Spring Data JPA实战:简化Java数据库操作的十大秘诀
发布时间: 2024-09-25 00:34:25 阅读量: 61 订阅数: 52 

# 1. Spring Data JPA概述与配置
## 1.1 Spring Data JPA简介
Spring Data JPA是Spring家族中用于简化数据库访问的子项目,它使得开发者能够以极简的方式进行数据持久化操作。通过继承特定接口并使用Spring Data提供的注解,开发者可以快速创建Repository接口,并实现基本的CRUD操作。这一技术的优势在于其高度的抽象,能大幅度减少模板代码的编写,同时通过接口规范和约定优于配置的设计哲学,使开发者能更专注于业务逻辑的实现。
## 1.2 配置Spring Data JPA
要配置Spring Data JPA,首先需要添加Maven或Gradle依赖。对于Maven项目来说,通常需要添加`spring-boot-starter-data-jpa`和数据库连接相关依赖,例如`h2`, `mysql`或`postgresql`等。配置文件(application.properties或application.yml)中需要指定数据库连接详情以及JPA相关的配置参数,如`spring.datasource.url`, `spring.datasource.username`, `spring.datasource.password`和`spring.jpa.hibernate.ddl-auto`等。
```xml
<!-- Maven依赖配置示例 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
```
```properties
# Spring配置文件示例
spring.datasource.url=jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1
spring.datasource.driverClassName=org.h2.Driver
spring.datasource.username=sa
spring.datasource.password=
spring.jpa.database-platform=org.hibernate.dialect.H2Dialect
spring.jpa.hibernate.ddl-auto=update
```
配置完成后,通过`@Entity`标注实体类,`@Repository`标注存储库接口,并通过继承`JpaRepository`接口,即可利用Spring Data JPA提供的丰富功能。开发者可以立即开始编写业务逻辑代码,而无需手动编写大量的数据访问层代码。
# 2. 核心概念与基础知识
### 2.1 实体映射与JPA注解
#### 2.1.1 实体类与@Table注解
在JPA中,实体类通常对应数据库中的表,而`@Table`注解用于映射实体类到具体的表。通过该注解,开发者可以自定义表的名称,以及各种数据库级别的约束,如索引、唯一性约束等。
```java
@Entity
@Table(name = "users")
public class User {
@Id
private Long id;
@Column(name = "username", nullable = false, unique = true)
private String username;
@Column(name = "password", nullable = false)
private String password;
// ... 其他属性和方法
}
```
在这个例子中,`User`类使用`@Entity`注解标注为一个JPA实体,并使用`@Table(name = "users")`指定了该实体映射到数据库中的`users`表。`@Id`注解表示该字段是主键,`@Column`注解则用来定义字段对应的列,其中`name`属性指定了数据库中列的名称,`nullable`表示该列是否可以为空,`unique`则表示该列的值是否需要是唯一的。
#### 2.1.2 常用JPA注解详解
除了`@Table`注解外,JPA还提供了一系列其他注解来定义实体的各种属性和关系。以下是一些常用的JPA注解及其功能说明:
- `@Column`:指定实体属性映射到数据库表的具体列。
- `@Id`:标识属性为主键。
- `@GeneratedValue`:指定主键的生成策略,例如`GenerationType.IDENTITY`表示主键由数据库自动递增。
- `@Basic`:指定属性是基本类型,默认就是基本类型,一般可省略。
- `@Temporal`:用于日期类型的属性,指定其映射到数据库的日期时间类型。
- `@Lob`:表示该字段映射为大对象类型,如CLOB或BLOB。
- `@Transient`:指定属性不映射到数据库表的列。
### 2.2 JPA查询语言JPQL
#### 2.2.1 JPQL基础与示例
JPQL(Java Persistence Query Language)是JPA提供的查询语言,它与SQL类似,但是JPQL查询的是实体对象而非数据库表。开发者可以利用JPQL编写查询操作,而无需关心底层使用的数据库。
例如,查询所有用户实体的JPQL语句如下:
```java
TypedQuery<User> query = entityManager.createQuery(
"SELECT u FROM User u", User.class);
List<User> users = query.getResultList();
```
这段代码首先通过`entityManager`对象创建了一个`TypedQuery`对象,查询类型为`User`。JPQL查询语句`"SELECT u FROM User u"`表示选择所有`User`实体,`u`是实体的别名。`getResultList()`方法执行查询,并返回所有匹配实体的列表。
#### 2.2.2 JPQL高级特性与实践
JPQL除了基础查询,还支持更复杂的查询操作,如参数绑定、别名使用、分组查询等。JPQL的高级特性使得它能够处理复杂的业务逻辑查询需求。
举例说明使用JPQL进行分组查询:
```java
TypedQuery<Tuple> query = entityManager.createQuery(
"SELECT u.name, COUNT(u.id) FROM User u GROUP BY u.name", Tuple.class);
List<Tuple> result = query.getResultList();
```
上述代码使用`Tuple`来接收查询结果,它将返回每个用户的名称和对应的用户数量。`GROUP BY`用于分组统计,这在处理报表和统计信息时非常有用。
### 2.3 事务管理与并发控制
#### 2.3.1 事务的声明与传播
在JPA中,事务是由`EntityManager`进行管理的。开发者可以通过`@Transactional`注解来声明一个方法的事务边界。此外,JPA提供了多种事务传播行为,以适应不同的业务场景。
```java
@Transactional(propagation = Propagation.REQUIRED)
public void updateUserData(Long userId, String newData) {
User user = entityManager.find(User.class, userId);
user.setData(newData);
entityManager.merge(user);
}
```
在上述代码中,`@Transactional(propagation = Propagation.REQUIRED)`注解表示如果当前调用的方法在事务中运行,那么被调用的方法会在同一个事务中运行,如果当前没有事务,则会新建一个事务。
#### 2.3.2 乐观锁与悲观锁的实际应用
在处理并发数据访问时,JPA提供了乐观锁和悲观锁两种机制。乐观锁适用于读多写少的应用场景,而悲观锁适用于写多读少的场景。
例如,使用乐观锁的实体类可能包含一个版本号字段:
```java
@Entity
public class Product {
@Id
private Long id;
@Version
private Integer version;
// ... 其他属性和方法
}
```
在更新`Product`实体时,JPA会检查版本号是否匹配,如果不匹配则抛出`OptimisticLockException`异常,防止数据更新冲突。而使用悲观锁时,可以在查询时使用`LockModeType`来加锁:
```java
Product product = entityManager.find(Product.class, productId, LockModeType.PESSIMISTIC_WRITE);
```
这段代码在查找`Product`时加了排他锁(`PESSIMISTIC_WRITE`),确保在当前事务完成之前,其他事务不能读取或修改该`Product`实例。
### 配置示例
为了展示章节内容的连贯性,下面是JPA配置文件的示例,通常命名为`persistence.xml`,位于项目的`META-INF`目录下:
```xml
<persistence xmlns="***"
xmlns:xsi="***"
xsi:schemaLocation="***
***"
version="2.0">
<persistence-unit name="example">
<jta-data-source>jdbc/exampleDataSource</jta-data-source>
<properties>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/exampleDB"/>
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《Java Spring》专栏深入探讨了 Spring 框架的各个方面,为 Java 企业应用开发人员提供全面的指导。从 Spring 核心原理到高级技术,该专栏涵盖了广泛的主题,包括 AOP、Spring Boot、Spring Data JPA、Spring Security、事务管理、RESTful API 设计、生命周期管理、Actuator、会话管理和设计模式应用。通过深入浅出的讲解和实战指南,该专栏旨在帮助读者掌握 Spring 框架的精髓,构建健壮、可扩展和安全的 Java 应用。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ODU flex故障排查:G.7044标准下的终极诊断技巧

# 摘要
本文综述了ODU flex技术在故障排查方面的应用,重点介绍了G.7044标准的基础知识及其在ODU flex故障检测中的重要性。通过对G.7044协议理论基础的探讨,本论文阐述了该协议在故障诊断中的核心作用。同时,本文还探讨了故障检测的基本方法和高级技术,并结合实践案例分析,展示了如何综合应用各种故障检测技术解决实际问题。最后,本论文展望了故障排查技术的未来发展,强调了终
环形菜单案例分析

# 摘要
环形菜单作为用户界面设计的一种创新形式,提供了不同于传统线性菜单的交互体验。本文从理论基础出发,详细介绍了环形菜单的类型、特性和交互逻辑。在实现技术章节,文章探讨了基于Web技术、原生移动应用以及跨平台框架的不同实现方法。设计实践章节则聚焦于设计流程、工具选择和案例分析,以及设计优化对用户体验的影响。测试与评估章节覆盖了测试方法、性能安全评估和用户反馈的分析。最后,本文展望
【性能优化关键】:掌握PID参数调整技巧,控制系统性能飞跃
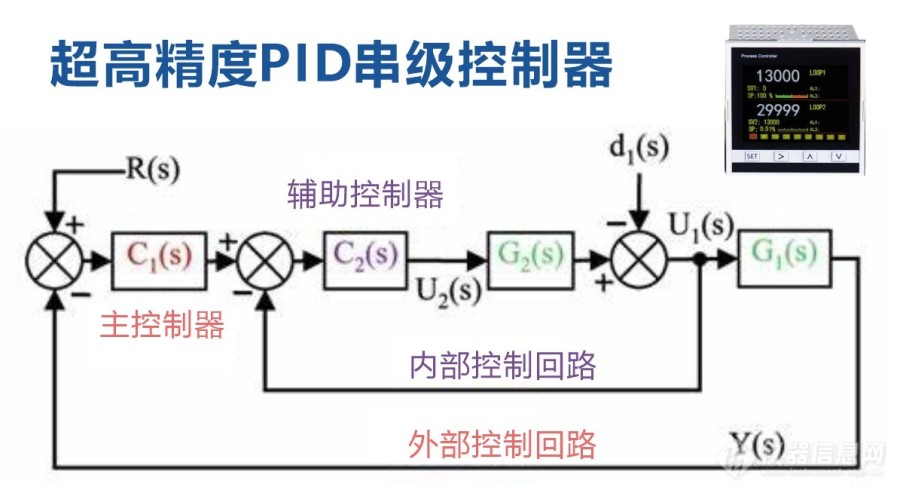
# 摘要
本文深入探讨了PID控制理论及其在工业控制系统中的应用。首先,本文回顾了PID控制的基础理论,阐明了比例(P)、积分(I)和微分(D)三个参数的作用及重要性。接着,详细分析了PID参数调整的方法,包括传统经验和计算机辅助优化算法,并探讨了自适应PID控制策略。针对PID控制系统的性能分析,本文讨论了系统稳定性、响应性能及鲁棒性,并提出相应的提升策略。在
系统稳定性提升秘籍:中控BS架构考勤系统负载均衡策略

# 摘要
本文旨在探讨中控BS架构考勤系统中负载均衡的应用与实践。首先,介绍了负载均衡的理论基础,包括定义、分类、技术以及算法原理,强调其在系统稳定性中的重要性。接着,深入分析了负载均衡策略的选取、实施与优化,并提供了基于Nginx和HAProxy的实际
【Delphi实践攻略】:百分比进度条数据绑定与同步的终极指南

# 摘要
本文针对百分比进度条的设计原理及其在Delphi环境中的数据绑定技术进行了深入研究。首先介绍了百分比进度条的基本设计原理和应用,接着详细探讨了Delphi中数据绑定的概念、实现方法及高级应用。文章还分析了进度条同步机制的理论基础,讨论了实现进度条与数据源同步的方法以及同步更新的优化策略。此外,本文提供了关于百分比进度条样式自定义与功能扩展的指导,并
【TongWeb7集群部署实战】:打造高可用性解决方案的五大关键步骤

# 摘要
本文深入探讨了高可用性解决方案的实施细节,首先对环境准备与配置进行了详细描述,涵盖硬件与网络配置、软件安装和集群节点配置。接着,重点介绍了TongWeb7集群核心组件的部署,包括集群服务配置、高可用性机制及监控与报警设置。在实际部署实践部分,本文提供了应用程序部署与测试、灾难恢复演练及持续集成与自动化部署
JY01A直流无刷IC全攻略:深入理解与高效应用

# 摘要
本文详细介绍了JY01A直流无刷IC的设计、功能和应用。文章首先概述了直流无刷电机的工作原理及其关键参数,随后探讨了JY01A IC的功能特点以及与电机集成的应用。在实践操作方面,本文讲解了JY01A IC的硬件连接、编程控制,并通过具体
先锋SC-LX59:多房间音频同步设置与优化

# 摘要
本文旨在介绍先锋SC-LX59音频系统的特点、多房间音频同步的理论基础及其在实际应用中的设置和优化。首先,文章概述了音频同步技术的重要性及工作原理,并分析了影响音频同步的网络、格式和设备性能因素。随后,针对先锋SC-LX59音频系统,详细介绍了初始配置、同步调整步骤和高级同步选项。文章进一步探讨了音频系统性能监测和质量提升策略,包括音频格式优化和环境噪音处理。最后,通过案例分析和实战演练,展示了同步技术在多品牌兼容性和创新应用
【S参数实用手册】:理论到实践的完整转换指南
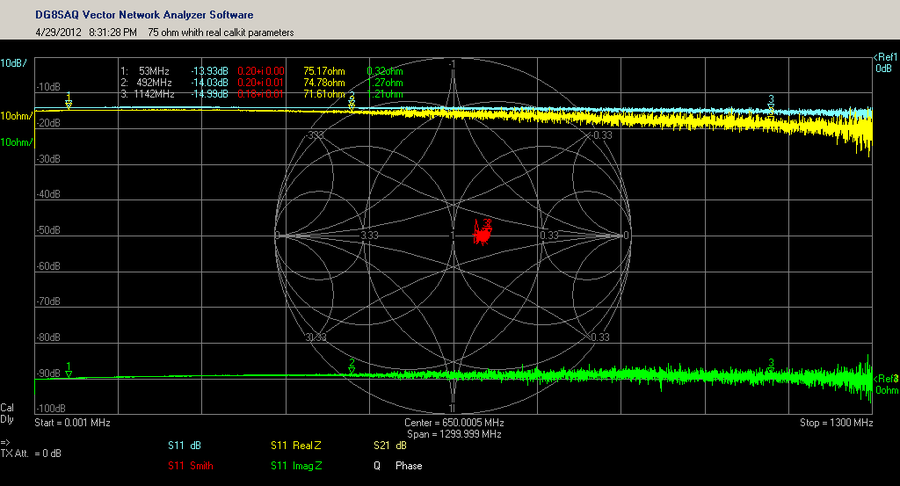
# 摘要
本文系统阐述了S参数的基础理论、测量技术、在射频电路中的应用、计算机辅助设计以及高级应用和未来发展趋势。第一章介绍了S参数的基本概念及其在射频工程中的重要性。第二章详细探讨了S参数测量的原理、实践操作以及数据处理方法。第三章分析了S参数在射频电路、滤波器和放大器设计中的具体应用。第四章进一步探讨了S参数在CAD软件中的集成应用、仿真优化以及数据管理。第五章介绍了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )