2024-04-08 12:18:59 阅读量: 54 订阅数: 66 

Linux操作系统,CUDA安装指南
# 1. 介绍CUDA
- CUDA是什么
- CUDA的优势和应用领域
- CUDA在深度学习和科学计算中的重要性
# 2. 准备工作
- 确认Linux操作系统版本
- 验证NVIDIA显卡是否支持CUDA
- 下载CUDA安装包和驱动程序
# 3. 安装NVIDIA显卡驱动
在安装CUDA之前,首先需要确保你的NVIDIA显卡驱动已经正确安装。接下来,我们将介绍如何在Linux环境下安装NVIDIA显卡驱动。
#### 1. 卸载旧版NVIDIA驱动
```shell
# 停止并禁用图形界面
sudo systemctl stop lightdm # LightDM 是 Ubuntu 的显示管理器
sudo systemctl disable lightdm
# 进入命令行模式
Ctrl + Alt + F1
# 卸载旧版NVIDIA驱动
sudo apt purge nvidia-*
```
#### 2. 安装新版NVIDIA驱动
```shell
# 添加NVIDIA驱动 PPA
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt update
# 安装新版NVIDIA驱动
sudo apt install nvidia-driver-<版本号> # 例如:sudo apt install nvidia-driver-460
```
#### 3. 验证显卡驱动安装是否成功
```shell
# 重启计算机
sudo reboot
# 查看NVIDIA显卡信息
nvidia-smi
```
通过上述步骤,你可以成功安装并验证NVIDIA显卡驱动是否正确加载。接下来,我们将继续安装CUDA工具包。
# 4. 安装CUDA工具包
在这一章节中,我们将详细介绍如何安装CUDA工具包,让您能够在Linux环境下顺利使用CUDA进行深度学习和科学计算任务。
### 执行CUDA安装包
首先,我们需要下载CUDA的安装包,并在Linux系统上执行安装。请确保您已经按照前文准备工作中的步骤下载了适用于您系统的CUDA安装包。
```bash
sudo sh cuda_10.1.105_418.39_linux.run
```
接着,按照安装向导的提示进行操作,可以选择安装路径、是否安装NVIDIA驱动等选项。
### 选择安装选项
在安装过程中,您需要根据自己的需求选择相应的安装选项。一般情况下,默认选项即可满足大部分用户的需求,但也可以根据具体情况进行定制化设置。
### 设置CUDA环境变量
安装完成后,为了能够顺利地使用CUDA工具包,我们需要设置相应的环境变量。可以编辑 `~/.bashrc` 文件,添加如下行:
```bash
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
```
保存文件并执行以下命令使其生效:
```bash
source ~/.bashrc
```
这样,环境变量就设置完成了,您可以开始在Linux环境下使用CUDA进行编程和计算任务了。
在下一章节中,我们将演示如何编译并运行CUDA示例程序,来验证CUDA是否成功安装并配置。
# 5. 编译并运行CUDA示例
在这一章节中,我们将详细介绍如何编译并运行CUDA示例程序,以验证CUDA环境的正常搭建和配置。
#### 编译CUDA示例程序
首先,我们需要下载CUDA示例程序的源代码,通常这些示例代码会包含在CUDA Toolkit中。我们以一个简单的向量相加程序(vector_add.cu)作为示例。
```python
# vector_add.cu
#include <iostream>
__global__ void add(int *a, int *b, int *c, int n) {
int tid = blockIdx.x;
if (tid < n) {
c[tid] = a[tid] + b[tid];
}
}
int main() {
int n = 10;
int a[n], b[n], c[n];
int *dev_a, *dev_b, *dev_c;
// Allocate device memory
cudaMalloc((void**)&dev_a, n * sizeof(int));
cudaMalloc((void**)&dev_b, n * sizeof(int));
cudaMalloc((void**)&dev_c, n * sizeof(int));
// Initialize input arrays
for (int i = 0; i < n; ++i) {
a[i] = i;
b[i] = i * 2;
}
// Copy input arrays from host to device
cudaMemcpy(dev_a, a, n * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, n * sizeof(int), cudaMemcpyHostToDevice);
// Launch add() kernel on GPU
add<<<n, 1>>>(dev_a, dev_b, dev_c, n);
// Copy result array from device to host
cudaMemcpy(c, dev_c, n * sizeof(int), cudaMemcpyDeviceToHost);
// Output result
for (int i = 0; i < n; ++i) {
std::cout << c[i] << " ";
}
std::cout << std::endl;
// Free device memory
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
```
以上是一个简单的向量相加CUDA示例程序的代码。我们首先声明了一个CUDA核函数`add`来进行向量相加操作,并在主函数中进行了内存的分配、数据初始化、数据传输和核函数调用等操作。
#### 运行CUDA示例程序
接下来,我们将演示如何编译并运行这个CUDA示例程序。假设我们已经保存代码为`vector_add.cu`,接下来执行以下步骤:
```bash
nvcc vector_add.cu -o vector_add
./vector_add
```
通过上述命令,我们使用`nvcc`编译CUDA程序,并将可执行文件命名为`vector_add`,然后运行该程序。如果一切顺利,您将看到程序输出的结果为每个位置上两个向量相加的结果。
#### 检查CUDA程序运行结果
在运行CUDA示例程序后,您可以根据输出结果来验证程序是否正常运行。确保输出结果与您预期的向量相加结果一致,以确认CUDA程序编译并运行正确。
通过以上步骤,您已经成功编译并运行了一个简单的CUDA示例程序,验证了您的CUDA环境已经搭建完毕。
# 6. 常见问题解决
在安装和配置CUDA环境的过程中,可能会遇到一些常见问题,下面列出一些常见问题及解决方法供参考:
1. **CUDA安装失败常见原因和解决办法**
- **原因**:可能是由于操作系统版本不兼容、显卡驱动问题或者CUDA安装包损坏等原因导致安装失败。
- **解决方法**:首先检查操作系统是否满足CUDA的最低要求版本,确认显卡是否支持CUDA,并且尝试重新下载安装包进行安装。
2. **CUDA程序编译运行遇到的常见问题及解决方法**
- **原因**:编译CUDA程序时可能会遇到路径配置错误、库依赖问题或者代码逻辑错误等导致程序无法正常运行。
- **解决方法**:检查CUDA程序中的路径配置是否正确,确认库依赖是否完整并正确安装,同时对代码进行逐行调试排查逻辑问题。
3. **CUDA环境配置问题解决方案**
- **原因**:CUDA环境配置不正确会导致程序无法编译运行,包括环境变量设置错误、编译器不匹配等问题。
- **解决方法**:检查CUDA环境变量设置是否正确,确认编译器版本和CUDA版本是否匹配,需要仔细检查配置并及时调整。
通过以上常见问题的解决方法,可以帮助解决在搭建Linux环境下CUDA安装过程中可能遇到的困难,提高安装和配置的效率和成功率。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**CUDA 安装指南**
本专栏提供了全面的 CUDA 安装指南,涵盖从初学者入门到高级用户深入了解的各个方面。它详细介绍了在 Windows 和 Linux 系统中安装 CUDA 工具包的步骤,并提供了有关驱动程序更新、工具包组件、运行时库和 IDE 集成的信息。此外,该指南还讨论了 CUDA 与不同编程语言的结合、环境变量配置、错误解决以及验证安装成功的最佳实践。无论是初学者还是经验丰富的开发人员,本专栏都是您了解 CUDA 安装和开发过程的宝贵资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
编译器优化算法探索:图着色与寄存器分配详解
# 摘要
编译器优化是提高软件性能的关键技术之一,而图着色算法在此过程中扮演着重要角色。本文系统地回顾了编译器优化算法的概述,并深入探讨了图着色算法的基础、在寄存器分配中的应用以及其分类和比较。接着,本文详细分析了寄存器分配策略,并通过多种技术手段对其进行了深入探讨。此外,本文还研究了图着色算法的实现与优化方法,并通过实验评估了这些方法的性能。通过对典型编程语言编译器中寄存器分配案例的分析,本文展示了优化策略的实际
时间序列季节性分解必杀技:S命令季节调整手法

# 摘要
时间序列分析是理解和预测数据动态的重要工具,在经济学、气象学、工商业等多个领域都有广泛应用。本文首先介绍了时间序列季节性分解的基本概念和分类,阐述了时间序列的特性,包括趋势性、周期性和季节性。接着,本文深入探讨了季节调整的理论基础、目的意义以及常用模型和关键假设。在实践环节,本文详细说明了如何使用S命令进行季节调整,并提供了步骤和技巧。案例分析部分进一步探讨了
【SAP MM高级定制指南】:4个步骤实现库存管理个性化

# 摘要
本文旨在深入探讨SAP MM(物料管理)模块的高级定制策略与实践。首先对SAP MM模块的功能和库存管理基础进行了概述。随后,介绍了定制的理论基础,包括核心功能、业务流程、定制概念及其类型、以及定制的先决条件和限制。文章接着详细阐述了实施高级定制的步骤,涉及需求分析、开发环境搭建、定制对象开发和测试等关键环节。此外,本文还探讨了SAP MM高级
【ParaView过滤器魔法】:深入理解数据预处理
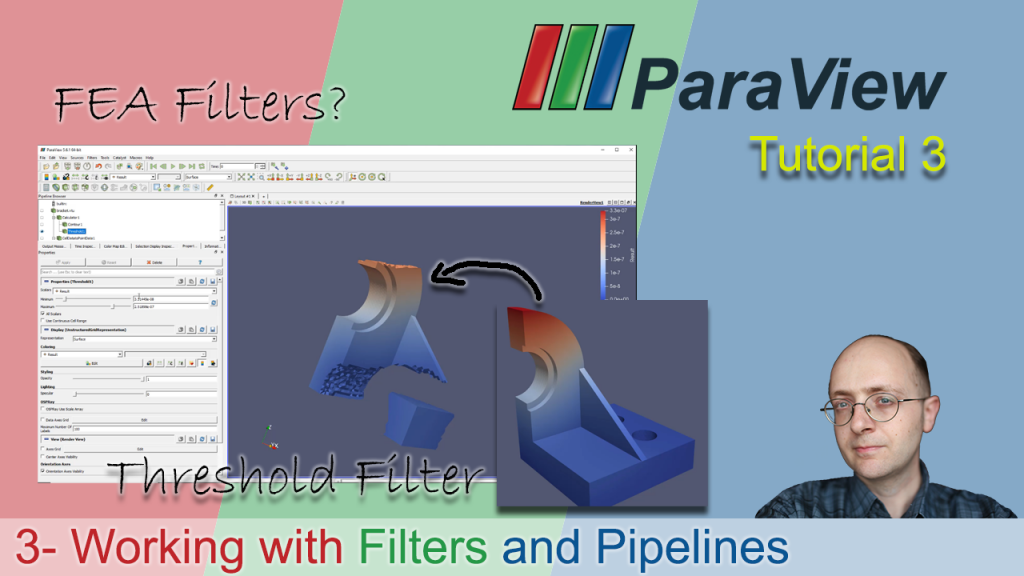
# 摘要
本文全面介绍了ParaView在数据预处理和分析中的应用,重点阐述了过滤器的基础知识及其在处理复杂数据结构中的作用。文章详细探讨了基本过滤器的使用、参数设置与管理、以及高级过滤技巧与实践,包括性能优化和数据流管理。此外,还对数据可视化与分析进行了深入研究,并通过实际案例分析了ParaView过滤器在科
【扩展Strip功能】:Visual C#中Strip控件的高级定制与插件开发(专家技巧)
# 摘要
Strip控件作为用户界面的重要组成部分,广泛应用于各种软件系统中,提供了丰富的定制化和扩展性。本文从Strip控件的基本概念入手,逐步深入探讨其高级定制技术,涵盖外观自定义、功能性扩展、布局优化和交互式体验增强。第三章介绍了Strip控件插件开发的基础知识,包括架构设计、代码复用和管理插件生命周期的策略。第四章进一步讲解了数据持久化、多线程处理和插件间交互等高级开发技巧。最后一章通过实践案例分析,展示了如何根据用户需求设计并开发出具有个性化功能的Strip控件插件,并讨论了插件测试与迭代过程。整体而言,本文为开发者提供了一套完整的Strip控件定制与插件开发指南。
# 关键字
S
【数据处理差异揭秘】

# 摘要
数据处理是一个涵盖从数据收集到数据分析和应用的广泛领域,对于支持决策过程和知识发现至关重要。本文综述了数据处理的基本概念和理论基础,并探讨了数据处理中的传统与现代技术手段。文章还分析了数据处理在实践应用中的工具和案例,尤其关注了金融与医疗健康行业中的数据处理实践。此外,本文展望了数据处理的未来趋势,包括人工智能、大数据、云计算、边缘计算和区块链技术如何塑造数据处理的未来。通过对数据治理和
【C++编程高手】:精通ASCII文件读写的最佳实践
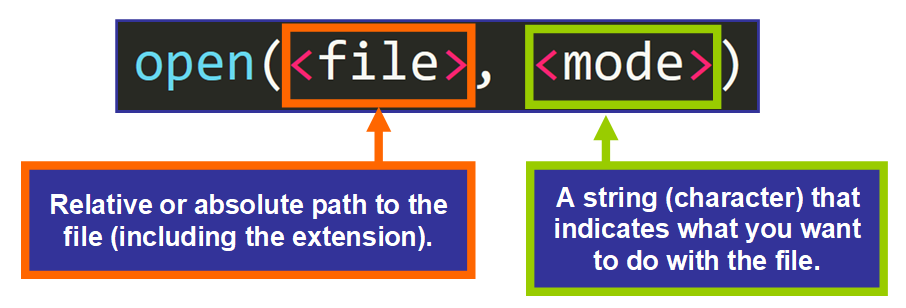
# 摘要
C++作为一门强大的编程语言,其在文件读写操作方面提供了灵活而强大的工具和方法。本文首先概述了C++文件读写的基本概念和基础知识,接着深入探讨了C++文件读写的高级技巧,包括错误处理、异常管理以及内存映射文件的应用。文章进一步分析了C++在处理ASCII文件中的实际应用,以及如何在实战中解析和重构数据,提供实用案例分析。最后,本文总结了C++文件读写的最佳实践,包括设计模式的应用、测试驱动开发(TDD)的
【通信信号分析】:TTL电平在现代通信中的关键作用与案例研究
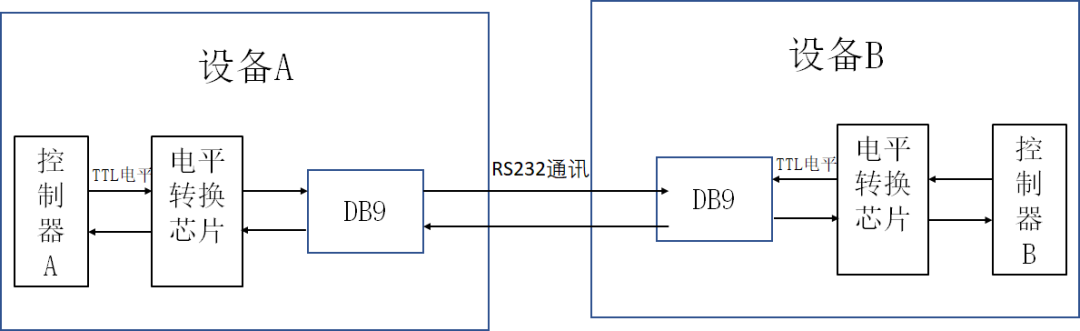
# 摘要
TTL电平作为电子和通信领域中的基础概念,在数字逻辑电路及通信接口中扮演着至关重要的角色。本文深入探讨了TTL电平的基础作用、技术细节与性能分析,并比较了TTL与CMOS电平的差异及兼容性问题。接着,本文着重分析了TTL电平在现代通信系统中的应用,包括其在数字逻辑电路、微处理器、通信接口协议中的实际应用以及
零基础Pycharm教程:如何添加Pypi以外的源和库

# 摘要
Pycharm作为一款流行的Python集成开发环境(IDE),为开发人员提供了丰富的功能以提升工作效率和项目管理能力。本文从初识Pycharm开始,详细介绍了环境配置、自定义源与库安装、项目实战应用以及高级功能的使用技巧。通过系统地讲解Pycharm的安装、界面布局、版本控制集成,以及如何添加第三方源和手动安装第三方库,本文旨在帮助读者全面掌握Pycharm的使用,特
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )