【Java字符串构建器对比】:StringBuilder与StringBuffer的选择之道
发布时间: 2024-09-25 03:32:01 阅读量: 26 订阅数: 26 

java String、StringBuilder和StringBuffer的区别详解
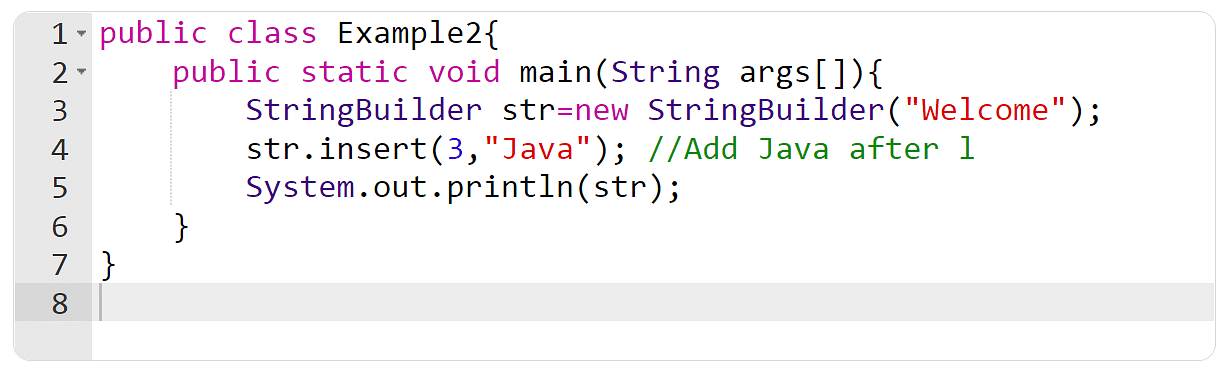
# 1. Java字符串构建器概述
在Java编程语言中,字符串构建器是构建和修改字符串值的常用工具。Java提供了几种方式来操作字符串,其中最常见的是`StringBuilder`和`StringBuffer`。它们允许开发者以更高效的方式动态地修改字符串内容,与`String`类的不可变性质相比,它们在频繁修改字符串的场景下尤其有用。
`StringBuilder`和`StringBuffer`主要通过字符数组实现,它们的内部结构允许在运行时通过添加、删除或替换操作来修改字符串内容。尽管它们的用法相似,但它们在性能和线程安全性上存在差异,这是本章将要探讨的重点之一。
本章将从字符串构建器的基本概念入手,概述它们的用途、结构和使用场景,为理解后面章节中的深入分析和应用策略打下基础。接下来的章节将逐步展开,深入探讨它们的内部机制、性能影响以及在多线程环境下的行为。
```java
// 示例代码:使用StringBuilder进行字符串构建
StringBuilder sb = new StringBuilder();
sb.append("Hello");
sb.append(" World!");
String result = sb.toString(); // 结果为 "Hello World!"
```
在这个示例中,`StringBuilder`被用来动态地构建一个字符串。这比使用多次加号(`+`)操作符来连接字符串要高效得多,因为它减少了中间`String`对象的创建。
# 2. 深入理解StringBuilder与StringBuffer
## 2.1 StringBuilder与StringBuffer的结构和特性
### 2.1.1 类的继承结构
`StringBuilder` 和 `StringBuffer` 是 Java 中用来处理可变字符串的两个核心类。它们都继承自 `AbstractStringBuilder` 类,并间接实现了 `CharSequence` 接口。`AbstractStringBuilder` 类提供了大部分字符串操作的底层实现,而 `StringBuilder` 和 `StringBuffer` 则在此基础上添加了线程安全的处理。
- `AbstractStringBuilder`:提供了动态数组的实现,以及诸如 `append` 和 `insert` 等修改字符串的方法。
- `StringBuffer`:在 `AbstractStringBuilder` 的基础上添加了同步控制,使得它成为线程安全的。
- `StringBuilder`:与 `StringBuffer` 类似,但没有同步控制,因此在单线程环境中更快。
```java
public abstract class AbstractStringBuilder implements Appendable, CharSequence {
// 实现了字符数组的扩容、追加、插入等操作
}
public final class StringBuffer extends AbstractStringBuilder
implements java.io.Serializable, Cloneable, Comparable<StringBuffer> {
// 添加了 synchronized 关键字,以实现线程安全
}
public final class StringBuilder extends AbstractStringBuilder
implements java.io.Serializable, Cloneable, Comparable<StringBuilder> {
// 无同步处理,速度快
}
```
### 2.1.2 核心成员变量和方法
`StringBuilder` 和 `StringBuffer` 拥有几乎相同的成员变量和方法,其中关键的成员变量包括一个字符数组 `value[]` 用于存储字符串数据,以及一个可变的 `int` 类型变量 `count` 用于记录实际字符数。核心方法有 `append()` 和 `insert()` 用于字符串的拼接和插入,`delete()` 和 `replace()` 用于删除和替换字符串中的字符。
```java
private transient char[] value; // 字符数组
private int count; // 实际字符数
public StringBuilder append(String str) {
super.append(str);
return this;
}
public StringBuilder insert(int offset, char[] str, int strLen) {
super.insert(offset, str, 0, strLen);
return this;
}
```
其中,`append()` 方法会根据需要调整 `value` 数组的大小,并将新字符添加到数组末尾。`insert()` 方法则更复杂,因为它需要在指定位置插入字符,可能会引起数组元素的移动。
## 2.2 StringBuilder与StringBuffer的性能对比
### 2.2.1 内部工作机制差异
`StringBuilder` 和 `StringBuffer` 的主要区别在于它们的内部工作机制。`StringBuffer` 的所有公共方法都被 `synchronized` 关键字修饰,确保了线程安全,但同时也带来了额外的性能开销。而 `StringBuilder` 方法没有同步控制,因此在单线程环境中运行更快。
### 2.2.2 性能基准测试与分析
在性能测试中,可以发现 `StringBuilder` 在单线程环境中通常比 `StringBuffer` 快上 10% 到 15%。这个比例会随着字符串的长度和操作的复杂性增加。然而,在多线程环境中,`StringBuffer` 的线程安全性则成为其优势。
```java
public class StringBuilderVsStringBufferTest {
public static void main(String[] args) {
// 测试代码,创建一个巨大的循环,执行字符串操作
long start = System.currentTimeMillis();
StringBuilder sb = new StringBuilder();
for (int i = 0; i < 10000; i++) {
sb.append("a");
}
long end = System.currentTimeMillis();
System.out.println("StringBuilder took " + (end - start) + " ms");
start = System.currentTimeMillis();
StringBuffer sbf = new StringBuffer();
for (int i = 0; i < 10000; i++) {
sbf.append("a");
}
end = System.currentTimeMillis();
System.out.println("StringBuffer took " + (end - start) + " ms");
}
}
```
在上面的代码中,我们分别使用 `StringBuilder` 和 `StringBuffer` 进行了字符串追加操作。通过计时器,我们可以看到两种方法的执行时间差距。
## 2.3 线程安全与同步机制的考量
### 2.3.1 同步机制的实现原理
`StringBuffer` 的同步机制是通过在每个公共方法前加上 `synchronized` 关键字来实现的,从而保证了在多线程环境下对共享对象的访问是线程安全的。这意味着当一个线程访问 `StringBuffer` 的方法时,其他线程必须等待该方法执行完成。
### 2.3.2 在多线程环境下的表现
在多线程环境中,`StringBuffer` 的优势是明显并且必要的。如果多个线程同时对同一个 `StringBuffer` 对象进行读写操作,没有同步机制将会导致不可预测的结果。然而,在高并发的场景下,`StringBuffer` 的同步机制可能会成为性能瓶颈。
```java
public class StringBufferThreadSafeDemo {
public static void main(String[] args) {
StringBuffer sbf = new StringBuffer();
Runnable r = () -> {
for (int i = 0; i < 1000; i++) {
sbf.append(String.valueOf(i));
}
};
// 启动多个线程进行演示
Thread t1 = new Thread(r);
Thread t2 = new Thread(r);
t1.start();
t2.start();
try {
t1.join();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Result: " + sbf.toString());
}
}
```
在上述代码中,两个线程同时对同一个 `StringBuffer` 对象进行操作,最终结果将证明 `StringBuffer` 的线程安全特性。
## 代码块和表格
### 代码块展示
下面是 `StringBuilder` 和 `StringBuffer` 在不同长度字符串操作下的性能对比示例代码:
```java
public class StringBuilderVsStringBufferPerformance {
public static void main(String[] args) {
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨 Java 中的字符串,涵盖其优化、剖析、操作、性能、国际化、转换、编码、分割、搜索、去重、安全、缓存、集合互转、比较、排序、构建器对比和处理实践等各个方面。
通过一系列文章,本专栏旨在帮助读者全面理解 Java 字符串的特性、最佳实践和性能优化技巧。从提升字符串性能的策略到掌握字符串不可变性的秘密,再到高效搜索和匹配的算法,本专栏提供了丰富的知识和实践指南。此外,还涵盖了字符串安全、缓存、国际化处理和数据类型转换等重要主题,为读者提供全面深入的 Java 字符串知识。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
S7-1500 PLC编程实战手册:图形化编程技巧深度揭秘
# 摘要
随着自动化和智能制造的快速发展,S7-1500 PLC编程技术的应用变得日益广泛。本文首先介绍了S7-1500 PLC的基本编程概念及其在TIA Portal环境下的图形化编程基础,随后探讨了编程中的高级技巧,如数据类型处理、功能块应用以及异常处理和优化。接着,文中分析了图形化编程在实践中的应用案例,从自动化项目的需求分析到高级控制策略的实现。在问题诊断与解决章节,讨论了编程错误的识别、性能分析以
Halcon函数应用全解读

# 摘要
本文全面介绍了Halcon软件在图像处理与机器视觉领域的应用。首先概述了Halcon的基础知识和软件特性,然后详细阐述了Halcon函数在图像预处理、特征提取、图像分割和目标识别中的具体应用。接着,文章通过实战案例,深入探讨了相机标定、三维重建、表面检测和运动目标跟踪等关键技术。此外,本文还提供了Halcon函数的高级开发技巧,包括图像分析算法的实现、自定义工具
PELCO-D协议全面解读:数据传输与优化策略

# 摘要
本文对PELCO-D协议进行了全面的介绍和分析,包括协议的基本理论、实践应用、高级功能以及未来的发展趋势。PELCO-D是一种广泛应用于监控系统中的通信协议,用于控制和管理相机等设备。文章首先概述了PELCO-D协议的基本概念,然后深入探讨了其数据格式、控制命令和通信机制。在实践应用方面,本文讨论了PELCO-D在监控系统中的集成步骤、数据加密和安全机制,以及性能优化的实践策略。高级功能与案例分析章节进一步探讨了扩展命
解决Tecplot标注难题:希腊字母和数学符号的精确操控秘籍

# 摘要
Tecplot软件广泛应用于技术绘图和数据可视化领域,其强大的标注功能对于提升图形和报告的专业性至关重要。本文详细介绍了希腊字母及数学符号在Tecplot中的精确应用方法,包括标准与非标准希腊字母的输入技巧、自定义方法以及数学符号的分类、功能和输入技巧。此外,本文还探讨了Tecplot标注功能的深度定制,强调了用户自定义标注功能的重要性,并提供了脚本基础和高级应用的指导。文章
手机射频技术实战指南:WIFI_BT_GPS性能优化与信号强度提升技巧
# 摘要
本文综述了手机射频技术的现状与挑战,首先介绍了射频技术的基本原理和性能指标,探讨了灵敏度、功率、信噪比等关键性能指标的定义及影响。然后,针对WIFI性能优化,深入分析了MIMO、波束成形技术以及信道选择和功率控制策略。对于蓝牙技术,探讨了BLE技术特点和优化信号覆盖范围的方法。最后,本文研究了GPS信号捕获、定位精度改进和辅
雷达信号处理的关键:MATLAB中的回波模拟与消除技巧

# 摘要
雷达信号处理是现代雷达系统中至关重要的环节,涉及信号的数学建模、去噪、仿真实现和高级处理技术。本文首先概述雷达信号处理的基本概念,随后深入介绍MATLAB在雷达信号处理中的应用,包括编程基础、工具箱的利用及信号仿真。文章重点探讨了雷达回波信号的数学描述、噪声分析、去噪技术以及回波消除方法,并讨论了自适应信号处理技术、空间和频率域处理方法以及MUSIC算法。最后,通过案例分析展示了MATLAB在
【CAD数据在ANSYS中完美预处理】:专业清理与准备指南
# 摘要
随着工程设计复杂性的增加,CAD数据的处理和ANSYS预处理成为了确保仿真分析准确性的重要步骤。本文详细探讨了从CAD数据导入、组织管理到几何处理的完整流程,强调了数据清理、简化与重构的技巧,以及网格划分的重要性。此外,文章还讨论了如何在ANSYS中准确地定义材料属性和载荷,以及为动态分析做准备。最后,本文展望了预处理流程自动化和优化的可能性,并分析了工程师在预处
【GNU-ld-V2.30链接脚本秘籍】:从入门到实践的快速指南

# 摘要
GNU ld链接器作为重要的工具,它在程序构建过程中扮演着至关重要的角色。本文深入解析了GNU ld链接器的基础知识、链接脚本的核心概念,并探讨了链接脚本的高级功能和组织结构。通过对实战演练的分析,本文提供了基本与高级链接脚本技术应用的实例,并详细讨论了脚本的调试
银河麒麟桌面系统V10 2303版本特性全解析:专家点评与优化建议
# 摘要
本文综合分析了银河麒麟桌面系统V10 2303版本的核心更新、用户体验改进、性能测试结果、行业应用前景以及优化建议。重点介绍了系统架构优化、用户界面定制、新增功能及应用生态的丰富性。通过基准测试和稳定性分析,评估了系统的性能和安全特性。针对不同行业解决方案和开源生态合作进行了前景探讨,同时提出了面临的市场挑战和对策。文章最后提出了系统优化方向和长期发展愿景,探讨了技术创新和对国产操作系统生态的潜在贡献。
# 关键字
银河麒麟桌面系统;系统架构;用户体验;性能评测;行业应用;优化建议;技术创新
参考资源链接:[银河麒麟V10桌面系统专用arm64架构mysql离线安装包](http
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )